利用Tess4J实现图片文字识别
前言
光学字符识别(OCR)技术允许计算机通过扫描仪、摄像头等设备来识别并转换印刷或手写文本的图像数据为可编辑的文本格式。Tess4J是一个优秀的Java库,提供了与Tesseract OCR引擎的集成,方便进行图片文字识别。
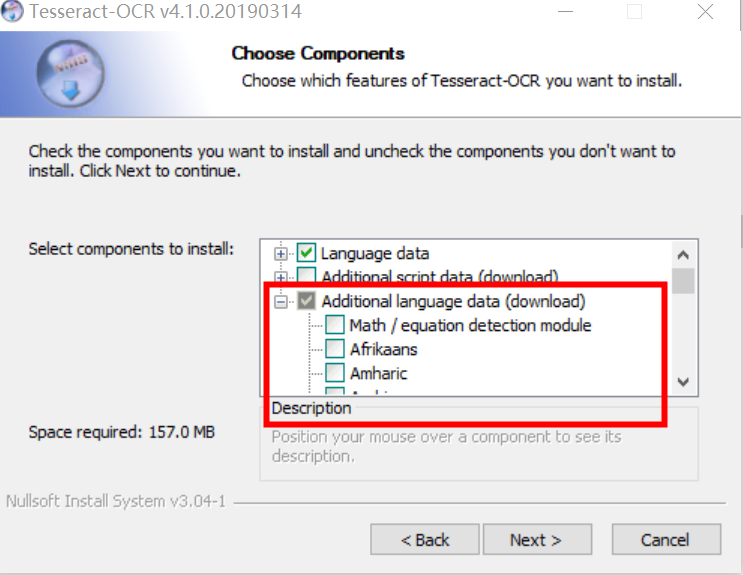
1.创建项目导入tess4j对应的依赖
代码如下:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.1.1</version>
</dependency>
2.编写测试类进行测试
代码如下:
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import java.io.File;
public class Application {
/**
* @Description:识别图片中的文字
* @param args
*/
public static void main(String[] args) {
try {
//获取本地图片
File file = new File("E:\\file\\aa.png");
//创建Tesseract对象
ITesseract tesseract = new Tesseract();
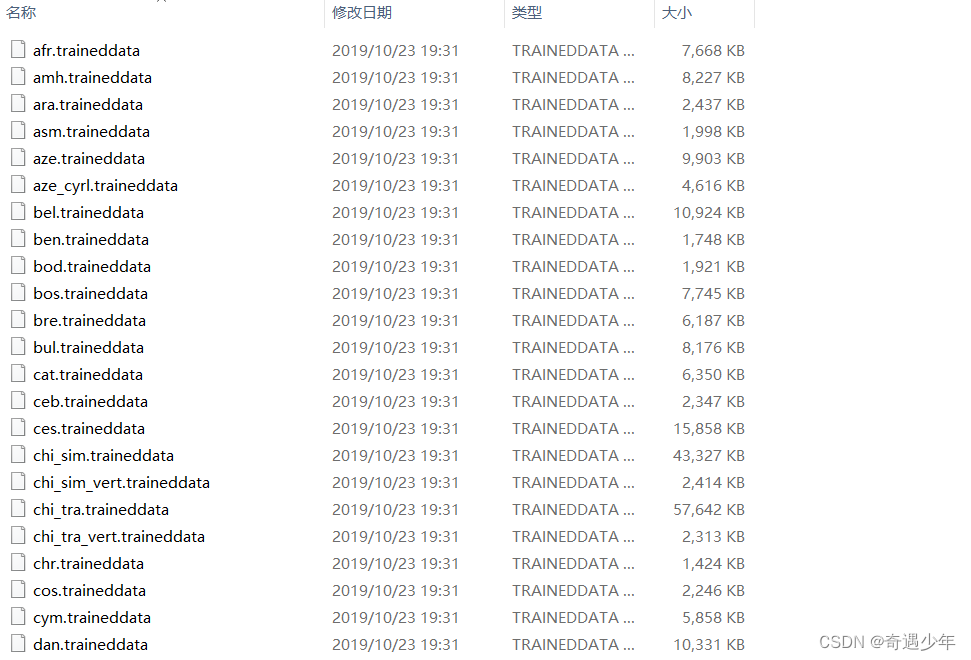
//设置字体库路径
tesseract.setDatapath("E:\\file");
//设置语言简体中文
tesseract.setLanguage("chi_sim");
//执行ocr识别图片
String result = tesseract.doOCR(file);
//替换回车和tal键 使结果为一行
result = result.replaceAll("\\r|\\n","-").replaceAll(" ","");
System.out.println("识别的结果为:"+result);
} catch (Exception e) {
e.printStackTrace();
}
}
}