相关文章
- 【数仓】基本概念、知识普及、核心技术
- 【数仓】数据分层概念以及相关逻辑
- 【数仓】Hadoop软件安装及使用(集群配置)
- 【数仓】Hadoop集群配置常用参数说明
- 【数仓】zookeeper软件安装及集群配置
- 【数仓】kafka软件安装及集群配置
- 【数仓】flume软件安装及配置
- 【数仓】flume常见配置总结,以及示例
- 【数仓】Maxwell软件安装及配置,采集mysql数据
- 【数仓】通过Flume+kafka采集日志数据存储到Hadoop
- 【数仓】DataX软件安装及配置,从mysql同步到hdfs
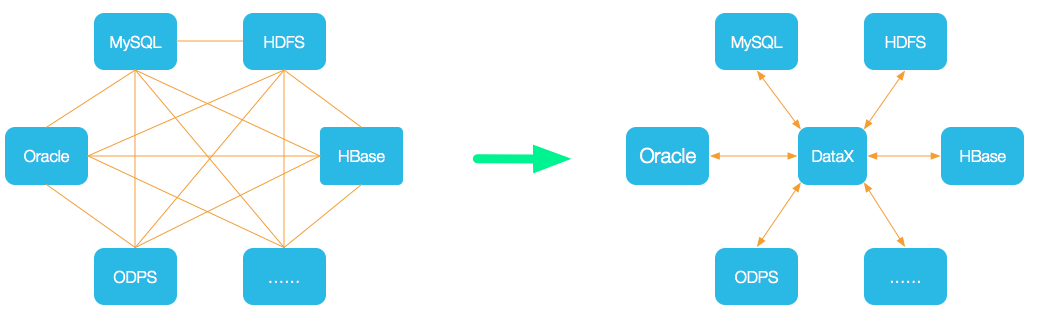
DataX的任务脚本job.json格式基本类似,而且我们在实际同步过程中通常都是一个表对应一个job,那么如果需要同步的表非常多的话,需要编写的job.json文件也非常多。既然是类似文件结构,那么我们就有办法通过程序自动生成相关的job.json文件。
居于以上考虑,有了下面的SpringBoot项目自动生成job.json的程序!
一、job 配置说明
DataX的job配置中的reader、writer和setting是构成数据同步任务的关键组件。
1、reader
reader是数据同步任务中的数据源读取配置部分,用于指定从哪个数据源读取数据以及如何读取数据。它通常包含以下关键信息:
name: 读取插件的名称,如mysqlreader、hdfsreader等,用于指定从哪种类型的数据源读取数据。parameter: 具体的读取参数配置,包括数据源连接信息、读取的表或文件路径、字段信息等。
示例:
假设要从MySQL数据库读取数据,reader的配置可能如下:
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "password",
"column": ["id", "name", "age"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://localhost:3306/test_db",
"table": ["test_table"]
}
]
}
}
2、writer
writer是数据同步任务中的目标数据源写入配置部分,用于指定将数据写入哪个目标数据源以及如何写入数据。它通常包含以下关键信息:
name: 写入插件的名称,如mysqlwriter、hdfswriter等,用于指定将数据写入哪种类型的数据源。parameter: 具体的写入参数配置,包括目标数据源连接信息、写入的表或文件路径、字段映射等。
示例:
假设要将数据写入HDFS,writer的配置可能如下:
"writer": {
"name": "hdfswriter",
"parameter": {
"writeMode": "append",
"fieldDelimiter": ",",
"compress": "gzip",
"column": [{"name": "id", "type": "int"}, {"name": "name", "type": "string"}, {"name": "age", "type": "int"}],
"connection": [
{
"hdfsUrl": "hdfs://localhost:9000",
"file": ["/user/hive/warehouse/test_table"]
}
]
}
}
3、setting
setting是数据同步任务的全局设置部分,用于配置影响整个任务行为的参数。它通常包含以下关键信息:
speed: 控制数据同步的速度和并发度,包括通道数(channel)和每个通道的数据传输速度(如byte)。errorLimit: 设置数据同步过程中的错误容忍度,包括允许出错的记录数(record)和错误率(percentage)。
示例:
一个典型的setting配置可能如下:
"setting": {
"speed": {
"channel": 3, // 并发通道数
"byte": 1048576 // 每个通道的数据传输速度,单位是字节(1MB)
},
"errorLimit": {
"record": 0, // 允许出错的记录数
"percentage": 0.02 // 允许出错的记录数占总记录数的百分比
}
}
综上所述,reader、writer和setting三个部分共同构成了DataX数据同步任务的配置文件。通过合理配置这些部分,用户可以灵活地定义数据源、目标数据源以及数据同步的行为和性能。在实际应用中,用户应根据具体的数据源类型、目标数据源类型和数据同步需求来填写和调整这些配置。
二、示例,从mysql同步到hdfs
该配置文件定义了从一个 MySQL 数据库读取数据,并将这些数据写入到 HDFS 的过程。
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id","name","msg","create_time","status","last_login_time"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://192.168.56.1:3306/user?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai"],
"table": ["t_user"]
}
],
"password": "password",
"username": "test",
"where": "id>3"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":"id","type":"bigint"},
{"name":"name","type":"string"},
{"name":"msg","type":"string"},
{"name":"create_time","type":"date"},
{"name":"status","type":"string"},
{"name":"last_login_time","type":"date"}
],
"compress": "gzip",
"defaultFS": "hdfs://hadoop131:9000",
"fieldDelimiter": "\t",
"fileName": "mysql2hdfs01",
"fileType": "text",
"path": "/mysql2hdfs",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
三、通过SpringBoot项目自动生成job文件
本例使用SpringBoot 3.0 结合 JDBC 读取mysql数据库表结构信息,生成job.json文件
1、创建SpringBoot项目,添加pom依赖以及配置
1)增加pom.xml依赖jar包
<!-- Spring Boot JDBC Starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- MySQL JDBC Driver -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.25</version>
</dependency>
2)增加application.properties配置项
server.port=8080
# mysql 数据库链接
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/user?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
spring.datasource.username=test
spring.datasource.password=password
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
# datax 相关配置,在生成文件时使用
datax.hdfs.defaultFS=hdfs://hadoop131:9000
datax.hdfs.path=/origin_data
# 需要生成job文件的表,多个用逗号隔开
datax.mysql.tables=t_user,t_user_test,t_sys_dict
# job文件存储位置
datax.savepath=d:/temp/
2、按照job.json格式创建好各个 vo
1)基础结构vo
@Data
public class DataxJobRoot {
private Job job;
}
@Data
public class Job {
private List<Content> content;
private Setting setting = new Setting();
}
@Data
public class Content {
private Reader reader;
private Writer writer;
}
@Data
public class Setting {
private Speed speed = new Speed();
@Data
public static class Speed {
private String channel = "1";
}
}
@Data
public class Reader {
private String name;
private Parameter parameter;
}
@Data
public class Writer {
private String name;
private Parameter parameter;
@Data
public static class MysqlParameter {
private List<String> column;
private List<Connection> connection;
private String password;
private String username;
private String writeMode = "replace";
}
@Data
public static class Connection {
private String jdbcUrl;
private List<String> table;
}
}
public class Parameter {
}
2)mysql2hdfs的vo实现类
@EqualsAndHashCode(callSuper = true)
@Data
public class MysqlReader extends Reader {
public String getName() {
return "mysqlreader";
}
@EqualsAndHashCode(callSuper = true)
@Data
public static class MysqlParameter extends Parameter {
private List<String> column;
private List<Connection> connection;
private String password;
private String username;
private String where;
}
@Data
public static class Connection {
private List<String> jdbcUrl;
private List<String> table;
}
}
@EqualsAndHashCode(callSuper = true)
@Data
public class HdfsWriter extends Writer {
public String getName() {
return "hdfswriter";
}
@EqualsAndHashCode(callSuper = true)
@Data
public static class HdfsParameter extends Parameter {
private List<Column> column;
private String compress = "gzip";
private String encoding = "UTF-8";
private String defaultFS;
private String fieldDelimiter = "\t";
private String fileName;
private String fileType = "text";
private String path;
private String writeMode = "append";
}
@Data
public static class Column {
String name;
String type;
}
}
3)hdfs2mysql的vo实现类
@EqualsAndHashCode(callSuper = true)
@Data
public class HdfsReader extends Reader {
@Override
public String getName() {
return "hdfsreader";
}
public HdfsParameter getParameter() {
return new HdfsParameter();
}
@EqualsAndHashCode(callSuper = true)
@Data
public static class HdfsParameter extends Parameter {
private List<String> column = Collections.singletonList("*");
private String compress = "gzip";
private String encoding = "UTF-8";
private String defaultFS;
private String fieldDelimiter = "\t";
private String fileName;
private String fileType = "text";
private String path;
private String nullFormat = "\\N";
}
}
@EqualsAndHashCode(callSuper = true)
@Data
public class MysqlWriter extends Writer {
public String getName() {
return "mysqlwriter";
}
public MysqlParameter getParameter() {
return new MysqlParameter();
}
@EqualsAndHashCode(callSuper = true)
@Data
public static class MysqlParameter extends Parameter {
private List<String> column;
private List<Connection> connection;
private String password;
private String username;
private String writeMode = "replace";
}
@Data
public static class Connection {
private String jdbcUrl;
private List<String> table;
}
}
3、创建Repository、Service类读取数据库表结构
@Repository
public class DatabaseInfoRepository {
private final JdbcTemplate jdbcTemplate;
@Autowired
public DatabaseInfoRepository(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
// 获取所有表名
public List<String> getAllTableNames() {
String sql = "SHOW TABLES";
return jdbcTemplate.queryForList(sql, String.class);
}
// 根据表名获取字段信息
public List<Map<String, Object>> getTableColumns(String tableName) {
String sql = "SHOW FULL COLUMNS FROM " + tableName;
return jdbcTemplate.queryForList(sql);
}
}
@Service
public class DatabaseInfoService {
private final DatabaseInfoRepository databaseInfoRepository;
@Autowired
public DatabaseInfoService(DatabaseInfoRepository databaseInfoRepository) {
this.databaseInfoRepository = databaseInfoRepository;
}
public void printAllTablesAndColumns() {
// 获取所有表名
List<String> tableNames = databaseInfoRepository.getAllTableNames();
// 遍历表名,获取并打印每个表的字段信息
for (String tableName : tableNames) {
System.out.println("Table: " + tableName);
// 获取当前表的字段信息
List<Map<String, Object>> columns = databaseInfoRepository.getTableColumns(tableName);
// 遍历字段信息并打印
for (Map<String, Object> column : columns) {
System.out.println(" Column: " + column.get("Field") + " (Type: " + column.get("Type") + ")" + " (Comment: " + column.get("Comment") + ")");
}
System.out.println(); // 打印空行作为分隔
}
}
/** 查询指定表的所有字段列表 */
public List<String> getColumns(String tableName) {
List<String> list = new ArrayList<>();
// 获取当前表的字段信息
List<Map<String, Object>> columns = databaseInfoRepository.getTableColumns(tableName);
// 遍历字段信息并打印
for (Map<String, Object> column : columns) {
list.add(column.get("Field").toString());
}
return list;
}
/** 查询指定表的所有字段列表,封装成HdfsWriter格式 */
public List<HdfsWriter.Column> getHdfsColumns(String tableName) {
List<HdfsWriter.Column> list = new ArrayList<>();
// 获取当前表的字段信息
List<Map<String, Object>> columns = databaseInfoRepository.getTableColumns(tableName);
// 遍历字段信息并打印
for (Map<String, Object> column : columns) {
String name = column.get("Field").toString();
String typeDb = column.get("Type").toString();
String type = "string";
if (typeDb.equals("bigint")) {
type = "bigint";
} else if (typeDb.startsWith("varchar")) {
type = "string";
} else if (typeDb.startsWith("date") || typeDb.endsWith("timestamp")) {
type = "date";
}
HdfsWriter.Column columnHdfs = new HdfsWriter.Column();
columnHdfs.setName(name);
columnHdfs.setType(type);
list.add(columnHdfs);
}
return list;
}
}
4、创建Service生成job.json文件
@Service
public class GenHdfs2mysqlJsonService {
@Value("${spring.datasource.url}")
private String url;
@Value("${spring.datasource.password}")
private String password;
@Value("${spring.datasource.username}")
private String username;
@Value("${datax.mysql.tables}")
private String tables;
@Value("${datax.hdfs.defaultFS}")
private String defaultFS;
@Value("${datax.hdfs.path}")
private String path;
@Value("${datax.savepath}")
private String savepath;
@Autowired
private DatabaseInfoService databaseInfoService;
/**
* 生成 hdfs2mysql的job.json
* @param table
*/
public void genHdfs2mysqlJson(String table) {
DataxJobRoot root = new DataxJobRoot();
Job job = new Job();
root.setJob(job);
Content content = new Content();
HdfsReader reader = new HdfsReader();
MysqlWriter writer = new MysqlWriter();
content.setReader(reader);
content.setWriter(writer);
job.setContent(Collections.singletonList(content));
HdfsReader.HdfsParameter hdfsParameter = reader.getParameter();
hdfsParameter.setPath(path);
hdfsParameter.setFileName(table + "_hdfs");
hdfsParameter.setDefaultFS(defaultFS);
MysqlWriter.MysqlParameter mysqlParameter = writer.getParameter();
mysqlParameter.setPassword(password);
mysqlParameter.setUsername(username);
List<String> columns = databaseInfoService.getColumns(table);
mysqlParameter.setColumn(columns);
MysqlWriter.Connection connection = new MysqlWriter.Connection();
connection.setJdbcUrl(url);
connection.setTable(Collections.singletonList(table));
mysqlParameter.setConnection(Collections.singletonList(connection));
String jsonStr = JSONUtil.parse(root).toJSONString(2);
System.out.println(jsonStr);
File file = FileUtil.file(savepath, table + "_h2m.json");
FileUtil.appendString(jsonStr, file, "utf-8");
}
/**
* 生成 mysql2hdfs 的job.json
* @param table
*/
public void genMysql2HdfsJson(String table) {
DataxJobRoot root = new DataxJobRoot();
Job job = new Job();
root.setJob(job);
Content content = new Content();
HdfsWriter writer = new HdfsWriter();
MysqlReader reader = new MysqlReader();
content.setReader(reader);
content.setWriter(writer);
job.setContent(Collections.singletonList(content));
HdfsWriter.HdfsParameter hdfsParameter = new HdfsWriter.HdfsParameter();
writer.setParameter(hdfsParameter);
hdfsParameter.setPath(path);
hdfsParameter.setFileName(table + "_hdfs");
hdfsParameter.setDefaultFS(defaultFS);
List<HdfsWriter.Column> lstColumns = databaseInfoService.getHdfsColumns(table);
hdfsParameter.setColumn(lstColumns);
MysqlReader.MysqlParameter mysqlParameter = new MysqlReader.MysqlParameter();
reader.setParameter(mysqlParameter);
mysqlParameter.setPassword(password);
mysqlParameter.setUsername(username);
List<String> columns = databaseInfoService.getColumns(table);
mysqlParameter.setColumn(columns);
MysqlReader.Connection connection = new MysqlReader.Connection();
connection.setJdbcUrl(Collections.singletonList(url));
connection.setTable(Collections.singletonList(table));
mysqlParameter.setConnection(Collections.singletonList(connection));
String jsonStr = JSONUtil.parse(root).toJSONString(2);
System.out.println(jsonStr);
File file = FileUtil.file(savepath, table + "_m2h.json");
FileUtil.appendString(jsonStr, file, "utf-8");
}
public void genAllTable() {
Splitter.on(",").split(tables).forEach(this::genMysql2HdfsJson);
}
}
5、执行测试
调用genAllTable()方法,在配置的存储目录中自动生成每个表的job.json文件,结构示例如下:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name",
"msg",
"create_time",
"last_login_time",
"status"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/user?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai"
],
"table": [
"t_user"
]
}
],
"password": "password",
"username": "test"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "name",
"type": "string"
},
{
"name": "msg",
"type": "string"
},
{
"name": "create_time",
"type": "date"
},
{
"name": "last_login_time",
"type": "date"
},
{
"name": "status",
"type": "bigint"
}
],
"compress": "gzip",
"encoding": "UTF-8",
"defaultFS": "hdfs://hadoop131:9000",
"fieldDelimiter": "\t",
"fileName": "t_user_hdfs",
"fileType": "text",
"path": "/origin_data",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
至此,通过SpringBoot项目自动生成DataX的job.json文件,功能完成!
其中细节以及其他的reader\writer转换可以按照例子实现。