一、理解人工智能、机器学习、深度学习、强化学习?
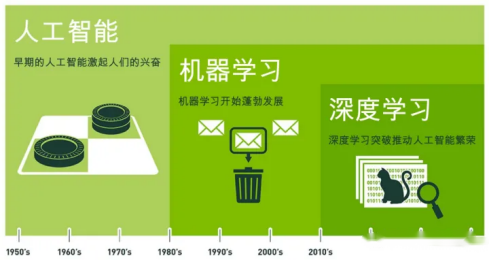
人工智能、机器学习和深度学习之间存在递进关系,它们的覆盖范围逐层递减。
**人工智能(Artificial Intelligence,AI)**是最宽泛的概念,旨在研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统。它涉及多个领域,包括机器人、语言识别、图像识别、自然语言处理、专家系统、机器学习等,是一个广泛的科学领域,旨在了解智能的实质,并生产出能以人类智能相似的方式做出反应的智能机器。
**机器学习(Machine Learning,ML)**则是实现人工智能的一种重要方式。它是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。机器学习专门研究计算机如何模拟或实现人类的学习行为,以获取新的知识或技能,并重新组织已有的知识结构以改善自身性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径。
**深度学习(Deep Learning,DL)**则是机器学习领域中的一个新的研究方向。它通过学习样本数据的内在规律和表示层次,使机器能够像人一样具有分析学习能力,从而识别文字、图像和声音等数据。深度学习在语音和图像识别等方面取得了显著成果,超过了先前的相关技术,并在搜索技术、数据挖掘、机器翻译、自然语言处理等多个领域取得了重要进展。深度学习使机器能够模仿人类的活动,如视听和思考,解决了许多复杂的模式识别问题,推动了人工智能技术的显著进步。
综上所述,人工智能是一个广泛的领域,机器学习是实现人工智能的一种方法,而深度学习则是机器学习中的一个重要分支和研究方向。三者之间的关系可以概括为:人工智能包含机器学习,而机器学习又包含深度学习,形成了一个由广到窄的递进关系。
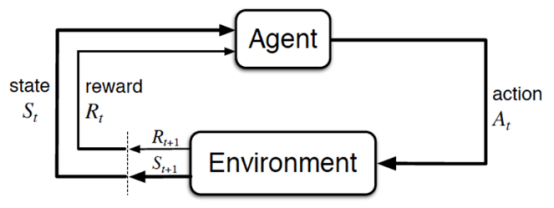
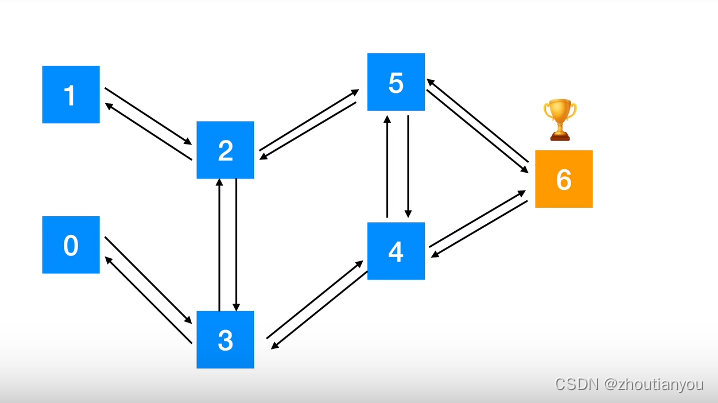
强化学习(Reinforcement Learning,简称RL),是指基于智能体在复杂、不确定的环境中最大话它能获得的奖励,从而达到自主决策的目的。
经典的强化学习模型可以总结为下图的形式(智能体、行为、环境、状态、奖励):
1.1 什么是人工智能
人工智能:计算机模拟人的思维与意识。它是一个大的方向,包含很多领域和方向。凡是让计算机系统执行特定的任务时,模仿人的行为、思维等都可以归为人工智能的范畴。大家需要了解的是人工智能分为3大主义。
1是行为主义:基于控制论,构建感知-动作控制系统。(控制论,如平衡、行走、避障等自适应控制系统)
**2是符号主义:**基于算数逻辑表达式,求解问题时先把问题描述为表达式,再求解表达式。(可用公式描述、实现理性思维,如专家系统)
**3连接主义:**仿生学,模仿神经元连接关系。(仿脑神经元连接,实现感性思维,如神经网络)。
当前人工智能的快速发展得异于连接主义即深度学习的发展,可以说深度学习推动了人工智能的繁荣。
1.2 什么是机器学习
机器学习:顾名思义,是计算机模仿人脑学习的模式来达到做某种任务。我们人脑是怎么学习的,是根据自己看过的书,走过的路,听过的课,遇到的人。也就是说数据,我们是通过学习这些接收到的数据,逐步的丰富自己的各项能力。所以机器学习也是这么一回事。
机器学习是一种从数据当中发现复杂规律,并且利用规律对未来时刻、未知状况进行预测和判定的方法,是当下被认为最有可能实现人工智能的方法。机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。
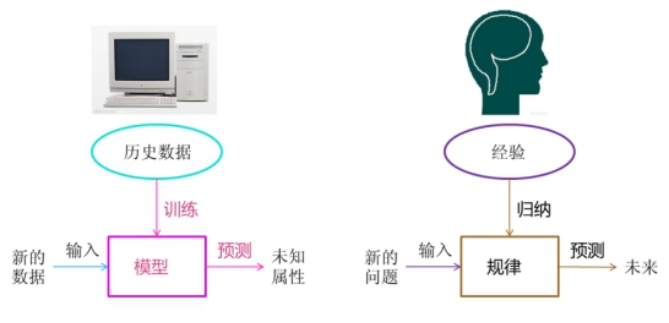
如上图所示,我们人脑对经验进行归纳得出规律,然后当有新的问题进来时,我们利用总结归纳的规律预测未来。计算机也是一样,它利用历史数据,对历史数据进行建模,然后当有新的数据输入时,就可以预测该数据的相关属性。
机器学习的形式化定义:
对于某类任务T 和性能度量P ,一个计算机程序被认为可以从经验E中学习是指;通过经验E改进后,它在任务T 上的性能有所提升。
我们继续抽象化这个定义。总结机器学习形式化定义三要素:
明确指定的任务T
评价任务性能P的性能指标
用于改善任务性能的经验E
也就是以 P 评价计算机程序关于某类任务 T 上的性能,如果某程序利用经验 E 使 T 中的任务得到了性能改善,则称该程序对经验 E 进行了学习。
例:介绍常见的机器学习数据集并给出数据集的机器学习形式化定义
手写数字识别数据集(MNIST)
MNIST数据集共有7000张图像,其中训练集60000张,测试集10000张,所有图像都是28*28的灰度图像,每张图像包含一个手写数字。
标注类别:共10个类别,每个类别代表0-9之间的数字。
给出上诉数据集的机器学习形式化定义:
以手写数字识别数据集(MNIST)为例:
任务T:识别或预测给定的手写体数字图像的类别
经验E:已知类别标记的手写体样本图像构成的数据集
评价任务性能P的指标:学习系统关于训练样本集的预测正确率
鸢尾花数据集(iris):
Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例。数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)中的哪一品种。
作业一:以鸢尾花(iris)数据集为例子给出机器学习形式化定义。
1.3 机器学习的分类
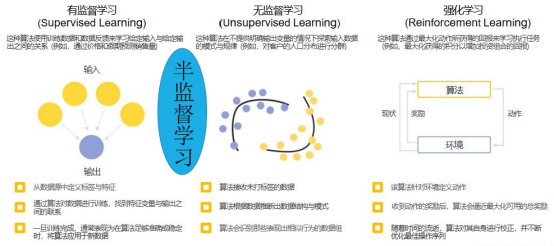
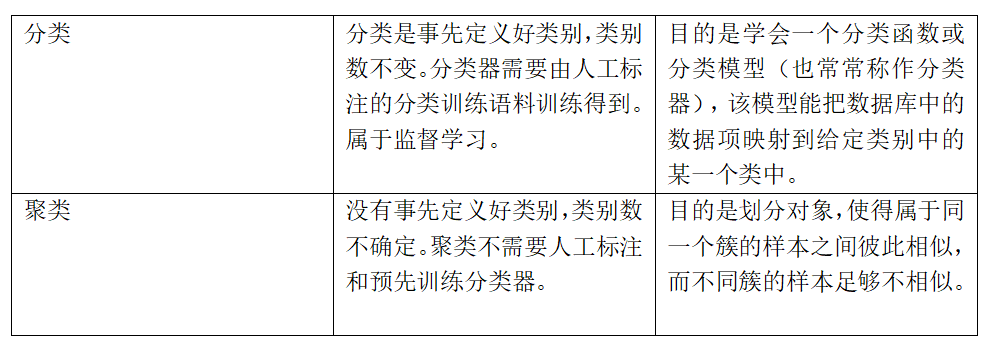
根据训练过程中是否有标签可将机器学习分为监督学习和无监督学习。
监督学习(Supervised Learning):在建立预测模型的过程中将预测结果与训练数据的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。典型例子:分类与回归任务、决策树、贝叶斯模型、支持向量机、深度学习。
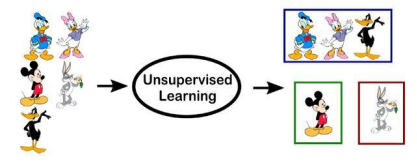
无监督学习(Unsupervised Learning):数据在训练时,并没有送入标签,即未被标记。计算机自行学习分析数据内部的规律、特征等,进而得出一定的结果(如内部结构、主要成分等)。典型例子:聚类算法。
**半监督学习:**介于监督学习和非监督学习之间,输入数据部分被标识,部分没有被标识。
**强化学习:**基于与环境的交互进行学习。通过尝试来发现各个动作产生的结果,对各个动作产生的结果,对各个动作产生的结果进行反馈(奖励或惩罚)。
如下图所示:
二、机器学习的基本术语
数据集(Dataset):数据是进行机器学习的基础,所有数据的集合称为数据集。
样本(sample):数据集中每条记录是关于一事件或对象的描述,称为样本。
属性(Attribute)或特征(Feature):每个样本在某方面表现或性质。
特征向量(Feature Vector):每个样本的特征对应的特征空间中的一个坐标向量。
特征维数(Feature Dimension):特征维数,简单来说,就是描述特征向量的维度或者说长度。
学习(Learning)或者训练(Training Data):从数据中学得模型的过程,这个过程通过执行某个算法来完成。
训练集(Training Dataset):训练过程中使用的数据。
训练样本(Training Sample):训练数据的每个样本。
验证集(Validation DataSet):是在机器学习和深度学习中用于调整超参数和评估模型性能的数据子集。在模型训练过程中,验证集起到了至关重要的作用,它帮助我们在训练集之外评估模型的泛化能力,以避免过拟合或欠拟合的情况。
测试集(Test DataSet):用于评估训练好的模型在未见过的数据上的性能。它是一组独立于训练集和验证集的数据,用于最终评估模型的泛化能力。
在模型开发和训练的过程中,我们通常会将整个数据集划分为三个主要部分:训练集(Training DataSet)、验证集(Validation DataSet)和测试集(Test DataSet)。训练集用于训练模型,通过优化损失函数来调整模型的参数。验证集用于在训练过程中评估模型的性能,并根据评估结果调整模型的超参数,如学习率、网络结构等。而测试集则用于最终评估模型的性能,确保模型在未见过的数据上也能表现出良好的性能。
标记(Label):训练数据中可能会指出训练结果的信息。
例子:银行贷款
如下表:
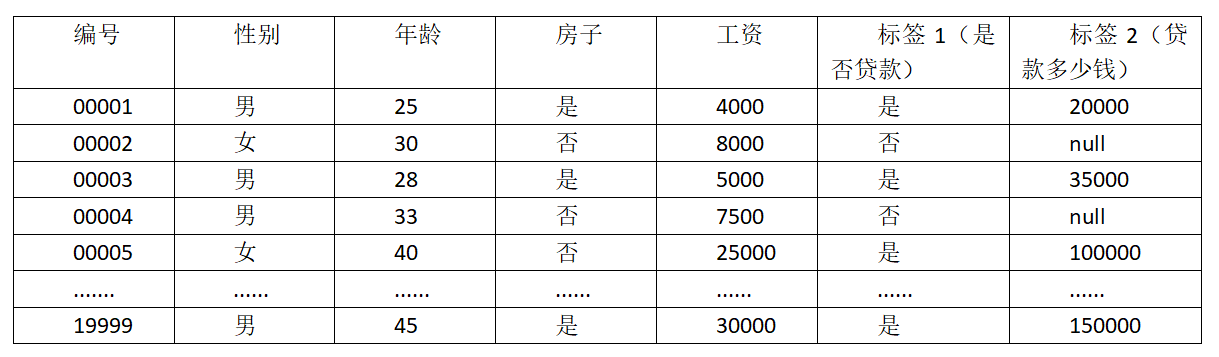
数据:性别、年龄、房子、工资 (特征)
目标:预测银行是否会给我贷款(标签)、贷款多少钱(标签)
请结合上诉数据示例理解机器学习的基本术语。
三、如何理解“使用机器学习解决问题的目的就是为了获得一个复杂函数”?
数学是科学的基础,在科学界,任何一个复杂的问题,都可以抽象化一个数学问题。我们把输入设为设为X ,输出设为 Y。那么y与x之间就要有一个映射关系。Y=f(X) 。我们求得了这个函数,便准确的把握了这个问题所在。
函数来表示数据之间的依赖性和规律,从而预测未知的输出。而机器学习作为人工智能的一个子领域,其目的正是旨在创建能够从数据中学习并执行复杂任务的系统。所以我们可以理解为使用机器学习解决问题的目的是为了获得一个复杂函数。机器学习的过程就是让机器利⽤已有的经验使得在对应任务上的性能得以提⾼的过程。也就是说,我们希望机器能够从经验数据中习得⼀个能够对新样本进⾏预测的模型,所以使用机器学习解决问题就是为了获得一个复杂函数。
请结合上诉银行数据集,再进一步理解“使用机器学习解决问题的目的就是为了获得一个复杂函数”?
四、机器学习的基本任务
4.1 分类问题与回归问题
分类是得到一个类别,比如向银行借钱,回归得到的是,银行就给我多少钱。
分类(Classification):使用计算机学习出的模型进行预测得到的是离散值。
二分类:只涉及两个类别的分类任务,其中一个类为正类(Positive Class),另一个类为负类(Negative Class)。如判断一个图像是否是猫。分为是猫、不是猫两类。
多分类(Multi-class Classification):涉及多个类别的分类任务。
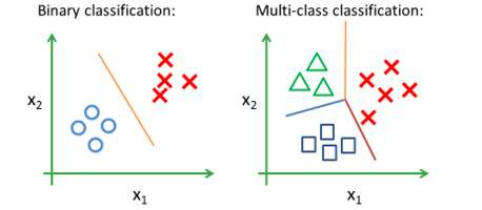
回归(Regression):使用计算机学习出的模型进行预测的得到是连续值。

4.2 聚类问题
聚类问题也可称为聚类分析(Cluster Analysis)又称群分析,是根据“物以类聚”的道理,对样品或指标进行划分的一种多元统计分析方法,聚类是一种无监督学习的方法,它的核心目标是将相似的数据对象归为一类,而将不相似的数据对象划分到不同的类别中。在这个过程中,不需要事先给定数据的类别标签,聚类算法会根据数据之间的相似性或距离自动地进行类别的划分。
特点:
聚类是在没有先验知识的情况下进行的。
一个类簇是测试空间中点的汇聚,同一个类簇的任意两个点间的距离小于不同类簇的任意两个点间的距离。
类簇可以描述为一个包含密度相对较高的点集的多维空间中的连通区域。
如下表所示,移动电话用户使用情况的数据集如下表所示:
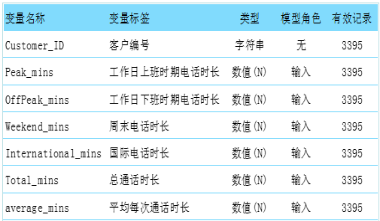
通过聚类分析,将客户聚集为5类,在聚类分析的基础上通过通话模式可以刻画各类客户特征,用户聚类的效果,如下图:
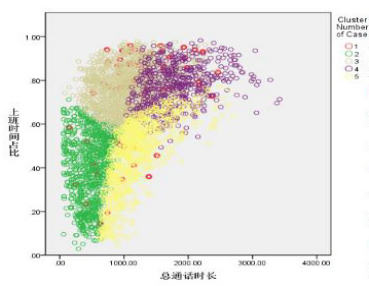
1类:平均每次通话市场最长,命名“长聊客户”。
2类:在各项中均较低,命名“不常使用客户”
3类:总通话居中,上班通话占比最高,命名“中端商用客户”。
4类:总通话事件长,上班通话占比高,国际通话最长,命名“高端商用客户”。
5类:总统话居中,下班通话最长,命名“中端日常客户”。
聚类与分类的区别:
4.3 相关分析
相关分析(relevance analysis)一般在分类和回归之前进行,识别分类和回归过程中显著相关的属性。
如某公司员工的基本情况分别为性别、年龄、工资,现在希望了解员工年龄和工资水平之间的关系,可通过计算皮尔森相关系数和显著性水平得出年龄与工资水平的相关关系。
4.4 关联规则
关联规则(Association rules)挖掘发现大量数据中项集之间有趣的关联或相关联系。
即在交易数据、关系数据或其他信息载体中,查找存在于项目集合或对象集合之间的频繁模式、关联、相关性或因果结构。
如下表:
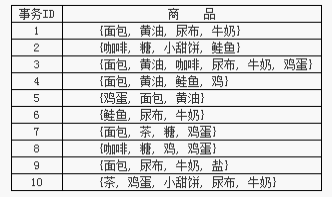
在商场中有大量的商品(项目),如牛奶、面包等,客户将所购买的客户将所购买的商品放入到自己的购物篮中。通过发现顾客放入购物篮中的不同商品之间的联系有助于分析顾客的购买习惯,如可能发现规则{尿布}→{牛奶}。该规则暗示购买尿布的顾客多半会购买牛奶。这种类型的规则可以用来发现各类商品中可能存在的交叉销售的商机。
关联规则研究有助于发现交易数据库中不同商品(项)之间的关系,找出顾客购买行为模式,如购买了某一商品对购买其他商品的影响。分析结果可以应用于商品货架布局、货存安排等。
4.5 异常检测
异常检测(anomaly detection)在数据库中包含着少数的数对象,它们于数据的一般行为或特征不一致,这些数据对象叫做异常点(Outlier),也叫孤立点。其任务是识别其特征显著不同于其他数据的观测值。其应用包括检测欺诈、网络攻击、疾病的不寻常模式、生态系统扰动等。
五、模型评估
5.1 训练误差和泛化误差
对于给定的一批数据,要求我们使用机器学习对其进行建模。通常首先将数据划分为训练集、验证集和测试集三个部分。
训练集用于对模型的参数进行训练;
验证集用于对训练的模型进行验证挑选、辅助调参;
测试集则用于测试训练好的模型的泛化能力。
训练误差:在训练集上,训练过程中使用训练误差来衡量模型对训练数据的拟合能力。
泛化误差:在测试集上,则使用泛化误差来测试模型的泛化能力。
在模型得到充分训练的条件下,训练误差与泛化误差之间的差异越小说明模型的泛化性能越好,得到一个泛化性能好的模型是机器学习的目的之一。训练误差和测试误差往往选择的是同一性能的度量函数,只是作用的数据集不同。
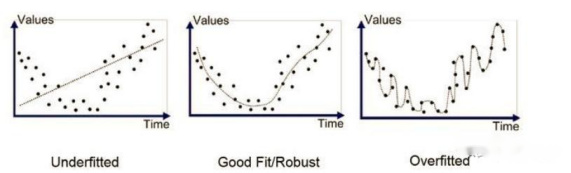
5.2 过拟合和欠拟合、正确拟合
欠拟合、过拟合和正确拟合是机器学习领域中经常遇到的术语,它们用于描述模型在训练数据上的表现以及其在未见过的数据上的泛化能力。以下是这三个概念的详细解释:
欠拟合(Underfitting):
欠拟合是指模型在训练数据上都没有得到很好的训练效果,即模型对训练数据的拟合程度不足。
当模型过于简单或参数数量太少时,可能无法捕捉到数据中的复杂关系或特征,导致欠拟合。
欠拟合的模型在训练集和测试集上的性能通常都很差,因为模型没有充分学习数据的内在规律。
过拟合(Overfitting):
过拟合是指模型在训练数据上表现非常好,但在未见过的数据(例如测试集)上表现较差。
当模型过于复杂或过于专注于训练数据的细节和噪声时,容易发生过拟合。
过拟合的模型对训练数据“记忆”得过于深刻,以至于无法泛化到新的数据。
过拟合的模型在训练集上的性能通常很好,但在测试集上的性能会显著下降。
正确拟合(Good Fitting):
正确拟合是指模型在训练数据上表现良好,并且在未见过的数据上也有良好的泛化能力。
正确拟合的模型能够捕捉到数据中的重要特征,同时忽略掉噪声和细节,从而在测试集上表现出色。
实现正确拟合通常需要选择合适的模型复杂度、使用正则化技术、进行交叉验证等。
为了避免欠拟合和过拟合,机器学习工程师通常会使用交叉验证来选择最佳的模型复杂度,或者使用正则化技术(如L1正则化、L2正则化或dropout)来限制模型的复杂度。同时,选择合适的特征、使用集成学习等方法也有助于提高模型的泛化能力,实现正确拟合。
5.3 专业技术指标
正样本和负样本是机器学习和数据分析中常用的概念,特别是在分类任务中。它们的主要区别在于它们与某个特定类别或目标的关联程度。
正样本(Positive Sample)是指属于目标类别的样本。在分类问题中,正样本是我们想要分类器识别出来的目标对象。以图片分类为例,如果目标是识别出图片中的猫,那么包含猫的图片就是正样本。简而言之,正样本是与真值对应的目标类别相匹配的样本。
负样本(Negative Sample)则是指不属于目标类别的样本。在同样的图片分类任务中,如果目标是识别猫,那么不包含猫的图片就是负样本。负样本是与真值不对应的其他所有目标类别。它们对于训练分类器同样重要,因为它们帮助分类器区分目标类别和非目标类别。
值得注意的是,在某些特定的任务中,如目标检测或物体识别,正样本可能指的是包含特定物体的图像区域,而负样本则是不包含该物体的区域或整个图像。此外,随着模型训练的进行,还可能出现所谓的“难分样本”,这些样本在初始阶段可能被错误分类,但在后续的训练中可以通过特定的策略(如“难例挖掘”)进行优化。
准确率、精准率、召回率
T(True)/F(False)/P(Positive)/N(Negatives)
TP(真正例):检测是正样本,实际是正样本
FP(假正例):检测是正样本,实际是负样本
TN(真负例):检测是负样本,实际是负样本
FN(假负例):检测是负样本,实际是正样本
GT(groud truth):样本真实值,在目标检测中 GT=TP+FN
accuracy = TP+TN/(TP+FP+TN+FN)
precision=TP/TP+FP
recall=TP/TP+FN=TP/GT
PR 曲线就是以精确率为纵坐标,以召回率为横坐标做出的曲线
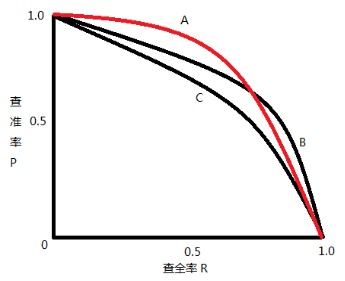
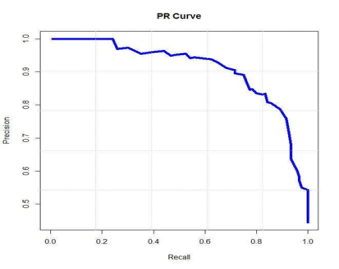
F1值,是指该模型查全率与查准率的调和均值:
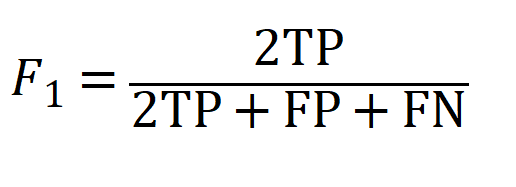
结语:课后请大家熟悉anaconda的安装方法、jupyter notebook的使用。以及了解Scikit-Learn 相关包等。
Scikit-Learn是基于 Python 语言的机器学习工具。它建立在 NumPy, SciPy, Pandas 和 Matplotlib 之上,里面的 API 的设计非常好,所有对象的接口简单,很适合新手上路。





























![BUUCTF:BUU UPLOAD COURSE 1[WriteUP]](https://img-blog.csdnimg.cn/direct/2c7d380ac2e54411bfeb87b32d215d51.png)