文心一言
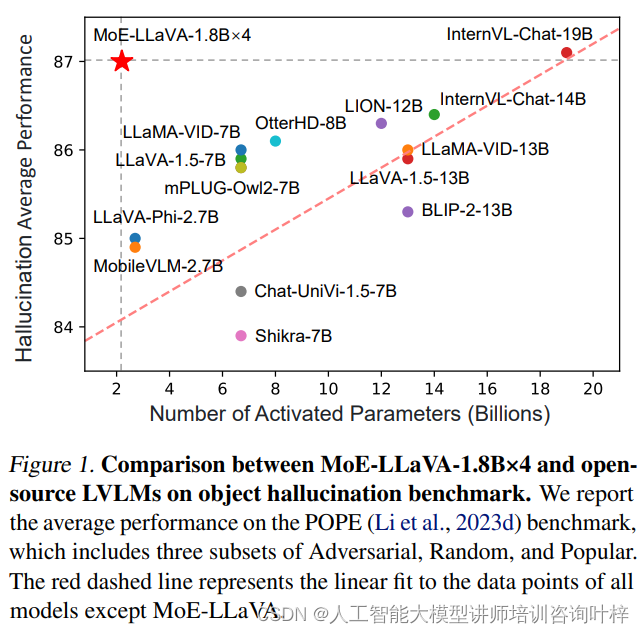
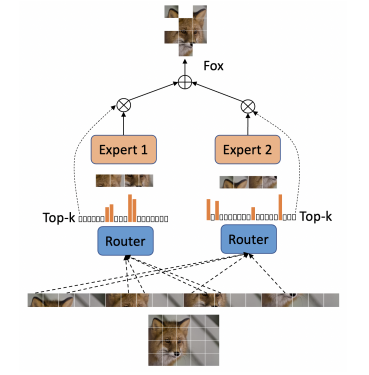
混合专家(Mixture of Experts,MoE)模型是一种机器学习架构,它结合了多个专家模型(或子模型)以处理不同的输入数据或任务。每个专家模型在其特定领域内表现出色,而MoE模型则负责根据输入数据的特点选择最合适的专家模型。这种架构可以显著提高模型的性能和泛化能力。
以下是一个简单的混合专家(MoE)模型示例:
假设我们有一个自然语言处理任务,需要对输入的句子进行情感分析(判断句子是积极、消极还是中性)。在这个任务中,我们可以使用MoE模型来集成多个情感分析专家模型。
- 专家模型:我们训练了三个情感分析专家模型,分别擅长处理不同类型的句子。第一个专家模型擅长处理包含积极词汇的句子,第二个专家模型擅长处理包含消极词汇的句子,而第三个专家模型则擅长处理中性或难以判断的句子。
- 门网络:MoE模型中包含一个门网络(Gating Network),它的作用是根据输入句子的特点来选择最合适的专家模型。门网络可以是一个简单的神经网络,它接受输入句子作为输入,并输出一个概率分布,表示每个专家模型被选择的概率。
- 集成输出:一旦门网络确定了每个专家模型的权重,MoE模型就会根据这些权重将各个专家模型的输出进行集成。这可以通过加权平均或其他方式来实现,以得到最终的情感分析结果。
这个示例展示了MoE模型的基本工作原理:通过将多个专家模型与门网络相结合,MoE模型可以根据输入数据的特点动态地选择合适的专家模型进行处理,从而提高模型的性能和泛化能力。
需要注意的是,MoE模型的性能取决于多个因素,包括专家模型的数量、门网络的设计以及训练数据的质量和数量等。因此,在实际应用中,需要根据具体任务和数据集的特点来设计和调整MoE模型的结构和参数。

讯飞星火
混合专家(Mixture-of-Experts,MoE)模型的示例通常涉及多个组件:专家层、门控机制(gating mechanism)和可选的软硬注意力机制。以下是构建一个基本的MoE模型的高层次步骤,以及如何将其应用于实际问题的一个简化例子。
构建基本MoE模型的步骤:
定义专家层:
- 选择专家的数量和每个专家的结构(如前馈神经网络、卷积神经网络等)。
- 确定专家网络之间的共享方式,比如是否共享参数。
设计门控机制:
- 门控机制负责决定输入数据分配给各个专家的概率。
- 这通常是一个额外的神经网络,它接受相同的输入并输出一个概率分布。
集成专家的预测:
- 根据门控机制的输出,将输入数据适当地分配给专家网络。
- 集成各专家的预测结果以产生最终输出。
训练模型:
- 使用反向传播和梯度下降方法来训练整个模型,包括专家和门控机制。
- 可能需要特殊算法,如软或硬注意机制,来优化门控的分配。
应用示例:
假设我们有一个多分类问题,需要根据不同的输入特征来决定属于哪一类。这个问题可以借助MoE框架来解决:
准备数据集:
- 收集和预处理数据,确保它适合用于训练MoE模型。
定义专家网络:
- 设定两个专家网络,每个网络专门处理特定类型的特征集。
- 专家1可能擅长处理数值特征,而专家2更擅长处理文本特征。
设计门控网络:
- 创建一个门控网络,它将基于输入数据的特征动态地决定哪个专家应该对每个数据点进行预测。
训练模型:
- 使用适当的损失函数(如交叉熵)来反映模型在多分类任务上的性能。
- 通过调整专家和门控网络的权重来最小化损失函数。
评估和应用:
- 使用测试数据来评估模型的性能。
- 将训练好的模型部署到实际应用中,以对新的数据点进行分类。
请注意,上述过程是一个高层次的描述,实现一个MoE模型需要深入的技术细节和对机器学习库(如TensorFlow或PyTorch)的理解。此外,MoE模型的设计和训练是高度依赖具体应用场景和数据的。

ChatGPT
混合专家(Mixture of Experts, MoE)是一种机器学习架构,它结合了多个专家模型的建议来进行决策。在一个标准的MoE模型中,有一个门控网络(gating network)和一组专家网络(expert networks)。门控网络负责为每个专家分配权重,表明每个专家对当前输入的重要性。每个专家网络则负责处理一部分输入空间,捕捉某些特定模式。最终的预测是根据门控网络分配的权重对所有专家的预测进行加权求和得到的。
下面是在一个简化的深度学习框架中实现的MoE模型的示例(使用假设的代码,仅为说明概念):
import numpy as np# 假设的专家网络类
class ExpertNetwork:
def __init__(self, input_size, output_size):
# 初始化专家网络的参数
pass
def forward(self, x):
# 对输入x进行处理,返回输出
# 这里使用一些深度学习操作
return x
# 假设的门控网络类
class GatingNetwork:
def __init__(self, input_size, num_experts):
# 初始化门控网络的参数
pass
def forward(self, x):
# 对输入x进行处理,返回每个专家的权重
# 使用softmax来确保权重和为1
weights = np.random.rand(num_experts) # 这里是随机权重,实际中需要计算
return weights / weights.sum()
# MoE模型
class MixtureOfExperts:
def __init__(self, input_size, output_size, num_experts):
self.gating_network = GatingNetwork(input_size, num_experts)
self.experts = [ExpertNetwork(input_size, output_size) for _ in range(num_experts)]
def forward(self, x):
# 计算每个专家的权重
weights = self.gating_network.forward(x)
# 计算每个专家的输出
expert_outputs = [expert.forward(x) for expert in self.experts]
# 计算最终输出
output = sum(weight * expert_output for weight, expert_output in zip(weights, expert_outputs))
return output
# 使用MoE模型
input_size = 10
output_size = 1
num_experts = 3
# 创建MoE模型实例
moe_model = MixtureOfExperts(input_size, output_size, num_experts)
# 输入数据
x_input = np.random.rand(input_size)
# 运行模型获得输出
output = moe_model.forward(x_input)
print("MoE output:", output)请注意,这个代码只是为了解释MoE模型的工作原理,在特定深度学习框架中,实现会有所不同,且需要包含参数优化和反向传播等部分。在实际应用中,专家网络和门控网络通常是通过深度神经网络实现的,而且需要经过训练来确定它们的参数。

混合专家(Mixture of Experts, MoE)模型是一种机器学习模型,它包含多个"专家"网络(通常是神经网络),和一个"门控"网络,用于决定在给定的输入下哪些专家被赋予多少权重。每个专家都是专门处理某一特定类型的数据或任务的网络。门控网络的职责是学习输入特征,并根据这些特征为每个专家分配权重,以优化整个系统的性能。
对于Hugging Face的`transformers`库中提到的`qwen2_moe`,这里的“MoE”即指混合专家模型。模型的名称“Qwen1.5-MoE-A2.7B-Chat”中,"1.5"可能是版本号,“A2.7B”表示大约有2.7十亿个参数,“Chat”说明这个模型针对对话或聊天任务进行了优化。这种类型的模型会结合多个专家的能力,尝试在聊天或对话任务中获得更好的效果。
在此情境下提到的“量化模型”,涉及到模型量化技术,这是一种用于压缩模型大小和提升推理速度的方法。它通过减少模型的权重和激活函数所使用的计算精度(比如,从32位浮点数降低到8位整数)来实现。这样做虽然可能会引入一些精度损失,但它可以大幅减少模型的存储需求和计算资源消耗,使得模型更容易部署在资源受限的环境中,例如在移动设备或者边缘计算设备上。
例如,“Qwen1.5-MoE-A2.7B-Chat-GPTQ-Int4”中的“GPTQ-Int4”就表示这是一个四位整数的量化版本,这可能使用了技术如Gradient-based Post-Training Quantization(GPTQ),用于在训练之后量化模型,以在尽可能少损失精度的情况下减少模型的大小。"AWQ"可能指的是一种不同的量化方法,但根据您的描述,它暂时不可用。

通义灵码
混合专家(MoE)模型的具体实现可以因应用场景和编程框架的不同而有所差异。这里给出一个基于深度学习框架PyTorch的简化示例,以说明MoE模型的基本结构和工作流程。我们将构建一个包含两个专家网络和一个门控网络的简单MoE模型。
import torch
import torch.nn as nn
class ExpertNetwork(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(ExpertNetwork, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
class GateNetwork(nn.Module):
def __init__(self, input_size, num_experts):
super(GateNetwork, self).__init__()
self.fc = nn.Linear(input_size, num_experts)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
logits = self.fc(x)
gates = self.softmax(logits)
return gates
class MixtureOfExperts(nn.Module):
def __init__(self, num_experts, input_size, hidden_size, output_size):
super(MixtureOfExperts, self).__init__()
self.experts = nn.ModuleList([ExpertNetwork(input_size, hidden_size, output_size) for _ in range(num_experts)])
self.gate = GateNetwork(input_size, num_experts)
def forward(self, x):
# Compute gating probabilities for each expert
gates = self.gate(x)
# Forward pass through each expert network
expert_outputs = [expert(x) for expert in self.experts]
# Weighted sum of expert outputs according to gate probabilities
combined_output = torch.stack(expert_outputs, dim=-1) * gates.unsqueeze(-1)
combined_output = combined_output.sum(dim=-1)
return combined_output
# Example usage:
model = MixtureOfExperts(num_experts=2, input_size=100, hidden_size=50, output_size=10)
input_data = torch.randn((batch_size, input_size))
output = model(input_data)在这个示例中:
定义了一个
ExpertNetwork类作为基础专家网络结构,包含两层全连接(FC)层和ReLU激活函数。GateNetwork类负责计算输入数据对应于各个专家的权重(门控概率)。它接受相同维度的输入,并通过一个全连接层后接softmax函数输出概率分布。MixtureOfExperts类整合了专家网络和门控网络,创建了指定数量的专家实例,并定义了模型的整体前向传播逻辑。在前向传播中:a. 使用门控网络计算每个样本对各个专家的信任度(门控概率)。 b. 将输入数据传递给每个专家网络,得到各专家的输出。 c. 根据门控概率对专家输出进行加权求和,得到最终的模型输出。
接下来,我们可以进一步完善这个示例,包括:
损失函数与优化器设置:为模型定义适当的损失函数(例如,分类任务使用交叉熵损失,回归任务使用均方误差损失),并配置优化器(如Adam、SGD等)用于模型参数更新。
训练循环:编写一个训练循环,包括前向传播、计算损失、反向传播、梯度更新等步骤。还可以考虑加入验证和测试阶段,评估模型在未见过数据上的性能。
实际应用:如果需要,可以展示如何使用训练好的MoE模型对新数据进行预测。
以下是上述内容的一个简要示例:
import torch.optim as optim
# 假设这是一个二分类任务,使用交叉熵损失
loss_fn = nn.CrossEntropyLoss()
# 使用Adam优化器,学习率为0.001
optimizer = optim.Adam(model.parameters(), lr=0.001)
def train(model, dataloader, loss_fn, optimizer):
model.train()
running_loss = 0.0
for inputs, targets in dataloader:
optimizer.zero_grad() # 清零梯度
outputs = model(inputs)
loss = loss_fn(outputs, targets)
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型参数
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(dataloader.dataset)
print(f"Epoch Loss: {epoch_loss:.4f}")
# 训练循环示例
num_epochs = 10
for epoch in range(num_epochs):
train(model, train_dataloader, loss_fn, optimizer)
# 可在此处添加验证和测试阶段的代码
# 使用训练好的模型进行预测
model.eval()
with torch.no_grad():
predictions = model(test_inputs)请注意,以上代码仅为示例性质,实际应用时需根据具体任务需求(如数据预处理、数据加载方式、模型参数调整、早停策略、模型保存与加载等)进行相应的定制和优化。此外,为了充分利用MoE模型的优势,建议在大数据集上进行训练,并适当增大专家数量以探索更多专业知识的划分。

PyTorch 是一个灵活且强大的深度学习框架,非常适合用来构建混合专家(Mixture of Experts, MoE)模型。下面是一个使用 PyTorch 构建 MoE 模型的示例代码:
import torch
import torch.nn as nn
class Expert(nn.Module):
"""
单个专家网络,此处以简单的全连接网络为例。
可根据实际任务需求替换为其他类型的神经网络结构。
"""
def __init__(self, input_dim, hidden_dim, output_dim):
super(Expert, self).__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, output_dim)
)
def forward(self, x):
return self.fc(x)
class GatingNetwork(nn.Module):
"""
门控网络,用于确定每个样本应分配给各个专家的权重。
"""
def __init__(self, input_dim, num_experts):
super(GatingNetwork, self).__init__()
self.fc = nn.Linear(input_dim, num_experts)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
logits = self.fc(x)
gates = self.softmax(logits)
return gates
class MixtureOfExperts(nn.Module):
"""
混合专家模型,包含多个专家网络和一个门控网络。
"""
def __init__(self, num_experts, input_dim, hidden_dim, output_dim):
super(MixtureOfExperts, self).__init__()
self.experts = nn.ModuleList([Expert(input_dim, hidden_dim, output_dim) for _ in range(num_experts)])
self.gate = GatingNetwork(input_dim, num_experts)
def forward(self, x):
gates = self.gate(x)
expert_outputs = torch.stack([expert(x) for expert in self.experts], dim=-1)
weighted_outputs = gates.unsqueeze(-1) * expert_outputs
mixture_output = weighted_outputs.sum(dim=-1)
return mixture_output
# 示例:创建一个包含2个专家的MoE模型,每个专家都是一个全连接网络
model = MixtureOfExperts(num_experts=2, input_dim=100, hidden_dim=50, output_dim=10)
# 假设有一个批量输入数据
input_data = torch.randn((batch_size, input_dim))
# 通过模型进行前向传播
outputs = model(input_data)在这个示例中:
定义了一个
Expert类作为单个专家网络,本例中使用的是一个包含两层全连接层和 ReLU 激活函数的简单网络结构。你可以根据实际任务需求替换为卷积神经网络(CNN)、循环神经网络(RNN)或其他合适的网络结构。GatingNetwork类负责计算输入数据对应于各个专家的权重(门控概率)。它接受相同维度的输入,通过一个线性层后接 softmax 函数输出概率分布。MixtureOfExperts类整合了多个专家网络和一个门控网络。它在构造函数中创建指定数量的Expert实例,并定义了模型的前向传播逻辑。在前向传播中:a. 使用门控网络计算每个样本对各个专家的信任度(门控概率)。
b. 将输入数据传递给每个专家网络,得到各专家的输出。
c. 根据门控概率对专家输出进行加权求和,得到最终的模型输出。
最后,我们创建了一个包含两个专家的 MoE 模型实例,并演示了如何使用该模型对一批输入数据进行前向传播计算。这个例子展示了如何在 PyTorch 中构建一个基础的混合专家模型。实际应用中,还需要根据具体任务进行数据预处理、损失函数定义、优化器选择、训练循环编写等后续步骤。