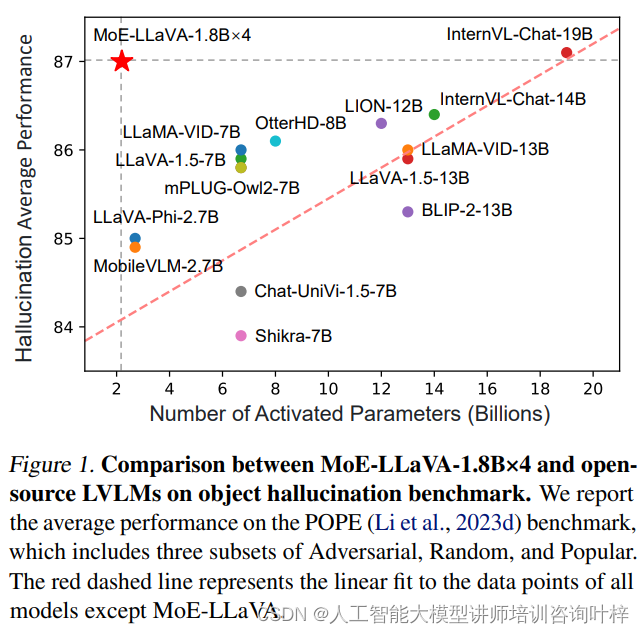
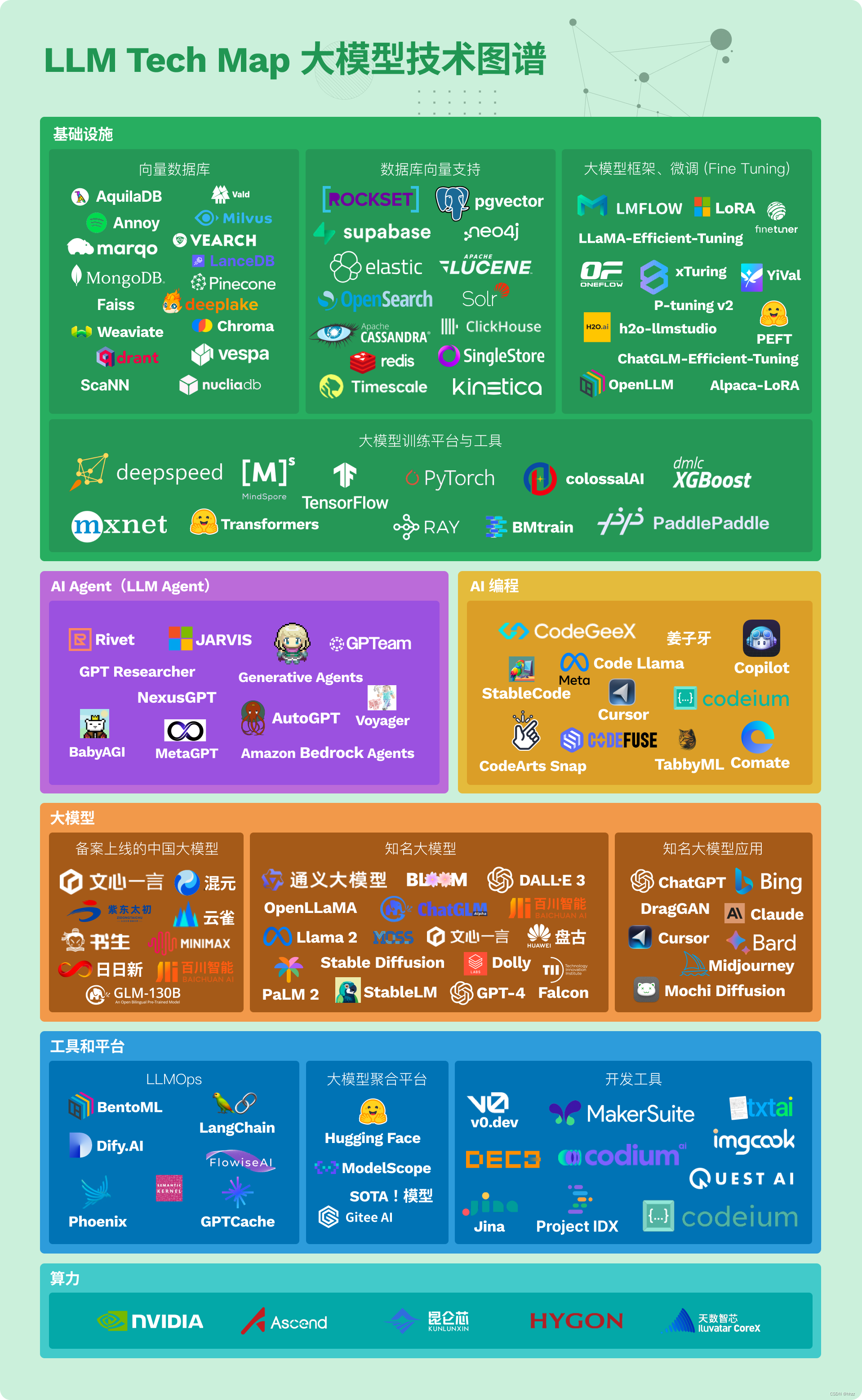
引言
本文主要想梳理一下 MoE 模型相关的概念,并阅读整理部分开源 MoE 模型的论文,简要地描述整体架构等。
概念
关于MoE 模型详解的部分主要参考了这篇文章 混合专家模型 (MoE) 详解。
Transformer 和 MoE
先回顾一下 Transformer 架构
- Transformer 完整结构由若干个 Block 组成
- 每个 Block 中包含了编码器 Encoder 和解码器 Decoder
- Encoder 和 Decoder 都包含4个部分:注意力层 Attention、位置感知前馈层 FNN、残差连接 Add 和层归一化 Norm
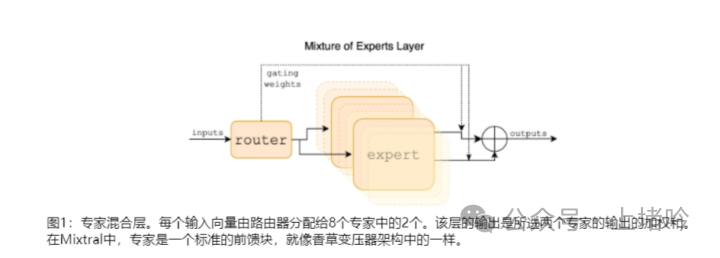
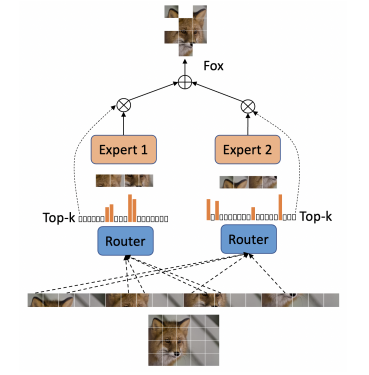
 混合专家模型 (MoE) 是一种基于 Transformer 架构的模型,主要是由两个关键部分组成:
混合专家模型 (MoE) 是一种基于 Transformer 架构的模型,主要是由两个关键部分组成:
- 稀疏 MoE 层:代替了 Transformer 架构中的前馈层 FNN。MoE 层包含了多个专家,每个专家可以是一个独立的神经网络,通常是前馈网络 FNN,但也可以是更复杂的网络结构,甚至可以是 MoE 层本身。
- 门控网络或路由:这部分决定 token 被发送到哪个专家。一个令牌可以被发送到多个专家,路由器由学习的参数组成,并与网络的其他部分一起进行预训练。

稀疏性
在传统的 Transformer 稠密模型中,所有参数都会对所有输入数据进行处理;相比而言,MoE 稀疏模型支持仅对整个系统的某些特定部分执行计算,即可以根据输入的特定特征或需求,只运行和调用部分参数,这被称为条件计算。
22年的一篇论文,指出了 Transformer 模型中 FFNs 也存在稀疏性激活问题。换句话说,对于单个输出,只有 FFNs 中一小部分神经元被激活(引用自 MoEfication: Transformer Feed-forward Layers are Mixtures of Experts )。为了验证这个结论,作者将 Transformer 中的 FNNs 层分割成多个专家,称作 MoEfication,比较重要的主要是两点:
专家分割:将 FFNs 分割成多个功能区作为专家,这里主要提供了两种方法
- 参数聚类分割:使用平衡 K-Means (Balanced K-Means) 算法对神经元向量做聚类
- 共激活图分割:构建共激活图 (Co-activation Graph)
专家选择:这部分主要决定如何选择专家,这里没有使用典型的 MoE 门控网络,只是浅谈一下
- Groundtruth Selection:用贪婪算法计算每个专家的得分,然后选得分最高的专家
- Similarity Selection:用余弦距离做近似计算,选出最近似的
- MLP Selection (推荐):训练多层感知器 (MLP),预测每个专家中激活神经元的总和并将其作为得分

门控网络
但这里还需要注意一点的是,需要对专家进行负载均衡,以防止不均匀分配和资源利用效率不高的问题。这可以通过一个可学习的门控网络 (G) 来决定要发送给哪些专家 (E):
y=∑i=1nG(x)iEi(x)y=\sum^n_{i=1}G(x)_iE_i(x)y=∑i=1nG(x)iEi(x)
典型的可学习的门控网络 (G) 通常是带有 softmaxsoftmaxsoftmax 函数的网络(返回每个输出分类的结果和概率),但默认的 softmaxsoftmaxsoftmax 函数是返回所有结果,即返回所有专家和概率。在这种情况下可以再引入一些可调整的噪声,然后保留k个值,公式如下。 (引用自 Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer )
H(x)i=(xWg)∗i+StandardNormal()∗SoftPlus((xW∗noise)i)H(x)_i =(xW_g)*i + StandardNormal()SoftPlus((xW{noise})_i)H(x)i=(xWg)∗i+StandardNormal()∗SoftPlus((xW∗noise)i)
G(x)=Softmax(KeepTopK(H(x),k))G(x)=Softmax(KeepTopK(H(x), k))G(x)=Softmax(KeepTopK(H(x),k))
最后还需要注意的是,在训练 MoE 模型的过程中,因为受欢迎的专家训练的更快,所以门控网络往往更倾向于主要激活相同的几个专家,使得这种情况自我加强。为了缓解这个问题,就需要引入一个辅助损失,从而确保所有专家接收大致相等数量的训练样本。在 transformers 库中,可以通过 aux_loss 参数来控制辅助损失。
💡 稀疏混合专家模型 (MoE) 更适用于有多台机器且要求高吞吐量的场景;相反,显存较少且吞吐量低的场景更适合用稠密Transfomer模型
GShard:Top-2 门控
谷歌使用 MoE 架构将模型的参数量扩展到了 6000亿。 (引用自 GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding )
GShard 将编码器和解码器中的每个前馈网络层(FNN)替换为一个 Top-2 门控网络的 MoE 层。简而言之,token 进入 MoE 层之后,通过门控网络选出 Top-2 的专家进行处理,每个专家都是 Transformer 架构的稠密模型。

GShard 还引入了一下关键变化:
- 随机路由:Top-2选择中,第一个专家是排名最高的,第二个专家是根据其权重比例随机选择的
- 专家容量:设定阈值来定义专家能处理多少个 token。如果两个专家的容量都达到上限,令牌就会溢出,并通过残差链接传递到下一层,或在某些情况下被完全丢弃。所以 MoE 模型的专家容量决定了能处理的token长度。
Switch Transformers:单专家和专家容量
HuggingFace 上开源的 Switch Transformer 是模型是一个基于 google/flan-t5-large 模型改造的 MoE ,拥有2048个专家、1.6万亿参数的 MoE,专家容量64。Switch Transformer 中的每个专家是一个标准的 FFN,所以总的参数量是标准 Transformer 模型的 2048 倍。
(引用自 Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, 模型 google/switch-c-2048)

与 GShard 想法不同,Switch Transformers 对经典的 topK 门控进行了简化,采用了单专家策略,即一个token令牌只由一个专家执行,这种方法可以 ① 减少门控网络的计算负担 ② 每个专家的批量大小至少可以减半 ③ 降低通信成本 ④ 保持模型质量。
Switch Transformers也对专家容量进行了研究,建议容量将批次中的令牌数量均匀分配到各个专家,具体公式如下(注:Switch Transformers 在低容量因子 (例如 1 至 1.25) 下表现出色)
Expert Capacity=(tokens per batchnumber of experts)×capacity factorExpert\space{} Capacity = (\frac{tokens \space{}per\space{}batch}{number \space{}of\space{}experts})\times capacity\space{}factorExpert Capacity=(number of expertstokens per batch)×capacity factor
以开源模型为例,专家容量是64,专家数量是2048,假设容量因子是1,那么每个批次中的令牌数量是 131072。
DeepSeek-MoE:共享专家
这部分主要看一下国产开源的 MoE 模型,在 huggingface 上开源的模型包含164亿参数,共 64个路由专家、2个共享专家,每个令牌会匹配6个专家。(引用自 DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, 模型 deepseek-ai/deepseek-moe-16b-base , 微调代码 github.com/deepseek-ai…)

DeepSeek-MoE 引入了“细粒度/垂类专家”和“共享专家”的概念。
“细粒度/垂类专家” 是通过细粒度专家切分 (Fine-Grained Expert Segmentation) 将一个 FFN 切分成 mmm 份。尽管每个专家的参数量小了,但是能够提高专家的专业水平。
“共享专家”是掌握更加泛化或公共知识的专家,从而减少每个细粒度专家中的知识冗余,共享专家的数量是固定的且总是处于被激活的状态。
LLaMA-MoE:轻量化和可配化
LLaMA-MoE-v1 是基于 LLaMA2 的一个 MoE 模型。类似 MoEfication,LLaMA-MoE-v1 将 LLaMA2 模型中的前馈网络层 FFNs 分割为包含多个专家的 MoE,这导致LLaMA-MoE-v1中一个专家的参数比其他 MoE 模型要更小些。(引用 LLaMA-MoE: Building Mixture-of-Experts from LLaMA with Continual Pre-training, 模型 llama-moe, 代码库 github.com/pjlab-sys4n…)
对于分割方法,这里提供了随机(Random)、聚类(Clustering)、共激活图(Co-activation Graph)和梯度(Gradient)等等。
对于专家路由即门控网络部分, LLaMA-MoE-v1 实现了经典的 TopK 噪声门控,也实现了 Switch Transformer 中提出的单专家门控。

最后
为了帮助大家更好的学习人工智能,这里给大家准备了一份人工智能入门/进阶学习资料,里面的内容都是适合学习的笔记和资料,不懂编程也能听懂、看懂,所有资料朋友们如果有需要全套人工智能入门+进阶学习资源包,可以在评论区或扫.码领取哦)~
在线教程
- 麻省理工学院人工智能视频教程 – 麻省理工人工智能课程
- 人工智能入门 – 人工智能基础学习。Peter Norvig举办的课程
- EdX 人工智能 – 此课程讲授人工智能计算机系统设计的基本概念和技术。
- 人工智能中的计划 – 计划是人工智能系统的基础部分之一。在这个课程中,你将会学习到让机器人执行一系列动作所需要的基本算法。
- 机器人人工智能 – 这个课程将会教授你实现人工智能的基本方法,包括:概率推算,计划和搜索,本地化,跟踪和控制,全部都是围绕有关机器人设计。
- 机器学习 – 有指导和无指导情况下的基本机器学习算法
- 机器学习中的神经网络 – 智能神经网络上的算法和实践经验
- 斯坦福统计学习
😝有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓


人工智能书籍
- OpenCV(中文版).(布拉德斯基等)
- OpenCV+3计算机视觉++Python语言实现+第二版
- OpenCV3编程入门 毛星云编著
- 数字图像处理_第三版
- 人工智能:一种现代的方法
- 深度学习面试宝典
- 深度学习之PyTorch物体检测实战
- 吴恩达DeepLearning.ai中文版笔记
- 计算机视觉中的多视图几何
- PyTorch-官方推荐教程-英文版
- 《神经网络与深度学习》(邱锡鹏-20191121)
- …

😝有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓
第一阶段:零基础入门(3-6个月)
新手应首先通过少而精的学习,看到全景图,建立大局观。 通过完成小实验,建立信心,才能避免“从入门到放弃”的尴尬。因此,第一阶段只推荐4本最必要的书(而且这些书到了第二、三阶段也能继续用),入门以后,在后续学习中再“哪里不会补哪里”即可。

第二阶段:基础进阶(3-6个月)
熟读《机器学习算法的数学解析与Python实现》并动手实践后,你已经对机器学习有了基本的了解,不再是小白了。这时可以开始触类旁通,学习热门技术,加强实践水平。在深入学习的同时,也可以探索自己感兴趣的方向,为求职面试打好基础。

第三阶段:工作应用

这一阶段你已经不再需要引导,只需要一些推荐书目。如果你从入门时就确认了未来的工作方向,可以在第二阶段就提前阅读相关入门书籍(对应“商业落地五大方向”中的前两本),然后再“哪里不会补哪里”。


😝有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓