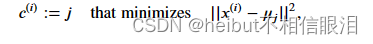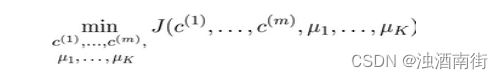K-means 初始化
首先 K < m,若集群的数量多于样本数显然是不合理的。
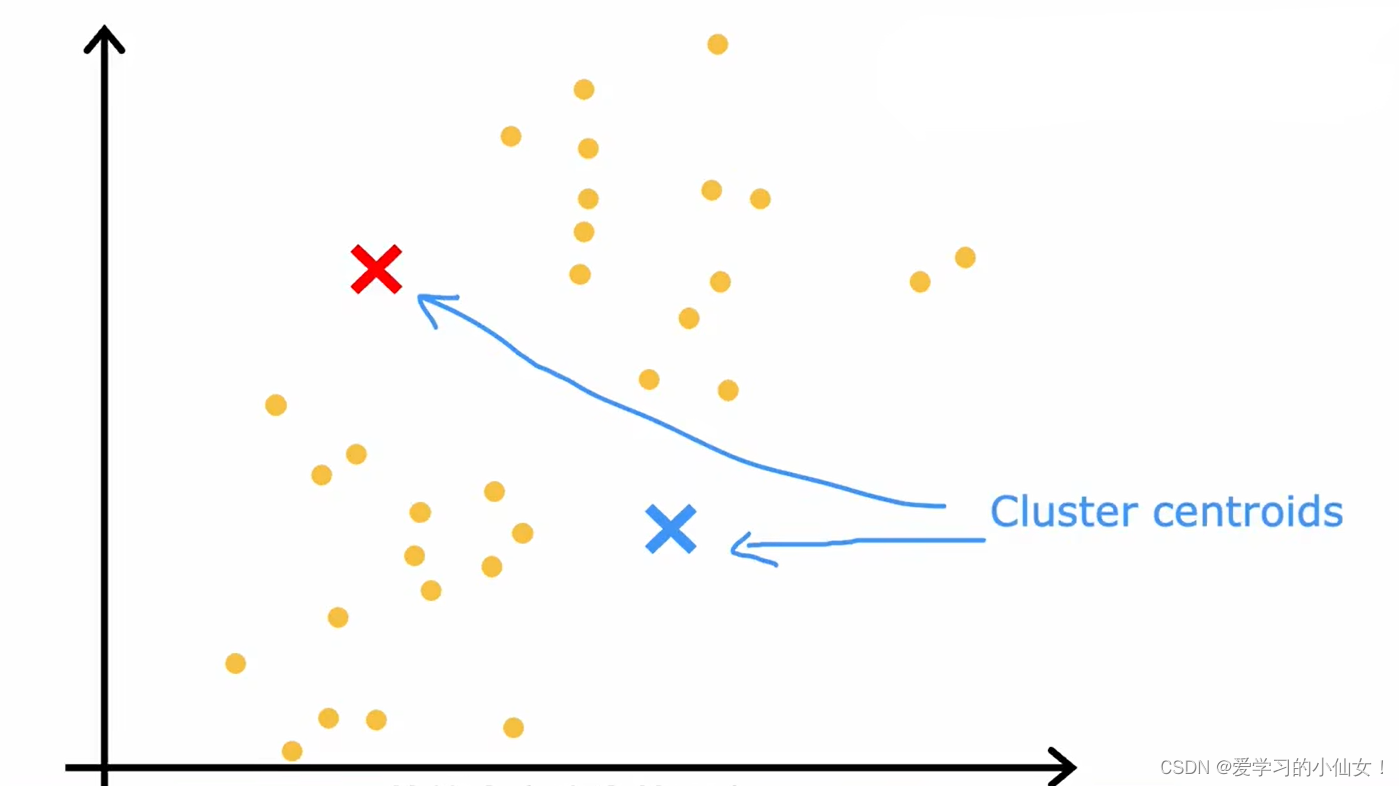
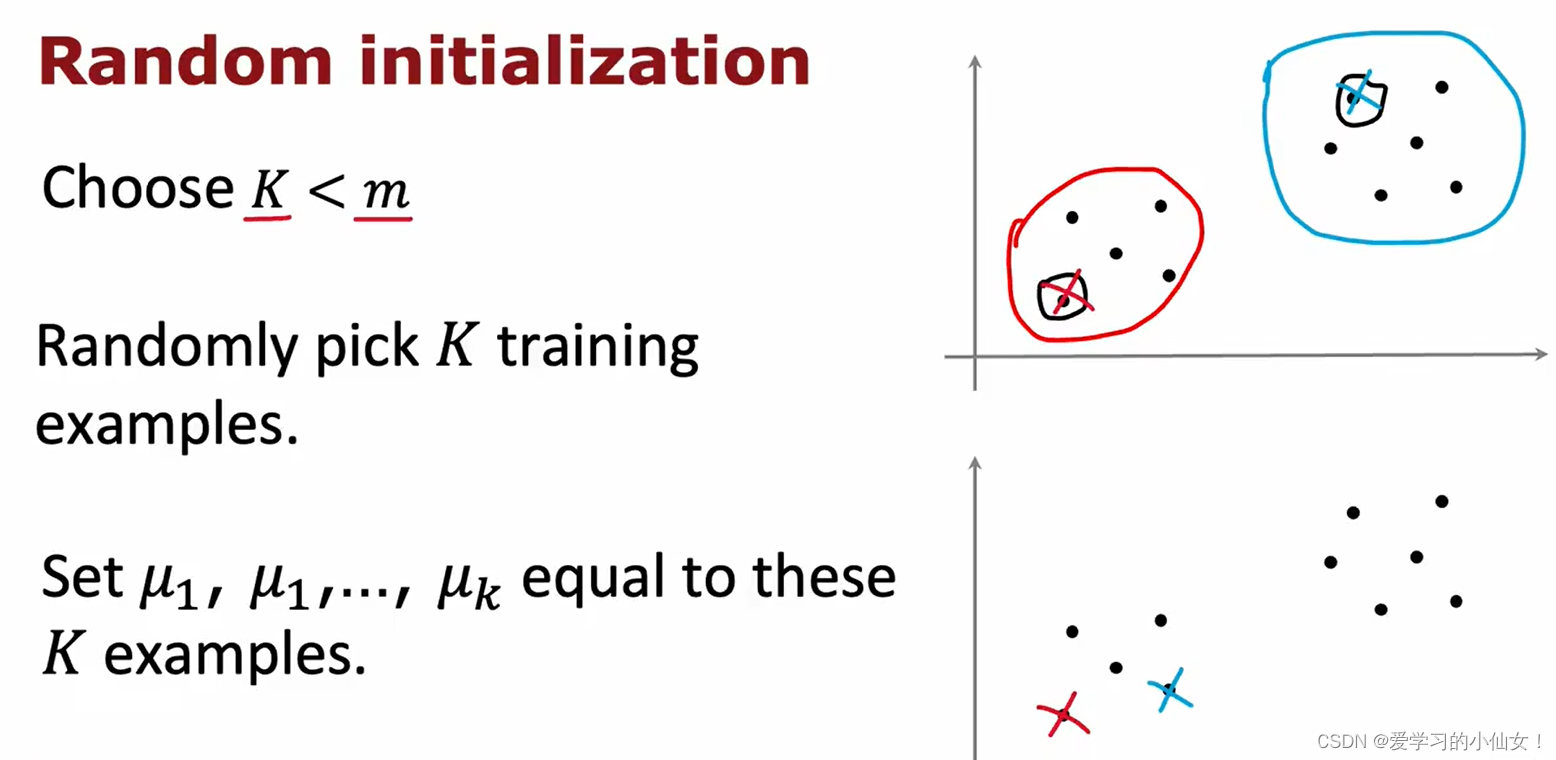
第一步:随机选取 K 个样本;
第二步:设这 K 个样本为 μ1 μ2 ... μk
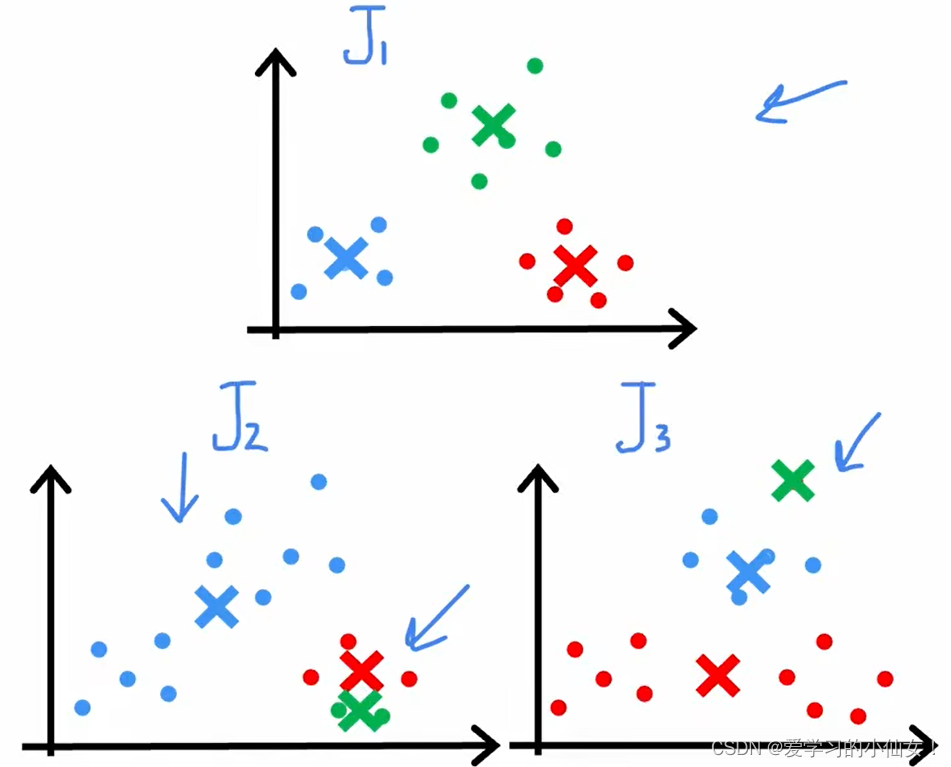
有时候K-meas 算法会出现局部最小值的情况,如左下图和右下图,因此应当多次运行 K-means 算法 ,取成本 J 最小的那个。
随机初始化的步骤如下,通常50-1000次是正常的,次数太多计算成本会很高。

聚类数量的选择
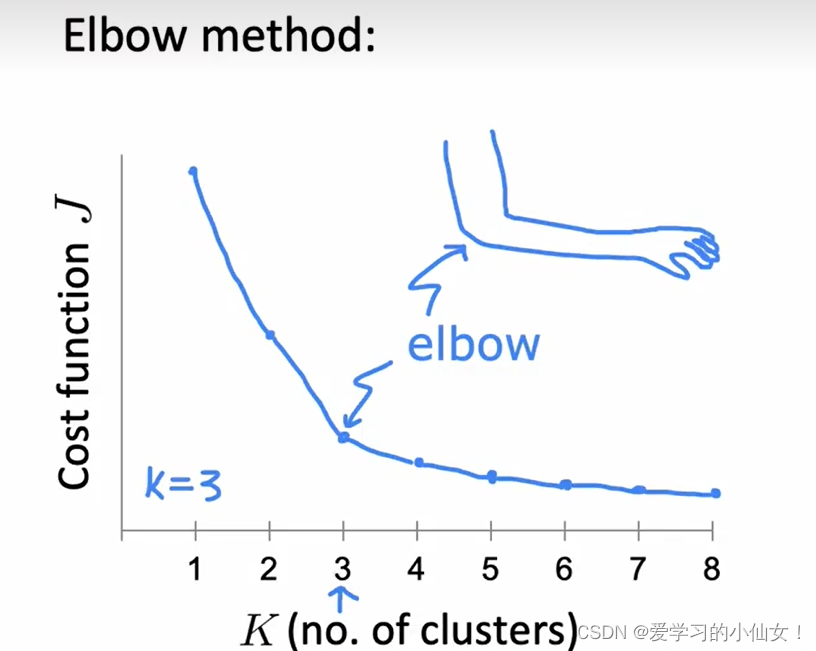
一种方法是肘方法(elbow method), 把 J 当做是集群数量 K 的函数,选择函数弯曲的地方(即手肘)作为 K 的值。
另一种方法是根据后续的工作进行评估 ,例如调整T恤衫的尺寸,可以分为三类,也可以分为五类,但两种情况下T恤衫的合适程度以及生产成本不同,需要根据这些进行选择。