聚类(clustering)是一种无监督学习算法,关注多个数据点并自动找到相似的数据点,在数据中找到一种特定的结构。无监督学习算法的数据集中没有标签 y ,所以不能说哪个是“正确的 y ”。
K-means算法
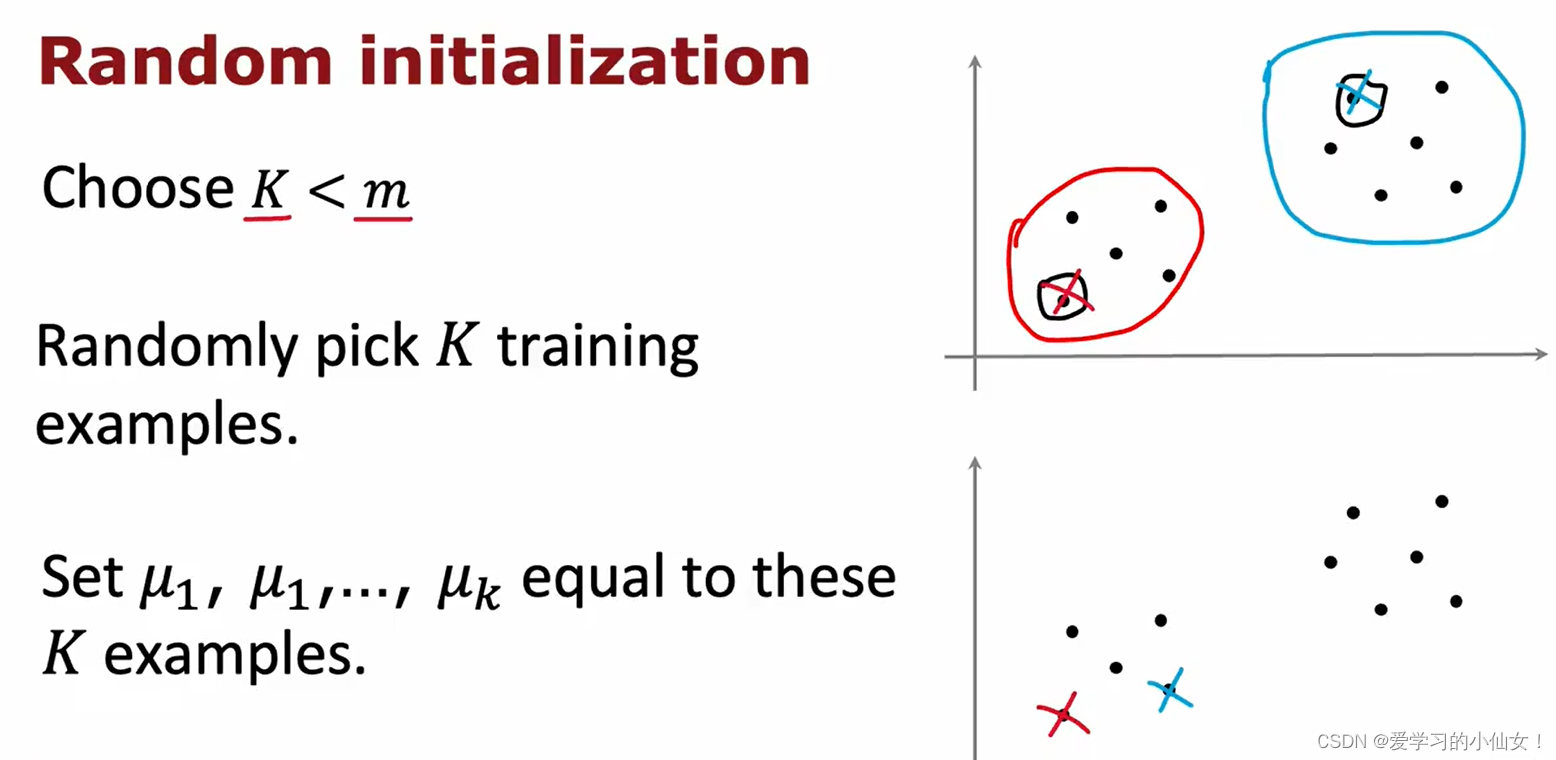
K-means算法就是在重复做两件事:一个是把点分配给集群质心,另一个是移动集群的中心。
例如,要求算法找到下图中的两个类,第一步随机选取两个地方,然后遍历每个点,看看它离那个更近
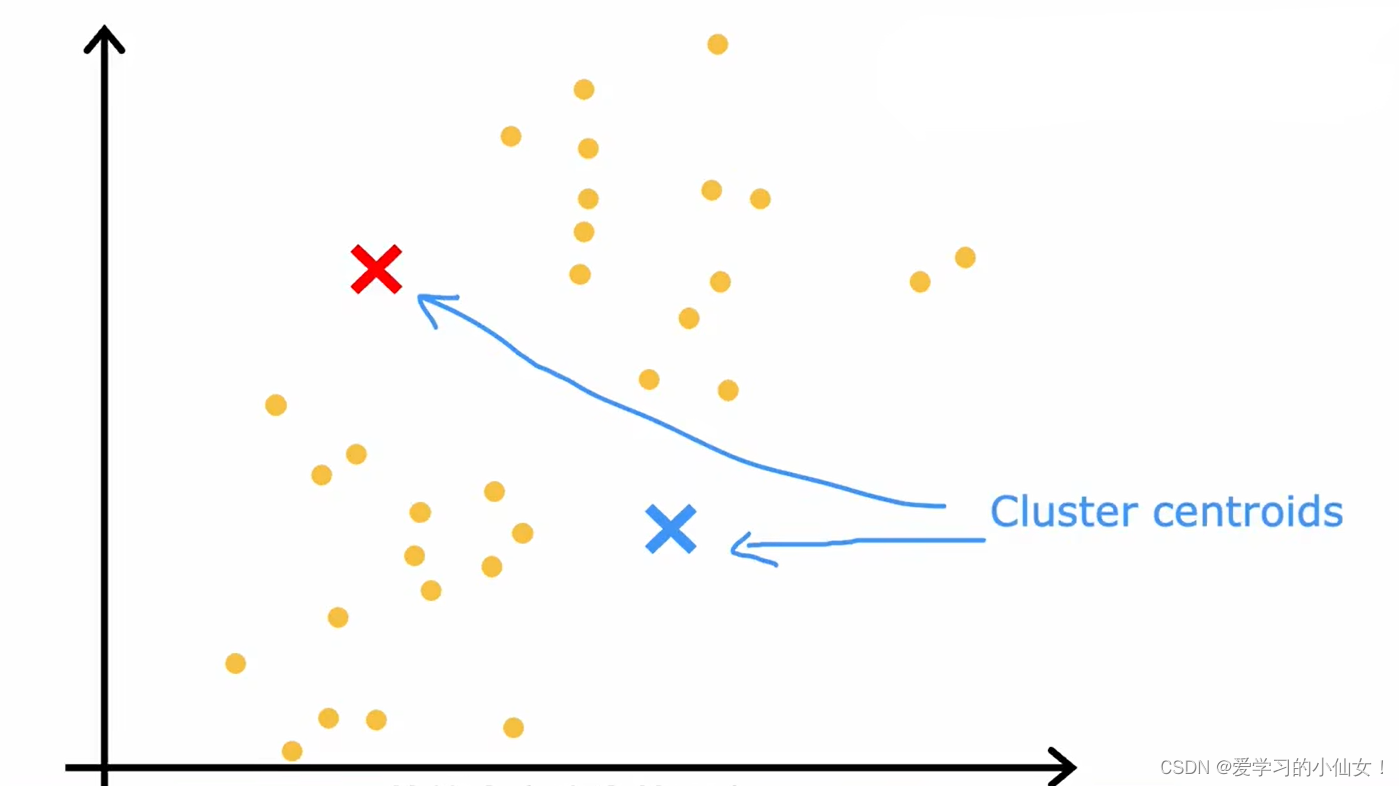
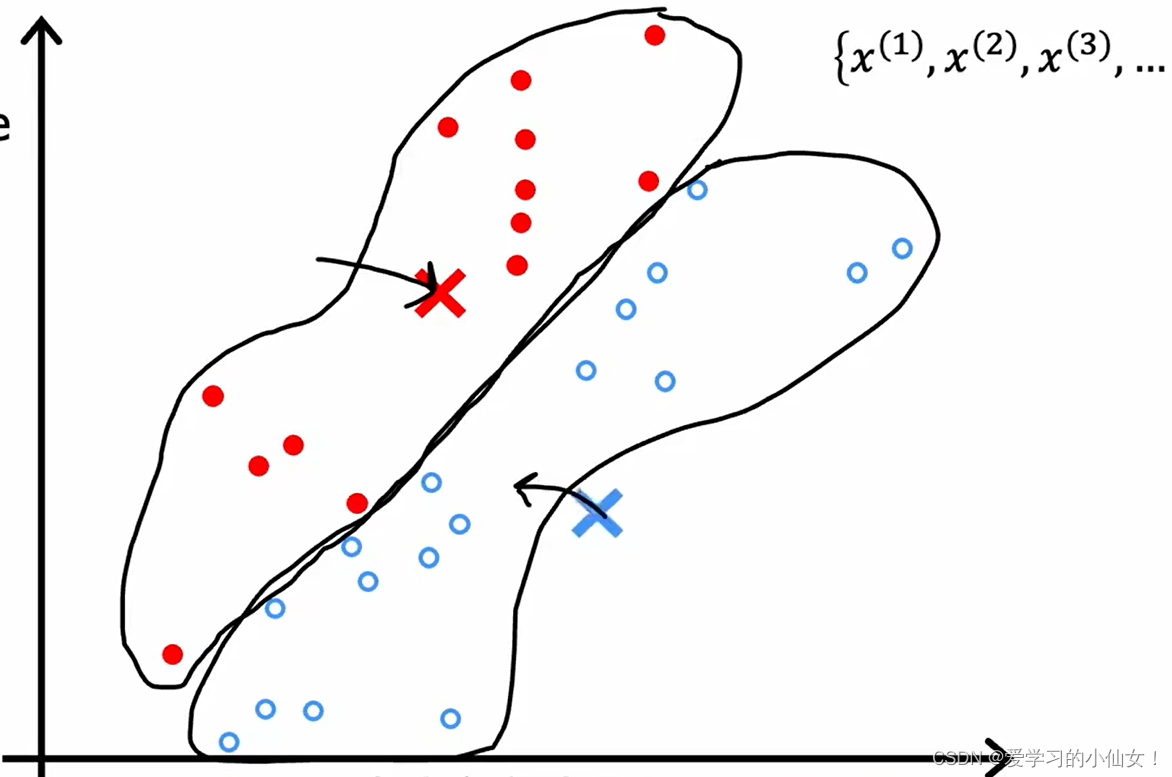
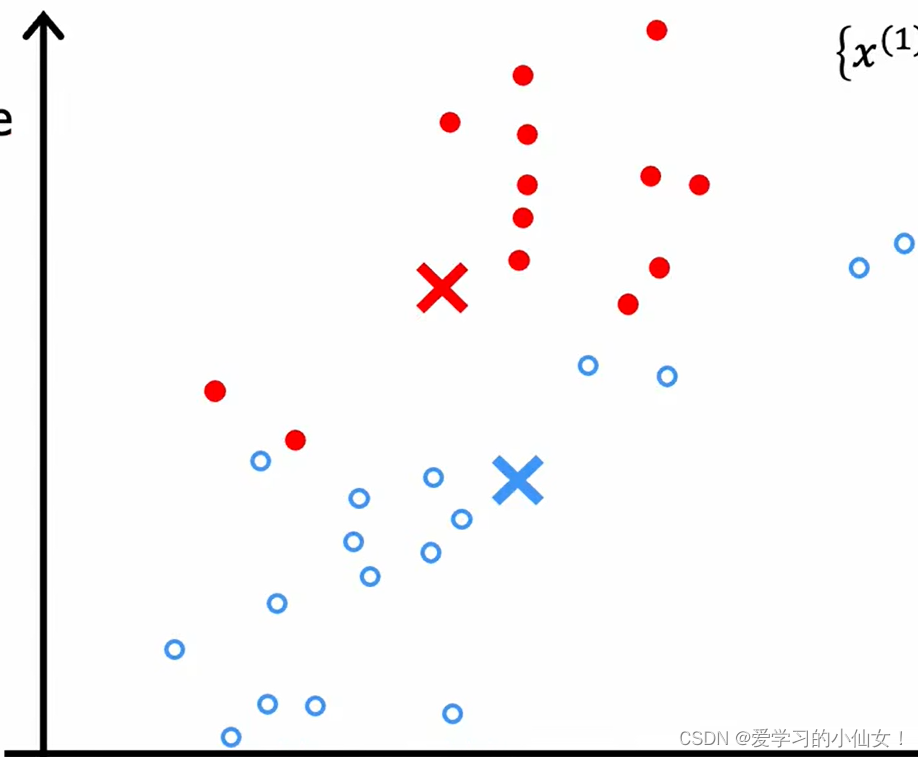
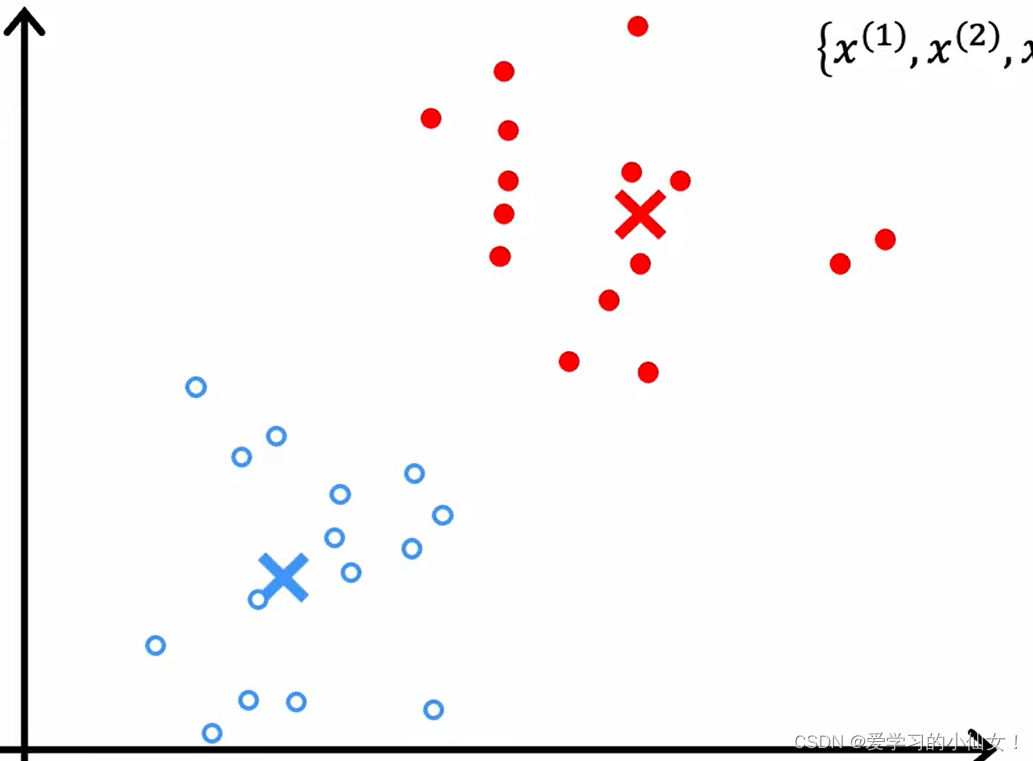
第二步:计算每个簇的中心,并把集群中心移动到这里,然后再次遍历每个点看看它离哪一个更近,然后重复,直到中心不再变化。
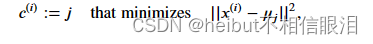





























![反序列化&动态调用 [NPUCTF2020]ReadlezPHP1 PHP assert 和 eval](https://img-blog.csdnimg.cn/direct/e3dd3b64fc7d423083817f48d2974ca4.png)