文章目录
这里的笔记均来自于极客时间的《AI大模型之美》课程,原课程中的代码大部分已无法正常运行并且已过时,这里我对其中的内容和代码进行了总结和优化,如果对原专栏感兴趣的朋友可以直接去相关专栏中学习:地址
1. 应用任务1:语义检索
Embedding 向量适合作为一个中间结果,用于传统的机器学习场景,比如分类、聚类。Completion 接口,一方面可以直接拿来作为一个聊天机器人,另一方面,只要善用提示词,就能完成合理的文案撰写、文本摘要、机器翻译等工作。
1.1 实验数据生成
并不是所有时候都能很快找到合适的数据集。这时也可以利用 AI 生成一些数据。然后将这些数据加载到一个 DataFrame 里。
from openai import OpenAI
import os
import pandas as pd
client = OpenAI(api_key = os.environ.get("OPENAI_API_KEY"))
COMPLETION_MODEL = "gpt-3.5-turbo-instruct"
def generate_data_by_prompt(prompt):
response = client.completions.create(
model=COMPLETION_MODEL,
prompt=prompt,
temperature=0.5,
max_tokens=2048,
top_p=1,
)
return response.choices[0].text
prompt = """请你生成50条淘宝网里的商品的标题,每条在30个字左右,品类是3C数码产品,标题里往往也会有一些促销类的信息,每行一条。"""
data = generate_data_by_prompt(prompt)
product_names = data.strip().split('\n')
df = pd.DataFrame({'product_name': product_names})
df.head() # 查看前5条数据
输出结果:
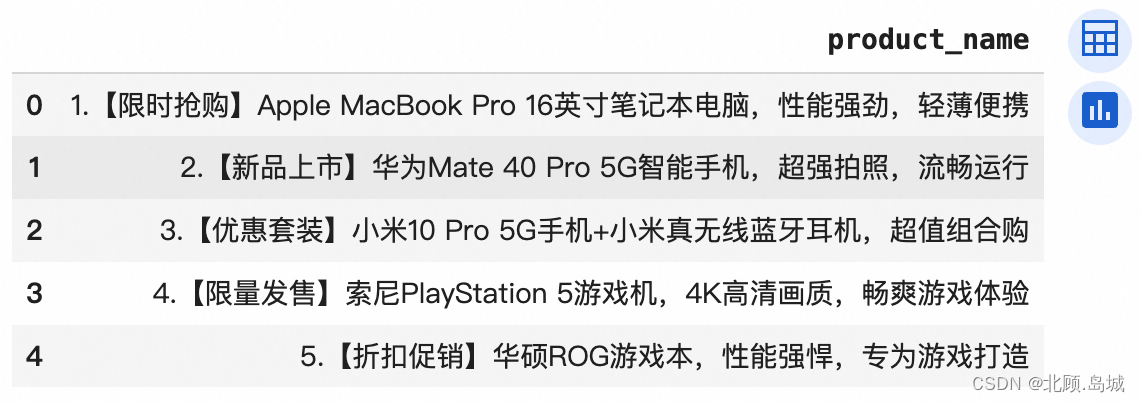
这里每一行都带上了一个标号,我们需要简单处理一下,去掉这个标号拿到一些干净的数据。
df.product_name = df.product_name.apply(lambda x: x.split('.')[1].strip())
df.head()
输出结果:

类似的,再生成一些女装的商品名称,覆盖不同的品类:
clothes_prompt = """请你生成50条淘宝网里的商品的标题,每条在30个字左右,品类是女性的服饰箱包等等,标题里往往也会有一些促销类的信息,每行一条。"""
clothes_data = generate_data_by_prompt(clothes_prompt)
clothes_product_names = clothes_data.strip().split('\n')
clothes_df = pd.DataFrame({'product_name': clothes_product_names})
clothes_df.product_name = clothes_df.product_name.apply(lambda x: x.split('.')[1].strip())
clothes_df.head()
输出结果:

把上面两个 DataFrame 拼接在一起,得到接下来用于做搜索实验的数据:
df = pd.concat([df, clothes_df], axis=0)
df = df.reset_index(drop=True)
display(df)
输出结果:

有时返回的数据没有50条,不过并不影响使用。
1.2 语义搜索
对于大部分中小公司,刚开始提供搜索功能的时候,往往是使用 Elasticsearch 这个开源项目。而 Elasticsearch 背后的搜索原理是先分词,然后再使用倒排索引。
以“气质小清新拼接百搭双肩斜挎包”这个商品名称为例,将其拆分成“气质”“小清新”“拼接”“百搭”“双肩”“斜挎包”几个词,对每个标题都做这样切分。之后,建立一个索引,比如“气质”这个词,出现过的标题的编号,都按编号顺序跟在气质后面。其他的词也类似。
当用户搜索的时候,比如用户搜索“气质背包”,也会拆分成“气质”和“背包”两个词。然后就根据这两个词,找到包含这些词的标题,根据出现的词的数量、权重等等找出一些商品。
这个策略有一个缺点,就是如果有同义词,那么这么简单地去搜索是搜不到的。比如,我们如果搜“自然淡雅背包”,虽然语义上很接近,但是因为“自然”“淡雅”“背包”这三个词在这个商品标题里都没有出现,所以就没有办法匹配上了。为了提升搜索效果,就得做更多的工程研发工作,比如做一个同义词表,把标题里出现的同义词也算上等等。
1.2.1 基于 Embedding 进行语义搜索
使用 OpenAI 的 Embedding 接口,可以把一段文本的语义表示成一段向量。如果我们把用户的搜索也通过 Embedding 接口变成向量,然后把它和所有的商品的标题计算一下余弦距离,找出离我们搜索词最近的几个向量。那最近的几个向量,其实就是语义和这个商品相似的,而并不一定需要相同的关键词。
(1)计算 Embedding
把随机生成出来的所有商品标题,都计算出来它们的 Embedding,然后存下来。还是利用 backoff 和 batch 处理,让代码能够容错,并且快速处理完这些商品标题。
import openai, os, backoff
from openai import OpenAI
client = OpenAI(api_key = os.environ["OPENAI_API_KEY"])
embedding_model = "text-embedding-ada-002"
batch_size = 100
def get_embeddings(list_of_text, model):
response = client.embeddings.create(input=list_of_text, model=model)
return [item.embedding for item in response.data]
@backoff.on_exception(backoff.expo, openai.RateLimitError)
def get_embeddings_with_backoff(prompts, model):
embeddings = []
for i in range(0, len(prompts), batch_size):
batch = prompts[i:i+batch_size]
embeddings += get_embeddings(list_of_text=batch, model=model)
return embeddings
prompts = df.product_name.tolist()
prompt_batches = [prompts[i:i+batch_size] for i in range(0, len(prompts), batch_size)]
embeddings = []
for batch in prompt_batches:
batch_embeddings = get_embeddings_with_backoff(prompts=batch, model=embedding_model)
embeddings += batch_embeddings
df["embedding"] = embeddings
df.to_parquet("data/taobao_product_title.parquet", index=False)
(2)计算相似度
定义一个 search_product 的搜索函数,接受三个参数,一个 df 代表用于搜索的数据源,一个 query 代表用于搜索的搜索词,然后一个 n 代表搜索返回多少条记录。
代码逻辑:
- 调用 OpenAI 的 API 将搜索词也转换成 Embedding。
- 将这个 Embedding 和 DataFrame 里的每一个 Embedding 都计算一下余弦距离。
- 根据余弦相似度排序,返回距离最近的 n 个标题。
import numpy as np
def get_embedding(text, model=embedding_model):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
def cosine_similarity(vector_a, vector_b):
dot_product = np.dot(vector_a, vector_b)
norm_a = np.linalg.norm(vector_a)
norm_b = np.linalg.norm(vector_b)
epsilon = 1e-10
cosine_similarity = dot_product / (norm_a * norm_b + epsilon)
return cosine_similarity
# search through the reviews for a specific product
def search_product(df, query, n=3, pprint=True):
product_embedding = get_embedding(
query,
model=embedding_model
)
df["similarity"] = df.embedding.apply(lambda x: cosine_similarity(x, product_embedding))
results = (
df.sort_values("similarity", ascending=False)
.head(n)
.product_name
)
if pprint:
for r in results:
print(r)
return results
results = search_product(df, "自然淡雅背包", n=3)
输出结果:

可以看到,使用“自然淡雅背包”作为搜索词得到的前 3 个返回结果中,尽管在关键词上完全不同,但是语义上十分接近。
1.2.2 基于 Embedding 进行商品推荐的冷启动
主流的推荐算法主要依托于用户“看了又看”的行为信息,但是一个新的商品或者新的平台,没有那么多相关的行为数据,这时同样可以根据商品名称在语义上的相似度,来进行商品推荐。
这里的代码和上面唯一的差别就是商品名称的 Embedding 是根据输入的商品名称从 DataFrame 里找到的,无需通过 OpenAI 的接口再获取。
def recommend_product(df, product_name, n=3, pprint=True):
product_embedding = df[df['product_name'] == product_name].iloc[0].embedding
df["similarity"] = df.embedding.apply(lambda x: cosine_similarity(x, product_embedding))
results = (
df.sort_values("similarity", ascending=False)
.head(n)
.product_name
)
if pprint:
for r in results:
print(r)
return results
results = recommend_product(df, "【限时抢购】华为P30 Pro 5G全网通手机,超强拍照性能,畅快游戏体验", n=3)
输出结果:

1.3 加速搜索
上述代码中,存在一个问题,每次我们进行搜索或者推荐的时候,都要把输入的 Embedding 和要检索数据的所有 Embedding 都计算一次余弦相似度。例子里,我们检索的数据只有 100 条,但是在实际的应用中,搜索对应的内容条数在几百万上千万的情况也不在少数。如果每次搜索都要计算几百万次余弦距离是不现实的。
解决这个问题我们可以使用一些向量数据库,或者能够快速搜索相似性的软件。这里我们使用 Facebook 开源的 Faiss 这个 Python 包,它的全称就是 Facebook AI Similarity Search,也就是快速进行高维向量的相似性搜索。
下载安装代码:
!pip install faiss-cpu # cpu 安装这个包
!pip install faiss-gpu # gpu 安装这个包
代码逻辑:把索引加载到 Faiss 里面只需要把整个的 Embedding 变成一个二维矩阵加载到 Faiss 里面就好了。在加载之前,先要定义好 Faiss 索引的维度数,也就是 Embedding 向量的维度数。
搜索时将查询变成 Embedding,之后转换成一个 numpy 的 array 向量,然后直接对刚才生成的索引 index 调用 search 方法,并且指定返回的结果数量就可以了。返回结果只有索引的 index,也就是加载在 Faiss 里面的第几个索引。最后还是要根据这个索引,在 DataFrame 里面反查到对应的是 DataFrame 里面的第几行,以及这一行商品的标题是什么,就能获得搜索的结果。
import faiss
import numpy as np
def load_embeddings_to_faiss(df):
embeddings = np.array(df['embedding'].tolist()).astype('float32')
index = faiss.IndexFlatL2(embeddings.shape[1])
index.add(embeddings)
return index
def search_index(index, df, query, k=5):
query_vector = np.array(get_embedding(query, model=embedding_model)).reshape(1, -1).astype('float32')
distances, indexes = index.search(query_vector, k)
results = []
for i in range(len(indexes)):
product_names = df.iloc[indexes[i]]['product_name'].values.tolist()
results.append((distances[i], product_names))
return results
index = load_embeddings_to_faiss(df)
products = search_index(index, df, "自然淡雅背包", k=3)
for distances, product_names in products:
for i in range(len(distances)):
print(product_names[i], distances[i])
输出结果:

可以看到搜索结果和之前我们自己计算余弦距离排序的结果是一样的。
Faiss 的原理,是通过 ANN 这样的近似最近邻的算法,快速实现相似性的搜索。
Faiss 这个库能够加载的数据量受限于内存大小。如果数据量进一步增长,就需要选用一些向量数据库来进行搜索。比如 OpenAI 就推荐了 Pinecone 和 Weaviate,或者是 Milvus 这个国人开源的产品。
无论是搜索还是推荐,使用 Embedding 的相似度都只是一种快速启动的方式。需要真正做到更好的效果,一定也需要投入更复杂的策略。比如根据用户行为的反馈,更好地排序搜索和推荐结果。但是,对于提供一个简单的搜索或者推荐功能来说,通过文本的 Embedding 的相似度,是一个很好的快速启动的方式。
1.4 补充练习:歧义关键词
搜索里面经常会遇到这样一个问题,同样的关键词有歧义。
代码示例如下:
data = {
'product_name': ["荣耀 V30 Pro", "黑龙江优质小米"]
}
df = pd.DataFrame(data)
prompts = df.product_name.tolist()
prompt_batches = [prompts[i:i+batch_size] for i in range(0, len(prompts), batch_size)]
embeddings = []
for batch in prompt_batches:
batch_embeddings = get_embeddings_with_backoff(prompts=batch, model=embedding_model)
embeddings += batch_embeddings
df["embedding"] = embeddings
# 1. 余弦相似度进行语义搜索
result = search_product(df, "小米手机", n=1)
# 2. 使用Faisss库来进行语义搜索
index = load_embeddings_to_faiss(df)
products = search_index(index, df, "小米手机", k=1)
for distances, product_names in products:
for i in range(len(distances)):
print(product_names[i], distances[i])
输出结果:

可以看到,搜索“小米手机”返回结果里应该是“荣耀 V30 Pro”,但是不应该返回“黑龙江优质小米”,但这里搜索的结果里“黑龙江优质小米”与“小米手机”的相似度却更为接近。解决这个问题需要使用更多复杂的策略。
2. 应用任务2:训练LLM“第二大脑”资料库(llama_index 库)
2.1 大型语言模型(LLM)的不足
在使用 OpenAI 提供的 GPT 系列模型的时候,如果问 AI 一些事实性的问题,AI 很容易胡编乱造,而当问它最近发生的新闻事件的时候,它直接回答它不知道23年之后的事。
即使 ChatGPT 可以引入第三方知识,也无法确保自己想要知道的信息正好被其他人提供了。而且,有些信息和问题我们只想提供给自己公司的内部使用,并不想开放给所有人。
例如,我们问 ChatGPT “鲁迅先生去日本学习医学的老师是谁”,它的答案是桥本龙太郎,而不是我们都知道的藤野先生。
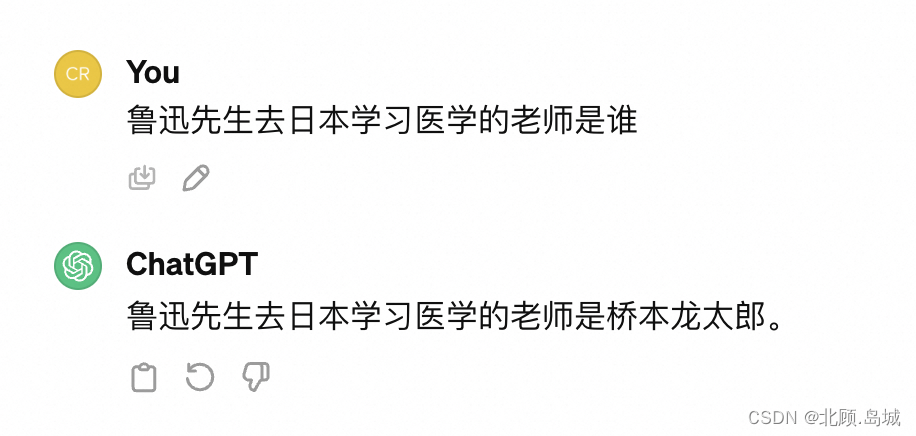
又比如我们问 ChatGPT 新闻类的信息,它也会拒绝回答。

之所以会出现这样的情况,和大模型的原理以及它使用训练的数据集是有关的。大语言模型的原理,就是利用训练样本里面出现的文本的前后关系,通过前面的文本对接下来出现的文本进行概率预测。如果类似的前后文本出现得越多,那么这个概率在训练过程里会收敛到少数正确答案上,回答就准确。如果这样的文本很少,那么训练过程里就会有一定的随机性,对应的答案就容易似是而非。而在 GPT-3 的模型里,虽然整体的训练语料很多,但是中文语料很少。只有不到 1% 的语料是中文的,所以如果问很多中文相关的知识性或者常识性问题,它的回答往往不准确。
一个解决办法是多找一些高质量的中文语料训练一个新的模型。或者,对于我们想让 AI 能够回答出来的问题,找一些数据。然后利用 OpenAI 提供的“微调”(Fine-tune)接口,在原来的基础上训练一个新模型出来。这是可行的,但是成本有点高。比如对于时效性要求比较强的资讯类的信息,像想让 AI 告诉我们前一天足球赛的比分,我们不太可能每隔几个小时就单独训练或者微调一下模型。
2.2 解决方法:“第二大脑”模式——llama_index 库
2.2.1 解决思路:先搜索,后提示
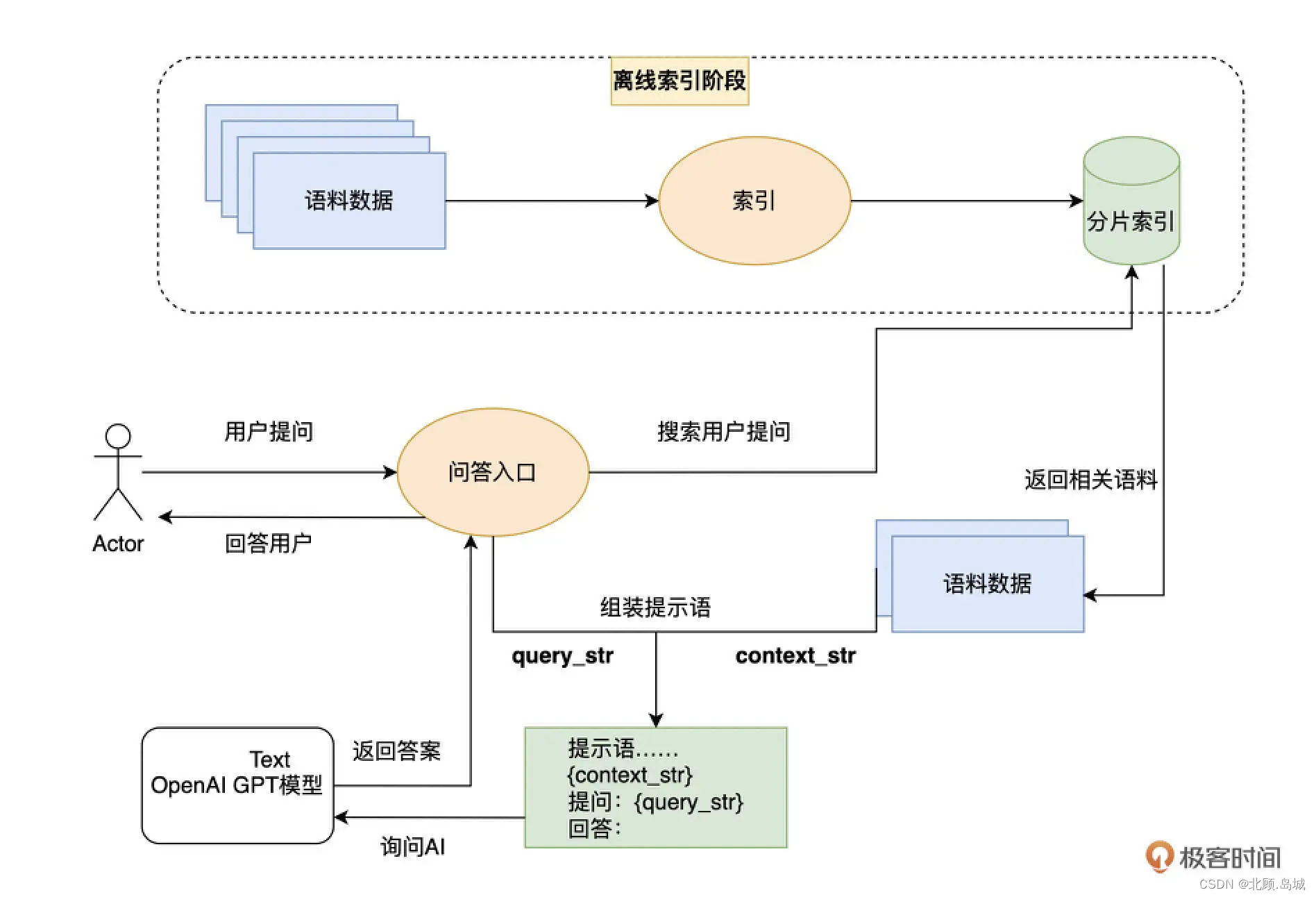
微软之前在 Bing 这个搜索引擎里,加上了 ChatGPT 的问答功能,效果似乎不错,虽然不了解 Bing 是怎么做的。但是我们通常会用这样一个解决办法——那就是先搜索,后提示(Prompt)。具体步骤如下:
- 先通过搜索的方式,找到和询问的问题最相关的语料。这个搜索过程中,我们既可以用传统的基于关键词搜索的技术,也可以用之前介绍过的使用 Embedding 的相似度进行语义搜索的技术。
- 将和问题语义最接近的前几条内容,作为提示语的一部分给到 AI。然后请 AI 参考这些内容,再来回答这个问题。

上图中我们把《藤野先生》里的两个段落给到 AI,然后请 AI 根据这两个段落,回答原来那个问题,就得到了正确的答案。
这就是利用大语言模型的一个常见模式。因为大语言模型其实内含了两种能力。
- 海量的语料中,本身已经包含了的知识信息。比如,我们前面问 AI 鱼香肉丝的做法,它能回答上来就是因为语料里已经有了充足的相关知识。我们一般称之为“世界知识”。
- 根据你输入的内容,理解和推理的能力。这个能力不需要训练语料里有一样的内容。而是大语言模型本身有“思维能力”,能够进行阅读理解。这个过程里,“知识”不是模型本身提供的,而是我们找出来临时提供给模型的。
2.2.2 llama_index 库介绍
上面这种先搜索、后提示的方式,我们可以把它称为 AI 的“第二大脑”模式。因为这个方法,需要提前把希望 AI 能够回答的知识,建立一个外部的索引,这个索引就好像 AI 的“第二个大脑”。每次向 AI 提问的时候,它都会先去查询一下这个第二大脑里面的资料,找到相关资料之后,再通过自己的思维能力来回答问题。
因为这个模式较为常用,有人专门实现了一个开源 Python 包叫做 llama-index 来完成这个功能。这里可以直接利用这个软件包来实现相关功能。
下载安装 llama-index 包:
!pip install llama-index
这里将《藤野先生》这篇文章变成了一个 txt 文件,放在了 data/mr_fujino 这个目录下。
下载数据集代码:
!wget -P data/mr_fujino/ https://github.com/xuwenhao/geektime-ai-course/raw/main/data/mr_fujino/mr_fujino.txt
2.2.2.1 构建及存储
构建外部知识索引的代码逻辑:
- 首先通过一个叫做 SimpleDirectoryReader 的数据加载器,将整个./data/mr_fujino 的目录给加载进来。这里面的每一个文件,都会被当成是一篇文档。
- 将所有的文档交给了 GPTVectorStoreIndex 构建索引。顾名思义,它会把文档分段转换成一个个向量,然后存储成一个索引。
- 把对应的索引存下来,存储的结果就是一个 json 文件。后面,我们就可以用这个索引来进行相应的问答。
from llama_index.core import GPTVectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('./data/mr_fujino').load_data()
index = GPTVectorStoreIndex.from_documents(documents)
index.storage_context.persist(persist_dir='index_mr_fujino')
执行结果后的目录结构:

2.2.2.2 读取及问答
问答代码逻辑:把刚才生成的索引加载到内存里,然后获取它的 query_engine,之后对着 query_engine 调用 query 函数,就能够获得问题的答案。
from llama_index.core import StorageContext, load_index_from_storage
index = load_index_from_storage(StorageContext.from_defaults(persist_dir='index_mr_fujino'))
query_engine = index.as_query_engine()
response = query_engine.query("鲁迅先生在日本学习医学的老师是谁?")
print(response)
response = query_engine.query("鲁迅先生去哪里学的医学?")
print(response)
输出结果:

可以看到,通过外部的索引,我们可以正确地获得问题的答案。
2.2.2.3 Prompt 模版
我们还可以自己定义一个模版对象,代码示例如下:
from llama_index.core import PromptTemplate
query_str = "鲁迅先生去哪里学的医学?"
DEFAULT_TEXT_QA_PROMPT_TMPL = (
"Context information is below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given the context information and not prior knowledge, "
"answer the question: {query_str}\n"
)
QA_PROMPT = PromptTemplate(DEFAULT_TEXT_QA_PROMPT_TMPL)
query_engine = index.as_query_engine(text_qa_template=QA_PROMPT)
response = query_engine.query(query_str)
print(response)
该段代码中:
- 模版的开头,我们告诉 AI,我们为其提供了一些上下文信息(Context information);
- 模版里面支持两个变量,一个叫做 context_str,另一个叫做 query_str。context_str 的地方,在实际调用的时候,会被通过 Embedding 相似度找出来的内容填入。而 query_str 则是会被我们实际提的问题替换掉;
- 实际提问的时候,我们告诉 AI,只考虑上下文信息,而不要根据自己已经有的先验知识(prior knowledge)来回答问题。
这样,把我们提供的上下文内容以及问题,组合到一起变成一段提示语,让 AI 能够按照我们的要求来回答问题。
上述代码的输出结果如下:

我们可以尝试改变一下模版内容,问一些不相干的问题:
QA_PROMPT_TMPL = (
"下面的“我”指的是鲁迅先生 \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"根据这些信息,请回答问题: {query_str}\n"
"如果您不知道的话,请回答不知道\n"
)
QA_PROMPT = PromptTemplate(QA_PROMPT_TMPL)
query_engine = index.as_query_engine(text_qa_template=QA_PROMPT)
response = query_engine.query("请问林黛玉和贾宝玉是什么关系?")
print(response)
输出结果:

2.3 llama_index 库的其他应用场景
2.3.1 生成文章摘要
之前进行文本聚类的时候我们已经可以通过合适的提示语(Prompt)做到这一点。不过,如果要总结一篇论文、甚至是一本书,每次最多只能支持 4096 个 Token 的 API 就不太够用了。
要解决这个问题也并不困难,我们只要进行分段小结,再对总结出来的内容再做一次小结就可以了。我们可以把一篇文章,乃至一本书,构建成一个树状的索引。每一个树里面的节点,就是它的子树下内容的摘要。最后,在整棵树的根节点,得到的就是整篇文章或者整本书的总结了。
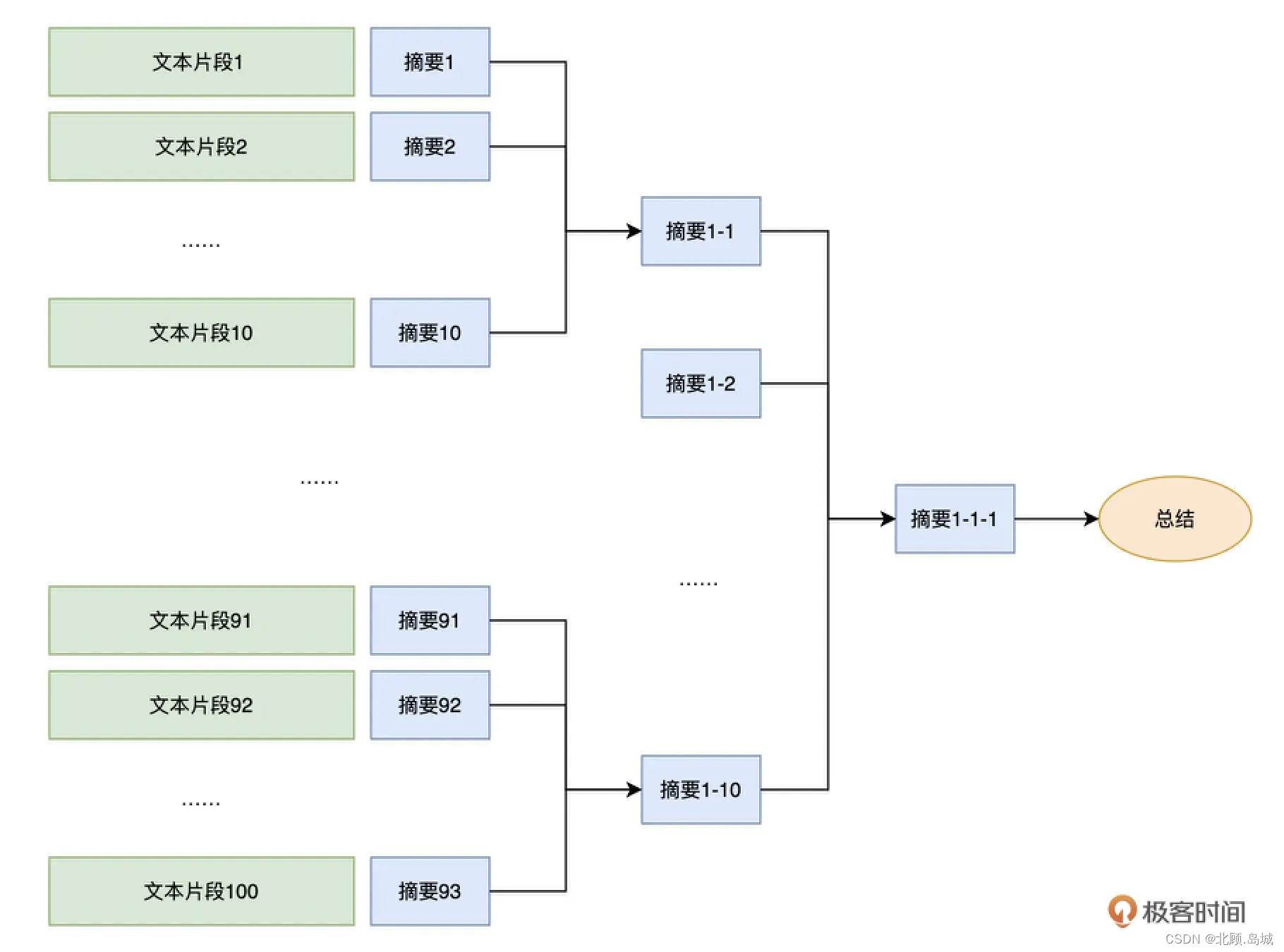
llama-index 本身就内置了上述这样的功能。
这里需要使用到 spacy 这个 Python 库,以及对应的中文分词分句需要的模型。同时还需要使用到 langchain 相关库。
!pip install spacy
!pip install langchain
!pip install langchain-openai
!pip install llama-index-llms-langchain
!python -m spacy download zh_core_web_sm
我们使用了 SummaryIndex 索引结构,同时针对自身需求做了两点优化:
- 在索引里面,我们指定了一个 ChatGPT 的 gpt-3.5-turbo 模型,因为这个模型比较快,也比较便宜。同时我们设置了模型输出的内容都在 1024 个 Token 以内,这样可以确保得到的总结不会太长,不会把一大段不相关的内容都合并到一起去。
- 我们定义了使用 SpacyTextSplitter 来进行中文文本的分割,llama-index 默认的设置对于中文的支持和效果都不太好。这里我们选用的文章是中文的,里面的标点符号也都是中文的,所以就用了中文的语言模型。我们也限制了分割出来的文本段,最长不要超过 2048 个 Token,这些参数都可以根据实际用来处理的文章内容和属性自己设置。
SummaryIndex 在构建索引的时候,并不会创建 Embedding,所以索引创建的时候很快,也不消耗 Token 数量。它只是根据设置的索引结构和分割方式,建立了一个 List 的索引。
之后,我们给出提示语,强调文章内容是鲁迅先生以“我”这个第一人称写的。因为我们想要的是按照树状结构进行文章的小结,所以我们设定了一个参数,叫做 response_mode = “tree_summarize”。这个参数,就会按照上面我们所说的树状结构把整个文章总结出来。实际上,它就是将每一段文本分片,都通过 query 内的提示语小结。再对多个小结里的内容,再次通过 query 里的提示语继续小结。
from langchain_openai import ChatOpenAI
from langchain.text_splitter import SpacyTextSplitter
from llama_index.core import SummaryIndex, ServiceContext
from llama_index.core.node_parser import SentenceSplitter
# define LLM
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=1024)
text_splitter = SpacyTextSplitter(pipeline="zh_core_web_sm", chunk_size = 2048)
parser = SentenceSplitter(chunking_tokenizer_fn=text_splitter.split_text)
documents = SimpleDirectoryReader('./data/mr_fujino').load_data()
nodes = parser.get_nodes_from_documents(documents)
service_context = ServiceContext.from_defaults(llm=llm)
list_index = SummaryIndex(nodes=nodes, service_context=service_context)
query_engine = index.as_query_engine(response_mode="tree_summarize")
response = query_engine.query("下面鲁迅先生以第一人称‘我’写的内容,请你用中文总结一下:")
print(response)
输出结果:

2.3.2 多模态
llama_index 不光能索引文本,还能索引图片。这个能力其实是通过一些多模态的模型,把文本和图片联系到一起做到的。
下面给出一个示例,给出多个吃饭的小票,询问哪天吃了什么,花了多少钱。
首先下载图片:
!wget -P data/receipts/ https://github.com/xuwenhao/geektime-ai-course/raw/main/data/receipts/1100-receipt.jpg
!wget -P data/receipts/ https://github.com/xuwenhao/geektime-ai-course/raw/main/data/receipts/1056-receipt.jpg
!wget -P data/receipts/ https://github.com/xuwenhao/geektime-ai-course/raw/main/data/receipts/1077-receipt.jpg
为了索引图片需要引入了 ImageReader 这个类,这个类背后,其实是一个基于 OCR 扫描的模型 Donut。它通过一个视觉的 Encoder 和一个文本的 Decoder,这样任何一个图片能够变成一段文本,然后我们再通过 OpenAI 的 Embedding 把这段文本变成了一个向量。
之后只需要使用简单的 SimpleDirectoryReader,通过指定 FileExtractor 把对应的图片通过 ImageReader 解析成为文本,并最终成为向量来用于检索。然后,我们只需要向索引用自然语言提问,就能找到对应的图片了。在提问的时候,我们专门制定了一个 ImageOutputQueryTransform,主要是为了在输出结果的时候,能够在图片外加上 <img> 的标签方便在 Notebook 里面显示。
代码:
from llama_index.core import SimpleDirectoryReader, GPTVectorStoreIndex
from llama_index.readers.file import ImageReader
from llama_index.core.response.notebook_utils import display_response
from llama_index.core.indices.query.query_transform.base import ImageOutputQueryTransform
from llama_index.core.query_engine import TransformQueryEngine
image_parser = ImageReader(keep_image=True, parse_text=True)
file_extractor = SimpleDirectoryReader.supported_suffix_fn()
file_extractor.update(
{
".jpg": image_parser,
".png": image_parser,
".jpeg": image_parser,
})
# NOTE: we add filename as metadata for all documents
filename_fn = lambda filename: {'file_name': filename}
receipt_reader = SimpleDirectoryReader(
input_dir='./data/receipts',
file_extractor=file_extractor,
file_metadata=filename_fn,
)
receipt_documents = receipt_reader.load_data()
receipts_index = GPTVectorStoreIndex.from_documents(receipt_documents)
query_engine = TransformQueryEngine(query_engine=receipts_index.as_query_engine(similarity_top_k=1),
query_transform=ImageOutputQueryTransform(width=400))
receipts_response = query_engine.query(
'When was the last time I went to McDonald\'s and how much did I spend. \
Also show me the receipt from my visit.'
)
display_response(receipts_response)
输出结果:
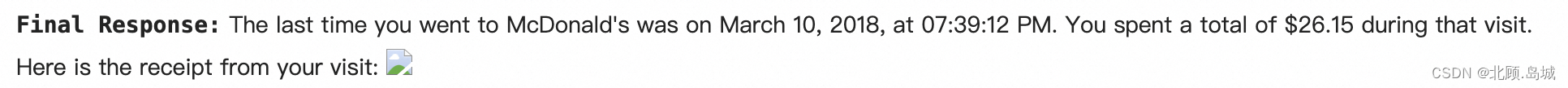
注意:这里由于 Colab 的文件路径问题,导致其通过 Html 解析的方式无法加载在 Google driver 中的图片。这里我在本地的 jupyter 环境中执行后成功输出了期望的结果:
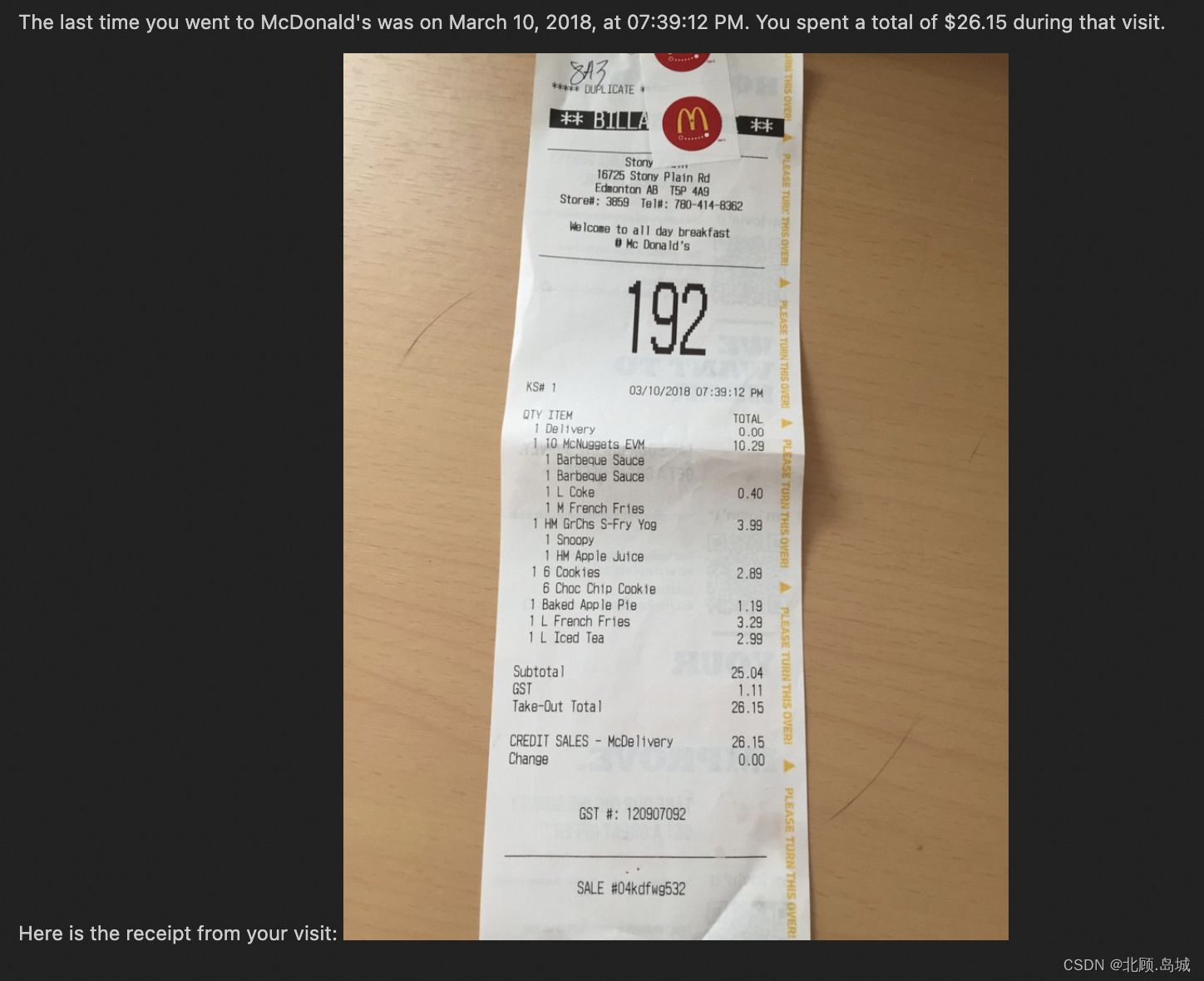
我们也可以单独解析一下图片,看看对应的文本内容是什么,代码如下:
output_image = image_parser.load_data('./data/receipts/1100-receipt.jpg')
print(output_image[0].text)
输出结果:
<s_menu><s_nm> Story</s_nm><s_num> 16725 Stony Platin Rd</s_nm><s_num> Store#:</s_nm><s_num> 3659</s_num><s_price> 700-418-8362</s_price><sep/><s_nm> Welcome to all day breakfast dormist O Md Donald's</s_nm><s_num> 192</s_num><s_price> 192</s_price><sep/><s_nm> QTY ITEM</s_nm><s_num> OTAL</s_num><s_unitprice> 03/10/2018</s_unitprice><s_cnt> 1</s_cnt><s_price> 07:39:12 PM</s_price><sep/><s_nm> Delivery</s_nm><s_cnt> 1</s_cnt><s_price> 0.00</s_price><sep/><s_nm> 10 McNuggets EVM</s_nm><s_cnt> 1</s_cnt><s_price> 10.29</s_price><sep/><s_nm> Barbeque Sauce</s_nm><s_cnt> 1</s_cnt><s_price> 1</s_price><sep/><s_nm> Barbeque Sauce</s_nm><s_num> 1</s_cnt><s_price> 0.40</s_price><sep/><s_nm> L Coke</s_nm><s_cnt> 1</s_cnt><s_price> 0.40</s_price><sep/><s_nm> M French Fries</s_nm><s_cnt> 1</s_cnt><s_price> 3.99</s_price><sep/><s_nm> HM GrChS S-Fry Yog</s_nm><s_cnt> 1</s_cnt><sep/><s_nm> Smoonya</s_nm><s_cnt> 1</s_cnt><sep/><s_nm> HM Apple Juice</s_nm><s_cnt> 1</s_cnt><s_price> 2.89</s_price><sep/><s_nm> Cookies</s_nm><s_cnt> 6</s_cnt><s_price> 2.89</s_price><sep/><s_nm> Choc Chip Cookie</s_nm><s_cnt> 6</s_cnt><s_price> 1.19</s_price><sep/><s_nm> Baked Apple Pie</s_nm><s_cnt> 1</s_cnt><s_price> 3.29</s_price><sep/><s_nm> French Fries</s_nm><s_cnt> 1</s_cnt><s_price> 2.99</s_price><sep/><s_nm> Iced Tea</s_nm><s_cnt> 1</s_cnt><s_price> 2.99</s_price></s_menu><s_sub_total><s_subtotal_price> 25.04</s_subtotal_price><s_tax_price> 1.11</s_tax_price></s_sub_total><s_total><s_total_price> 26.15</s_total_price><s_changeprice> 0.00</s_changeprice><s_creditcardprice> 26.15</s_creditcardprice></s_total>
可以看到,对应的就是 OCR 后的文本结果,里面的确有对应我们去的店铺的名字和时间,以及消费的金额。
围绕 OpenAI 以及整个大语言模型的生态还在快速发展中,所以 llama-index 这个库也在快速迭代。作为开源项目,llama-index 提供了大量的 DataConnector,既包括 PDF、ePub 这样的电子书格式,也包括 YouTube、Notion、MongoDB 这样外部的数据源、API 接入的数据,或者是本地数据库的数据。你可以在 llamahub.ai 看到社区开发出来的读取各种不同数据源格式的 DataConnector。
2.4 总结
LlamaIndex 官方文档:https://docs.llamaindex.ai/en/latest/
llama_index 源码及示例:https://github.com/run-llama/llama_index
llama-index 其实给出了一种使用大语言模型的设计模式,我称之为“第二大脑”模式。通过先将外部的资料库索引,然后每次提问的时候,先从资料库里通过搜索找到有相关性的材料,然后再通过 AI 的语义理解能力让 AI 基于搜索到的结果来回答问题。
前两步的索引和搜索,我们可以使用 OpenAI 的 Embedding 接口,也可以使用其它的大语言模型的 Embedding,或者传统的文本搜索技术。只有最后一步的问答,往往才必须使用 OpenAI 的接口。我们不仅可以索引文本信息,也可以通过其他的模型来把图片变成文本进行索引,实现所谓的多模态功能。
llama-index 的生态,不仅支持各种各样的 DataConnector 去加载数据,后端也支持各种形式的索引,比如在语义搜索里面我们介绍过的 Faiss、Pinecone、Weaviate 它都是支持的。
3. 应用任务3:电商FAQ(使用开源模型)
3.1 使用 OpenAI 模型的问题
问题一:对于大数据集的场景,OpenAI 提供的模型免费额度是不太够用的。而 ChatCompletion 的接口,又需要传入大量的上下文信息,实际消耗的 Token 数量非常大。
问题二:存在数据安全的问题。因为每个国家的数据监管要求不同,并不是所有的数据,都适合通过 OpenAI 的 API 来处理的。
3.2 解决方案:使用开源模型
3.2.1 环境设置
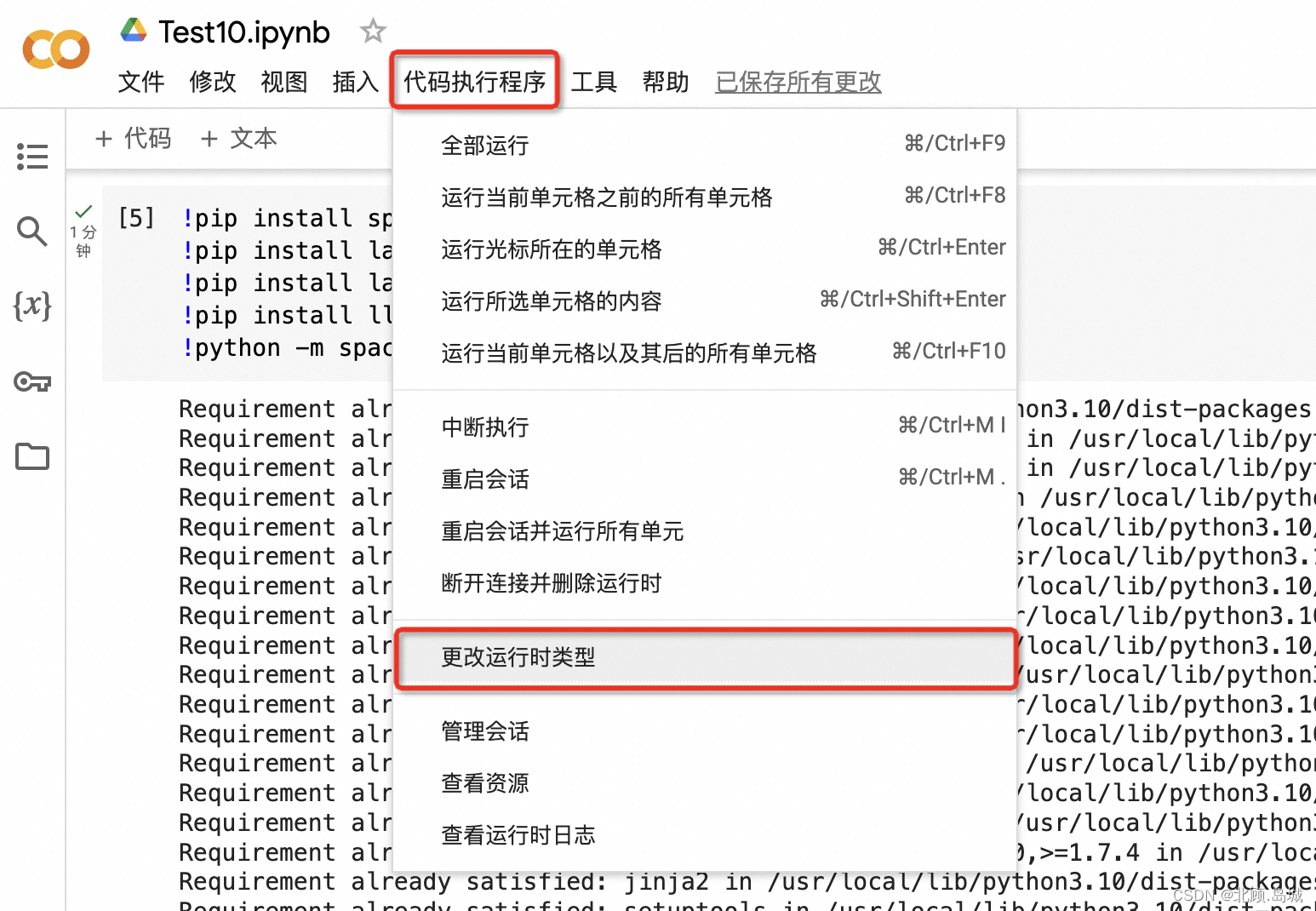
因为要使用开源模型,但不是所有人的电脑里都有一个强劲的 Nvidia GPU 的。所以可以通过 Colab 来运行对应的 Notebook,并且注意,要把对应的运行环境设置成 GPU。
设置方式:
- 选择菜单栏里的 “代码执行程序”,然后点击 “更改运行时类型”。
- 在弹出的对话框里,把 “硬件加速器” 换成 T4 GPU,然后点击 “保存” 就可以了。
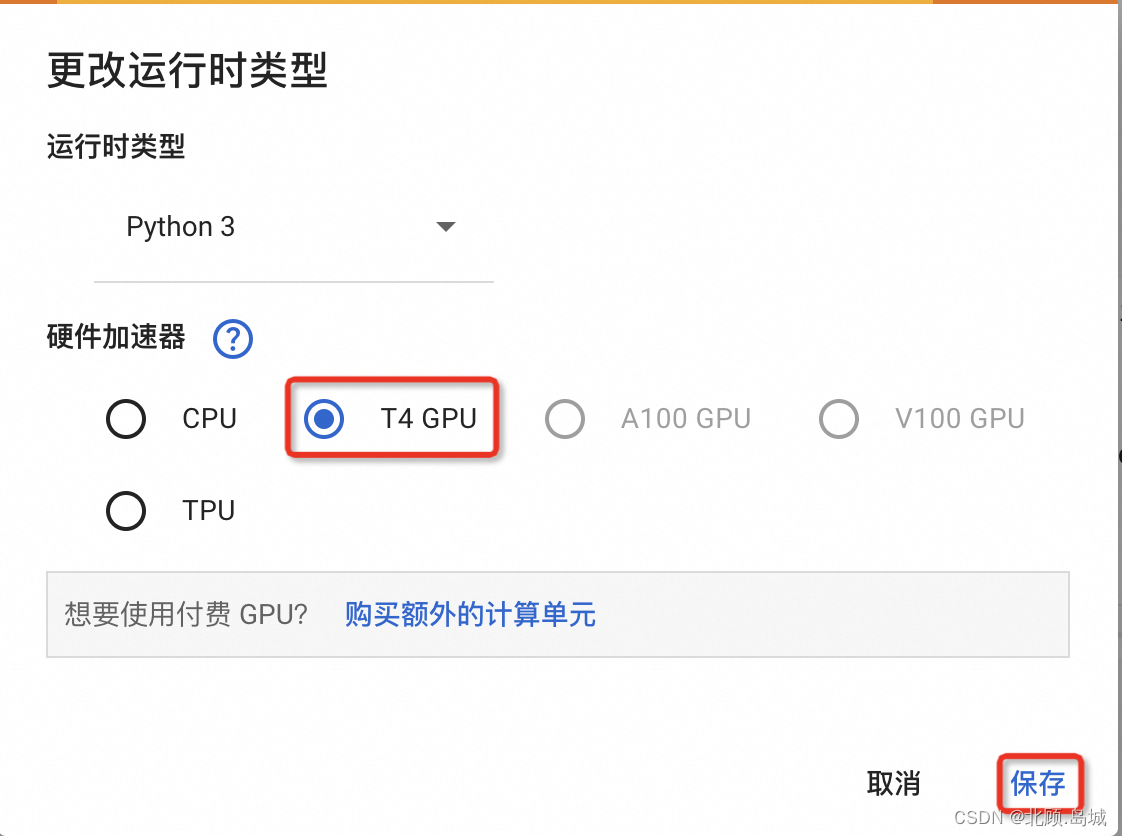
只要用得不是太多,Colab 的 GPU 是可以免费使用的。
3.2.2 HuggingfaceEmbedding
llama-index 也支持我们自己直接定义一个定制化的 Embedding,这里我们使用 sentence-transformers 模型,首先需要安装相关包:
!pip install faiss-gpu
!pip install llama-index
!pip install llama-index-vector-stores-faiss
!pip install llama-index-embeddings-langchain
!pip install langchain
!pip install sentence-transformers
下载数据集:
!wget -P data/faq/ https://github.com/xuwenhao/geektime-ai-course/raw/main/data/faq/ecommerce_faq.txt
代码示例:
import faiss
from llama_index.core import SimpleDirectoryReader, ServiceContext, VectorStoreIndex, StorageContext
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from llama_index.core.node_parser import SentenceSplitter
from llama_index.vector_stores.faiss import FaissVectorStore
text_splitter = CharacterTextSplitter(separator="\n\n", chunk_size=100, chunk_overlap=20)
parser = SentenceSplitter(chunking_tokenizer_fn=text_splitter.split_text)
documents = SimpleDirectoryReader('./data/faq/').load_data()
nodes = parser.get_nodes_from_documents(documents)
embed_model = HuggingFaceEmbeddings(model_name="sentence-transformers/paraphrase-multilingual-mpnet-base-v2")
service_context = ServiceContext.from_defaults(embed_model=embed_model)
dimension = 768
faiss_index = faiss.IndexFlatIP(dimension)
vector_store = FaissVectorStore(faiss_index=faiss_index)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex(nodes=nodes, storage_context=storage_context, service_context=service_context)
上述这段代码使用了一个面向电商的 FAQ 的纯文本文件作为输入。里面是一系列预设好的 FAQ 问答对。然后,我们定义了一个 embeded_model,这个 embeded_model 里面包装的是一个 HuggingFaceEmbeddings 的类。
因为 HuggingFace 为基于 transformers 的模型定义了一个标准,大部分模型只需要传入一个模型名称,HuggingFacebEmbedding 这个类就会下载模型、加载模型,并通过模型来计算输入文本的 Embedding。使用 HuggingFace 的好处是可以通过一套代码使用所有的 transfomers 类型的模型。
sentence-transformers 是目前效果最好的语义搜索类的模型,它在 BERT 的基础上采用了对比学习的方式,来区分文本语义的相似度,它包括了一系列的预训练模型。我们在这里选用的是 sentence-transformers 下面的 paraphrase-multilingual-mpnet-base-v2 模型。顾名思义,这个是一个支持多语言(multilingual)并且能把语句和段落(paraphrase)变成向量的一个模型。因为我们给的示例都是中文,所以选取了这个模型。你可以根据你要解决的实际问题,来选取一个适合自己的模型。
之后我们使用 Faiss 这个库来作为我们的向量索引库,所以需要指定一下向量的维度,paraphrase-multilingual-mpnet-base-v2 这个模型的维度是 768,所以我们就把维度定义成 768 维。
对文档的切分我们使用的是 CharacterTextSplitter,并且在参数上做了一些调整:
- 我们把“\n\n”这样两个连续的换行符作为一段文本的分隔符,因为我们的 FAQ 数据里,每一个问答对都有一个空行隔开,正好是连续两个换行。
- 我们把 chunk_size 设置得比较小,只有 100。这是因为我们所使用的开源模型是个小模型,这样我们才能在单机加载起来。它能够支持的输入长度有限,只有 128 个 Token,超出的部分会进行截断处理。如果不设置 chunk_size,llama-index 会自动合并多个 chunk 变成一个段落。
- 我们还增加 chunk_overlap 参数。这个参数代表我们自动合并小的文本片段的时候,可以接受多大程度的重叠。它的默认值是 200,超过了单段文档的 chunk_size,所以我们这里要把它设小一点,不然程序会报错。
在创建完整个索引之后,我们可以拿一些常见的电商类型的 FAQ 问题尝试:
from llama_index.core.vector_stores.types import VectorStoreQueryMode
query_engine = index.as_query_engine(
vector_store_query_mode=VectorStoreQueryMode.DEFAULT,
verbose=True,
)
response = query_engine.query("请问你们海南能发货吗?")
print(response)
response = query_engine.query("你们用哪些快递公司送货?")
print(response)
response = query_engine.query("你们的退货政策是怎么样的?")
print(response)
输出结果:

我们在问问题的时候,指定了 vector_store_query_mode 是 DEFAULT,即 vector search。可以看到,AI 均给出了正确的回答。
3.2.3 ChatGLM2 模型
上面的代码只是把生成 Embedding 以及利用 Embedding 的相似度进行搜索的过程使用 HuggingfaceEmbedding 解决了,实际问答过程中使用的还是 OpenAI 的 Completion API。这里我们使用来自清华大学的 ChatGLM2 中文语言模型来实现这个过程。
(1)模型加载
首先安装相关包:
!pip install icetk
!pip install cpm_kernels
之后通过 transformers 来加载模型。ChatGLM 最大的一个模型有 1300 亿个参数。使用这么大的模型,无论是自己的电脑,还是 Colab 提供的 GPU 和 TPU 显然都放不了。所以我们只能选用一个裁剪后的 60 亿个参数的版本,并且还必须用 int-4 量化的方式,而不是用 float16 的浮点数。同时,我们使用的是 ChatGLM-6B 的第二代版本。所以,这里我们的模型名字就叫做 chatglm2-6b-int4,也就是 6B 的参数量,通过 int-4 量化。然后,我们希望通过 GPU 进行模型的计算,在加载模型的时候需要调用.cuda()。
这里加载模型的时候,我们还设置了一个 trust_remote_code = true 的参数,这是因为 ChatGLM 的模型不是一个 Huggingface 官方发布的模型,而是由用户贡献的,所以需要显式确认你信任这个模型的代码,它不会造成恶意的破坏。
模型加载代码如下:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4", trust_remote_code=True).half().cuda()
model = model.eval()
如果想要用 CPU 运行,可以把模型加载的代码换成下面这样:
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4",trust_remote_code=True).float()不过不建议这么做。因为 CPU 在运行对话的时候非常慢。
(2)模型问答
使用模型进行问答的代码如下:
question = """
自收到商品之日起7天内,如产品未使用、包装完好,您可以申请退货。某些特殊商品可能不支持退货,请在购买前查看商品详情页面的退货政策。
根据以上信息,请回答下面的问题:
Q: 你们的退货政策是怎么样的?
"""
response, history = model.chat(tokenizer, question, history=[])
print(response)
输出结果:

试着去掉提供的 FAQ 的内容,再看下效果:
question = """
Q: 你们的退货政策是怎么样的?
A:
"""
response, history = model.chat(tokenizer, question, history=[])
print(response)
输出结果:

可以看到,没有给出合适的上下文信息时,它编造出了一些原本没有的说明,比如“在收到退货产品后的14天内完成退货处理”。
我们继续来看下模型是否有简单的推理能力,比如在上下文里只说可以送到海南,不说是否支持三亚这个城市,看下 AI 回答的效果:
question = """
我们支持全国大部分省份的配送,包括北京、上海、天津、重庆、河北、山西、辽宁、吉林、黑龙江、江苏、浙江、安徽、福建、江西、山东、河南、湖北、湖南、广东、海南、四川、贵州、云南、陕西、甘肃、青海、台湾、内蒙古、广西、西藏、宁夏和新疆.
根据以上信息,请回答下面的问题:
Q: 你们能配送到三亚吗?
"""
response, history = model.chat(tokenizer, question, history=[])
print(response)
输出结果:

之后,我们再在上下文里面去掉东三省,然后问问它能不能送到哈尔滨:
question = """
我们支持全国大部分省份的配送,包括北京、上海、天津、重庆、河北、山西、江苏、浙江、安徽、福建、江西、山东、河南、湖北、湖南、广东、海南、四川、贵州、云南、陕西、甘肃、青海、台湾、内蒙古、广西、西藏、宁夏和新疆.但是不能配送到东三省
根据以上信息,请回答下面的问题:
Q: 你们能配送到哈尔滨吗?
"""
response, history = model.chat(tokenizer, question, history=[])
print(response)
输出结果:

可以看到, ChatGLM 均能正确回答上述的问题。
注意,如果提示如下错误
ImportError: cannot import name 'builder' from 'google.protobuf.internal' (/usr/local/lib/python3.10/dist-packages/google/protobuf/internal/__init__.py)为
protobuf包的版本问题,可执行下面的代码对protobuf包进行升级即可解决:!pip install --upgrade protobuf如果此时提示如下错误
NotImplementedError: A UTF-8 locale is required. Got ANSI_X3.4-1968执行如下代码即可:
import locale def getpreferredencoding(do_setlocale = True): return "UTF-8" locale.getpreferredencoding = getpreferredencoding
3.2.4 封装 LLM
上面的代码里我们用的还是原始的 ChatGLM 的模型代码,还不能直接通过 query 来访问 llama-index 得到答案。我可以把它封装成一个 LLM 类,让 index 使用这个指定的大语言模型就好了。
对应的 llama-index 的文档地址:链接
下载相关包:
!pip install llama-index-llms-langchain
代码逻辑:定义一个 CustomLLM 对象,传入 index 的构造函数里。
import faiss
from llama_index.core import SimpleDirectoryReader, ServiceContext, StorageContext, VectorStoreIndex
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from llama_index.core.node_parser import SentenceSplitter
from llama_index.vector_stores.faiss import FaissVectorStore
from langchain.llms.base import LLM
from typing import Optional, List, Mapping, Any
class CustomLLM(LLM):
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
response, history = model.chat(tokenizer, prompt, history=[])
return response
@property
def _identifying_params(self) -> Mapping[str, Any]:
return {"name_of_model": "chatglm2-6b-int4"}
@property
def _llm_type(self) -> str:
return "custom"
llm = CustomLLM()
text_splitter = CharacterTextSplitter(separator="\n\n", chunk_size=100, chunk_overlap=20)
parser = SentenceSplitter(chunking_tokenizer_fn=text_splitter.split_text)
documents = SimpleDirectoryReader('./data/faq/').load_data()
nodes = parser.get_nodes_from_documents(documents)
embed_model = HuggingFaceEmbeddings(model_name="sentence-transformers/paraphrase-multilingual-mpnet-base-v2")
service_context = ServiceContext.from_defaults(embed_model=embed_model, llm=llm)
dimension = 768
faiss_index = faiss.IndexFlatIP(dimension)
vector_store = FaissVectorStore(faiss_index=faiss_index)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex(nodes=nodes, storage_context=storage_context, service_context=service_context)
之后对它进行提问:
from llama_index import QuestionAnswerPrompt
from llama_index import QueryMode
QA_PROMPT_TMPL = (
"{context_str}"
"\n\n"
"根据以上信息,请回答下面的问题:\n"
"Q: {query_str}\n"
)
QA_PROMPT = QuestionAnswerPrompt(QA_PROMPT_TMPL)
response = index.query(
"请问你们海南能发货吗?",
mode=QueryMode.EMBEDDING,
text_qa_template=QA_PROMPT,
verbose=True,
)
print(response)
输出结果:

可以看到,我们实现了一个通过 paraphrase-multilingual-mpnet-base-v2 模型来计算 Embeddding 并进行语义搜索,然后通过 chatglm2-6b-int4 的模型来进行问答的解决方案。
3.3 开源模型的不足
上例中我们实现了一个很容易运行的小模型,它数据安全,并且无需担心花费。但是我们处理的电商 FAQ 问题较为简单,我们使用一个复杂一点的问题来看下效果。
下载数据集:
!git clone https://github.com/xuwenhao/geektime-ai-course.git
安装相关包:
!pip install spacy
!python -m spacy download zh_core_web_sm
代码实现:
from langchain.text_splitter import SpacyTextSplitter
text_splitter = SpacyTextSplitter(pipeline="zh_core_web_sm", chunk_size = 128, chunk_overlap=32)
parser = SentenceSplitter(chunking_tokenizer_fn=text_splitter.split_text)
documents = SimpleDirectoryReader('./geektime-ai-course/data/zhaohuaxishi/').load_data()
nodes = parser.get_nodes_from_documents(documents)
embed_model = HuggingFaceEmbeddings(model_name="sentence-transformers/paraphrase-multilingual-mpnet-base-v2")
service_context = ServiceContext.from_defaults(embed_model=embed_model, llm=llm)
dimension = 768
faiss_index = faiss.IndexFlatIP(dimension)
vector_store = FaissVectorStore(faiss_index=faiss_index)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex(nodes=nodes, storage_context=storage_context, service_context=service_context)
这里我们输入索引的数据是鲁迅先生整套《朝花夕拾》的散文集。对应的模型和索引加载的代码基本一致,只有一个小小的区别,就是在文本分割的时候,我们用了SpacyTextSplitter,因为这里都是散文的内容,而不是确定好格式的 QA 对。所以通过 SpacyTextSplitter 来分句,并在允许的时候合并小的片段是有意义的。
尝试询问之前问过的问题:
# query will use the same embed_model
from llama_index.core import PromptTemplate
from llama_index.core.vector_stores.types import VectorStoreQueryMode
QA_PROMPT_TMPL = (
"下面的内容来自鲁迅先生的散文集《朝花夕拾》,很多内容是以第一人称写的 \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"根据这些信息,请回答问题: {query_str}\n"
"如果您不知道的话,请回答不知道\n"
)
QA_PROMPT = PromptTemplate(QA_PROMPT_TMPL)
query_engine = index.as_query_engine(
vector_store_query_mode=VectorStoreQueryMode.DEFAULT,
similarity_top_k=1,
text_qa_template=QA_PROMPT,
verbose=True,
)
response = query_engine.query("鲁迅先生在日本学习医学的老师是谁?")
print(response)
response = query_engine.query("鲁迅先生是在日本的哪个城市学习医学的?")
print(response)
输出结果:

可以看到,有些问题在这个模式下回答是正确的。但是有些问题,无法得出答案。
这里我们观察到这样一个问题:单机的开源小模型能够承载的文本输入的长度问题。在我们使用 OpenAI 的 gpt-3.5-turbo 模型的时候,最长支持 4096 个 Token,也就是一个文本片段可以放上千字在里面。但是我们这里用的 paraphrase-multilingual-mpnet-base-v2 模型,只能支持 128 个 Token 的输入,虽然对应的 Tokenizer 不一样,但是就算一个字一个 Token,也就 100 个字而已。这使得我们检索出来的内容的上下文非常少,很多时候没有足够的信息让语言模型去回答。
该问题可以通过把更大规模的模型,部署到云端来解决。
我们再使用给商品总结英文名称和卖点的例子来看下模型的推理能力。
question = """Consideration proudct : 工厂现货PVC充气青蛙夜市地摊热卖充气玩具发光蛙儿童水上玩具
1. Compose human readale product title used on Amazon in english within 20 words.
2. Write 5 selling points for the products in Amazon.
3. Evaluate a price range for this product in U.S.
Output the result in json format with three properties called title, selling_points and price_range"""
response, history = model.chat(tokenizer, question, history=[])
print(response)
输出结果:

可以看到,虽然这个结果和问题有些关系,但是效果并没有 ChatGPT 好。这也是 ChatGPT 让人震撼的原因,的确目前它的效果还是要远远超出任何一个竞争对手和开源项目的。
3.4 总结
本节使用了开源模型来代替 ChatGPT 实现类似的功能。
首先通过 sentence_transfomers 类型的模型,生成了文本分片的 Embedding,并且基于这个 Embedding 来进行语义检索。然后通过 ChatGLM2 这个开源模型,实现了基于上下文提示语的问答。在简单的电商 QA 场景里,实现了不错的效果。
但是,当我们需要解决更加复杂的问题时,比如需要更长的上下文信息,或者需要模型本身更强的推理能力的时候,这样的小模型就远远不够用了。
除了 ChatGLM 之外,还有很多开源的中文大语言模型,比如基于斯坦福的 Alpaca 数据集进行微调的 Chinese-LLaMA-Alpaca,链家科技开源的 BELLE
扩展阅读:《让LLM回答问题更靠谱》这篇文章组合了三个模型来完成了医学领域的语义搜索、语义匹配排序,以及最终的问答语句生成,地址:链接
4. 应用任务4:实现插件
4.1 应用背景
之前利用大语言模型实现的任务都是通过代码实现的,虽然已经使用了如 Colab 这种在线 Notebook 工具,但是这些对非技术人员来说还是有一些门槛的。
普通业务人员最常用的界面就是像 Excel 或者 Chrome 浏览器这样的应用。而且这些产品都有自己的插件机制。这里我们将使用 ChatGPT 来辅助我们使用我们并不熟悉,甚至完全不会的编程语言和工具完成任务。
4.2 具体业务任务:实现 Excel 插件
4.2.1 业务需求
之前我们使用 ChatGPT 的 API,在一个商品上实现了标题翻译、卖点撰写和售价预估的功能。这个需求,其实是很多跨境电商的运营人员都能用上的。
但是,让运营人员去学会用 Python 写程序门槛还是太高了。而且如果每件商品都把同样的提示语往 ChatGPT 的界面里复制粘贴,效率又太低。
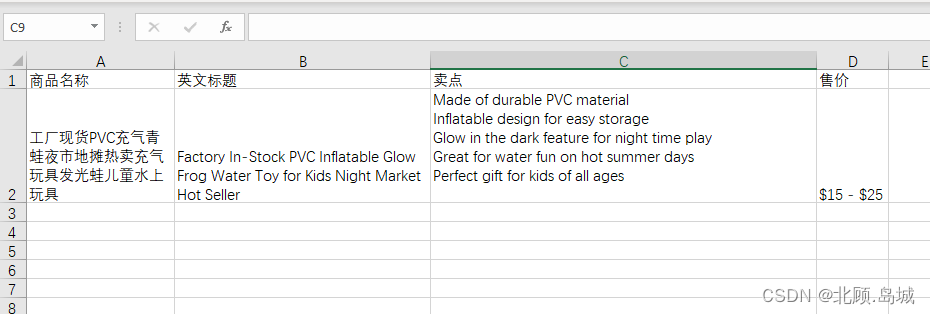
因此,我们的需求就是把所有想要翻译和寻找卖点的商品标题,都放在 Excel 文件的第一列里面,然后让 AI 根据我们的需要填后面几列。
示例:
4.2.2 和 ChatGPT 协同编写代码
本节仅演示和 ChatGPT 协同编写代码的过程,无需复现完整过程。
注意:该小节的交互每个人的 ChatGPT 返回结果可能均有不同,这里的操作流程与专栏原文也有较大差别。
(1)描述需求
我们先输入一句粗略的提示语:
请你帮我写一个Excel插件,能够将商品标题翻译成英文,寻找商品里面的卖点,以及确定商品的售价
ChatGPT 的结果如下:

虽然 ChatGPT 没有给出准确的答案,但它还是给我们提供了一个很有用的信息,那就是 Excel 里我们可以通过 VBA 来运行程序。
(2)简单功能
知道了 Excel 可以通过 VBA 来执行程序,我们就先通过它来写一个最简单的功能,来试试整个流程是否可以走通。所以,我给了 AI 这样一个指令:
请你为我写一个Excel的VBA插件,它会将表格里面的第一列的内容,复制到第二列
ChatGPT 的结果如下:

可以看到,ChatGPT 给出了如下代码:
Sub CopyColumn()
Dim ws As Worksheet
Dim lastRow As Long
' 设置当前活动的工作表
Set ws = ThisWorkbook.ActiveSheet
' 获取第一列最后一个非空单元格的行数
lastRow = ws.Cells(ws.Rows.Count, 1).End(xlUp).Row
' 复制第一列的内容到第二列
ws.Range("A1:A" & lastRow).Copy Destination:=ws.Range("B1")
End Sub
根据 ChatGPT 给出的详细操作步骤,我们在 Excel 尝试,但是无法正确操作(因为我们使用的是 mac 系统,而 ChatGPT 给出的是 Windows 系统下的操作方式)。于是我们继续给出如下提示:
上述操作步骤似乎是windows下使用Excel宏的操作方式,如果我想在mac系统下使用应该如何操作
ChatGPT 输出结果:

根据给出的步骤进行操作时,发现找不到“工具”这一选项卡,可能的原因是 ChatGPT 的知识数据较旧而 Excel for Mac 已经更新到了较新的版本导致的。可以如下操作:
- 增加“开发工具”菜单栏
- 将前面 ChatGPT 给出的操作步骤中的“工具”菜单栏改为“开发工具”菜单栏。
执行结果如下:
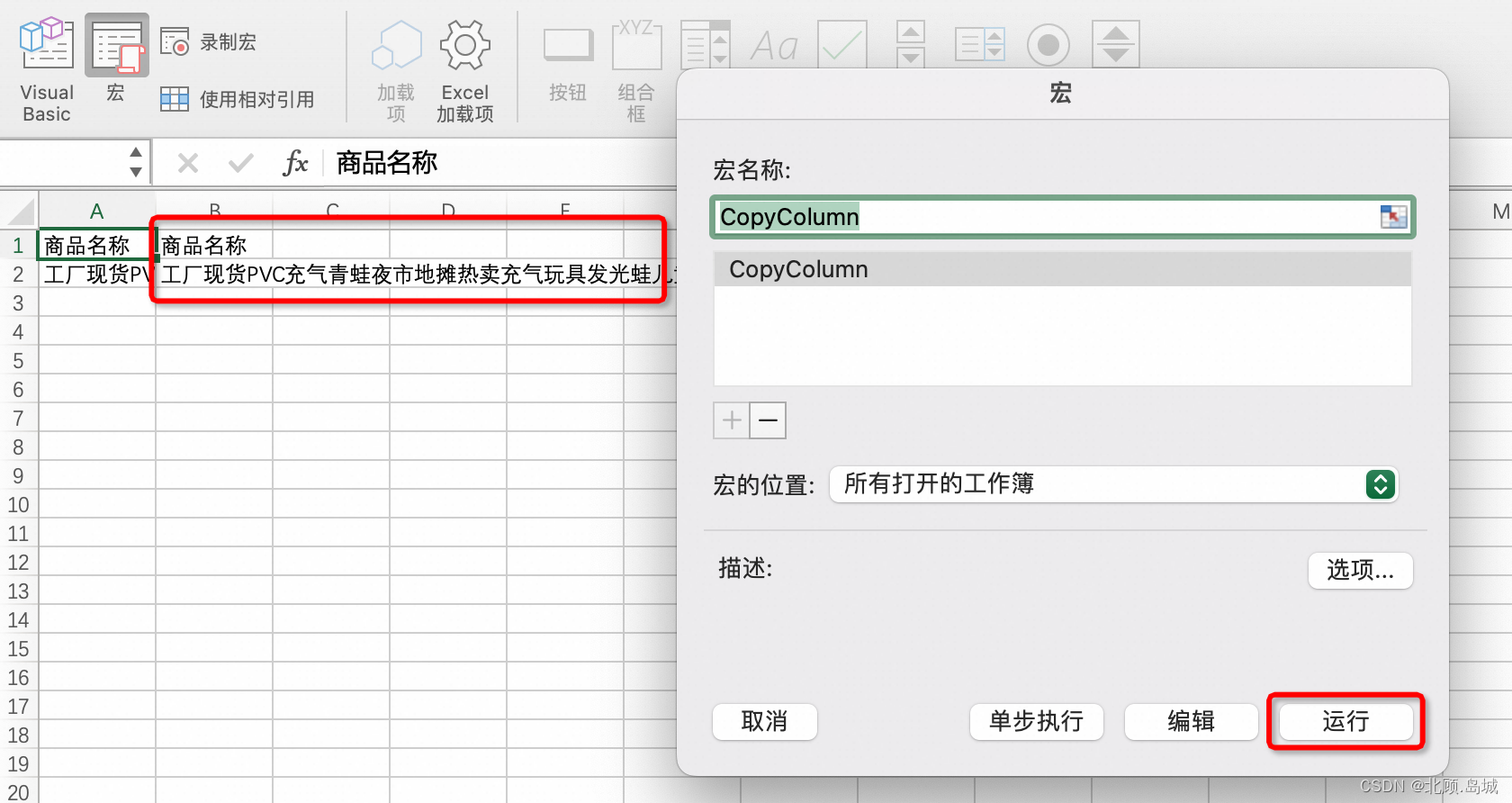
可以看到,根据 ChatGPT 给出的 VBA 的宏的确能够将我们表格里面的第一列,复制到第二列里面。
(3)拆分功能
经过上面两步验证之后,这里我们重新描述我们希望 ChatGPT 写出的代码完成什么功能,包括我们希望它使用的具体步骤和方法。
请为我写这样一段在Excel里面运行的VBA程序:
1. 读取表格里面的第一列的内容
2. 内容的每一行,都是一个商品标题。对这个商品标题,通过下面的Prompt,调用OpenAI的API拿到返回结果:
"""
Consideration proudct : 商品标题
1. Compose human readable product title used on Amazon in english within 20 words.
2. Write 5 selling points for the products in Amazon.
3. Evaluate a price range for this product in U.S.
Output the result in json format with three properties called title, selling_points and price_range
"""
3. 将对应API的返回结果,插入到表格的第二列里
生成的代码:
Sub 获取商品信息并调用OpenAIAPI()
Dim ws As Worksheet
Dim rng As Range
Dim cell As Range
Dim httpRequest As Object
Dim jsonResponse As Object
Dim apiUrl As String
Dim prompt As String
Dim title As String
Dim sellingPoints As String
Dim priceRange As String
Dim jsonOutput As String
' 设置工作表
Set ws = ThisWorkbook.Sheets("Sheet1") ' 请将Sheet1替换为您的工作表名称
' 设置范围为第一列
Set rng = ws.Columns(1)
' 创建HTTP请求对象
Set httpRequest = CreateObject("MSXML2.XMLHTTP")
' 循环读取每个单元格的内容并调用API
For Each cell In rng.Cells
If cell.Value <> "" Then
' 准备API请求
apiUrl = "https://api.openai.com/v1/completions"
prompt = "Consideration proudct: " & cell.Value & vbCrLf & _
"1. Compose human readable product title used on Amazon in english within 20 words." & vbCrLf & _
"2. Write 5 selling points for the products in Amazon." & vbCrLf & _
"3. Evaluate a price range for this product in U.S."
' 发送HTTP POST请求
With httpRequest
.Open "POST", apiUrl, False
.setRequestHeader "Content-Type", "application/json"
.setRequestHeader "Authorization", "Bearer YOUR_API_KEY" ' 请将YOUR_API_KEY替换为您的OpenAI API密钥
.send "{""prompt"":""" & prompt & """}"
End With
' 解析JSON响应
Set jsonResponse = JsonConverter.ParseJson(httpRequest.responseText)
' 提取返回结果
title = jsonResponse("choices")(1)("text")
sellingPoints = jsonResponse("choices")(2)("text")
priceRange = jsonResponse("choices")(3)("text")
' 准备输出JSON格式数据
jsonOutput = "{""title"":""" & title & """,""selling_points"":""" & sellingPoints & """,""price_range"":""" & priceRange & """}"
' 将结果插入到第二列
cell.Offset(0, 1).Value = jsonOutput
End If
Next cell
' 清除对象引用
Set ws = Nothing
Set rng = Nothing
Set cell = Nothing
Set httpRequest = Nothing
Set jsonResponse = Nothing
End Sub
将生成的代码中“YOUR_API_KEY“部分换成我们自己的 Key 然后运行,结果如下:
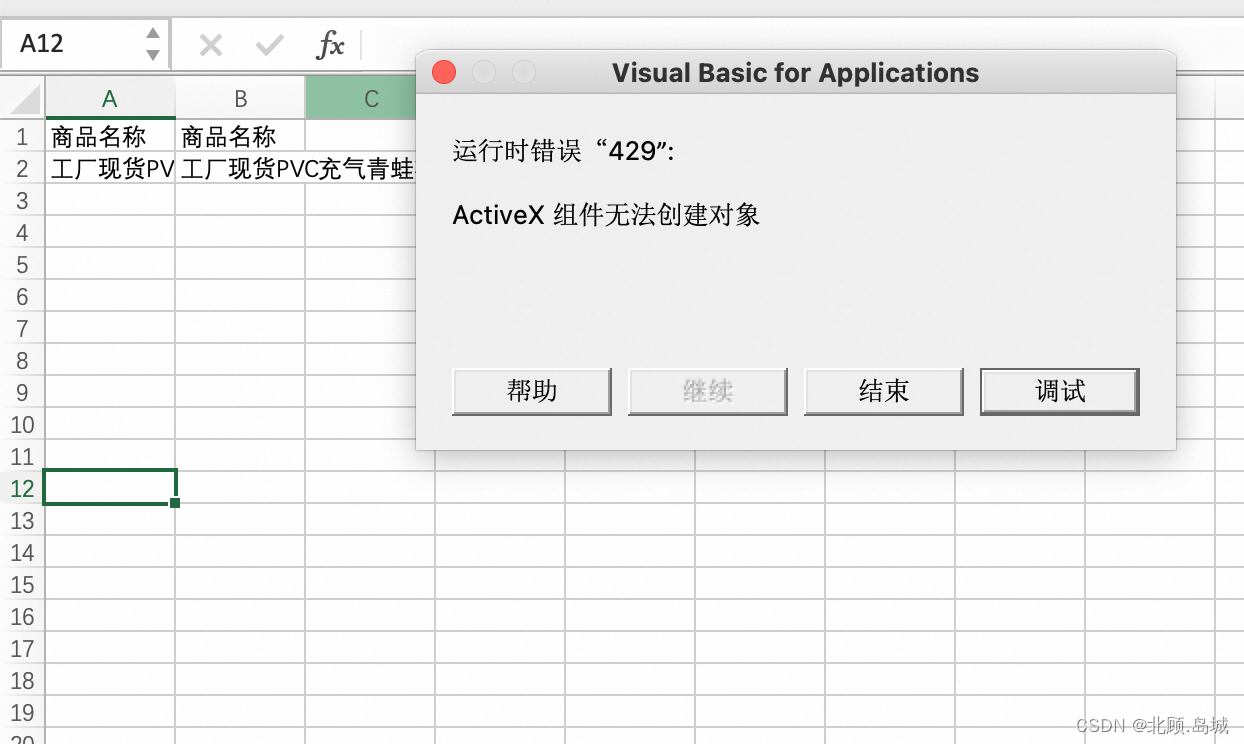
将错误信息也抛给 ChatGPT:
ActiveX 组件无法创建对象
ChatGPT结果:

经过我的判断,初步怀疑是由于 Mac 系统的原因,于是我询问了 ChatGPT:
执行环境为mac系统而非windows,上述错误是否与这个原因有关
ChatGPT结果:

可以看到,通过 ChatGPT 我们知道了上面运行代码失败的原因,在结果中我们看到可以使用 AppleScript 这种脚本语言在 macOS 上操作 Excel 文件。
于是我们重新描述我们的需求:
请为我写这样一段可以操作Excel的AppleScript程序:
1. 读取表格里面的第一列的内容
2. 内容的每一行,都是一个商品标题。对这个商品标题,通过下面的Prompt,调用OpenAI的API拿到返回结果:
"""
Consideration proudct : 商品标题
1. Compose human readable product title used on Amazon in english within 20 words.
2. Write 5 selling points for the products in Amazon.
3. Evaluate a price range for this product in U.S.
Output the result in json format with three properties called title, selling_points and price_range
"""
3. 将对应API的返回结果,插入到表格的第二列里
ChatGPT 生成代码:
set excelFile to choose file with prompt "请选择Excel文件:"
set sheetName to "Sheet1" -- 修改为你的表格名称
set columnNumber to 1 -- 第一列的列号
set startRow to 2 -- 数据开始的行号
set endRow to 5 -- 数据结束的行号
tell application "Microsoft Excel"
activate
open excelFile
set activeSheet to worksheet sheetName of active workbook
repeat with i from startRow to endRow
set productTitle to value of cell ("A" & i) of activeSheet
set apiPrompt to "Consideration product: " & productTitle & "
1. Compose human readable product title used on Amazon in English within 20 words.
2. Write 5 selling points for the products in Amazon.
3. Evaluate a price range for this product in U.S.
Output the result in JSON format with three properties called title, selling_points and price_range"
set apiResponse to do shell script "curl -X POST -H 'Content-Type: application/json' -H 'Authorization: Bearer YOUR_OPENAI_API_KEY' -d '{\"prompt\": \"" & apiPrompt & "\"}' https://api.openai.com/v1/completions"
set jsonResponse to (do shell script "echo '" & apiResponse & "' | python -m json.tool")
set titleText to (do shell script "echo '" & apiResponse & "' | grep -o '\"text\": \"[^\"]*\"' | head -n 1 | sed 's/\"text\": //g' | sed 's/\"//g'")
set sellingPointsText to (do shell script "echo '" & apiResponse & "' | grep -o '\"text\": \"[^\"]*\"' | tail -n +2 | head -n 5 | sed 's/\"text\": //g' | sed 's/\"//g' | tr '\n' ',' | sed 's/,$//'")
set priceRangeText to (do shell script "echo '" & apiResponse & "' | grep -o '\"text\": \"[^\"]*\"' | tail -n 1 | sed 's/\"text\": //g' | sed 's/\"//g'")
set value of cell ("B" & i) of activeSheet to "{\"title\": " & titleText & ", \"selling_points\": [" & sellingPointsText & "], \"price_range\": " & priceRangeText & "}"
end repeat
save active workbook
close active workbook
end tell
需要将"YOUR_OPENAI_API_KEY"替换为你的OpenAI API密钥。
这里由于本地环境网络原因调用 OpenAI API 访问不通,执行上述代码会报错,因此不继续演示,可参考原专栏文章作者与 ChatGPT 交互过程。
5. 应用任务5:自动化测试
5.1 问题背景
OpenAI Cookbook 提供的 AI 写单元测试示例地址:链接
为了避免待测程序本身就在 AI 的训练数据集里面,我们用了这样一个小题目,就是让 Python 根据输入的一个整数代表的秒数,格式化成一段自然语言描述的时间。比如,输入 1 就返回 1s,输入 61 就返回 1min1s。
需求:
用Python写一个函数,进行时间格式化输出,比如:
输入 输出
1 1s
61 1min1s
要求仅需要格式化到小时(?h?min?s),即可
根据这个需求,我们直接让 ChatGPT 来实现这个代码。
生成代码为:
def format_time(seconds):
hours = seconds // 3600
minutes = (seconds % 3600) // 60
seconds = seconds % 60
formatted_time = ""
if hours > 0:
formatted_time += str(hours) + "h"
if minutes > 0:
formatted_time += str(minutes) + "min"
if seconds > 0 or not formatted_time:
formatted_time += str(seconds) + "s"
return formatted_time
# 示例
print(format_time(1)) # 输出: 1s
print(format_time(61)) # 输出: 1min1s
之后我们可以尝试让 ChatGPT 也把单元测试写好:

生成代码如下:
import pytest
from your_module import format_time
def test_format_time():
assert format_time(3661) == "1h1min1s"
assert format_time(7200) == "2h"
assert format_time(120) == "2min"
assert format_time(30) == "30s"
assert format_time(0) == "0s"
assert format_time(3601) == "1h1s"
assert format_time(61) == "1min1s"
assert format_time(3600) == "1h"
assert format_time(60) == "1min"
assert format_time(1) == "1s"
仔细观察上述生成的单元测试还是存在如下一些问题:
- 这个测试没有考虑负数。如果我们输入的是负数会怎么样?
- 没有考虑非整数类型的输入,如果我们输入浮点数 1.0 会怎么样?字符串“abc”会怎么样?nil 这样的空值会怎么样?
- 即使是整数,也还没有考虑过,超过 24 小时的话,格式化后的结果是怎么样的。
5.2 问题拆解
很多事情不是我们直接把问题给到 ChatGPT 就能解决的。我们需要反过来自己思考一下,如果我们自己来为一段代码写单元测试,我们会怎么做。
我们可以把问题拆分成三个步骤:
- 把代码提交给大语言模型,让大语言模型解释一下,这个代码是在干什么。
- 把代码以及代码的解释一起交给大语言模型,让大语言模型规划一下,针对这个代码逻辑,我们到底要写哪几个 TestCase。如果在这个过程里,大语言模型规划的 TestCase 数量太少,那么我们就重复第二步,让 AI 多生成几个 TestCase。
- 针对上面的 TestCase 的详细描述,再提交给大语言模型,让它根据这些描述生成具体的测试代码。在这个过程中,我们还会对生成的代码,进行一次语法检查,如果语法检查没法通过,我们就要让 AI 重新生成一下。这个可以避免因为大语言模型的概率采样不稳定,导致生成的代码无法运行的问题。
5.2.1 解释代码
我们首先定义一个 gpt35 的函数,对调用 GPT3.5 的模型做简单的封装。其中有 2 点需要注意:
- 我们使用 gpt-3.5-turbo-instruct 模型;
- 对 stop 做了特殊的设置,只要连续两个换行或者类似连续两个换行的情况出现,就中止数据的生成。这是避免模型一口气连测试代码也生成出来。那样的话,我们没法对测试代码的生成提出具体的要求。通过 stop,我们可以确保在第一步,只解释现在的功能代码有什么用。
之后,使用提示语让 GPT 模型为我们来解释代码,在提示语中做下面 4 件事:
- 指定了使用 pytest 这个测试包;
- 把对应要测试的代码,也提供给了 GPT 模型;
- 告诉 AI,要精确描述代码做了什么;
- 在最后一行用 “- First” 开头,引导 GPT 模型,逐步分行描述要测试的代码干了什么。
代码如下:
from openai import OpenAI
import os
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
def gpt35(prompt, model="gpt-3.5-turbo-instruct", temperature=0.4, max_tokens=1000,
top_p=1, stop=["\n\n", "\n\t\n", "\n \n"]):
response = client.completions.create(
model=model,
prompt = prompt,
temperature = temperature,
max_tokens = max_tokens,
top_p = top_p,
stop = stop
)
message = response.choices[0].text
return message
code = """
def format_time(seconds):
hours = seconds // 3600
minutes = (seconds % 3600) // 60
seconds = seconds % 60
formatted_time = ""
if hours > 0:
formatted_time += str(hours) + "h"
if minutes > 0:
formatted_time += str(minutes) + "min"
if seconds > 0 or not formatted_time:
formatted_time += str(seconds) + "s"
return formatted_time
"""
def explain_code(function_to_test, unit_test_package="pytest"):
prompt = f""""# How to write great unit tests with {unit_test_package}
In this advanced tutorial for experts, we'll use Python 3.10 and `{unit_test_package}` to write a suite of unit tests to verify the behavior of the following function.
```python
{function_to_test}
Before writing any unit tests, let's review what each element of the function is doing exactly and what the author's intentions may have been.
- First,"""
response = gpt35(prompt)
return response, prompt
code_explaination, prompt_to_explain_code = explain_code(code)
print(code_explaination)
输出结果:

5.2.2 制定测试计划
根据生成的上面详细描述,请 AI 为我们制定一下具体的测试计划,测试计划的提示语有如下几个要求:
- 要求测试用例,尽量考虑输入的范围广一些;
- 要求 AI 想一些连代码作者没有想到过的边界条件;
- 希望 AI 能够利用好 pytest 这个测试包的特性;
- 希望测试用例清晰易读,测试的代码要干净;
- 要求测试代码的输出结果是确定的,要么通过,要么失败,不要有随机性。
然后,我们的提示语并没有立刻让 AI 去写测试代码,而是说我们要举几个例子。这样,AI 就会生成一系列的示例。我们对测试用例的提示是非常详尽的,这也是我们前面第一步没有直接让 AI 生成测试用例的原因。因为那样的话,我们没法在提示语中间插入这些详尽的要求。对具体的测试用例,只能寄希望于 AI 想得多一些。
我们发给 AI 的提示语,则是既包括了第一步要求解释代码的内容,也包括 AI 生成的对代码的解释,以及这里我们新增的对测试用例的要求,提供了非常详细的上下文,这样 AI 的表现也会更好、更有逻辑性。
代码示例:
def generate_a_test_plan(full_code_explaination, unit_test_package="pytest"):
prompt_to_explain_a_plan = f"""
A good unit test suite should aim to:
- Test the function's behavior for a wide range of possible inputs
- Test edge cases that the author may not have foreseen
- Take advantage of the features of `{unit_test_package}` to make the tests easy to write and maintain
- Be easy to read and understand, with clean code and descriptive names
- Be deterministic, so that the tests always pass or fail in the same way
`{unit_test_package}` has many convenient features that make it easy to write and maintain unit tests. We'll use them to write unit tests for the function above.
For this particular function, we'll want our unit tests to handle the following diverse scenarios (and under each scenario, we include a few examples as sub-bullets):
-"""
prompt = full_code_explaination + prompt_to_explain_a_plan
response = gpt35(prompt)
return response, prompt
test_plan, prompt_to_get_test_plan = generate_a_test_plan(prompt_to_explain_code + code_explaination)
print(test_plan)
输出结果:

可以看到,AI 提供了很多测试用例。并且,里面考虑了很多情况,包括负数这样的特殊条件,也包括输入字符串,以及 None 这样的内容。
不过,生成哪些用例其实是有一定的随机性。这个也是大语言模型的一个缺点,就是可控性差。有时候,AI 生成的用例过少导致很多情况覆盖不到。
因此,我们加一个步骤来检查一下到底生成了多少个用例。如果太少的话,我们就让 AI 再生成一些。通过“\n-”这样一个换行加横杆的标记来判断之前生成的测试用例数量,如果比我们设定的下限少,我们就再添加一段提示语,让 AI 再生成一些。同时,要特别提醒 AI 考虑一下测试罕见情况和边界条件。
代码示例:
not_enough_test_plan = """The function is called with a valid number of seconds
- `format_time(1)` should return `"1s"`
- `format_time(59)` should return `"59s"`
- `format_time(60)` should return `"1min"`
"""
approx_min_cases_to_cover = 7
elaboration_needed = test_plan.count("\n-") +1 < approx_min_cases_to_cover
if elaboration_needed:
prompt_to_elaborate_on_the_plan = f"""
In addition to the scenarios above, we'll also want to make sure we don't forget to test rare or unexpected edge cases (and under each edge case, we include a few examples as sub-bullets):
-"""
more_test_plan, prompt_to_get_test_plan = generate_a_test_plan(prompt_to_explain_code + code_explaination + not_enough_test_plan + prompt_to_elaborate_on_the_plan)
print(more_test_plan)
输出结果:
5.2.3 生成测试代码及语法检查
把前面已经生成的所有内容拼接在一起,然后要求 AI 根据前面的内容来写具体的测试代码。
有一点值得注意的是,为了避免 AI 忘记一开头功能代码的内容,我们特地再在提示语的最后,再次给 AI 看了一下我们要测试的功能代码。
代码示例:
def generate_test_cases(function_to_test, unit_test_package="pytest"):
starter_comment = "Below, each test case is represented by a tuple passed to the @pytest.mark.parametrize decorator"
prompt_to_generate_the_unit_test = f"""
Before going into the individual tests, let's first look at the complete suite of unit tests as a cohesive whole. We've added helpful comments to explain what each line does.
```python
import {unit_test_package} # used for our unit tests
{function_to_test}
#{starter_comment}"""
full_unit_test_prompt = prompt_to_explain_code + code_explaination + test_plan + prompt_to_generate_the_unit_test
return gpt35(model="gpt-3.5-turbo-instruct", prompt=full_unit_test_prompt, stop="```"), prompt_to_generate_the_unit_test
unit_test_response, prompt_to_generate_the_unit_test = generate_test_cases(code)
print(unit_test_response)
输出结果:

可以看到,测试代码不仅有正常情况下的测试,也包含了异常输入的测试。
这里我们最好还是再检查一下生成的测试代码的语法,这个可以通过 Python 的 AST 库来完成。不过需要注意,检查语法的时候,我们不仅需要生成的测试代码,也需要原来的功能代码,不然是没办法通过语法检查的。
代码示例:
import ast
code_start_index = prompt_to_generate_the_unit_test.find("```python\n") + len("```python\n")
code_output = prompt_to_generate_the_unit_test[code_start_index:] + unit_test_response
try:
ast.parse(code_output)
except SyntaxError as e:
print(f"Syntax error in generated code: {e}")
print(code_output)
最终输出的功能代码及其测试代码如下:
import pytest # used for our unit tests
def format_time(seconds):
hours = seconds // 3600
minutes = (seconds % 3600) // 60
seconds = seconds % 60
formatted_time = ""
if hours > 0:
formatted_time += str(hours) + "h"
if minutes > 0:
formatted_time += str(minutes) + "min"
if seconds > 0 or not formatted_time:
formatted_time += str(seconds) + "s"
return formatted_time
#Below, each test case is represented by a tuple passed to the @pytest.mark.parametrize decorator.
#The first element of the tuple is the input to the function, and the second element is the expected output.
@pytest.mark.parametrize(
"seconds, expected",
[
(60, "1min"), # test case for 1 minute
(3600, "1h"), # test case for 1 hour
(3661, "1h1min1s"), # test case for 1 hour, 1 minute, 1 second
(0, "0s"), # test case for 0 seconds
(-60, "-1min"), # test case for -1 minute
(-3600, "-1h"), # test case for -1 hour
(0.5, "0.5s"), # test case for 0.5 seconds
(1.5, "1.5s"), # test case for 1.5 seconds
(3661.5, "1h1min1.5s"), # test case for 1 hour, 1 minute, 1.5 seconds
(360000, "100h"), # test case for 100 hours
(3600000, "1000h"), # test case for 1000 hours
(36000000, "10000h"), # test case for 10000 hours
(1.5, "1.5s"), # test case for 1.5 seconds
(1.75, "1.75s"), # test case for 1.75 seconds
(1.99, "1.99s"), # test case for 1.99 seconds
],
)
def test_format_time(seconds, expected):
assert format_time(seconds) == expected # use assert statement to check if the function output matches the expected output
# Below, we use pytest's `raises` context manager to check if the function raises the expected error for invalid inputs.
def test_invalid_inputs():
with pytest.raises(TypeError):
format_time("abc") # check for TypeError when input is a string
with pytest.raises(TypeError):
format_time(None) # check for TypeError when input is None
with pytest.raises(TypeError):
format_time([]) # check for TypeError when input is a list
5.2.4 测试结果
把对应生成的代码,单独复制到一个 auto_unit_test.py 文件里面。然后去命令行里执行一下 pytest 这个命令,看看结果是怎样的。
首先安装 pytest 包:
pip install pytest
执行测试命令:
pytest
输出结果:


可以看到,16条测试用例中有3条没有通过。
尝试在 Colab 中运行一下没有通过的测试用例 format_time(-60),输出结果为 59min。可以看到,AI 生成的测试代码确实捕捉到了一个 Bug。
5.3 总结
生成整套测试代码的过程里,我们不需要人工地复制粘帖任何内容,全都是代码自动完成的,是一个“自动档”的过程。
在整个过程中,将一个问题拆分成多个提示语,循序渐进地让 AI 解释代码,构造测试用例,最后再根据代码的解释和设计的测试用例,生成最终的自动化测试。
多步提示语带来的一个好处,就是我们的内容是更加有条理、有逻辑的,也更符合我们平时写文字的方式,而不是一股脑地把各种要求都放在提示语的开头,这在解决复杂问题时往往效果不好。
5.4 练习:自动化生成测试封装代码
上述代码为演示过程分步骤实现了生成测试代码的每个过程,这里封装整个过程为一个完整函数。详细代码可参考官方 Cookbook 中示例:链接
代码如下:
# imports needed to run the code in this notebook
import ast # used for detecting whether generated Python code is valid
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
color_prefix_by_role = {
"system": "\033[0m", # gray
"user": "\033[0m", # gray
"assistant": "\033[92m", # green
}
def print_messages(messages, color_prefix_by_role=color_prefix_by_role) -> None:
"""Prints messages sent to or from GPT."""
for message in messages:
role = message["role"]
color_prefix = color_prefix_by_role[role]
content = message["content"]
print(f"{color_prefix}\n[{role}]\n{content}")
def print_message_delta(delta, color_prefix_by_role=color_prefix_by_role) -> None:
"""Prints a chunk of messages streamed back from GPT."""
if "role" in delta:
role = delta["role"]
color_prefix = color_prefix_by_role[role]
print(f"{color_prefix}\n[{role}]\n", end="")
elif "content" in delta:
content = delta["content"]
print(content, end="")
else:
pass
# example of a function that uses a multi-step prompt to write unit tests
def unit_tests_from_function(
function_to_test: str, # Python function to test, as a string
unit_test_package: str = "pytest", # unit testing package; use the name as it appears in the import statement
approx_min_cases_to_cover: int = 7, # minimum number of test case categories to cover (approximate)
print_text: bool = False, # optionally prints text; helpful for understanding the function & debugging
explain_model: str = "gpt-3.5-turbo", # model used to generate text plans in step 1
plan_model: str = "gpt-3.5-turbo", # model used to generate text plans in steps 2 and 2b
execute_model: str = "gpt-3.5-turbo", # model used to generate code in step 3
temperature: float = 0.4, # temperature = 0 can sometimes get stuck in repetitive loops, so we use 0.4
reruns_if_fail: int = 1, # if the output code cannot be parsed, this will re-run the function up to N times
) -> str:
"""Returns a unit test for a given Python function, using a 3-step GPT prompt."""
# Step 1: Generate an explanation of the function
# create a markdown-formatted message that asks GPT to explain the function, formatted as a bullet list
explain_system_message = {
"role": "system",
"content": "You are a world-class Python developer with an eagle eye for unintended bugs and edge cases. You carefully explain code with great detail and accuracy. You organize your explanations in markdown-formatted, bulleted lists.",
}
explain_user_message = {
"role": "user",
"content": f"""Please explain the following Python function. Review what each element of the function is doing precisely and what the author's intentions may have been. Organize your explanation as a markdown-formatted, bulleted list.
```python
{function_to_test}
```""",
}
explain_messages = [explain_system_message, explain_user_message]
if print_text:
print_messages(explain_messages)
explanation_response = client.chat.completions.create(model=explain_model,
messages=explain_messages,
temperature=temperature,
stream=True)
explanation = ""
for chunk in explanation_response:
delta = chunk.choices[0].delta
if print_text:
print_message_delta(delta)
if "content" in delta:
explanation += delta.content
explain_assistant_message = {"role": "assistant", "content": explanation}
# Step 2: Generate a plan to write a unit test
# Asks GPT to plan out cases the units tests should cover, formatted as a bullet list
plan_user_message = {
"role": "user",
"content": f"""A good unit test suite should aim to:
- Test the function's behavior for a wide range of possible inputs
- Test edge cases that the author may not have foreseen
- Take advantage of the features of `{unit_test_package}` to make the tests easy to write and maintain
- Be easy to read and understand, with clean code and descriptive names
- Be deterministic, so that the tests always pass or fail in the same way
To help unit test the function above, list diverse scenarios that the function should be able to handle (and under each scenario, include a few examples as sub-bullets).""",
}
plan_messages = [
explain_system_message,
explain_user_message,
explain_assistant_message,
plan_user_message,
]
if print_text:
print_messages([plan_user_message])
plan_response = client.chat.completions.create(model=plan_model,
messages=plan_messages,
temperature=temperature,
stream=True)
plan = ""
for chunk in plan_response:
delta = chunk.choices[0].delta
if print_text:
print_message_delta(delta)
if "content" in delta:
explanation += delta.content
plan_assistant_message = {"role": "assistant", "content": plan}
# Step 2b: If the plan is short, ask GPT to elaborate further
# this counts top-level bullets (e.g., categories), but not sub-bullets (e.g., test cases)
num_bullets = max(plan.count("\n-"), plan.count("\n*"))
elaboration_needed = num_bullets < approx_min_cases_to_cover
if elaboration_needed:
elaboration_user_message = {
"role": "user",
"content": f"""In addition to those scenarios above, list a few rare or unexpected edge cases (and as before, under each edge case, include a few examples as sub-bullets).""",
}
elaboration_messages = [
explain_system_message,
explain_user_message,
explain_assistant_message,
plan_user_message,
plan_assistant_message,
elaboration_user_message,
]
if print_text:
print_messages([elaboration_user_message])
elaboration_response = client.chat.completions.create(model=plan_model,
messages=elaboration_messages,
temperature=temperature,
stream=True)
elaboration = ""
for chunk in elaboration_response:
delta = chunk.choices[0].delta
if print_text:
print_message_delta(delta)
if "content" in delta:
explanation += delta.content
elaboration_assistant_message = {"role": "assistant", "content": elaboration}
# Step 3: Generate the unit test
# create a markdown-formatted prompt that asks GPT to complete a unit test
package_comment = ""
if unit_test_package == "pytest":
package_comment = "# below, each test case is represented by a tuple passed to the @pytest.mark.parametrize decorator"
execute_system_message = {
"role": "system",
"content": "You are a world-class Python developer with an eagle eye for unintended bugs and edge cases. You write careful, accurate unit tests. When asked to reply only with code, you write all of your code in a single block.",
}
execute_user_message = {
"role": "user",
"content": f"""Using Python and the `{unit_test_package}` package, write a suite of unit tests for the function, following the cases above. Include helpful comments to explain each line. Reply only with code, formatted as follows:
```python
# imports
import {unit_test_package} # used for our unit tests
{{insert other imports as needed}}
# function to test
{function_to_test}
# unit tests
{package_comment}
{{insert unit test code here}}
```""",
}
execute_messages = [
execute_system_message,
explain_user_message,
explain_assistant_message,
plan_user_message,
plan_assistant_message,
]
if elaboration_needed:
execute_messages += [elaboration_user_message, elaboration_assistant_message]
execute_messages += [execute_user_message]
if print_text:
print_messages([execute_system_message, execute_user_message])
execute_response = client.chat.completions.create(model=execute_model,
messages=execute_messages,
temperature=temperature,
stream=True)
execution = ""
for chunk in execute_response:
delta = chunk.choices[0].delta
if print_text:
print_message_delta(delta)
if delta.content:
execution += delta.content
# check the output for errors
code = execution.split("```python")[1].split("```")[0].strip()
try:
ast.parse(code)
except SyntaxError as e:
print(f"Syntax error in generated code: {e}")
if reruns_if_fail > 0:
print("Rerunning...")
return unit_tests_from_function(
function_to_test=function_to_test,
unit_test_package=unit_test_package,
approx_min_cases_to_cover=approx_min_cases_to_cover,
print_text=print_text,
explain_model=explain_model,
plan_model=plan_model,
execute_model=execute_model,
temperature=temperature,
reruns_if_fail=reruns_if_fail
- 1, # decrement rerun counter when calling again
)
# return the unit test as a string
return code
给定样例代码如下:
example_function = """def pig_latin(text):
def translate(word):
vowels = 'aeiou'
if word[0] in vowels:
return word + 'way'
else:
consonants = ''
for letter in word:
if letter not in vowels:
consonants += letter
else:
break
return word[len(consonants):] + consonants + 'ay'
words = text.lower().split()
translated_words = [translate(word) for word in words]
return ' '.join(translated_words)
"""
unit_tests = unit_tests_from_function(
example_function,
approx_min_cases_to_cover=10
)
print(unit_tests)
输出生成的测试代码如下:

6. Langchain 库(链式调用)及其应用
6.1 链式调用介绍
OpenAI 的大语言模型只是提供了简单的 Completion 和 Embedding 这样两个核心接口。通过合理使用这两个接口,我们完成了各种各样复杂的任务:
- 通过提示语(Prompt)里包含历史的聊天记录,我们能够让 AI 根据上下文正确地回答问题。
- 通过将 Embedding 提前索引好存起来,我们能够让 AI 根据外部知识回答问题。
- 通过多轮对话,将 AI 返回的答案放在新的问题里,我们能够让 AI 帮我们给自己的代码撰写单元测试。
这些方法,也是一个实用的自然语言类应用里常见的模式。开源社区就有人将这些常见的需求和模式抽象了出来,开发了一个叫做 Langchain 的开源库。
6.2 使用 Langchain 的链式调用
llama-index 专注于为大语言模型的应用构建索引,虽然 Langchain 也有类似的功能,但这一点并不是 Langchain 的主要卖点。
Langchain 官方文档:链接
Pinecone 制作的 Langchain AI Handbook:链接
6.2.1 人工链式调用
我们知道,GPT-3 的基础模型里面,中文的语料很少。用中文问它问题,很多时候它回答得不好。所以有时候要迂回处理一下,先把中文问题给 AI,请它翻译成英文,然后再把英文问题贴进去提问,得到一个英文答案。最后,再请 AI 把英文答案翻译回中文。
比如,下面的截图里,我就请它简单介绍一下 Stable Diffusion 的原理是什么。



如果用 API 来实现上述过程,其实就是一个链式调用的过程:
- 先调用 OpenAI,把翻译请求和原始问题组合在一起发送给 AI,完成问题的中译英。
- 把拿到的翻译好的英文问题发送给 OpenAI,得到英文答案。
- 最后再把英文答案,和对应要求 AI 翻译答案的请求组合在一起,完成答案的英译中。
6.2.2 LLMChain 链式调用
针对上述的人工过程,我们可以使用 Langchain 来实现,主要使用 Langchain 的三个包:
- LLM,也就是我们使用哪个大语言模型来回答我们提出的问题。这里我们还是使用 OpenAIChat,也就是 gpt-3.5-turbo 模型。
- PromptTemplate,和 llama-index 的 PromptTemplate 是一个东西。它可以定义一个提示语模版,里面能够定义一些可以动态替换的变量。比如,下面代码里的 question_prompt 这个模版里,我们就定义了一个叫做 question 的变量,因为我们每次问的问题都会不一样。事实上,llamd-index 里面的 PromptTemplate 就是对 Langchain 的 PromptTemplate 做了一层简单的封装。
- LLMChain,它的构造函数接收一个 LLM 和一个 PromptTemplate 作为参数。构造完成之后,可以直接调用里面的 run 方法,将 PromptTemplate 需要的变量,用 K=>V 对的形式传入进去。返回的结果,就是 LLM 给我们的答案。
安装 langchain 包:
!pip install langchain
!pip install langchain-openai
代码如下:
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
llm = ChatOpenAI(model_name="gpt-3.5-turbo", max_tokens=2048, temperature=0.5)
en_to_zh_prompt = PromptTemplate(
template="请把下面这句话翻译成英文: \n\n {question}?", input_variables=["question"]
)
question_prompt = PromptTemplate(
template = "{english_question}", input_variables=["english_question"]
)
zh_to_cn_prompt = PromptTemplate(
input_variables=["english_answer"],
template="请把下面这一段翻译成中文: \n\n{english_answer}?",
)
question_translate_chain = LLMChain(llm=llm, prompt=en_to_zh_prompt, output_key="english_question")
english = question_translate_chain.run(question="请你作为一个机器学习的专家,介绍一下CNN的原理。")
print(english)
qa_chain = LLMChain(llm=llm, prompt=question_prompt, output_key="english_answer")
english_answer = qa_chain.run(english_question=english)
print(english_answer)
answer_translate_chain = LLMChain(llm=llm, prompt=zh_to_cn_prompt)
answer = answer_translate_chain.run(english_answer=english_answer)
print(answer)
输出结果:

上面这段代码,我们似乎只是对 OpenAI 的 API 做了一层封装而已。我们构建了 3 个 LLMChain,然后按照顺序调用,每次拿到答案之后,再作为输入,交给下一个 LLM 调用。
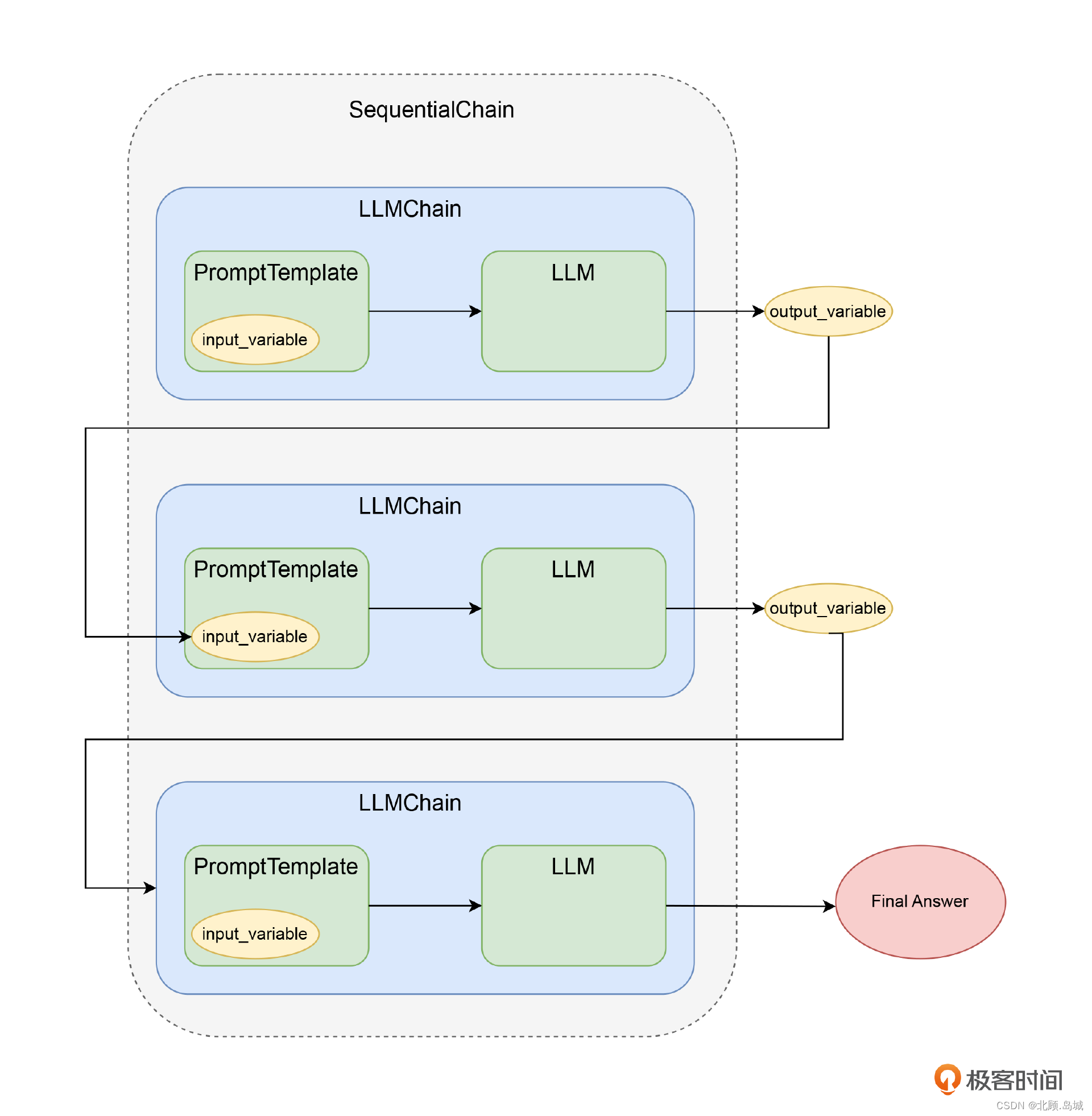
如果想要使用真正的“链式调用“功能,需要使用一个叫做 SimpleSequentialChain 的 LLMChain 类,把我们要按照顺序依次调用的三个 LLMChain 放在一个数组里,传给这个类的构造函数。
然后我们调用这个对象的 run 方法,把我们用中文问的问题交给它。这个时候 SimpleSequentialChain 就会按照顺序开始调用 chains 这个数组参数里面包含的其他 LLMChain。并且每一次调用的结果都会存储在这个 Chain 构造时定义的 output_key 参数里。而下一个调用的 LLMChain 里面模版内的变量如果有和之前的 output_key 名字相同的,就会用 output_key 里存入的内容替换掉模版内变量所在的占位符。这时我们只向这个 SimpleSequentialChain 调用一次 run 方法,把一开始的问题交给它,后面根据答案去问新的问题,这个 LLMChain 会自动地链式搞定。
这里把日志的 Verbose 模式打开,在输出的过程中可以看到其实这个 LLMChain 是调用了三次,并且中间两次的返回结果也可以一并看到。
代码如下:
from langchain.chains import SimpleSequentialChain
chinese_qa_chain = SimpleSequentialChain(
chains=[question_translate_chain, qa_chain, answer_translate_chain], input_key="question",
verbose=True)
answer = chinese_qa_chain.run(question="请你作为一个机器学习的专家,介绍一下CNN的原理。")
print(answer)
输出结果:

上述链式调用代码中有一点要注意,就是一个 LLMChain 里,所使用的 PromptTemplate 里的输入参数,之前必须在 LLMChain 里,通过 output_key 定义过。不然,这个变量没有值,程序就会报错。
6.2.3 支持多变量输入的链式调用
不是只能用前一个 LLMChain 的输出作为后一个 LLMChain 的输入。我们完全可以连续问多个问题,然后把这些问题的答案,作为后续问题的输入来继续处理。
示例代码:
from langchain.chains import SequentialChain
q1_prompt = PromptTemplate(
input_variables=["year1"],
template="{year1}年的欧冠联赛的冠军是哪支球队,只说球队名称。"
)
q2_prompt = PromptTemplate(
input_variables=["year2"],
template="{year2}年的欧冠联赛的冠军是哪支球队,只说球队名称。"
)
q3_prompt = PromptTemplate(
input_variables=["team1", "team2"],
template="{team1}和{team2}哪只球队获得欧冠的次数多一些?"
)
chain1 = LLMChain(llm=llm, prompt=q1_prompt, output_key="team1")
chain2 = LLMChain(llm=llm, prompt=q2_prompt, output_key="team2")
chain3 = LLMChain(llm=llm, prompt=q3_prompt)
sequential_chain = SequentialChain(chains=[chain1, chain2, chain3], input_variables=["year1", "year2"], verbose=True)
answer = sequential_chain.run(year1=2000, year2=2010)
print(answer)
输出结果:

该例中我们定义了两个 PromptTemplate 和对应的 LLMChain,各自接收一个年份作为输入,回答这两个年份的欧冠冠军。然后将两个队名作为输入,放到第三个问题里,让 AI 告诉我们这两支球队哪一支获得欧冠的次数多一些。只需要在我们的 SequentialChain 里输入两个年份,就能通过三次回答得到答案。
6.2.4 实践:使用 Langchain 实现自动化撰写单元测试
前面我们通过多步提示语自动给代码写单元测试,这里使用 Langchain 可以顺序地通过多个 Prompt 调用 OpenAI 的 GPT 模型实现同样的功能,同时还补上了 AST 语法解析失败之后自动重试的能力。
代码如下:
from langchain_openai import OpenAI
from langchain.chains import SequentialChain
def write_unit_test(function_to_test, unit_test_package = "pytest"):
# 解释源代码的步骤
explain_code = """"# How to write great unit tests with {unit_test_package}
In this advanced tutorial for experts, we'll use Python 3.10 and `{unit_test_package}` to write a suite of unit tests to verify the behavior of the following function.
```python
{function_to_test}
```
Before writing any unit tests, let's review what each element of the function is doing exactly and what the author's intentions may have been.
- First,"""
explain_code_template = PromptTemplate(
input_variables=["unit_test_package", "function_to_test"],
template=explain_code
)
explain_code_llm = OpenAI(model_name="gpt-3.5-turbo-instruct", temperature=0.4, max_tokens=1000,
top_p=1, stop=["\n\n", "\n\t\n", "\n \n"])
explain_code_step = LLMChain(llm=explain_code_llm, prompt=explain_code_template, output_key="code_explaination")
# 创建测试计划示例的步骤
test_plan = """
A good unit test suite should aim to:
- Test the function's behavior for a wide range of possible inputs
- Test edge cases that the author may not have foreseen
- Take advantage of the features of `{unit_test_package}` to make the tests easy to write and maintain
- Be easy to read and understand, with clean code and descriptive names
- Be deterministic, so that the tests always pass or fail in the same way
`{unit_test_package}` has many convenient features that make it easy to write and maintain unit tests. We'll use them to write unit tests for the function above.
For this particular function, we'll want our unit tests to handle the following diverse scenarios (and under each scenario, we include a few examples as sub-bullets):
-"""
test_plan_template = PromptTemplate(
input_variables=["unit_test_package", "function_to_test", "code_explaination"],
template= explain_code + "{code_explaination}" + test_plan
)
test_plan_llm = OpenAI(model_name="gpt-3.5-turbo-instruct", temperature=0.4, max_tokens=1000,
top_p=1, stop=["\n\n", "\n\t\n", "\n \n"])
test_plan_step = LLMChain(llm=test_plan_llm, prompt=test_plan_template, output_key="test_plan")
# 撰写测试代码的步骤
starter_comment = "Below, each test case is represented by a tuple passed to the @pytest.mark.parametrize decorator"
prompt_to_generate_the_unit_test = """
Before going into the individual tests, let's first look at the complete suite of unit tests as a cohesive whole. We've added helpful comments to explain what each line does.
```python
import {unit_test_package} # used for our unit tests
{function_to_test}
#{starter_comment}"""
unit_test_template = PromptTemplate(
input_variables=["unit_test_package", "function_to_test", "code_explaination", "test_plan", "starter_comment"],
template= explain_code + "{code_explaination}" + test_plan + "{test_plan}" + prompt_to_generate_the_unit_test
)
unit_test_llm = OpenAI(model_name="gpt-3.5-turbo-instruct", temperature=0.4, max_tokens=1000, stop="```")
unit_test_step = LLMChain(llm=unit_test_llm, prompt=unit_test_template, output_key="unit_test")
sequential_chain = SequentialChain(chains=[explain_code_step, test_plan_step, unit_test_step],
input_variables=["unit_test_package", "function_to_test", "starter_comment"], verbose=True)
answer = sequential_chain.run(unit_test_package=unit_test_package, function_to_test=function_to_test, starter_comment=starter_comment)
return f"""#{starter_comment}""" + answer
code = """
def format_time(seconds):
hours = seconds // 3600
minutes = (seconds % 3600) // 60
seconds = seconds % 60
formatted_time = ""
if hours > 0:
formatted_time += str(hours) + "h"
if minutes > 0:
formatted_time += str(minutes) + "min"
if seconds > 0 or not formatted_time:
formatted_time += str(seconds) + "s"
return formatted_time
"""
import ast
def write_unit_test_automatically(code, retry=3):
unit_test_code = write_unit_test(code)
all_code = code + unit_test_code
tried = 0
while tried < retry:
try:
ast.parse(all_code)
return all_code
except SyntaxError as e:
print(f"Syntax error in generated code: {e}")
all_code = code + write_unit_test(code)
tried += 1
print(write_unit_test_automatically(code))
输出结果:

可以看到,我们把解释代码、生成测试计划,以及最终生成测试代码,变成了三个 LLMChain。每一步的输入,都来自上一步的输出。这个输入既包括上一步的 Prompt Template 和这一步的 Prompt Template 的组合,也包括过程中的一些变量,这些变量是上一步执行的结果作为输入变量传递进来的。最终,我们可以使用 SequentialChain 来自动地按照这三个步骤,执行 OpenAI 的 API 调用。
整个过程通过 write_unit_test 这个函数给封装起来了。对于重试,我们则是通过一个 while 循环来调用 write_unit_test。拿到的结果和输入的代码拼装在一起,交给 AST 库做解析。如果解析通不过,则重试整个单元测试生成的过程,直到达到我们最大的重试次数为止。
LangChain 的这个分多个步骤调用 OpenAI 模型的能力,能够帮助我们通过 AI 完成复杂的任务,并且将整个任务的完成过程定义成了一个固定的流程模版。
6.3 Langchain 的 LLMChain 功能
ChatGPT 具有 Plugins 这个插件机制。通过 Plugins,ChatGPT 可以浏览整个互联网,还可以接上 Wolfram 这样的科学计算工具,能够实现很多原先光靠大语言模型解决不好的问题。而通过 LangChain 也能实现这些类似的功能。
6.3.1 数学运算(LLMMathChain)
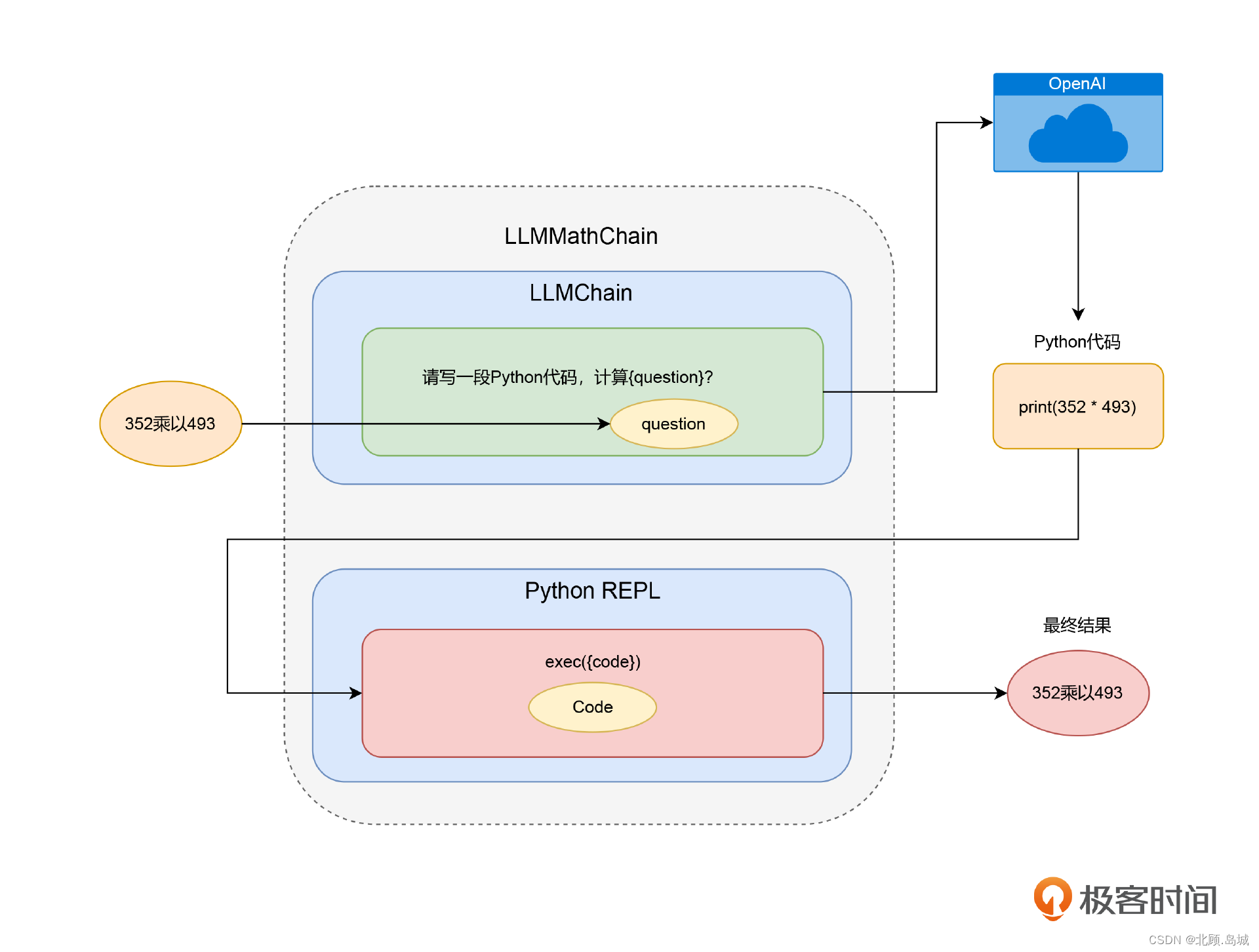
早期的 ChatGPT 模型在计算三位数乘法时并不能准确计算(这个问题在现在的 gpt-3.5-turbo 及以上的模型上几乎已经不存在),我们可以通过让它写一段利用 Python 计算这个数学式子的代码来解决,同时在之后自动调用一个 Python 解释器来让整个过程自动完成。
对比示例代码:
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
llm = ChatOpenAI(model_name="gpt-3.5-turbo", max_tokens=2048, temperature=0.5)
multiply_prompt = PromptTemplate(template="请计算一下{question}是多少?", input_variables=["question"])
math_chain = LLMChain(llm=llm, prompt=multiply_prompt, output_key="answer")
answer = math_chain.run({"question": "352乘以493"})
print("OpenAI API 说答案是:", answer)
python_answer = 352 * 493
print("Python 说答案是:", python_answer)
输出结果:

自动执行Python示例代码:
multiply_by_python_prompt = PromptTemplate(template="请写一段Python代码,计算{question}?", input_variables=["question"])
math_chain = LLMChain(llm=llm, prompt=multiply_by_python_prompt, output_key="answer")
answer_code = math_chain.run({"question": "352乘以493"})
print(answer_code)
from langchain.utilities import PythonREPL
python_repl = PythonREPL()
result = python_repl.run(answer_code)
print(result)
输出结果:

可以看到,LangChain 里面内置了一个 utilities 的包,里面包含了 PythonREPL 这个类,可以实现对 Python 解释器的调用。如果你去翻看一下对应代码的源码的话,它其实就是简单地调用了一下系统自带的 exec 方法,来执行 Python 代码。
utilities 里面还有很多其他的类,能够实现很多功能,比如可以直接运行 Bash 脚本,调用 Google Search 的 API 等等。详细可参考 LangChain 的文档:链接
上述过程其实也是一种链式调用,只是调用链里面的第二步不是去访问 OpenAI 的 API 而已。对于这些工具能力,LangChain 也把它们封装成了 LLMChain 的形式。比如刚才的数学计算问题,是一个先生成 Python 脚本,再调用 Python 解释器的过程,LangChain 就把这个过程封装成了一个叫做 LLMMathChain 的 LLMChain。不需要自己去生成代码,再调用 PythonREPL,只要直接调用 LLMMathChain 即可完成整个过程。
示例代码:
from langchain import LLMMathChain
llm_math = LLMMathChain(llm=llm, verbose=True)
result = llm_math.run("请计算一下352乘以493是多少?")
print(result)
输出结果:

LangChain 也把上面 utilities 包里面的很多功能,都封装成了 Utility Chains。比如,SQLDatabaseChain 可以直接根据你的数据库生成 SQL,然后获取数据,LLMRequestsChain 可以通过 API 调用外部系统,获得想要的答案。可以直接在 LangChain 关于 Utility Chains 的文档里面,找到有哪些工具可以用,地址:链接。
6.3.2 调用外部 API(LLMRequestsChain)
之前在介绍 llama-index 的时候,我们已经介绍过一种为 AI 引入外部知识的方法了,那就是计算这些外部知识的 Embedding,然后作为索引先保存下来。但是,这只适用于处理那些预先准备好会被问到的知识,比如一本书、一篇论文。这些东西,内容多但是固定,也不存在时效性问题,我们可以提前索引好,而且用户问的问题往往也有很强的相似性。
但是,对于时效性强的问题,这个方法不太适用,因为我们可能没有必要不停地更新索引。比如,你想要知道实时的天气情况,我们不太可能把全球所有城市最新的天气信息每隔几分钟都索引一遍。
这时可以使用 LLMRequestsChain,通过一个 HTTP 请求来得到问题的答案。最简单粗暴的一个办法,就是直接通过一个 HTTP 请求来问一下 Google。
示例代码:
from langchain.chains import LLMRequestsChain
template = """在 >>> 和 <<< 直接是来自Google的原始搜索结果.
请把对于问题 '{query}' 的答案从里面提取出来,如果里面没有相关信息的话就说 "找不到"
请使用如下格式:
Extracted:<answer or "找不到">
>>> {requests_result} <<<
Extracted:"""
PROMPT = PromptTemplate(
input_variables=["query", "requests_result"],
template=template,
)
requests_chain = LLMRequestsChain(llm_chain = LLMChain(llm=ChatOpenAI(temperature=0), prompt=PROMPT))
question = "今天上海的天气怎么样?"
inputs = {
"query": question,
"url": "https://www.google.com/search?q=" + question.replace(" ", "+")
}
result=requests_chain(inputs)
print(result)
print(result['output'])
输出结果:

在上述代码中,基于 LLMRequestsChain,我们用到了之前使用过的几个技巧:
- 因为是简单粗暴地搜索 Google,但是想要的是一个有价值的天气信息,而不是整个网页。所以,我们还需要通过 ChatGPT 把网页搜索结果里面的答案给找出来。所以我们定义了一个 PromptTemplate,通过一段提示语,让 OpenAI 为我们在搜索结果里面,找出问题的答案,而不是去拿原始的 HTML 页面。
- 使用了 LLMRequestsChain,并且把刚才 PromptTemplate 构造的一个普通的 LLMChain,作为构造函数的一个参数,传给 LLMRequestsChain,帮助我们在搜索之后处理搜索结果。
- 对应的搜索词,通过 query 这个参数传入,对应的原始搜索结果,则会默认放到 requests_results 里。而通过我们自己定义的 PromptTemplate 抽取出来的最终答案,则会放到 output 这个输出参数里面。
6.3.3 数据格式转换(TransformChain)
有了实时的外部数据就又有很多做应用的创意了。比如说,我们可以根据气温来推荐大家穿什么衣服。我们可以要求如果最低温度低于 0 度,就要推荐用户去穿羽绒服。或者,根据是否下雨来决定要不要提醒用户出门带伞。
在现在的返回结果里,天气信息(天气、温度、风力)只是一段文本,而不是可以直接获取的 JSON 格式。当然,我们可以在 LLMChain 里面再链式地调用一次 OpenAI 的接口,把这段文本转换成 JSON 格式。但是,这样做的话,一来还要消耗更多的 Token、花更多的钱,二来这也会进一步增加程序需要运行的时间,毕竟一次往返的网络请求也是很慢的。这里的文本格式其实很简单,我们完全可以通过简单的字符串处理完成解析。
这里我们实现一个 parse_weather_info 函数,可以把前面 LLMRequestsChain 的输出结果,解析成一个 dict。然后使用一个叫做 TransformChain 的解决方案传到 LLMChain 的链式调用的最后。
原专栏给出的解析天气信息的代码如下,因为使用的模型返回的结果不同,因此解析方式不同:
def parse_weather_info(weather_info: str) -> dict: # 将天气信息拆分成不同部分 parts = weather_info.split('; ') # 解析天气 weather = parts[0].strip() # 解析温度范围,并提取最小和最大温度 temperature_range = parts[1].strip().replace('℃', '').split('~') temperature_min = int(temperature_range[0]) temperature_max = int(temperature_range[1]) # 解析风向和风力 wind_parts = parts[2].split(' ') wind_direction = wind_parts[0].strip() wind_force = wind_parts[1].strip() # 返回解析后的天气信息字典 weather_dict = { 'weather': weather, 'temperature_min': temperature_min, 'temperature_max': temperature_max, 'wind_direction': wind_direction, 'wind_force': wind_force } return weather_dict输出结果:
示例代码:
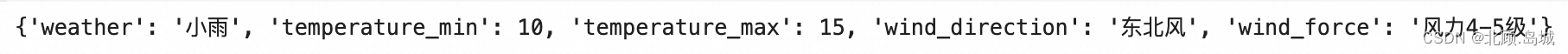
from langchain.chains import TransformChain, SequentialChain
def parse_weather_info(weather_info: str) -> dict:
# 将天气信息拆分成不同部分
parts = weather_info.strip().split('。')
# 解析天气
weather = parts[0].strip()
# 解析温度范围,并提取最小和最大温度
temperature_range = parts[1].strip().replace('℃', '').split('/')
temperature_min = int(temperature_range[0])
temperature_max = int(temperature_range[1])
if temperature_min > temperature_max:
temperature_min, temperature_max = temperature_max, temperature_min
# 返回解析后的天气信息字典
weather_dict = {
'weather': weather,
'temperature_min': temperature_min,
'temperature_max': temperature_max,
}
return weather_dict
def transform_func(inputs: dict) -> dict:
text = inputs["output"]
print(text)
return {"weather_info" : parse_weather_info(text)}
transformation_chain = TransformChain(input_variables=["output"],
output_variables=["weather_info"], transform=transform_func)
final_chain = SequentialChain(chains=[requests_chain, transformation_chain],
input_variables=["query", "url"], output_variables=["weather_info"])
final_result = final_chain.run(inputs)
print(final_result)
输出结果:

注:在 requests_chain 后面跟上一个 transformation_chain,我们就能把结果解析成 dict,供后面其他业务使用结构化的数据。
上述代码逻辑如下:
- 先定义一个 transform_func,对 parse_weather_info 函数做了一下简单的封装。它的输入,是整个 LLMChain 里,执行到 TransformChain 之前的整个输出结果的 dict。我们前面看到整个 LLMRequestsChain 里面的天气信息的文本内容,是通过 output 这个 key 拿到的,所以这里我们也是先通过它来拿到天气信息的文本内容,再调用 parse_weather_info 解析,并且把结果输出到 weather_info 这个字段里。
- 定义一个 TransformChain,里面的输入参数就是 output,输出参数就是 weather_info。
- 通过上面用过的 SequentialChain,将前面的 LLMRequestsChain 和这里的 TransformChain 串联到一起,变成一个新的叫做 final_chain 的 LLMChain。
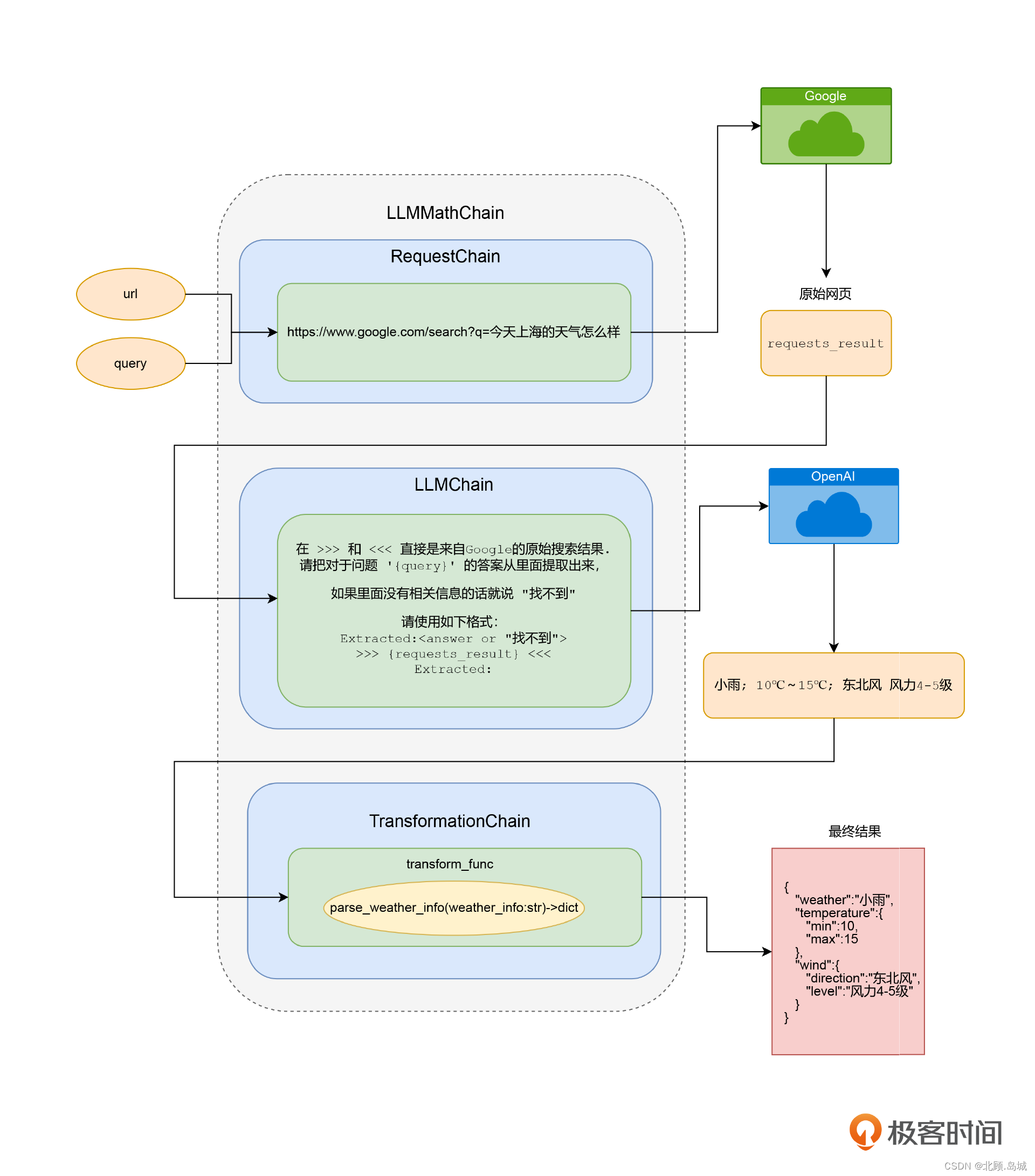
这里的 final_chain 做了三件事:
- 通过一个 HTTP 请求,根据搜索词拿到 Google 的搜索结果页。
- 把定义的 Prompt 提交给 OpenAI,然后把搜索的问题和结果页都发给了 OpenAI,让它从里面提取出搜索结果页里面的天气信息。
- 通过 transform_func 解析拿到的天气信息的文本,被转换成一个 dict。
6.3.4 使用 VectorDBQA 的索引
还有一个常用的 LLMChain,就是之前 llama-index 的使用场景,也就是针对自己的资料库进行问答。我们预先把资料库索引好,然后每次用户来问问题的时候,都是先到这个资料库里搜索,再把问题和答案一并交给 AI,让它去组织语言回答。
这里我们使用之前的电商 FAQ 的数据集:
!wget -P data https://github.com/xuwenhao/geektime-ai-course/raw/main/data/faq/ecommerce_faq.txt
安装下载相关包:
!pip install faiss-cpu
!python -m spacy download zh_core_web_sm
示例代码:
from langchain.vectorstores import FAISS
from langchain.text_splitter import SpacyTextSplitter
from langchain import VectorDBQA
from langchain.document_loaders import TextLoader
from langchain_openai import OpenAI, OpenAIEmbeddings
llm = OpenAI(temperature=0)
loader = TextLoader('./data/ecommerce_faq.txt')
documents = loader.load()
text_splitter = SpacyTextSplitter(chunk_size=256, pipeline="zh_core_web_sm")
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
docsearch = FAISS.from_documents(texts, embeddings)
faq_chain = VectorDBQA.from_chain_type(llm=llm, vectorstore=docsearch, verbose=True)
注:上面的代码创建了一个基于 FAISS 进行向量存储的 docsearch 的索引,以及基于这个索引的 VectorDBQA 这个 LLMChain。
上述代码逻辑是,首先我们通过一个 TextLoader 把文件加载进来,还通过 SpacyTextSplitter 给文本分段,确保每个分出来的 Document 都是一个完整的句子。因为这里的文档是电商 FAQ 的内容,都比较短小精悍,所以我们设置的 chunk_size 只有 256。然后,我们定义了使用 OpenAIEmbeddings 来给文档创建 Embedding,通过 FAISS 把它存储成一个 VectorStore。最后,我们通过 VectorDBQA 的 from_chain_type 定义了一个 LLM。
尝试问两个不同类型的问题:
question = "请问你们的货,能送到三亚吗?大概需要几天?"
result = faq_chain.run(question)
print(result)
question = "请问你们的退货政策是怎么样的?"
result = faq_chain.run(question)
print(result)
输出结果:

在 VectorDBQA 这个 LLMChain 背后,其实也是通过一系列的链式调用,来完成搜索 VectorStore,再向 AI 发起 Completion 请求这样两个步骤的。
6.3.5 练习:访问数据库(SQLDatabaseChain)
官方文档的示例:链接
注意:SQLDatabaseChain 已经迁移到了 langchain-experimental 包下
首先安装相关包:
!pip install langchain-experimental
这里使用 Chinook 数据库,该数据库详细介绍地址:链接
下载 sql 和执行生成该数据集的操作需在本地完成,同时本地需安装有 sqlite3 工具(安装 sqlite3 方式可自行查询):
wget 'https://github.com/lerocha/chinook-database/releases/download/v1.4.2/Chinook_Sqlite.sql'
sqlite3 -bail -cmd '.read Chinook_Sqlite.sql' -cmd '.save Chinook.db' -cmd '.quit'
之后将生成的 Chinook.db 数据集文件上传至 Colab:

执行代码示例:
from langchain_experimental.sql import SQLDatabaseChain
from langchain_community.utilities import SQLDatabase
from langchain_community.llms import OpenAI
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
db_chain = SQLDatabaseChain.from_llm(OpenAI(), db, verbose=True)
db_chain.run("Describe the schema of the playlist table")
db_chain.run("Describe the playlists table")
db_chain.run("List the total sales per country. Which country's customers spent the most?")
输出结果:

可以看到,这里的 SQLDatabaseChain 在链式调用过程中首先根据输入生成对应的 SQL 查询语句,然后在 sqlite 数据库中查询到相关数据集后分析查询结果。
6.3.6 总结
LLMChain 可以把解决一个问题需要的多个步骤串联到一起。这个步骤可以是调用我们的语言模型,也可以是调用一个外部 API,或者在内部定义一个 Python 函数。这大大增强了我们利用大语言模型的能力,特别是能够弥补它的很多不足之处,比如缺少有时效的信息,通过 HTTP 调用比较慢等等。
这些能力大大增强了 AI 的实用性,解决了几个之前大语言模型处理得不好的问题,包括数学计算能力、实时数据能力、和现有程序结合的能力,以及搜索属于自己的资料库的能力。你完全可以定义自己需要的 LLMChain,通过程序来完成各种任务,然后合理地组合不同类型的 LLMChain 对象,来实现连 ChatGPT 都做不到的事情。而 ChatGPT Plugins 的实现机制,其实也是类似的。
有人直接为 Langchain 做了一个可以拖拽的图形界面叫做 LangFlow,可以尝试体验,地址:链接
6.4 Langchain 的 Memory 功能
LangChain 并不是只有链式调用这样一个核心功能,它还封装了很多其他能力,来方便我们开发 AI 应用。比如,让 AI 能够拥有“记忆力”,也就是记住我们聊天上下文的能力。之前我们做的聊天机器人为了知道整个聊天的上下文,我们需要把历史的对话记录都传给它。但是,因为能够接收的 Token 数量有上限,所以我们只能设定一个参数,只保留最后几轮对话。
6.4.1 滑动窗口记忆(BufferWindowMemory)
这个基于一个固定长度的滑动窗口的“记忆”功能,被直接内置在 LangChain 里面了。在 Langchain 里,把对于整个对话过程的上下文叫做 Memory。任何一个 LLMChain,我们都可以给它加上一个 Memory,来让它记住最近的对话上下文。
和之前的聊天机器人类似,我们定义了一个 PromptTemplate 来输入我们的指示。然后,在 LLMChain 构造的时候,我们为它指定了一个叫做 ConversationBufferWindowMemory 的 memory 对象,并且为这个 memory 对象定义了 k=3,也就是只保留最近三轮的对话内容。
代码如下:
from langchain.memory import ConversationBufferWindowMemory
from langchain import LLMChain, PromptTemplate
from langchain_openai import OpenAI
template = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文
2. 回答限制在100个字以内
{chat_history}
Human: {human_input}
Chatbot:"""
prompt = PromptTemplate(
input_variables=["chat_history", "human_input"],
template=template
)
memory = ConversationBufferWindowMemory(memory_key="chat_history", k=3)
llm_chain = LLMChain(
llm=OpenAI(),
prompt=prompt,
memory=memory,
verbose=True
)
llm_chain.predict(human_input="你是谁?")
输出结果:

和它连续进行几轮对话,就会发现到第四轮的时候它还是能够记得我们问它的第一个问题是“你是谁”,但是第 5 轮的时候,已经变成“鱼香肉丝怎么做?”了。这就是因为我们选择只保留过去 3 轮对话。
llm_chain.predict(human_input="鱼香肉丝怎么做?")
llm_chain.predict(human_input="那宫保鸡丁呢?")
llm_chain.predict(human_input="我问你的第一个问题是什么?")
输出:

llm_chain.predict(human_input="我问你的第一个问题是什么?")
输出:

这里可以直接调用 memory 的 load_memory_variables 方法,它会直接返回 memory 里实际记住的对话内容。
memory.load_memory_variables({})
输出:
{'chat_history': 'Human: 那宫保鸡丁呢?\nAI: 宫保鸡丁也是一道经典的川菜,我会先将鸡肉切成丁,用料酒和淀粉腌制一下。然后加入炒香的葱姜蒜,再放入干辣椒和花椒炒出香味,最后加入酱油、糖、醋和花生米炒匀即可。这道菜的关键是要保持鸡肉的嫩滑口感,同时让酱汁浓郁香辣。希望你也能成功做出一道美味的宫保鸡丁。\nHuman: 我问你的第一个问题是什么?\nAI: 你是谁?\nHuman: 我问你的第一个问题是什么?\nAI: 你问我怎么做鱼香肉丝。'}
6.4.2 总结记忆(SummaryMemory)
之前我们提到过也可以让 AI 去总结一下前面几轮对话的内容。Langchain 也提供了一个 ConversationSummaryMemory,可以实现这样的功能。
实现代码里有两个需要注意的点:
- 对于我们定义的 ConversationSummaryMemory,它的构造函数也接受一个 LLM 对象。这个对象会专门用来生成历史对话的小结,是可以和对话本身使用的 LLM 对象不同的。
- 这次我们没有使用 LLMChain 这个对象,而是用了封装好的 ConversationChain。用 ConversationChain 的话,其实我们是可以不用自己定义 PromptTemplate 来维护历史聊天记录的,但是为了使用中文的 PromptTemplate,我们在这里还是自定义了对应的 Prompt。
代码如下:
from langchain.chains import ConversationChain
from langchain.memory import ConversationSummaryMemory
llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=OpenAI())
prompt_template = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文
2. 回答限制在100个字以内
{history}
Human: {input}
AI:"""
prompt = PromptTemplate(
input_variables=["history", "input"], template=prompt_template
)
conversation_with_summary = ConversationChain(
llm=llm,
memory=memory,
prompt=prompt,
verbose=True
)
conversation_with_summary.predict(input="你好")
输出:
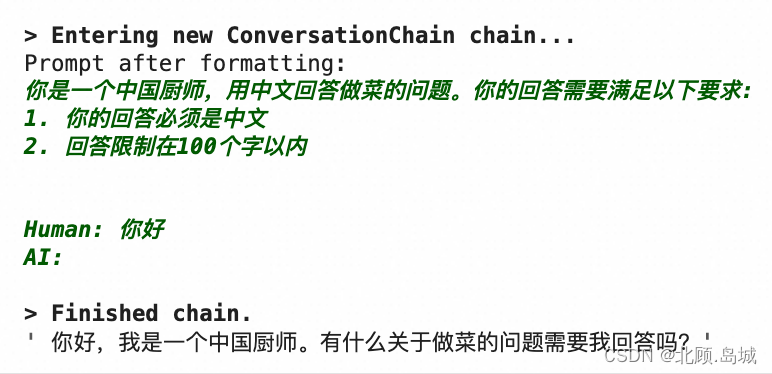
这里我们打开了 Verbose 模式,然后询问 AI 第二个问题的时候可以看到,在 Verbose 的信息里面,没有历史聊天记录,而是多了一段对之前聊天内容的英文小结。
conversation_with_summary.predict(input="鱼香肉丝怎么做?")
输出:

此时,再调用 memory 的 load_memory_variables 方法,可以看到记录下来的 history 是一小段关于对话的英文小结,而不是像上面那样记录完整的历史对话。
memory.load_memory_variables({})
输出:
{'history': '\nThe human greets the AI in Chinese and the AI responds by introducing itself as a Chinese chef and asking if there are any cooking-related questions it can answer. The human asks for a recipe for 鱼香肉丝 and the AI provides the steps, including marinating the pork and adding various vegetables and sauces for flavor. The AI then asks if there are any other dishes the human needs help with.'}
之后如果进一步对话,就会看到英文的小结内容会随着对话内容不断变化。每一次 AI 都是把之前的小结和新的对话交给 memory 中定义的 LLM 再次进行小结。
conversation_with_summary.predict(input="那蚝油牛肉呢?")
输出:

6.4.3 两者结合记忆(SummaryBufferMemory)
虽然 SummaryMemory 可以支持更长的对话轮数,但是它也有一个缺点,就是即使是最近几轮的对话,记录的也不是精确的内容。当你问“上一轮我问的问题是什么?”的时候,它其实没法给出准确的回答。LangChain 里提供了一个把 BufferMemory 和 SummaryMemory 结合的解决方案,就叫做 ConversationSummaryBufferMemory。
实现的代码有两点要注意:
- 把 Langchain 原来默认的对 Memory 进行小结的提示语模版从英文改成中文;
- 定义了一个 ConversationSummaryBufferMemory,在这个 Memory 的构造函数里面,我们指定了使用的 LLM、提示语,以及一个 max_token_limit 参数。max_token_limit 参数,其实就是告诉我们,当对话的长度到多长之后,我们就应该调用 LLM 去把文本内容小结一下。
代码如下:
from langchain import PromptTemplate
from langchain.chains import ConversationChain
from langchain.memory import ConversationSummaryBufferMemory
from langchain_openai import OpenAI, ChatOpenAI
SUMMARIZER_TEMPLATE = """请将以下内容逐步概括所提供的对话内容,并将新的概括添加到之前的概括中,形成新的概括。
EXAMPLE
Current summary:
Human询问AI对人工智能的看法。AI认为人工智能是一种积极的力量。
New lines of conversation:
Human:为什么你认为人工智能是一种积极的力量?
AI:因为人工智能将帮助人类发挥他们的潜能。
New summary:
Human询问AI对人工智能的看法。AI认为人工智能是一种积极的力量,因为它将帮助人类发挥他们的潜能。
END OF EXAMPLE
Current summary:
{summary}
New lines of conversation:
{new_lines}
New summary:"""
SUMMARY_PROMPT = PromptTemplate(
input_variables=["summary", "new_lines"], template=SUMMARIZER_TEMPLATE
)
memory = ConversationSummaryBufferMemory(llm=OpenAI(), prompt=SUMMARY_PROMPT, max_token_limit=256)
CHEF_TEMPLATE = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
1. 你的回答必须是中文。
2. 对于做菜步骤的回答尽量详细一些。
{history}
Human: {input}
AI:"""
CHEF_PROMPT = PromptTemplate(
input_variables=["history", "input"], template=CHEF_TEMPLATE
)
conversation_with_summary = ConversationChain(
llm=ChatOpenAI(model_name="gpt-3.5-turbo", stop="\n\n", max_tokens=2048, temperature=0.5),
prompt=CHEF_PROMPT,
memory=memory,
verbose=True
)
answer = conversation_with_summary.predict(input="你是谁?")
print(answer)
输出结果:
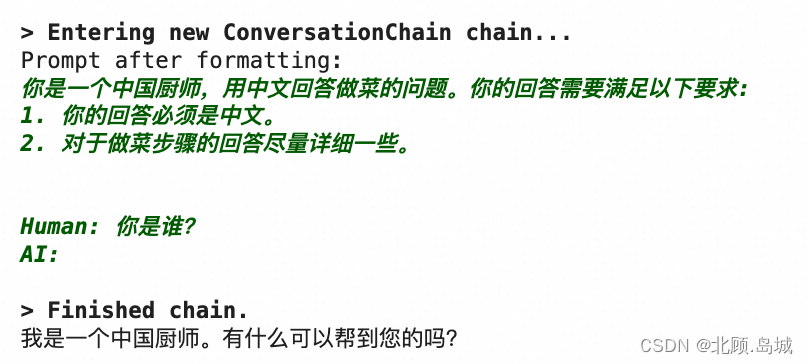
当我们连续多问 AI 几句话就会看到,随着对话轮数的增加,Token 数量超过了前面的 max_token_limit 。于是 SummaryBufferMemory 就会触发,对前面的对话进行小结,也就会出现一个 System 的信息部分,里面是聊天历史的小结,而后面完整记录的实际对话轮数就变少了。
answer = conversation_with_summary.predict(input="请问鱼香肉丝怎么做?")
print(answer)
answer = conversation_with_summary.predict(input="那蚝油牛肉呢?")
print(answer)
输出结果:

在实际使用 SummaryBufferMemory 的时候,并不需要把各个 Prompt 都改成自定义的中文版本。用默认的英文 Prompt 就足够了。因为在 Verbose 信息里出现的 System 信息并不会在实际的对话进行过程中显示给用户。这部分提示,只要 AI 自己能够理解就足够了。当然,你也可以根据实际对话的效果,来改写自己需要的提示语。
Pinecone 在自己网站上给出了一个数据对比,不同类型的 Memory 随着对话轮数的增长,占用的 Token 数量的变化。可以看到,不同的 Memory 在不同的参数下,占用的 Token 数量是不同的。比较合理的方式,还是使用这里的 ConversationSummaryBufferMemory,这样既可以在记录少数对话内容的时候,记住的东西更加精确,也可以在对话轮数增长之后,既能够记住各种信息,又不至于超出 Token 数量的上限。
不过,在运行程序的过程里可以感觉到现在程序跑得有点儿慢。这是因为我们使用 ConversationSummaryBufferMemory 很多时候要调用多次 OpenAI 的 API。在字数超过 max_token_limit 的时候,需要额外调用一次 API 来做小结。而且这样做,对应的 Token 数量消耗也是不少的。
在 Pinecone 提供的 Langchain AI Handbook 里面,专门测试了一下,从 BufferWindowMemory 到 BufferSummaryMemory,对于上下文保持的能力,以及消耗的 Token 数量的统计。参考地址:链接
不是所有的任务,都适合通过调用一次 ChatGPT 的 API 来解决。
除了在整个对话过程里使用 Memory 功能。如果之前已经有了一系列的历史对话,我们也可以通过 Memory 提供的 save_context 接口,把历史聊天记录灌进去。然后基于这个 Memory 让 AI 接着和用户对话。比如下面我们就把一组电商客服历史对话记录给了 SummaryBufferMemory。
代码如下:
memory = ConversationSummaryBufferMemory(llm=OpenAI(), prompt=SUMMARY_PROMPT, max_token_limit=40)
memory.save_context(
{"input": "你好"},
{"ouput": "你好,我是客服李四,有什么我可以帮助您的么"}
)
memory.save_context(
{"input": "我叫张三,在你们这里下了一张订单,订单号是 2023ABCD,我的邮箱地址是 customer@abc.com,但是这个订单十几天了还没有收到货"},
{"ouput": "好的,您稍等,我先为您查询一下您的订单"}
)
memory.load_memory_variables({})
输出:
{'history': 'System: \nHuman向客服询问有关订单状态的问题。客服李四表示可以帮助解决,要求提供订单号和邮箱地址。Human提供订单号和邮箱地址,并说明已经等待十几天仍未收到货。\nAI: 好的,您稍等,我先为您查询一下您的订单'}
为了演示方便,这里设置了一个很小的 max_token_limit
通过调用 memory.load_memory_variables 方法,我们发现 AI 对整段对话做了小结。但是这个小结有个问题,就是它并没有提取到我们最关注的信息,比如用户的订单号、用户的邮箱。只有有了这些信息,AI 才能够去查询订单,拿到结果然后回答用户的问题。
6.4.4 关注信息记忆(EntityMemory)
在还没有 ChatGPT 的时代,在客服聊天机器人的领域里,我们会通过命名实体识别的方式,把邮箱、订单号之类的关键信息提取出来。在有了 ChatGPT 这样的大语言模型之后,我们还是可以这样做。不过不是让专门的命名实体识别的算法做,而是直接让 ChatGPT 帮我们做。Langchain 也内置了一个 EntityMemory 的封装,让 AI 自动帮我们提取这样的信息。
from langchain.chains import ConversationChain
from langchain.memory import ConversationEntityMemory
from langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
entityMemory = ConversationEntityMemory(llm=llm)
conversation = ConversationChain(
llm=llm,
verbose=True,
prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE,
memory=entityMemory
)
answer=conversation.predict(input="我叫张老三,在你们这里下了一张订单,订单号是 2023ABCD,我的邮箱地址是 customer@abc.com,但是这个订单十几天了还没有收到货")
print(answer)
输出结果:

可以看到,在 Verbose 的日志里面,整个对话的提示语,多了一个叫做 Context 的部分,里面包含了刚才用户提供的姓名、订单号和邮箱。
我们把 memory 里面存储的东西打印出来。
print(conversation.memory.entity_store.store)
输出:
{'张老三': '张老三下了一张订单,订单号是 2023ABCD,邮箱地址是 customer@abc.com,但是订单十几天了还没有收到货。', '2023ABCD': '订单号是 2023ABCD,我的邮箱地址是 customer@abc.com,但是这个订单十几天了还没有收到货', 'customer@abc.com': "The customer's email address is customer@abc.com."}
可以看到,EntityMemory 里面不仅存储了这些命名实体的名字,也对应的把命名实体所关联的上下文记录了下来。这个时候,如果我们再通过对话来询问相关的问题,AI 也能够答上来。
answer=conversation.predict(input="我刚才的订单号是多少?")
print(answer)
answer=conversation.predict(input="订单2023ABCD是谁的订单?")
print(answer)
输出:

上述内容往往才是我们在聊天的过程中真正关注的信息。如果我们要做一个电商客服,后续的对话需要查询订单号、用户姓名的时候,这些信息是必不可少的。
事实上,我们不仅可以把这些 Memory 放在内存里面,还可以进一步把它们存放在 Redis 这样的外部存储里面。这样即使我们的服务进程消失了,这些“记忆”也不会丢失。官方文档也提供了类似的示例:链接
6.4.5 补充:知识图谱记忆(KnowledgeGraphMemory)
LangChain 推出了 ConversationKGMemory。这种记忆类型利用知识图的力量来存储和调用信息。通过这样做,它可以帮助模型理解不同实体之间的关系,增强其根据复杂的连接网络和历史背景做出响应的能力。
官网示例:链接
以下代码均来自官网:
from langchain.memory import ConversationKGMemory
from langchain_openai import OpenAI
from langchain.chains import ConversationChain
from langchain.prompts.prompt import PromptTemplate
llm = OpenAI(temperature=0)
template = """The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context.
If the AI does not know the answer to a question, it truthfully says it does not know. The AI ONLY uses information contained in the "Relevant Information" section and does not hallucinate.
Relevant Information:
{history}
Conversation:
Human: {input}
AI:"""
prompt = PromptTemplate(input_variables=["history", "input"], template=template)
conversation_with_kg = ConversationChain(
llm=llm, verbose=True, prompt=prompt, memory=ConversationKGMemory(llm=llm)
)
conversation_with_kg.predict(input="Hi, what's up?")
输出:

conversation_with_kg.predict(
input="My name is James and I'm helping Will. He's an engineer."
)
输出:

conversation_with_kg.predict(input="What do you know about Will?")
输出:

6.5 Langchain 的 Agent 功能
6.5.1 AI 自主决策
如果我们真的想要做一个能跑在生产环境上的 AI 聊天机器人,我们需要的不只一个单项技能。它应该针对你自己的数据有很多个不同的“单项技能”,就拿我比较熟悉的电商领域来说,我们至少需要这样三个技能。
- 需要一个“导购咨询”的单项技能,能够查询自己商品库里的商品信息为用户做导购和推荐。
- 需要一个“售中咨询”的单项技能,能够查询订单的物流轨迹,对买了东西还没有收到货的用户给出安抚和回复
- 需要一个“FAQ”的单项技能,能够把整个电商网站的 FAQ 索引起来,当用户问到退货政策、运费、支付方式等问题的时候,我们可以从 FAQ 里面拿到对应的答案,回复给用户。
对于这三个单项技能,AI 要能够自己判断什么时候该用什么样的技能。而不是需要人工介入,或者写一堆 if…else 的代码。
我们可以采用一个在写大型系统的时候常用的思路,就是“分而治之”。对于每一个单项技能,都可以把它们变成一个 LLMChain。然后,对于用户问的问题,可以先问问 AI,让它告诉我们应该选用哪一个 LLMChain 来回答问题。
示例代码:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(max_tokens=2048, temperature=0.5)
multiple_choice = """
请针对 >>> 和 <<< 中间的用户问题,选择一个合适的工具去回答他的问题。只要用A、B、C的选项字母告诉我答案。
如果你觉得都不合适,就选D。
>>>{question}<<<
我们有的工具包括:
A. 一个能够查询商品信息,为用户进行商品导购的工具
B. 一个能够查询订单信息,获得最新的订单情况的工具
C. 一个能够搜索商家的退换货政策、运费、物流时长、支付渠道、覆盖国家的工具
D. 都不合适
"""
multiple_choice_prompt = PromptTemplate(template=multiple_choice, input_variables=["question"])
choice_chain = LLMChain(llm=llm, prompt=multiple_choice_prompt, output_key="answer")
可以试试问不同的问题,看看它能不能选择一个正确的工具。
question = "我想买一件衣服,但是不知道哪个款式好看,你能帮我推荐一下吗?"
print(choice_chain(question))
question = "我有一张订单,订单号是 2022ABCDE,一直没有收到,能麻烦帮我查一下吗?"
print(choice_chain(question))
question = "请问你们的货,能送到三亚吗?大概需要几天?"
print(choice_chain(question))
question = "今天天气怎么样?"
print(choice_chain(question))
输出:

可以看到,对于我们提出的四个问题,ChatGPT 都给出了正确的答案。在拿到答案之后,你可以直接再通过一个 TransformChain,去匹配返回结果的前缀,看看是 A、B、C、D 中的哪一个,再来决定后面可以去调用哪个 LLMChain。
6.5.2 Agent 的使用:电商客服聊天机器人应用
6.5.2.1 Agent 基本使用
Agent 翻译成中文,有两个意思。一个叫做代理人,比如在美国你买房子、租房子,都要通过 Real Estate Agent,也就是“房产代理”,其实就是我们这里说的“中介”。另一个意思,叫做“特工”,这是指 Agent 是有自主行动能力的,它可以根据你提出的要求,直接使用提供的工具采取行动。它不只是做完选择题就完事儿了,而是直接拿起选中的工具进行下一步的行动。Langchain 的 Agent 其实这两个意思都是包含的。
对于上例我们使用 Langchain 提供的 Agent 来解决,代码如下:
from langchain.agents import initialize_agent, Tool
from langchain_openai import OpenAI
llm = OpenAI(temperature=0)
def search_order(input: str) -> str:
return "订单状态:已发货;发货日期:2023-01-01;预计送达时间:2023-01-10"
def recommend_product(input: str) -> str:
return "红色连衣裙"
def faq(intput: str) -> str:
return "7天无理由退货"
tools = [
Tool(
name = "Search Order",func=search_order,
description="useful for when you need to answer questions about customers orders"
),
Tool(name="Recommend Product", func=recommend_product,
description="useful for when you need to answer questions about product recommendations"
),
Tool(name="FAQ", func=faq,
description="useful for when you need to answer questions about shopping policies, like return policy, shipping policy, etc."
)
]
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
这段代码由三个部分组成:
- 我们定义了三个函数,分别叫做 search_order、recommend_product 以及 faq。它们的输入都是一个字符串,输出是我们写好的对于问题的回答。
- 我们针对这三个函数,创建了一个 Tool 对象的数组,把这三个函数分别封装在了三个 Tool 对象里面。每一个 Tool 的对象,在函数之外,还定义了一个名字,并且定义了 Tool 的 description。这个 description 就是告诉 AI,这个 Tool 是干什么用的。就像上面的那个例子一样,AI 会根据问题以及这些描述来做选择题。
- 我们创建了一个 agent 对象,指定它会用哪些 Tools、LLM 对象以及 agent 的类型。在 agent 的类型这里,我们选择了 zero-shot-react-description。这里的 zero-shot 就是指之前讲过的“零样本分类”,也就是不给 AI 任何例子,直接让它根据自己的推理能力来做决策。而 react description,指的是根据你对于 Tool 的描述(description)进行推理(Reasoning)并采取行动(Action)。
这里的 ReAct,并不是来自 Facebook 的前端框架的名字,而是来自一篇 Google Brain 的论文:ReAct: Synergizing Reasoning and Acting in Language Models,地址:链接
Langchain 里面的 zero-shot-react-description 这个想法,来自一个知名的 AI 创业公司 AI21 Labs 的论文 MRKL Systems,论文地址:链接
尝试询问刚才的三个问题:
question = "我想买一件衣服,但是不知道哪个款式好看,你能帮我推荐一下吗?"
result = agent.run(question)
print(result)
question = "我有一张订单,订单号是 2022ABCDE,一直没有收到,能麻烦帮我查一下吗?"
result = agent.run(question)
print(result)
question = "请问你们的货,能送到三亚吗?大概需要几天?"
result = agent.run(question)
print(result)
输出:

这里 Agent 思考日志的每一步操作,可以分成 5 个步骤,分别是 Action、Action Input、Observation、Thought,最后输出一个 Final Answer。
- Action,就是根据用户的输入,选择应该选取哪一个 Tool,然后行动。
- Action Input,就是根据需要使用的 Tool,从用户的输入里提取出相关的内容,可以输入到 Tool 里面。
- Oberservation,就是观察通过使用 Tool 得到的一个输出结果。
- Thought,就是再看一眼用户的输入,判断一下该怎么做。
- Final Answer,就是 Thought 在看到 Obersavation 之后,给出的最终输出。
这里有几个有意思的现象:
- “推荐衣服“的问题,没有遵循上面的 5 个步骤,而是在第 4 步 Thought 之后,重新回到了 Action。并且在这样反复三次之后,才不得已强行回答了问题。
- 同样,对于“货需要几天送到三亚”的问题,也重复了2次,给出的答案,也并不一定准确,因为我们的回答里面并没有说能不能送到三亚。
上面整个过程,其实也是通过一段 Prompt 来实现的,具体可以去看一下 Langchain 源码,地址:链接。
源码如下:
# flake8: noqa
PREFIX = """Answer the following questions as best you can. You have access to the following tools:"""
FORMAT_INSTRUCTIONS = """Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question"""
SUFFIX = """Begin!
Question: {input}
Thought:{agent_scratchpad}"""
可以看到,其实它就是把一系列的工具名称和对应的描述交给了 OpenAI,让它根据用户输入的需求,选取对应的工具,然后提取用户输入中和用户相关的信息。本质上,只是我们上面让 AI 做选择题的一种扩展而已。
6.5.2.2 通过 max_iterations 限制重试次数
前面反复重复思考过程其实是 Agent 本身的功能。因为实际很多逻辑处理不一定准确,所以 AI 会在 Thought 的时候根据回答是否靠谱来决定是否重试。如果希望控制这个重试次数,可以设置 max_iterations 这个参数。
示例代码:
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", max_iterations = 2, verbose=True)
question = "请问你们的货,能送到三亚吗?大概需要几天?"
result = agent.run(question)
print("===")
print(result)
print("===")
输出:

可以看到,AI 重试了两次就不再重试,并且也没有强行给出一个回答,而是回答 Agent 因为 max iterations 的设置而中止了。这样,你可以把 AI 回答不上来的问题,切换给人工客服回答。
6.5.2.3 通过 VectorDBQA 支持问答
对于上面的示例,我们进一步增强它的能力,使用具体的 LLMChain 来代替现在返回固定字符串的函数。这里使用 VectorDBQA 这个 LLMChain,把它封装成一个 Tool。
(1)封装 FAQ Tool
使用之前的电商 FAQ 的数据集:
!wget -P data https://github.com/xuwenhao/geektime-ai-course/raw/main/data/faq/ecommerce_faq.txt
安装下载相关包:
!pip install faiss-cpu
!python -m spacy download zh_core_web_sm
示例代码:
from langchain.vectorstores import FAISS
from langchain.text_splitter import SpacyTextSplitter
from langchain import VectorDBQA
from langchain.document_loaders import TextLoader
from langchain_openai import OpenAI, OpenAIEmbeddings
from langchain.agents import tool
llm = OpenAI(temperature=0)
loader = TextLoader('./data/ecommerce_faq.txt')
documents = loader.load()
text_splitter = SpacyTextSplitter(chunk_size=256, pipeline="zh_core_web_sm")
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
docsearch = FAISS.from_documents(texts, embeddings)
faq_chain = VectorDBQA.from_chain_type(llm=llm, vectorstore=docsearch, verbose=True)
@tool("FAQ")
def faq(intput: str) -> str:
"""useful for when you need to answer questions about shopping policies, like return policy, shipping policy, etc."""
return faq_chain.run(intput)
tools = [
Tool(
name = "Search Order",func=search_order,
description="useful for when you need to answer questions about customers orders"
),
Tool(name="Recommend Product", func=recommend_product,
description="useful for when you need to answer questions about product recommendations"
),
faq
]
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
这里通过 @tool 这个 Python 的 decorator 功能,将 FAQ 这个函数直接变成了 Tool 对象,这可以减少我们每次创建 Tools 的时候都要指定 name 和 description 的工作。
重新问一下之前的问题:
question = "请问你们的货,能送到三亚吗?大概需要几天?"
result = agent.run(question)
print(result)
输出:

(2)封装商品推荐 Tool
对于商品的推荐,可以把对应的商品信息,存到 VectorStore 里,然后通过先搜索后问答的方式来解决。
下载数据集:
!wget -P data https://github.com/xuwenhao/geektime-ai-course/raw/main/data/ecommerce_products.csv
重新构建 Agent 代码:
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import CSVLoader
product_loader = CSVLoader('./data/ecommerce_products.csv')
product_documents = product_loader.load()
product_text_splitter = CharacterTextSplitter(chunk_size=1024, separator="\n")
product_texts = product_text_splitter.split_documents(product_documents)
product_search = FAISS.from_documents(product_texts, OpenAIEmbeddings())
product_chain = VectorDBQA.from_chain_type(llm=llm, vectorstore=product_search, verbose=True)
@tool("FAQ")
def faq(intput: str) -> str:
""""useful for when you need to answer questions about shopping policies, like return policy, shipping policy, etc."""
return faq_chain.run(intput)
@tool("Recommend Product")
def recommend_product(input: str) -> str:
""""useful for when you need to search and recommend products and recommend it to the user"""
return product_chain.run(input)
tools = [
Tool(
name = "Search Order",func=search_order,
description="useful for when you need to answer questions about customers orders"
),
recommend_product, faq]
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
询问之前的推荐问题:
question = "我想买一件衣服,想要在春天去公园穿,但是不知道哪个款式好看,你能帮我推荐一下吗?"
answer = agent.run(question)
print(answer)
输出结果:

6.5.2.4 优化 Prompt
订单查询使用向量检索就不太合适了,我们直接拿着订单号去数据库里查就好了。这里为了简化,我们在对应的函数里造几条数据,根据用户输入的不同订单号返回不同的订单状态,找不到的话,就告诉用户找不到订单就好。
重构 Agent 代码:
import json
ORDER_1 = "20230101ABC"
ORDER_2 = "20230101EFG"
ORDER_1_DETAIL = {
"order_number": ORDER_1,
"status": "已发货",
"shipping_date" : "2023-01-03",
"estimated_delivered_date": "2023-01-05",
}
ORDER_2_DETAIL = {
"order_number": ORDER_2,
"status": "未发货",
"shipping_date" : None,
"estimated_delivered_date": None,
}
import re
@tool("Search Order")
def search_order(input:str)->str:
"""useful for when you need to answer questions about customers orders"""
if input.strip() == ORDER_1:
return json.dumps(ORDER_1_DETAIL)
elif input.strip() == ORDER_2:
return json.dumps(ORDER_2_DETAIL)
else:
return f"对不起,根据{input}没有找到您的订单"
tools = [search_order,recommend_product, faq]
agent = initialize_agent(tools, llm=OpenAI(temperature=0), agent="zero-shot-react-description", verbose=True)
尝试让 Agent 查询一下订单号:
question = "我有一张订单,订单号是 2022ABCDE,一直没有收到,能麻烦帮我查一下吗?"
answer = agent.run(question)
print(answer)
输出:

这里当查询不到订单时,也可以调整 search_order 这个 Tool 的提示语,让 Agent 明确知道在找不到订单的时候,告诉用户找不到订单或者请它再次确认。
代码如下:
import re
@tool("Search Order")
def search_order(input:str)->str:
"""一个帮助用户查询最新订单状态的工具,并且能处理以下情况:
1. 在用户没有输入订单号的时候,会询问用户订单号
2. 在用户输入的订单号查询不到的时候,会让用户二次确认订单号是否正确"""
pattern = r"\d+[A-Z]+"
match = re.search(pattern, input)
order_number = input
if match:
order_number = match.group(0)
else:
return "请问您的订单号是多少?"
if order_number == ORDER_1:
return json.dumps(ORDER_1_DETAIL)
elif order_number == ORDER_2:
return json.dumps(ORDER_2_DETAIL)
else:
return f"对不起,根据{input}没有找到您的订单"
tools = [search_order,recommend_product, faq]
agent = initialize_agent(tools, llm=OpenAI(temperature=0), agent="zero-shot-react-description", verbose=True)
question = "我有一张订单,订单号是 2022ABCDE,一直没有收到,能麻烦帮我查一下吗?"
answer = agent.run(question)
print(answer)
输出:
这里可以看到,调整了提示语之后效果反而不如之前的好,后面对于这个问题我们可以进一步优化。
6.5.2.5 通过多轮对话实现订单查询
上面的客服聊天机器人还有几个可以优化的空间:
- 应该支持多轮聊天。因为用户不一定是在第一轮提问的时候,就给出了自己的订单号。
- 可以直接让 Search Order 这个 Tool,回答用户的问题,没有必要再让 Agent 思考一遍。
相对应的改造点如下:
- 给 Search Order 这个 Tool 设置了一个参数,叫做 return_direct = True,这个参数是告诉 AI,在拿到这个工具的回复之后,不要再经过 Thought 那一步思考,直接把我们的回答给到用户就好了。设了这个参数之后,你就会发现 AI 不会在没有得到一个订单号的时候继续去反复思考,尝试使用工具,而是会直接去询问用户的订单号。同时,对于查询到的订单号,我们不直接返回一个 JSON 字符串,而是通过 answer_order_llm 这个工具来组织语言文字。
- 我们把 Agent 换成了 converstional-react-description,这样就支持多轮对话了,同时我们也把对应的 LLM 换成了 ChatOpenAI,这样成本更低。并且,我们还为这个 Agent 设置了 memory。
最终代码如下:
import re
answer_order_info = PromptTemplate(
template="请把下面的订单信息回复给用户: \n\n {order}?", input_variables=["order"]
)
answer_order_llm = LLMChain(llm=ChatOpenAI(temperature=0), prompt=answer_order_info)
@tool("Search Order", return_direct=True)
def search_order(input:str)->str:
"""useful for when you need to answer questions about customers orders"""
pattern = r"\d+[A-Z]+"
match = re.search(pattern, input)
order_number = input
if match:
order_number = match.group(0)
else:
return "请问您的订单号是多少?"
if order_number == ORDER_1:
return answer_order_llm.run(json.dumps(ORDER_1_DETAIL))
elif order_number == ORDER_2:
return answer_order_llm.run(json.dumps(ORDER_2_DETAIL))
else:
return f"对不起,根据{input}没有找到您的订单"
from langchain.memory import ConversationBufferMemory
from langchain.chat_models import ChatOpenAI
tools = [search_order,recommend_product, faq]
chatllm=ChatOpenAI(temperature=0)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation_agent = initialize_agent(tools, chatllm,
agent="conversational-react-description",
memory=memory, verbose=True)
尝试问下问题:
question1 = "我有一张订单,一直没有收到,能麻烦帮我查一下吗?"
answer1 = conversation_agent.run(question1)
print(answer1)
question2 = "我的订单号是20230101ABC"
answer2 = conversation_agent.run(question2)
print(answer2)
question3 = "你们的退货政策是怎么样的?"
answer3 = conversation_agent.run(question3)
print(answer3)
输出:

对于电商客服聊天机器人来说,通过 EntityMemory 获取并查询订单信息更重要,以下是使用 EntityMemory 实现的聊天机器人:
from langchain.memory import ConversationEntityMemory
from langchain.chat_models import ChatOpenAI
tools = [search_order,recommend_product, faq]
chatllm=ChatOpenAI(temperature=0)
entityMemory = ConversationEntityMemory(llm=llm, chat_history_key="chat_history", return_messages=True)
conversation_agent = initialize_agent(tools, chatllm,
agent="conversational-react-description",
memory=entityMemory, verbose=True)
尝试问同样的问题:
question1 = "我有一张订单,一直没有收到,能麻烦帮我查一下吗?"
answer1 = conversation_agent.run(question1)
print(answer1)
question2 = "我的订单号是20230101ABC"
answer2 = conversation_agent.run(question2)
print(answer2)
question3 = "你们的退货政策是怎么样的?"
answer3 = conversation_agent.run(question3)
print(answer3)
question4 = "我的订单号是多少?"
answer4 = conversation_agent.run(question4)
print(answer4)
输出:


7. 模型微调(Fine-tune)
7.1 概念
模型微调,是因为无论是 ChatGPT 还是 GPT-4 都不是全知全能的 AI。在很多垂直的领域,它的回答还是常常会出错。其中很大一部分原因,是它也缺少特定领域的训练数据。而如果我们有比较丰富的垂直领域的数据,那么就可以利用这些数据来“微调”一个特别擅长这个垂直领域的模型。
OpenAI 模型微调的过程,并不复杂。只需要把数据提供给 OpenAI 就好了,对应的整个微调的过程是在云端的“黑盒子”里进行的。需要提供的数据格式是一个文本文件,每一行都是一个 Prompt,以及对应这个 Prompt 的 Completion 接口会生成的内容。
示例如下:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...
模型微调的过程,就是根据输入的内容,在原来的基础模型上训练。这个基础模型,就是以前介绍过的 Ada、Babbage、Curie 和 Davinci 其中的一个。每一个示例,都会导致基础模型原有参数发生变化。整个微调过程结束之后,变化后的参数就会被固定下来,变成一个只有你可以使用的新模型。
如果你提供了很多医疗行业的文本内容,那么微调出来的新模型就会拥有更多医疗领域的知识,以及对话的风格。而如果你给的是笑话大全,那么微调出来的模型就更擅长讲笑话。而且要注意,微调之后的模型,不仅有你用来微调的数据的相关知识,原先基础模型里面的绝大部分知识和能力它也还都保留着。
OpenAI 官网提供了更多关于模型微调的介绍,地址:链接
Weight & Bias 提供了工具来追踪 OpenAI 微调后的模型的实验、模型与数据集,文档地址:链接,Notebook 地址:链接
7.2 应用实践:实现一个讲“历史英雄人物和奥特曼一起打怪兽”故事的 AI
7.2.1 代码实现
代码非常简单,我们可以定义一系列朝代、超能力和故事的类型。然后通过三重循环,让 AI 根据这三者的组合来生成一系列故事。这些生成出来的故事,也就构成了我们用来微调模型的训练数据。因为数据量不大,这里直接用 CSV 把它存下来了。
在这个过程中,数据是一条条生成的,比较慢,也比较消耗 Token,你可以不用运行,直接拿运行后生成的结果数据就好。
生成数据代码:
import os,openai,backoff
import pandas as pd
from openai import OpenAI
client = OpenAI(api_key = os.environ["OPENAI_API_KEY"])
dynasties= ['唐', '宋', '元', '明', '清', '汉', '魏', '晋', '南北朝']
super_powers = ['隐形', '飞行', '读心术', '瞬间移动', '不死之身', '喷火']
story_types = ['轻松', '努力', '艰难']
@backoff.on_exception(backoff.expo, openai.RateLimitError)
def gpt35(prompt, max_tokens=2048, temperature=0.5, top_p=1, frequency_penalty=0, presence_penalty=0):
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
frequency_penalty=frequency_penalty,
presence_penalty=presence_penalty)
return response.choices[0].text
def prepare_stories(dynasties, super_powers, story_types, repeat=3, output_file="data/ultraman_stories.csv"):
df = pd.DataFrame()
for dynasty in dynasties:
for super_power in super_powers:
for story_type in story_types:
for i in range(repeat):
prompt = f"""请你用中文写一段300字的故事,情节跌宕起伏,讲述一位{dynasty}朝时期的英雄人物,穿越到现代,拥有了{super_power}这样的超能力,通过{story_type}的战斗,帮助奥特曼一起打败了怪兽的故事。"""
story = gpt35(prompt)
row = {"dynasty": dynasty, "super_power": super_power, "story_type": story_type, "story": story}
row = pd.DataFrame([row])
df = pd.concat([df, row], axis=0, ignore_index=True)
df.to_csv("data/ultraman_stories.csv")
prepare_stories(dynasties, super_powers, story_types)
上述生成的数据可以直接下载获取:
!wget -P data https://github.com/xuwenhao/geektime-ai-course/raw/main/data/ultraman_stories.csv
之后,我们可以使用 OpenAI 自带的命令行工具把对应的 CSV 格式的数据转换成微调模型所需要的 JSONL 格式的文件。
这里主要做两个动作:
- 处理生成微调数据。对于微调,我们使用的 Prompt 不再是一个完整的句子,而是只用了“朝代”+“超能力”+“故事类型”拼接在一起的字符串,中间用逗号隔开。然后把这个字符串和生成的故事,用 Prompt 和 Completion 作为列名存储成了一个 CSV。
- 通过 subprocess 调用了命令行里的 OpenAI 工具,把上面的 CSV 文件,转化成了一个 JSONL 格式的文件。
df = pd.read_csv("data/ultraman_stories.csv")
df['sub_prompt'] = df['dynasty'] + "," + df['super_power'] + "," + df['story_type']
prepared_data = df.loc[:,['sub_prompt','story']]
prepared_data.rename(columns={'sub_prompt':'prompt', 'story':'completion'}, inplace=True)
prepared_data.to_csv('data/prepared_data.csv',index=False)
import subprocess
subprocess.run('openai tools fine_tunes.prepare_data --file data/prepared_data.csv --quiet'.split())
输出:

查看目录结构,可以看到生成了一个 JSONL 格式的文件:

这个文件的内容如下:
{"prompt":"唐,隐形,轻松 ->","completion":" \n\n一位叫做李明的英雄人物,出生在唐朝时期。他是一个勇敢的将军,在他的一生中,他打败了许多敌人,为自己的国家和人民做出了许多贡献。\n\n一天,李明意外被一道神秘的光束穿越到了现代。他发现自己拥有了超能力,可以隐形,可以飞行,可以发射光束,可以放出火焰,可以穿墙而过等等。\n\n李明发现,在现代,怪兽们正在摧毁地球,他决定和奥特曼一起,用自己的超能力,帮助奥特曼消灭怪兽们。\n\n于是,李明和奥特曼开始了一场艰苦的战斗,他们用自己的超能力,一招一式,击退了怪兽们,最终成功地拯救了地球。\n\n在这场战斗之后,地球上的人们都对李明充满了敬佩,他从此成为了一位英雄,他的事迹也被传颂了很久。李明也因此被永远铭记在人们心中,成为了一位不朽的英雄。."}
{"prompt":"唐,隐形,轻松 ->","completion":" \n\n这是一个关于英雄的故事,发生在唐朝时期的中国。一个叫李自成的勇士,他拥有过人的勇气,英勇的行为让他成为当时最受尊敬的人物。\n\n一天,李自成被一道神秘的光芒笼罩住,他突然发现自己似乎穿越时空,来到了现代。他惊讶地发现,自己竟然拥有了一种超能力,可以让自己隐形。\n\n李自成接受了这种超能力,他发现这种能力可以让自己变得更加强大,他决定利用这种能力来帮助人们。\n\n一次,李自成发现有一群怪兽正在破坏城市,他决定和奥特曼一起出动,利用自己的超能力,把怪兽一个个击败,最终成功拯救了城市,令众人欢呼雀跃。\n\n自此,李自成受到了众人的尊敬,他成为了这个城市的英雄,他也把自己的超能力用在了正义的事业上,为人们做出了许多贡献,他也成为了一个英雄。."}
{"prompt":"唐,隐形,轻松 ->","completion":" \n\n某一天,一位叫做萧炎的唐朝时期英雄人物突然被一道神秘的光芒所笼罩,他被带到了现代。他发现自己可以隐形,可以操纵物体,还可以拥有超能力,让他的力量超越了人类的极限。\n\n萧炎发现,现代的世界正面临着一个叫做怪兽的可怕敌人的威胁,他决定和奥特曼一起,帮助他们打败怪兽。他们开始了一场艰苦的战斗,但是怪兽的力量太强大了,奥特曼们几乎要被击垮。\n\n就在这时,萧炎出现了。他用自己的超能力,操纵物体,隐身攻击,轻松击败了怪兽,拯救了世界。当战斗结束,萧炎又回到了唐朝,但他留下了一句:“你们永远不会孤单,我会永远在你们身边。”."}
...
可以看到,转换后的数据文件,在 Prompt 的最后,多了一个“->”符号。而在 Completion 的开头,多了两个“\n\n”的换行,结尾则是多了一个“.”。这是为了方便我们后续在使用这个模型生成数据的时候,控制生成结果。未来在使用模型的时候,Prompt 需要以“->\n”这个提示符结束,并且将 stop 设置成“.”。这样,模型就会自然套用我们微调里的模式来生成文本。
生成数据后,再上传训练文件,然后创建微调模型。这里创建模型时指定了三个参数,分别是用来训练的数据文件上传后生成的id、一个基础模型,以及生成模型的后缀。
file = client.files.create(
file=open("data/prepared_data_prepared.jsonl", "rb"),
purpose="fine-tune"
)
client.fine_tuning.jobs.create(
training_file=file.id,
model="babbage-002",
suffix="ultraman"
)
这里运行代码会报错,错误信息为
'Fine-tuning jobs cannot be created on an Explore plan. You can upgrade to a paid plan on your billing page: https://platform.openai.com/account/billing/overview',即 fine-tune 模型超出了我们的付费范围,因此这里不再真实演示,仅给出原专栏中的示例,并调整其中过时不可用的代码部分。
微调完成后,可以通过 fine_tuning.jobs.list 指令,找出所有我们微调的模型:
client.fine_tuning.jobs.list()
模型的使用方式也与其他 OpenAI 提供的官方模型一致。对应在调用模型时我们使用的提示语是“朝代”+“超能力”+“故事类型”,并且跟着“->\n”,而 stop 则是设置成“.”。
代码示例:
import os
from openai import OpenAI
client = OpenAI(api_key = os.environ["OPENAI_API_KEY"])
def write_a_story(prompt):
response = client.completions.create(
model="[微调出的模型名称]",
prompt=prompt,
temperature=0.7,
max_tokens=2000,
top_p=1,
stop=["."])
return response.choices[0].text
story = write_a_story("宋,发射激光,艰难 ->\n")
print(story)
因为这是一个微调的模型,它不仅拥有我们训练数据提供的知识,也包括基础模型里的各种信息。所以我们使用的朝代、超能力和故事类型也可以是在之前微调数据里面没有出现过的。比如,上面的例子里,我们使用的超能力叫做“发射激光”,并不是我们拿来微调的数据里面有的一种超能力。这里专栏原文给了一个示例:
story = write_a_story("秦,龙卷风,辛苦 ->\n")
print(story)
输出:
曾经有一位叫苏轼的英雄人物,他曾经英勇地抵抗过许多强大的敌人,拯救了许多被危险封印的百姓。他曾经在一次战争中发挥过自己的作用,赢得了许多胜利,被尊为英雄。
然而,苏轼却在一次激烈的战斗中牺牲了,他的灵魂被封印在一个古老的石头里,隔着一层玻璃,一直沉睡了几百年。
苏轼的灵魂在穿越时空,来到了现代,他发现自己拥有了一种超能力,这就是龙卷风,他可以使自己的身体具有超强的力量,甚至可以抵抗恶魔的攻击。
苏轼在现代的世界里,发现了一种可怕的怪兽,它们正在摧毁着人类的家园,苏轼决定要拯救这个世界,于是他和奥特曼一起出发,开始了一场史诗般的战斗。
在苏轼和奥特曼的帮助下,苏轼利用自己的超能力,一次次击退怪兽的攻击,最终他们成功地打败了怪兽,拯救了人类。
苏轼的事迹在这里传唱了很久,他成为了一位永恒的英雄,他的故事也被传唱了下来,让人们永远不会忘记他的英勇事迹。
7.2.2 模型微调的成本
专栏原文使用的 Curie 基础模型已经不可用,这里我们使用的是较为便宜的babbage-002。各微调模型的成本如下:
详细数据可参考官方计价文档:链接
使用微调模型的成本要远远高于使用 OpenAI 内置的模型。
对于模型微调的效果,可以通过查询微调作业、从 result_files 中提取文件 ID,然后检索该文件内容来查看有关训练过程的指标。每个结果 CSV 文件都包含以下列:step、train_loss、train_accuracy、valid_loss和valid_mean_token_accuracy。
7.2.3 增量训练优化模型
微调模型还有一个能力,就是我们可以在已经微调了的模型上根据新数据做进一步地微调。这个在很多垂直领域是非常有用,比如在医学、金融这样的领域,我们就可以不断收集新的数据,不断在前一个微调模型的基础之上继续微调我们的模型,让模型的效果越来越好。而这些领域往往也能承受更高一些的成本。
过程也很简单,只需要再准备一些数据,以之前已经微调好的模型为基础模型来操作就好了。
生成额外的数据代码:
dynasties= ['秦', '五代', '隋']
super_powers = ['龙卷风', '冰冻大海', '流星火雨']
story_types = ['轻松', '努力', '艰难', '勇敢', '辛苦']
new_stories = "data/ultraman_stories_more.csv"
prepare_stories(dynasties, super_powers, story_types, repeat=3, output_file=new_stories)
上述生成的数据可以直接下载获取:
!wget -P data https://github.com/xuwenhao/geektime-ai-course/raw/main/data/ultraman_stories_more.csv
数据转换:
df = pd.read_csv(new_stories)
df['sub_prompt'] = df['dynasty'] + "," + df['super_power'] + "," + df['story_type']
prepared_data = df.loc[:,['sub_prompt','story']]
prepared_data.rename(columns={'sub_prompt':'prompt', 'story':'completion'}, inplace=True)
new_stories_prepared = 'data/prepared_data_more.csv'
prepared_data.to_csv(new_stories_prepared, index=False)
subprocess.run('openai tools fine_tunes.prepare_data --file data/prepared_data_more.csv --quiet'.split())
继续微调:
from openai.types.fine_tuning.job_create_params import Hyperparameters
file = client.files.create(
file=open("data/prepared_data_more_prepared.jsonl", "rb"),
purpose="fine-tune"
)
client.fine_tuning.jobs.create(
training_file=file.id,
model="[上面微调过的模型名]",
suffix="ultraman",
hyperparameters=Hyperparameters(learning_rate_multiplier=0.2)
)
这里要修改两个参数:
- 把 model 换成刚才微调之后的模型;
- learning_rate_multiplier 这个参数的默认值是根据样本数量在 0.05 到 0.2 不等。如果你继续微调的样本数要比之前微调的数据量小很多,就可以调得大一点。
微调更新之后,模型的名称没有变,老的模型就被更新成了微调后的新模型。这里尝试使用新模型的效果使用原专栏文章给出的示例:
fine_tuned = write_a_story("五代,流星火雨,艰难 ->\n")
print(fine_tuned)
输出:
这是一个发生在一个古老的世界,一个叫做“六代”的世界。这个世界有着一种叫做“超能力”的特性,可以让人穿越时空,穿越到现代。
一位叫做“英雄”的人物,他来自于六代,但他拥有了一种叫做“流星火雨”的超能力,他可以把自己的身体变成一个火焰,然后穿越时空,来到现代。
他来到现代,发现这个世界变得越来越危险,有一种叫做“怪兽”的存在,他们想要毁灭这个世界。英雄决定帮助奥特曼一起打败怪兽,于是他们开始了一场激烈的战斗。
英雄凭借着自己的超能力,以及奥特曼的力量,战胜了怪兽,拯救了这个世界。最后,英雄又一次穿越回六代,这次他拥有了一种叫做“流星火雨”的超能力,他可以把自己的身体变成一个火焰,然后穿越时空,拯救又一次六代。
7.2.4 流式生成输出结果
这里代码运行的生成结果不像在 ChatGPT 的 Web 界面里那样一个词一个词地输出,想做到这样的效果只需要在调用 Completion 接口的时候,启用 stream=True 这个参数,然后对于返回结果,我们不再是直接拿到整个 response 然后打印出来。而是拿到一个可以通过迭代器访问的一系列 events,每一个 event 都包含了一部分新生成的文本。
原专栏示例代码:
def write_a_story_by_stream(prompt):
response = client.completions.create(
model="[上面微调过的模型名]",
prompt=prompt,
temperature=0.7,
max_tokens=2000,
stream=True,
top_p=1,
stop=["."])
return response
response = write_a_story_by_stream("汉,冰冻大海,艰难 ->\n")
for event in response:
event_text = event.choices[0].text
print(event_text, end = '')