Relation-Aware Entity Alignment for Heterogeneous Knowledge Graphs
面向异质知识图谱的关系感知实体对齐
Abstract
实体对齐是从不同的知识图(KGs)中链接具有相同真实世界实体的任务,最近被基于嵌入的方法所主导。这种方法通过学习KG表示来工作,以便可以通过测量实体嵌入之间的相似性来执行实体对齐。虽然有希望,但该领域的现有工作往往不能很好地捕获多关系KGs中常见的复杂关系信息,留下了很大的改进空间。本文提出了一种新的关系感知双图卷积网络(RDGCN),通过知识图与其对偶关系副本之间的密切交互来融合关系信息,并进一步捕获邻域结构以学习更好的实体表示。在三个真实的跨语言数据集上的实验表明,我们的方法通过学习更好的KG表示,比最先进的对齐方法提供了更好和更健壮的结果。
1 Introduction
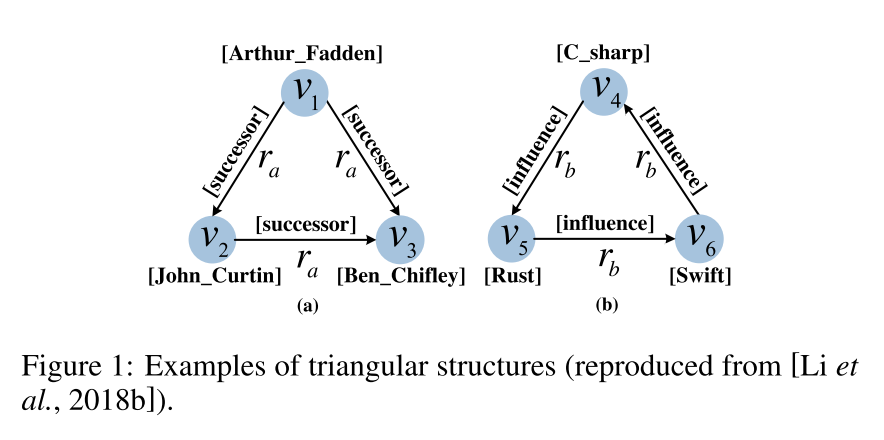
KGs中的知识通常被组织成 ⟨ h e a d e n t i t y , r e l a t i o n , t a i l e n t i t y ⟩ \langle head entity, relation, tail entity \rangle ⟨headentity,relation,tailentity⟩的三元组。现有的大多数方法都使用跨家族模型作为嵌入KG的主干,这些KG受假设 h e a d + r e l a t i o n ≈ t a i l head + relation \approx tail head+relation≈tail的约束。这种强假设使得该模型不能有效地捕捉多关系图中更复杂的关系信息。跨家族方法不能捕捉图中描述的三角形结构,如果使用跨家族学习KG表示,则对齐性能将不可避免地受到影响,因为更复杂的结构,如三角形结构,经常出现在多关系图中。
基于GCN的模型代表了基于嵌入的实体对齐的飞跃。然而,这种方法也无法正确地对关系信息进行建模。由于普通GCN是在无向和无标号图上操作的,因此基于GCN的模型会忽略KG的有用关系信息。DPGCNN在图及其对偶图上交替进行卷积操作,其顶点对应于原始图的边缘,并迭代地应用图注意力机制来使用其对偶图增强原始边缘表示。
受DPGCNN的启发,在本文中,提出了一种新的具有感知能力的双图卷积网络(RDGCN),RDGCN方法通过与原始实体图和对偶关系图之间的多轮交互,有效地将更复杂的关系信息融入实体表示。为了进一步融合邻域结构信息,我们还扩展了带有高速公路门控的GCN。
这项工作的主要贡献是一种新的DPGCNN为基础的模型学习强大的KG表示。
2 Related Work
2.1 Graph Convolutional Networks
对扩展神经网络来处理图形的工作:光谱方法、空间方法
GCN:已经成为许多NLP任务的强大的基于深度学习的方法
R-GCN:对关系数据进行建模,并已成功地用于链接预测和实体分类
DPGCNN(GAT模型的推广):顶点分类,链接预测和图引导矩阵
3 Problem Formulation
KG表示 G = ( E , R , T ) G =(E, R, T) G=(E,R,T),其中 E , R , T E,R,T E,R,T分别是实体,关系和三元组的集合。
两个异质KG: G 1 = ( E 1 , R 1 , T 1 ) G_1 =(E_1,R_1,T_1) G1=(E1,R1,T1)和 G 2 = ( E 2 , R 2 , T 2 ) G_2 =(E_2,R_2,T_2) G2=(E2,R2,T2)
种子: L = { ( e i 1 , e i 2 ) ∣ e i 1 ∈ E 1 , e i 2 ∈ E 2 } \mathbb L = \{(e_{i1},e_{i2})|e_{i1}\in E_1,e_{i2}\in E_2\} L={(ei1,ei2)∣ei1∈E1,ei2∈E2}
4 Our Approach: RDGCN
给定输入KG(即原始图),首先构造其对偶关系图,其顶点表示原始图中的关系,然后利用图注意机制来鼓励对偶关系图与原始图之间的交互.然后将原始图中的结果顶点表示馈送到具有高速公路门控的GCN层,以捕获相邻的结构信息。最终的实体表示将用于确定两个实体是否应对齐。(可以分三个部分:对偶图的构建,对偶图与原始图的交互,和结构信息集成)
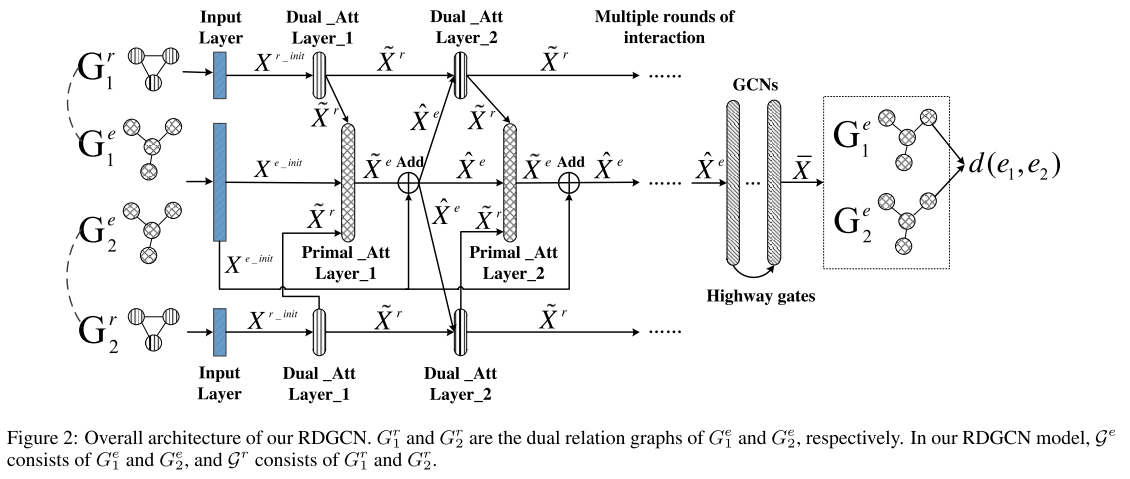
其中, G 1 r , G 2 r G_1^r,G_2^r G1r,G2r 分别是 G 1 e , G 2 e G_1^e,G_2^e G1e,G2e的对偶关系图,在 RDGCN 模型中, G e \mathcal G^e Ge由 G 1 e , G 2 e G_1^e, G_2^e G1e,G2e组成, G r \mathcal G^r Gr由 G 1 r , G 2 r G_1^r, G_2^r G1r,G2r组成。
4.1 Constructing the Dual Relation Graph
将 G 1 G_1 G1和 G 2 G_2 G2放在一起作为原始图 G e = ( V e , E e ) \mathcal G^e =(\mathcal V^e, \mathcal E^e) Ge=(Ve,Ee),其中顶点集 V e = E 1 ∪ E 2 \mathcal V^e = E_1 \cup E_2 Ve=E1∪E2是 G 1 G_1 G1和 G 2 G_2 G2中所有顶点的并集,边集 E e = T 1 ∪ T 2 \mathcal E^e = T_1 \cup T_2 Ee=T1∪T2是 G 1 G_1 G1和 G 2 G_2 G2中所有边/三元组的并集。
给定原始图 G e \mathcal G^e Ge,其对偶关系图 G r = ( V r , E r ) \mathcal G^r =(\mathcal V^r,\mathcal E^r) Gr=(Vr,Er)构造如下:
- 对于 G e \mathcal G^e Ge中的每种类型的关系 r r r, V r \mathcal V^r Vr中将存在顶点 v r v^r vr,因此 V r = R 1 ∪ R 2 \mathcal V^r = R_1 \cup R_2 Vr=R1∪R2;
- 如果两个关系 r i r_i ri和 r j r_j rj在 G e \mathcal G^e Ge中共享相同的头或尾实体,则在 G r \mathcal G^r Gr中创建连接 v i r v_i^r vir和 v j r v^r_j vjr的边 u i j r u^r_{ij} uijr。
根据两个关系 v i r v^r_i vir和 v j r v^r_j vjr在 G e \mathcal G^e Ge中共享类似头部或尾部的可能性,用权重 w i j r w^r_{ij} wijr对 G r \mathcal G^r Gr中的每条边 u i j r u^r_{ij} uijr进行加权,计算如下:
w i j r = H ( r i , r j ) + T ( r i , r j ) w_{ij}^r=H(r_i,r_j)+T(r_i,r_j) wijr=H(ri,rj)+T(ri,rj)
H ( r i , r j ) = H i ∩ H j H i ∪ H j , T ( r i , r j ) = T i ∩ T j T i ∪ T j H(r_i,r_j)=\frac{H_i\cap H_j}{H_i\cup H_j},T(r_i,r_j)=\frac{T_i\cap T_j}{T_i\cup T_j} H(ri,rj)=Hi∪HjHi∩Hj,T(ri,rj)=Ti∪TjTi∩Tj
其中 H i H_i Hi和 T i T_i Ti分别是 G e \mathcal G^e Ge中关系 r i r_i ri的头和尾实体的集合。构造对偶图的开销与原始图中的关系类型的数量成比例。
4.2 Interactions between Dual and Primal Graphs
引入对偶关系图的目的是更好地将关系信息融入到原始图表示中。为此,我们建议应用图注意机制(GAT)迭代地获得对偶关系图和原始图的顶点表示,其中注意机制有助于提示两个图之间的交互。每一个双原始交互包含两个层,双注意层和原始注意层。
Dual Attention Layer(双重注意层)
令 X r ∈ R m × 2 d \mathbf{X}^r \in \mathbb R^{m\times 2d} Xr∈Rm×2d表示输入对偶顶点表示矩阵,其中每行对应于对偶关系图 G r \mathcal G^r Gr中的一个顶点。不同于普通的GAT使用原始顶点特征来计算双重注意力分数 X ^ e \hat{\mathbf{X}}^e X^e 由来自先前交互模块的原始注意力层产生:
x ~ i r = σ r ( ∑ j ∈ N i r α i j r x j r ) , \tilde{\mathbf{x}}_{i}^{r}=\sigma^{r}(\sum_{j\in N_{i}^{r}}\alpha_{ij}^{r}\mathbf{x}_{j}^{r}), x~ir=σr(j∈Nir∑αijrxjr),
α i j r = e x p ( η ( w i j r a r [ c i ∥ c j ] ) ) ∑ k ∈ N i r e x p ( η ( w i k r a r [ c i ∥ c k ] ) ) , \alpha_{ij}^{r}=\frac{exp(\eta(w_{ij}^{r}a^{r}[\mathbf{c}_{i}\|\mathbf{c}_{j}]))}{\sum_{k\in N_{i}^{r}}exp(\eta(w_{ik}^{r}a^{r}[\mathbf{c}_{i}\|\mathbf{c}_{k}]))}, αijr=∑k∈Nirexp(η(wikrar[ci∥ck]))exp(η(wijrar[ci∥cj])),
其中, x ~ i r \tilde{\mathbf{x}}_i^r x~ir表示在对偶顶点 v i r v^r_i vir处的 d ′ d' d′维输出表示(对应于关系 r i ∈ G e r_i \in \mathcal G^e ri∈Ge); x ~ j r \tilde{\mathbf{x}}_j^r x~jr表示顶点 v j r v^r_j vjr的对偶表示; N i r N^r_i Nir是 v i r v^r_i vir的邻居索引的集合; α i j r \alpha^r_{ij} αijr是对偶注意力分数; a r a^r ar是将 2 d ′ 2d' 2d′维输入映射到标量中的全连接层; σ r \sigma_r σr是激活函数ReLU; η \eta η是修正线性单元(Leaky ReLU); c i \mathbf c_i ci是从先前的原始注意力层获得的 G e \mathcal G^e Ge中的关系 r i r_i ri的关系表示。
基于图嵌入的框架中,由于训练数据有限,无法直接提供关系表示。因此,通过连接 G e \mathcal G^e Ge中的平均头部和尾部实体表示来近似 r i r_i ri的关系表示:
c i = [ ∑ k ∈ H i x ^ k e ∣ H i ∣ ∥ ∑ l ∈ T i x ^ l e ∣ T i ∣ ] , \mathbf{c}_{i}=[\frac{\sum_{k\in H_{i}}\hat{\mathbf{x}}_{k}^{e}}{|H_{i}|}\|\frac{\sum_{l\in T_{i}}\hat{\mathbf{x}}_{l}^{e}}{|T_{i}|}], ci=[∣Hi∣∑k∈Hix^ke∥∣Ti∣∑l∈Tix^le],
其中, x ^ k e 和 x ^ l e \hat{\mathbf{x}}_{k}^{e}和\hat{\mathbf{x}}_{l}^{e} x^ke和x^le是来自先前的主要关注层的关系 r i r_i ri的第 k k k个头实体和第 l l l个尾实体的输出表示。
Primal Attention Layer(原始注意力层)
使用 X e ∈ R n × d \mathbf{X}^e \in \mathbb R^{n\times d} Xe∈Rn×d来表示输入原始顶点表示矩阵。对于原始图 G e \mathcal G^e Ge中的实体 e q e_q eq,其表示 x ^ q e \hat{\mathbf{x}}_{q}^{e} x^qe可以通过下式计算:
x ~ q e = σ e ( ∑ t ∈ N q e α q t e x t e ) , \tilde{\mathbf{x}}_{q}^{e}=\sigma^{e}(\sum_{t\in N_{q}^{e}}\alpha_{qt}^{e}\mathbf{x}_{t}^{e}), x~qe=σe(t∈Nqe∑αqtexte),
α q t e = e x p ( η ( a e ( x ~ q t r ) ) ) ∑ k ∈ N q e e x p ( η ( a e ( x ~ q k r ) ) ) , \alpha_{qt}^{e}=\frac{exp(\eta(a^{e}(\tilde{\mathbf{x}}_{qt}^{r})))}{\sum_{k\in N_{q}^{e}}exp(\eta(a^{e}(\tilde{\mathbf{x}}_{qk}^{r})))}, αqte=∑k∈Nqeexp(η(ae(x~qkr)))exp(η(ae(x~qtr))),
其中, x ~ q t r \tilde{\mathbf{x}}_{qt}^{r} x~qtr表示从 G r \mathcal G^r Gr获得的 r q t r_{qt} rqt(实体 e q e_q eq和 e t e_t et之间的关系)的对偶表示; α q t e \alpha^e_{qt} αqte是原始注意力分数; N q e N^e_q Nqe是 G e \mathcal G^e Ge中实体 e q e_q eq的邻居索引的集合; a e a^e ae是将 d ′ d' d′维输入映射到标量的全连接层, σ e \sigma^e σe是原始层激活函数。
原始顶点的初始表示矩阵 X e _ i n i t \mathbf{X}^{e\_init} Xe_init,可以使用实体名称初始化,这为实体对齐提供了重要的证据。因此,我们通过将初始表示与原始注意力层的输出混合来显式地保留证据:
x ^ q e = β s ∗ x ~ q e + x q e _ i n i t , \hat{\mathbf{x}}_{q}^{e}=\beta_{s}*\tilde{\mathbf{x}}_{q}^{e}+\mathbf{x}_{q}^{e\_init}, x^qe=βs∗x~qe+xqe_init,
其中, x ~ q e \tilde{\mathbf{x}}_{q}^{e} x~qe表示 G e \mathcal G^e Ge中实体 e q e_q eq的交互模块的最终输出表示; β s \beta_s βs是第 s s s个主要注意力层的加权参数。
4.3 Incorporating Structural Information
在对偶关系图和原始图之间的多轮交互之后,从原始图中收集关系感知实体表示。接下来,将带有高速公路门的双层GCN应用于生成的原始图,以进一步纳入来自其相邻结构的证据。
在具有实体表示 X ( l ) X^{(l)} X(l)作为输入的每个GCN层 l l l中,输出表示 X ( l + 1 ) X^{(l+1)} X(l+1)可以被计算为:
X ( l + 1 ) = ξ ( D ~ − 1 2 A ~ D ~ − 1 2 X ( l ) W ( l ) ) , X^{(l+1)}=\xi(\tilde D^{-\frac{1}{2}}\tilde A\tilde D^{-\frac{1}{2}}X^{(l)}W^{(l)}), X(l+1)=ξ(D~−21A~D~−21X(l)W(l)),
其中, A ~ = A + I \tilde A = A+I A~=A+I是添加了自连接的原始图 G e \mathcal G^e Ge的邻接矩阵, I I I是单位矩阵; D ~ j j = ∑ k A ~ j k \tilde D_{jj} = \sum_k\tilde A_{jk} D~jj=∑kA~jk, W ( l ) ∈ R d ( l ) × d ( l + 1 ) W^{(l)}\in \mathbb R^{d(l)}\times d^{(l+1)} W(l)∈Rd(l)×d(l+1)是层特定的可训练权重矩阵; ξ \xi ξ是激活函数ReLU。在构造 A A A时,将 G e \mathcal G^e Ge视为无向图,以允许信息在两个方向上流动。
此外,为了控制跨层累积的噪声并保留从交互中学习到的有用的关系信息,在GCN层之间引入逐层门,类似于高速公路网络:
T ( X ( l ) ) = σ ( X ( l ) W T ( l ) + b T ( l ) ) , T(X^{(l)})=\sigma(X^{(l)}W_{T}^{(l)}+b_{T}^{(l)}), T(X(l))=σ(X(l)WT(l)+bT(l)),
X ( l + 1 ) = T ( X ( l ) ) ⋅ X ( l + 1 ) + ( 1 − T ( X ( l ) ) ) ⋅ X ( l ) , X^{(l+1)}=T(X^{(l)})\cdot X^{(l+1)}+(1-T(X^{(l)}))\cdot X^{(l)}, X(l+1)=T(X(l))⋅X(l+1)+(1−T(X(l)))⋅X(l),
其中 X ( l ) X^{(l)} X(l)是层 l + 1 l+1 l+1的输入; σ \sigma σ是sigmoid函数; ⋅ \cdot ⋅ 是逐元素乘法; X T ( l ) X^{(l)}_T XT(l)和 b T ( l ) b^{(l)}_T bT(l)是变换门 T ( X ( l ) ) T(X^{(l)}) T(X(l))的权重矩阵和偏置向量。
**对齐。**从 GCN 层的输出中收集最终的实体表示 X ‾ \overline X X ,考虑两个实体之间的距离作为对齐分数:
d ( e 1 , e 2 ) = ∥ x ˉ e 1 − x ˉ e 2 ∥ L 1 . d(e_1,e_2)=\|\bar{x}_{e_1}-\bar{x}_{e_2}\|_{L_1}. d(e1,e2)=∥xˉe1−xˉe2∥L1.
4.4 Training
对于训练,期望对齐实体对之间的距离尽可能近,而否定实体对之间的距离尽可能远。使用基于边缘的评分函数作为训练目标:
L = ∑ ( p , q ) ∈ L ∑ ( p ′ , q ′ ) ∈ L ′ max { 0 , d ( p , q ) − d ( p ′ , q ′ ) + γ } , L=\sum_{(p,q)\in\mathbb{L}}\sum_{(p',q')\in\mathbb{L}'}\max\{0,d(p,q)-d(p',q')+\gamma\}, L=(p,q)∈L∑(p′,q′)∈L′∑max{0,d(p,q)−d(p′,q′)+γ},
其中 γ > 0 \gamma > 0 γ>0是一个边缘超参数; L \mathbb L L是我们的比对种子, L ′ \mathbb L' L′是负实例的集合。
寻找具有挑战性的负样本,给定一个正对齐对 ( p , q ) (p, q) (p,q),选择 p ( o r q ) p(or\ q) p(or q)的 K \mathcal K K-最近实体,嵌入空间中替换 q ( o r p ) q(or\ p) q(or p)作为负实例。
5 Experimental Setup
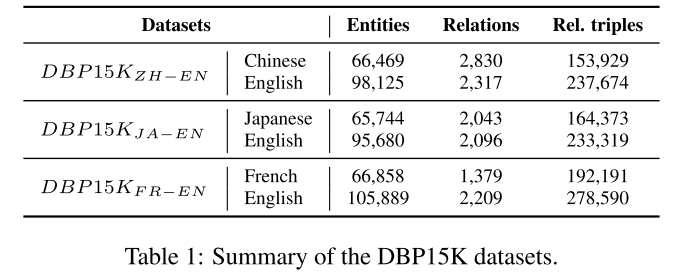
数据集:DBP15K,30%用于训练,70%用于测试。
比较模型:JE、MTransE、JAPE、IPTransE、BootEA 、GCN
模型变体:
- GCN-s:具有实体名称初始化但没有高速公路门的双层GCN;
- R-GCN-s:双层R-GCN
- HGCN-s:具有实体名称初始化和高速公路门的两层GCN;
- RD:两个双原始交互模块的实现,但没有后续的GCN层。
6 Results and Discussion
6.1 Main Results
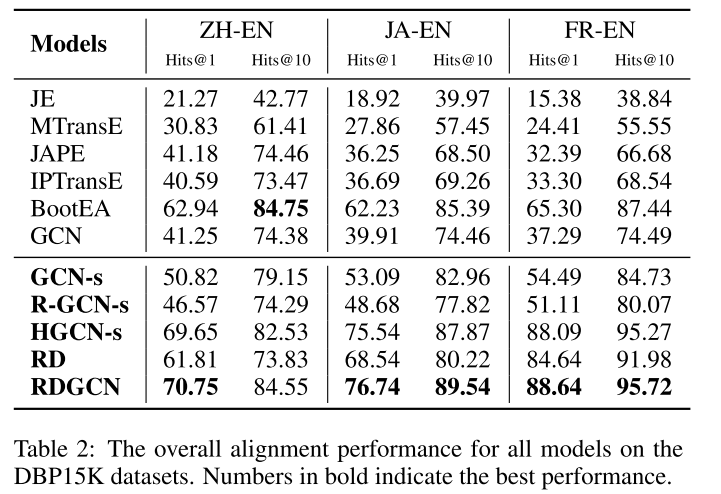
RDGCN在所有指标和数据集上都提供了最佳性能,除了在 D B P 15 K Z H − E N DBP15K_{ZH-EN} DBP15KZH−EN上的 H i t s @ 10 Hits@10 Hits@10,RDGCN的性能仅次于BootEA,得分略低(84.55 vs 84.75)。
6.2 Ablation Studies
GCN-s与GCN: GCN-s在所有数据集中显著改善了GCN,
GCN-s与R-GCN-s: R-GCN是GCN的扩展,通过显式地建模KG关系,GCN-s在所有数据集上都比RGCN-s实现了更好的性能。
HGCN-s与GCN-s: HGCN-s在采用分层公路门之后,大大提高了GCN-s的性能,这主要是由于它们能够防止噪声顶点驱动KG表示。
HGCN-s与RDGCN: 双原始交互模块对性能至关重要,交互模块通过引入近似关系信息来挖掘知识库的关系特征,并通过对偶关系图与原始图的多次交互,将关系和实体信息充分融合。结果表明,有效的建模和关系信息的使用是有益的实体对齐。
RD与RDGCN: 从模型中删除GCN层时,性能会显著下降。因为双原始图交互被设计为集成KG关系信息,而GCN层可以有效地捕获KG的相邻结构信息。这两个关键组件在某种程度上是互补的,应该结合在一起学习更好的关系感知表示。
6.3 Analysis
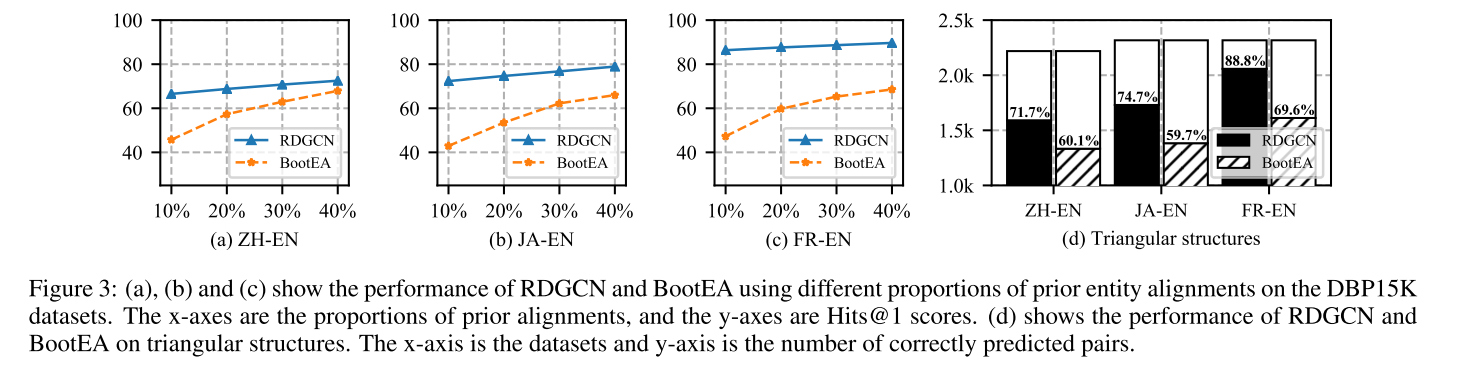
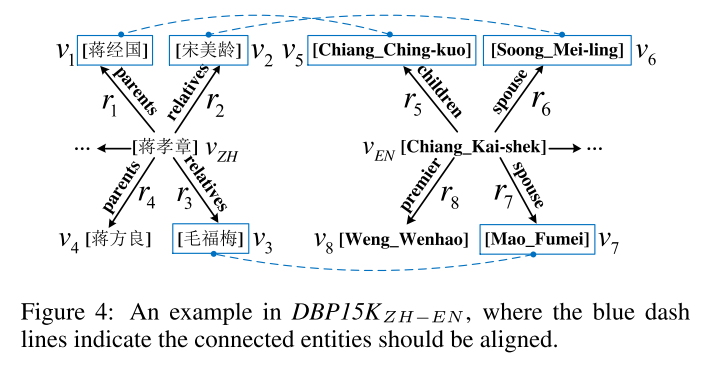
通过对原始图和对偶关系图之间的密切交互进行建模,RDGCN能够通过门控GCN层将关系信息与相邻结构信息结合起来,并学习更好的实体表示以进行对齐。与最先进的方法相比,RDGCN使用更少的训练数据,但在三个真实世界的数据集上实现了最佳的对齐性能。
论文原文:
https://www.ijcai.org/proceedings/2019/0733.pdf
GitHub仓库:
https://github.com/StephanieWyt/RDGCN
论文原文:
https://www.ijcai.org/proceedings/2019/0733.pdf
GitHub仓库:



























![[MSSQL]理解SQL Server AlwaysOn AG的备份](https://img-blog.csdnimg.cn/direct/fbb3cf8c28554ad69d321437742e428d.png)