一、lebelme
1、界面介绍
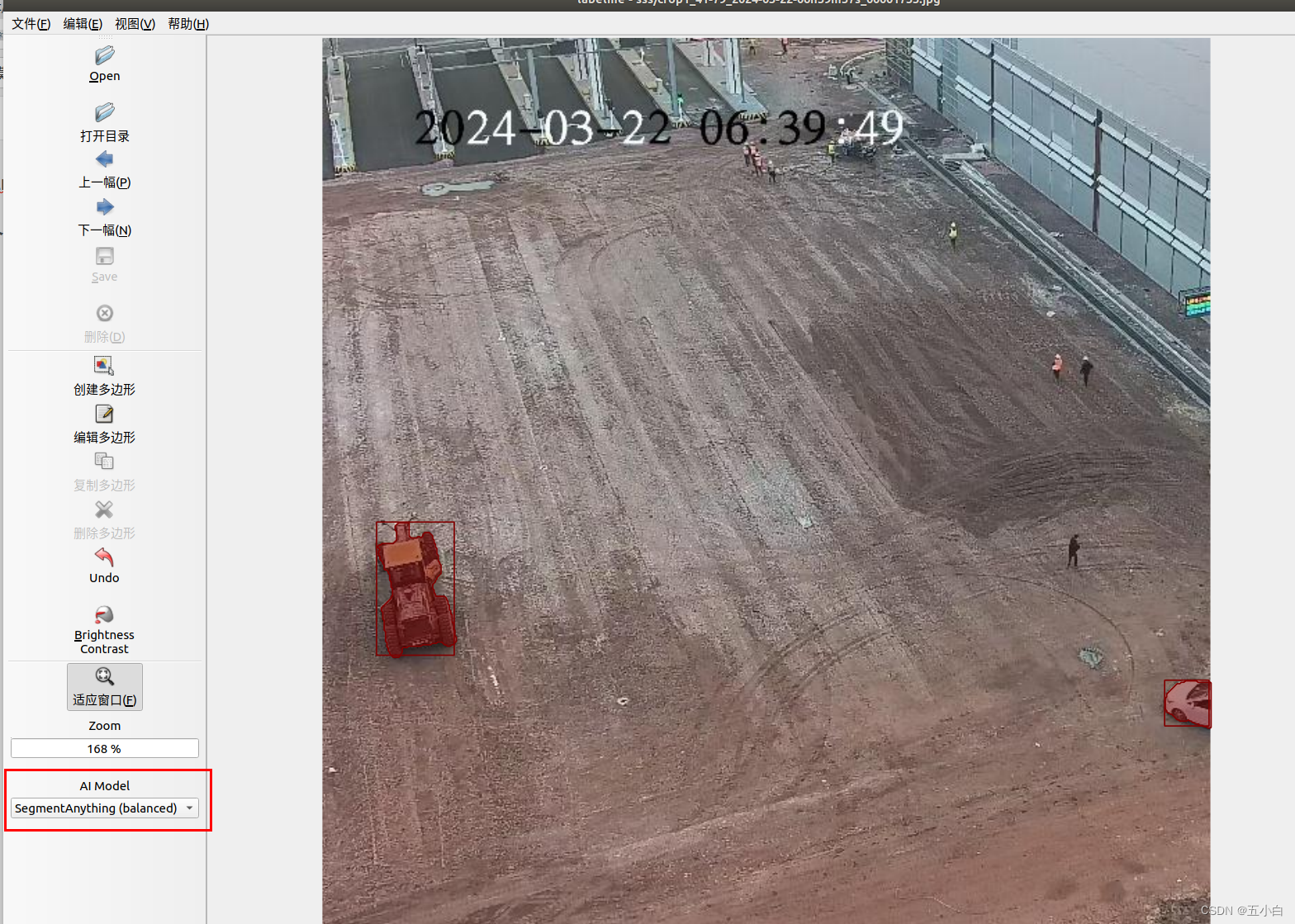
点击上图位置,选择对应的模型。这里我每个模型都测试了一下,EfficientSam这个模型最好用,准确率和速度都ok。
2、使用方法
目标框标注方法:点左上角【编辑】-> 【Create Ai-Mask】就可以标志了,这个是标注的mske区域和目标框。但是mask区域无法修改,等同于获取目标框。目标检测项目标注方法。
目标mask注方法:点左上角【编辑】-> 【Create Ai-Polygon】标注的是mask区域,这个区域是可以修改的,一般是用作语义分割等任务。
单击左键选择目标,双击左键目标标注就完成了,此时会出现选择目标标签的选项了。
二、模型介绍
注意,有encoder和decoder 两个。建议直接用EfficientSam (accuracy)对应的模型。
1、模型下载地址
# 模型下载地址
# sam_vit_b "SegmentAnything (speed)"
url="https://github.com/wkentaro/labelme/releases/download/sam-20230416/sam_vit_b_01ec64.quantized.encoder.onnx",
md5="80fd8d0ab6c6ae8cb7b3bd5f368a752c",
url="https://github.com/wkentaro/labelme/releases/download/sam-20230416/sam_vit_b_01ec64.quantized.decoder.onnx",
md5="4253558be238c15fc265a7a876aaec82",
# sam_vit_l "SegmentAnything (balanced)"
url="https://github.com/wkentaro/labelme/releases/download/sam-20230416/sam_vit_l_0b3195.quantized.encoder.onnx",
md5="080004dc9992724d360a49399d1ee24b",
url="https://github.com/wkentaro/labelme/releases/download/sam-20230416/sam_vit_l_0b3195.quantized.decoder.onnx",
md5="851b7faac91e8e23940ee1294231d5c7",
# sam_vit_h "SegmentAnything (accuracy)" 这个模型效果可以,速度巨慢
url="https://github.com/wkentaro/labelme/releases/download/sam-20230416/sam_vit_h_4b8939.quantized.encoder.onnx",
md5="958b5710d25b198d765fb6b94798f49e",
url="https://github.com/wkentaro/labelme/releases/download/sam-20230416/sam_vit_h_4b8939.quantized.decoder.onnx",
md5="a997a408347aa081b17a3ffff9f42a80",
# efficient_sam_vitt "EfficientSam (speed)"
url="https://github.com/labelmeai/efficient-sam/releases/download/onnx-models-20231225/efficient_sam_vitt_encoder.onnx",
md5="2d4a1303ff0e19fe4a8b8ede69c2f5c7",
url="https://github.com/labelmeai/efficient-sam/releases/download/onnx-models-20231225/efficient_sam_vitt_decoder.onnx",
md5="be3575ca4ed9b35821ac30991ab01843",
# efficient_sam_vits "EfficientSam (accuracy)" 这个模型速度和效果都非常不错,建议直接用这个
url="https://github.com/labelmeai/efficient-sam/releases/download/onnx-models-20231225/efficient_sam_vits_encoder.onnx",
md5="7d97d23e8e0847d4475ca7c9f80da96d",
url="https://github.com/labelmeai/efficient-sam/releases/download/onnx-models-20231225/efficient_sam_vits_decoder.onnx",
md5="d9372f4a7bbb1a01d236b0508300b994",
2、模型保存位置
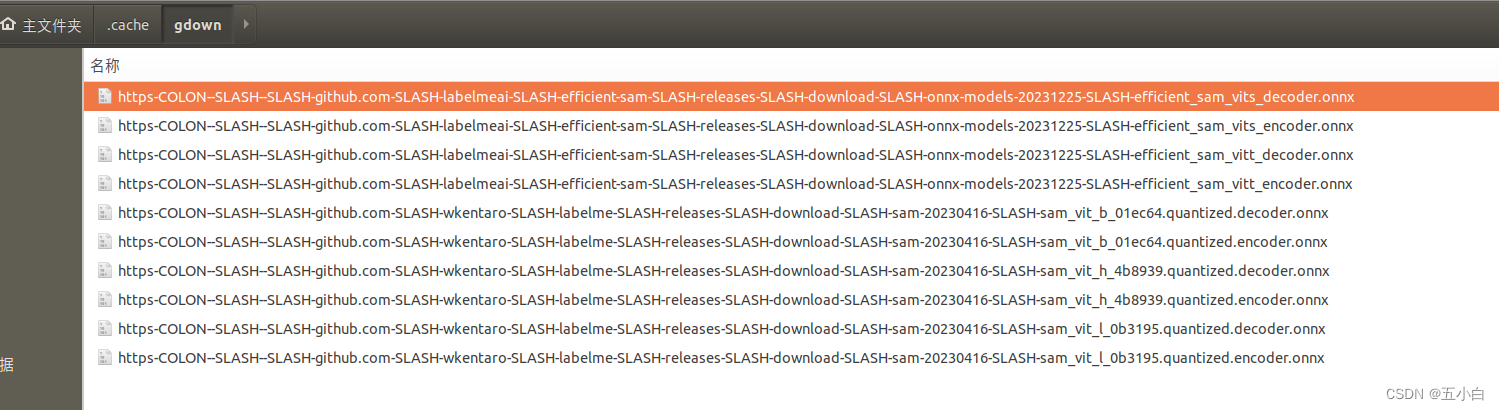
下载模型后,放到 /home/wqg/.cache/gdown 下,需要注意一下,要把模型的名称修改一下。
SegmentAnything系列,模型名称加上这个:
https-COLON--SLASH--SLASH-github.com-SLASH-wkentaro-SLASH-labelme-SLASH-releases-SLASH-download-SLASH-sam-20230416-SLASH-
EfficientSam 系列,模型名称前加上这个:
https-COLON--SLASH--SLASH-github.com-SLASH-labelmeai-SLASH-efficient-sam-SLASH-releases-SLASH-download-SLASH-onnx-models-20231225-SLASH-
最后的模型如下:
这里已经可以使用了,不过推荐模型有一点点慢,后面使用GPU加速后推荐模型推理非常快。
三、使用onnxruntime-GPU 做模型推理
模型推理需要安装cuda和cudnn。安装问题可以自己百度一下。推荐模型推理,大概占用显存4G左右。
1、代码位置。
安装好labelme后,记住安装的位置,一般存在anaconda的环境下,在对应环境下找site-packages。由于我是装在.local下。所以我的是如下位置。

打开后会有一个ai的文件夹。
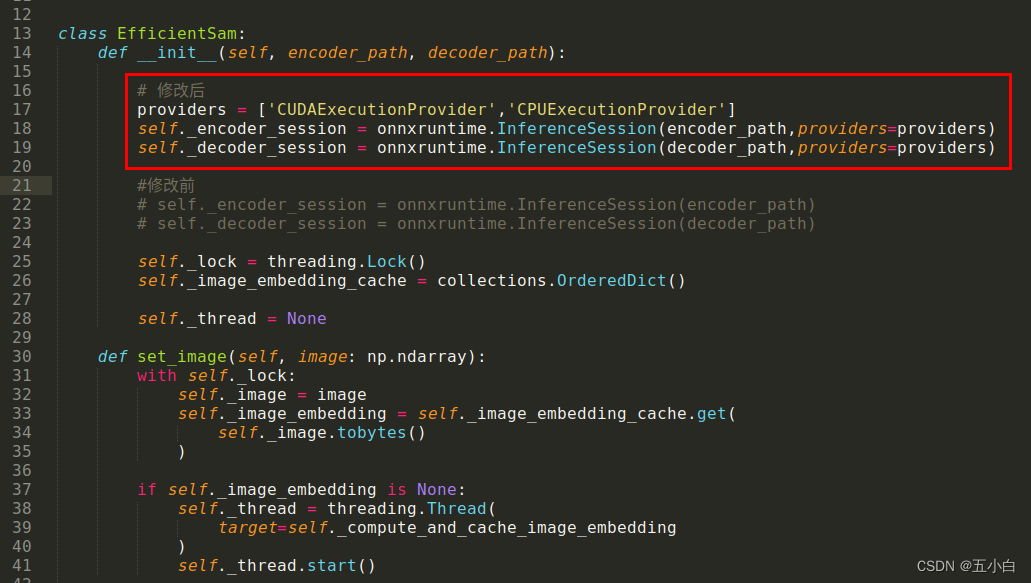
找到 efficient_sam.py 和 segment_anything_model.py 文件,修改对应的 init 方法即可
# segment_anything_model.py
class SegmentAnythingModel:
def __init__(self, encoder_path, decoder_path):
self._image_size = 1024
# 修改后
providers = ['CUDAExecutionProvider','CPUExecutionProvider'] # if cuda else ['CPUExecutionProvider']
self._encoder_session = onnxruntime.InferenceSession(encoder_path, providers=providers)
self._decoder_session = onnxruntime.InferenceSession(decoder_path, providers=providers)
#修改前
# self._encoder_session = onnxruntime.InferenceSession(encoder_path)
# self._decoder_session = onnxruntime.InferenceSession(decoder_path)
self._lock = threading.Lock()
self._image_embedding_cache = collections.OrderedDict()
self._thread = None
# efficient_sam.py
class EfficientSam:
def __init__(self, encoder_path, decoder_path):
# 修改后
providers = ['CUDAExecutionProvider','CPUExecutionProvider']
self._encoder_session = onnxruntime.InferenceSession(encoder_path,providers=providers)
self._decoder_session = onnxruntime.InferenceSession(decoder_path,providers=providers)
#修改前
# self._encoder_session = onnxruntime.InferenceSession(encoder_path)
# self._decoder_session = onnxruntime.InferenceSession(decoder_path)
self._lock = threading.Lock()
self._image_embedding_cache = collections.OrderedDict()
self._thread = None
这里给出 efficient_sam.py 文件的修改图。
四、本站蜘蛛onnx下载链接
这里的模型是已经修改过名字的,不需要修改名称,直接放到对应位置就行。百度云链接























![filebox在线文件管理工具V1.11.1.1查分吧修改自用版免费分享[PHP]](https://img-blog.csdnimg.cn/direct/510f10a56ec049929c13fbde48143224.png)