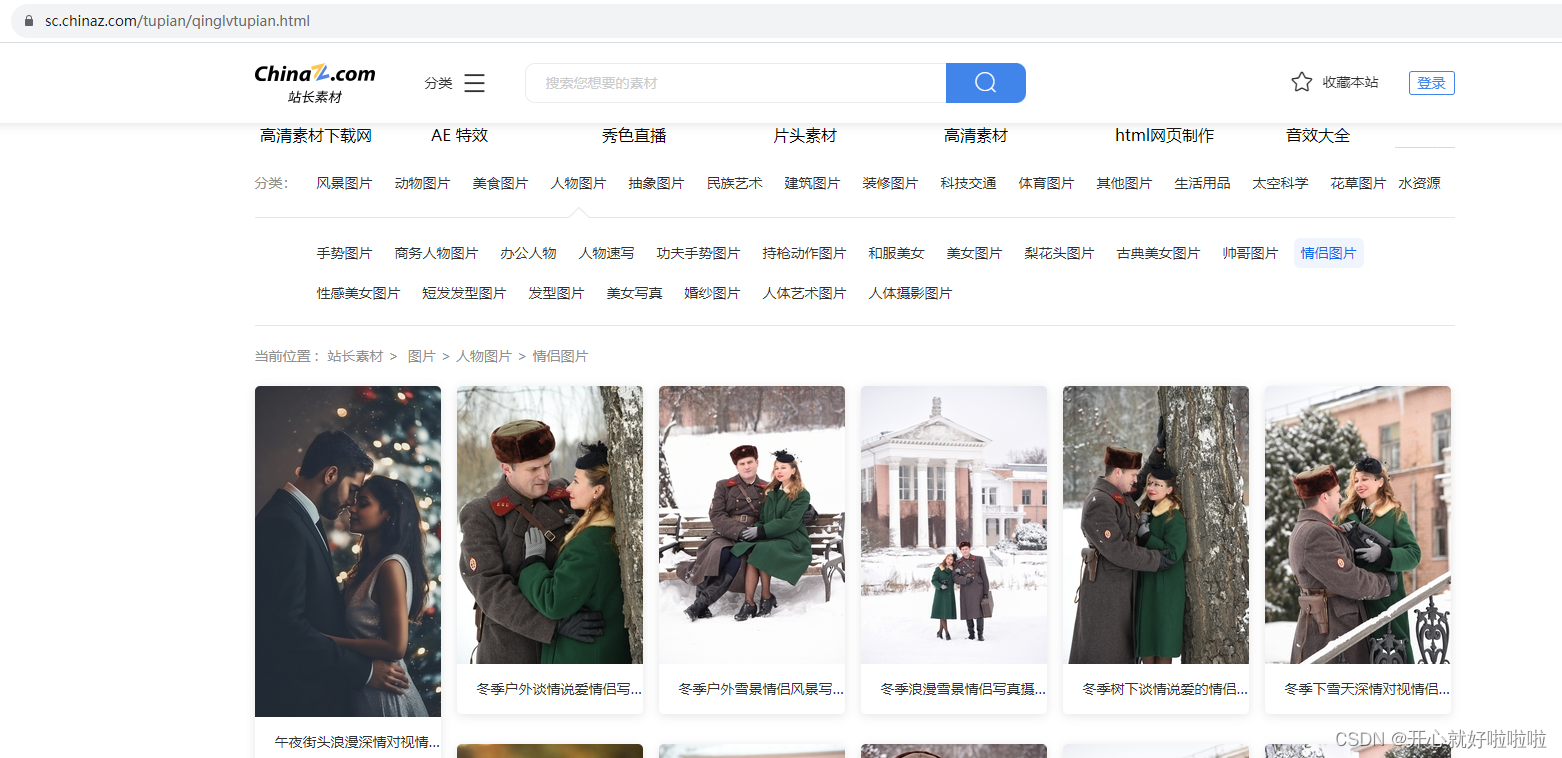
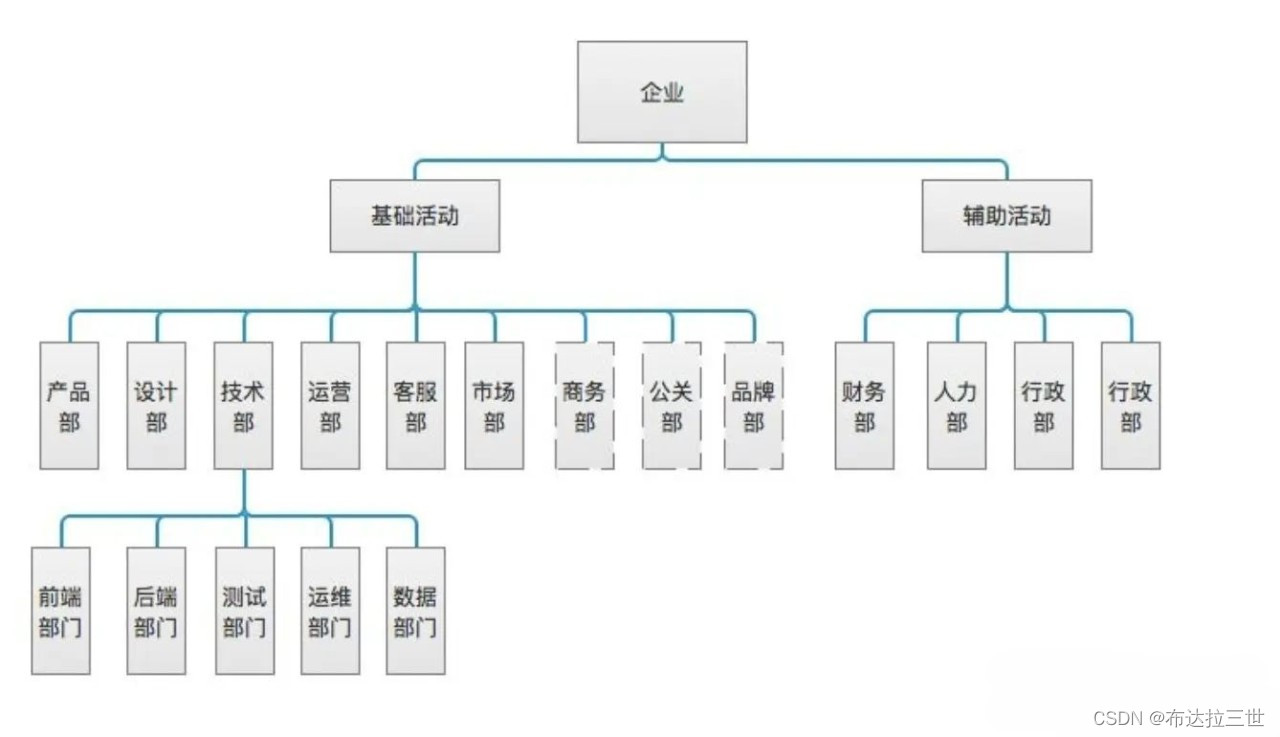
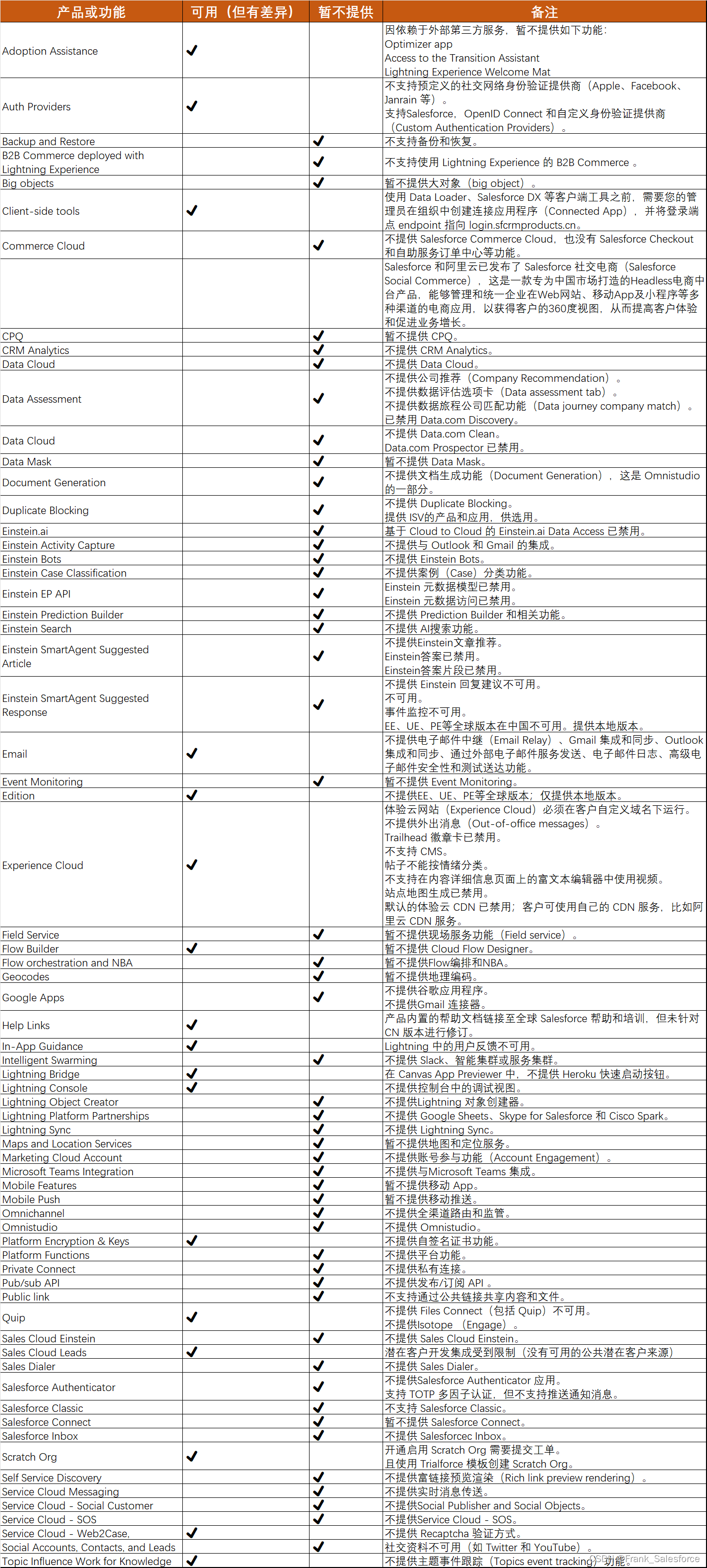
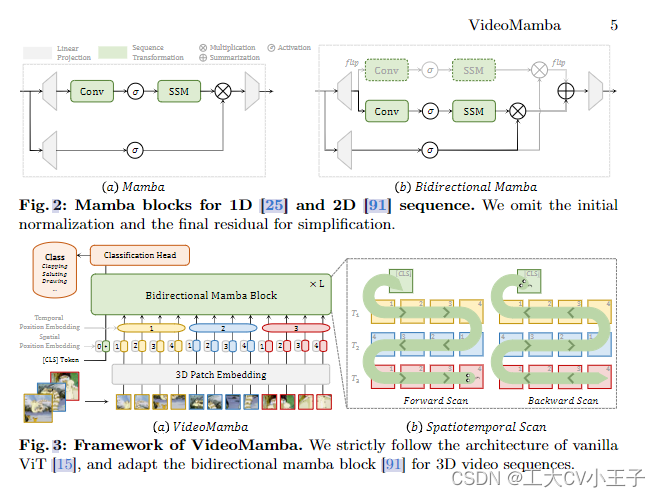
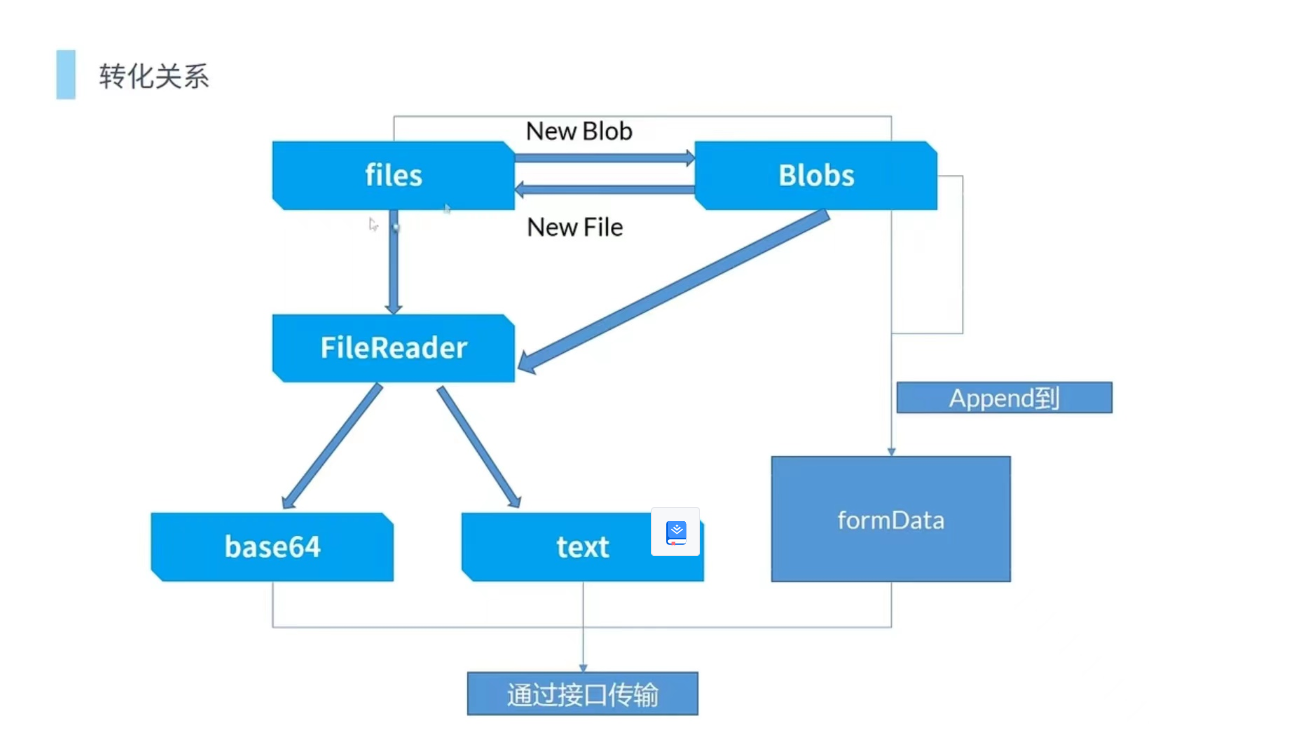
进入自己的学习通网站主页检查网络

可以发现只有courselistdata响应信息由我们想要的东西

该请求url我用模拟登录+cookie试了下,应该是有反爬机制,响应是403 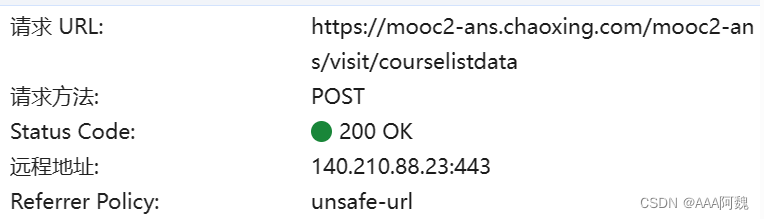
所以我把courselistdata的响应信息全部手动复制并保存为本地txt文件和html文件
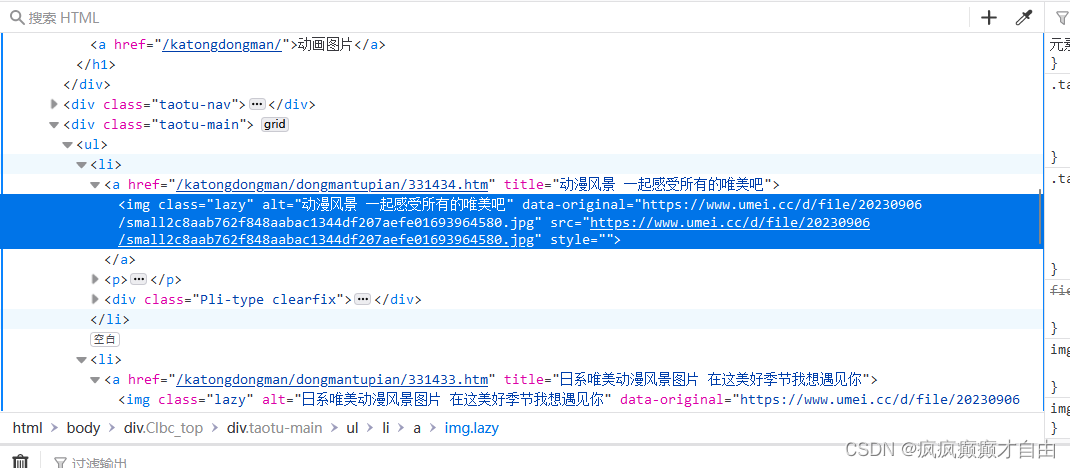
可以发现课程名的样式是span标签加上class='course-name overHidden2',所以只要抓取指定样式的内容就行了
![]()
![]()
开始写代码
from bs4 import BeautifulSoup
# 读取 HTML 文件
with open('result.html', 'r', encoding='utf-8') as file:
html_content = file.read()
# 使用 BeautifulSoup 解析页面内容
soup = BeautifulSoup(html_content, 'html.parser')
# 查找所有指定样式的内容
course_names = soup.find_all('span', class_='course-name overHidden2')
# 保存内容到TXT文档
with open('course_names.txt', 'w', encoding='utf-8') as file:
for course_name in course_names:
file.write(course_name.text + '\n')
print('内容已成功保存到 course_names.txt 文件中')代码最终是保存在一个txt文档里的,下面是结果

同理,可以发现课程图片的链接都是以src开头+http://.....的形式的,所以使用正则表达式获取所有的图片链接并保存在img文件夹内
# import re
# import requests
#
# # 读取文本文件内容
# with open("result.txt", mode="r", encoding="UTF-8") as f:
# text = f.read()
#
# # 使用正则表达式查找所有图片链接
# result = re.findall(r'<img.*?src="(http.*?)".*?>', text)
# print(result)
# # 创建一个 Session 对象
# session = requests.Session()
# # 添加请求头信息
# session.headers = {
# "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0",
# "Cookie": 'fid=18743; lv=1;_uid=236979880; UID=236979880;vc=137C52E726857E8F909BE63816932583;xxtenc=ddbc37dc960f59c4e4d80e7d212577c5; uf=b2d2c93beefa90dc62d0140d27586032be363a80c34379c8d55b182f4be7c0cdea1bb3571a26a1eb6edce3182980a667273683571faa0dcd88b83130e7eb4704a07401fce4235b32ce915f659a7402a8eea6be31981211d2c73072b75b8ec48b996adb45563782ea; _d=1711287844321; vc2=64BBB1352F74F266EA1110742827E42B; vc3=DiLAK%2FjtrTE2cmk6mArbULln8pJr%2BfA3UDzlOrNN%2Fc2cZAub5Cto8BI4SdxzMHme99F6R6DDq6cVxLPZnVXv6MDqnS25i82UVemY6g0PgxxV9Vn7197SiPLmlOAp5Nb0yPy9oPWrRoPHa95pUy91RReKj8RMqqF%2FVc5CKByXQ%2Bw%3Df84771ac7a8f04a131bbb08a9a5693f5; cx_p_token=2e9d9f80ee244828a78c88adb75b8286; p_auth_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1aWQiOiIyMzY5Nzk4ODAiLCJsb2dpblRpbWUiOjE3MTEyODc4NDQzMjMsImV4cCI6MTcxMTg5MjY0NH0.zbdW33Q-ypoJUryCOWOOy-aA1LrQC0ApZXT8gsCjJUY; DSSTASH_LOG=C_38-UN_755-US_236979880-T_1711287844323; tl=1; orgfid=31057; registerCode=00010013000100010034; createSiteSource=num9; source=num9; wfwEnc=7BE3D5CDD9642876BB1DCA0A31350E89; spaceFid=18743; spaceRoleId=''; k8s=1711633502.83.442.232697; route=2fe558bdb0a1aea656e6ca70ad0cad20; _industry=5; jrose=4FC9840C52C3D251E1C3A988291A2346.mooc2-387400510-8w2l6'# 这里省略了 Cookie 的部分内容
# }
#
#
# # 下载所有图片
# for idx, img_url in enumerate(result):
# filename = f"image_{idx}.jpg"
# response = requests.get(img_url)
# if response.status_code == 200:
# with open(filename, 'wb') as img_file:
# img_file.write(response.content)
# print(f"图片 {idx} 下载成功")
# else:
# print(f"图片 {idx} 下载失败,状态码:{response.status_code}")上面的代码是有问题的,请求下载图片会被拒绝,因为图片的网址是在学习通账号内部的
所以需要增加模拟登录来骗过浏览器(登录信息结合自己的帐号来)
import re
import requests
import base64
import os
# 读取文本文件内容
with open("result.txt", mode="r", encoding="UTF-8") as f:
text = f.read()
# 使用正则表达式查找所有图片链接
result = re.findall(r'<img.*?src="(http.*?)".*?>', text)
print(result)
# 创建一个 Session 对象
session = requests.Session()
# 设置登录信息
username = "手机号"
password = "密码"
login_info = f"{username}:{password}"
base64_login_info = base64.b64encode(login_info.encode()).decode()
session.headers["Authorization"] = f"Basic {base64_login_info}"
# 添加请求头信息
session.headers.update({
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0",
"Cookie": 'fid=18743; lv=1;_uid=236979880; UID=236979880;vc=137C52E726857E8F909BE63816932583;xxtenc=ddbc37dc960f59c4e4d80e7d212577c5; uf=b2d2c93beefa90dc62d0140d27586032be363a80c34379c8d55b182f4be7c0cdea1bb3571a26a1eb6edce3182980a667273683571faa0dcd88b83130e7eb4704a07401fce4235b32ce915f659a7402a8eea6be31981211d2c73072b75b8ec48b996adb45563782ea; _d=1711287844321; vc2=64BBB1352F74F266EA1110742827E42B; vc3=DiLAK%2FjtrTE2cmk6mArbULln8pJr%2BfA3UDzlOrNN%2Fc2cZAub5Cto8BI4SdxzMHme99F6R6DDq6cVxLPZnVXv6MDqnS25i82UVemY6g0PgxxV9Vn7197SiPLmlOAp5Nb0yPy9oPWrRoPHa95pUy91RReKj8RMqqF%2FVc5CKByXQ%2Bw%3Df84771ac7a8f04a131bbb08a9a5693f5; cx_p_token=2e9d9f80ee244828a78c88adb75b8286; p_auth_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1aWQiOiIyMzY5Nzk4ODAiLCJsb2dpblRpbWUiOjE3MTEyODc4NDQzMjMsImV4cCI6MTcxMTg5MjY0NH0.zbdW33Q-ypoJUryCOWOOy-aA1LrQC0ApZXT8gsCjJUY; DSSTASH_LOG=C_38-UN_755-US_236979880-T_1711287844323; tl=1; orgfid=31057; registerCode=00010013000100010034; createSiteSource=num9; source=num9; wfwEnc=7BE3D5CDD9642876BB1DCA0A31350E89; spaceFid=18743; spaceRoleId=''; k8s=1711633502.83.442.232697; route=2fe558bdb0a1aea656e6ca70ad0cad20; _industry=5; jrose=4FC9840C52C3D251E1C3A988291A2346.mooc2-387400510-8w2l6'# 这里省略了 Cookie 的部分内容
})
# 创建 img 文件夹
if not os.path.exists("img"):
os.makedirs("img")
# 下载所有图片
for idx, img_url in enumerate(result):
filename = f"img/image_{idx}.jpg" # 保存在 img 文件夹下
response = session.get(img_url)
if response.status_code == 200:
with open(filename, 'wb') as img_file:
img_file.write(response.content)
print(f"图片 {idx} 下载成功")
else:
print(f"图片 {idx} 下载失败,状态码:{response.status_code}")最终可以爬到56们课程图片,结果如下
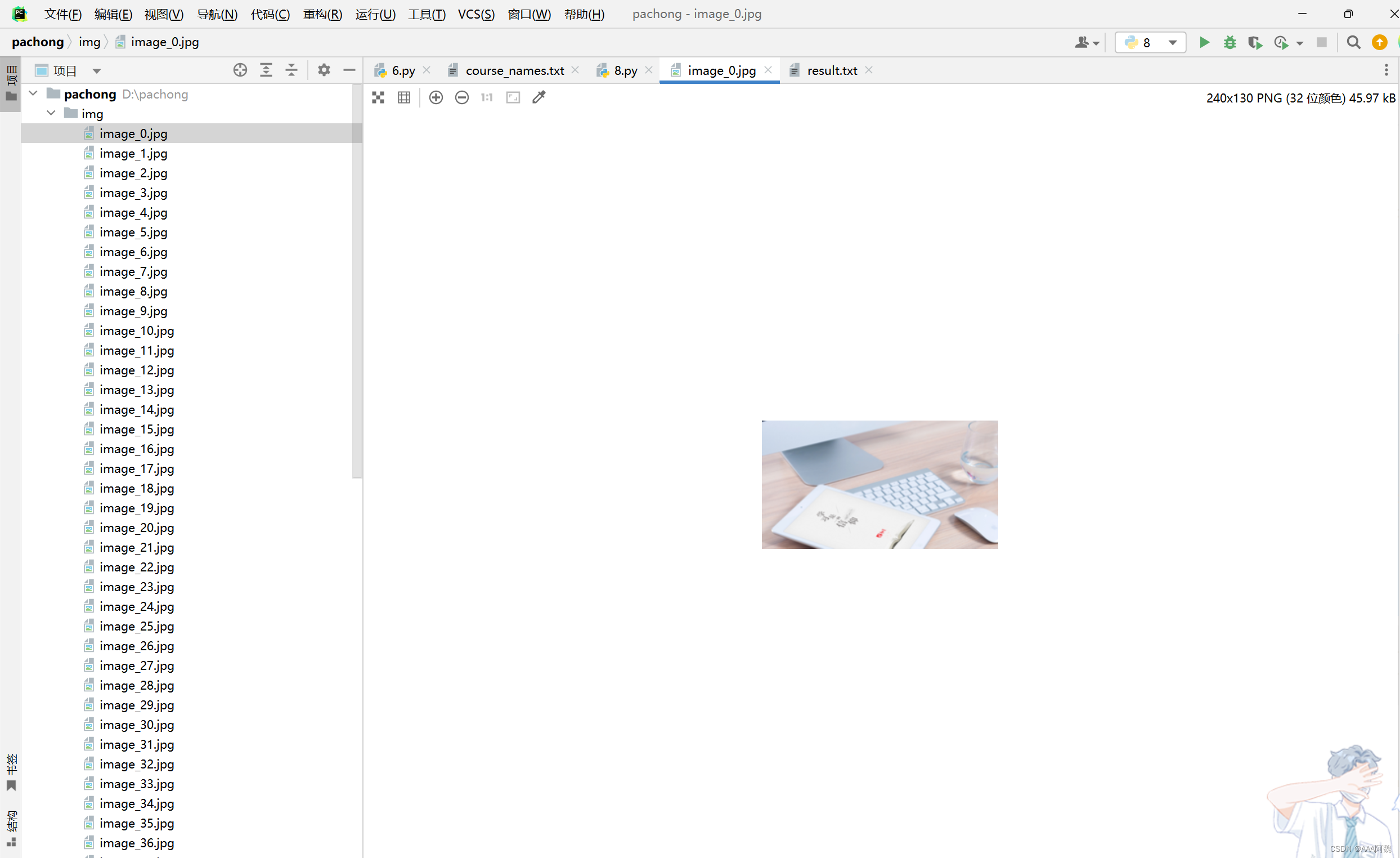
结束!