速通 数据挖掘课程
大的分类
标签预测(分类) 和 数值预测(预测呀)
监督 非监督 是否 需要预先训练模型 然后预测
聚类:拿一个比一个,看看相似否,然后归一类
数据四种类型
数据属性有四种:标称属性、序数属性、区间标度属性、比率标度属性
标称属性的值代表某种类别、编码或状态,不必具有有意义的序。二进制属性是一种特殊的标称属性,只有两个类别或状态(有对称的和非对称的)
序数属性具有有意义的序,但连续值之间的大小是未知的,例如学生的成绩可以分为优、良、中、差四个等级
区间标度属性用相等的单位尺度度量,值是有序的,比如日期和温度。区间标度属性不存在零点,倍数没有意义,比如我们不会说2000年是1000年的两倍。
比率标度属性是具有固定零点的数值属性,有序且可以计算倍数,如长度、重量。
分这个是为了:后面在看到不同类型的数据采用不同类型的方法
箱式图
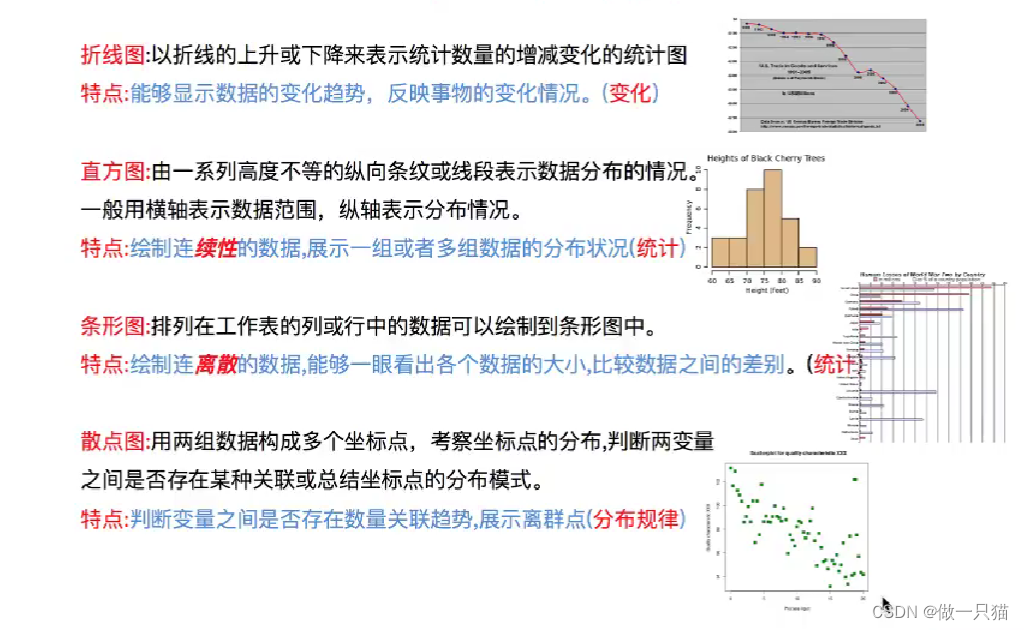
数据可视化
箱线图:分析多个属性数据的离散度差异性;
直方图:分析单个属性在各个区间的变化分布;
散点图:显示两组或多组数据的相关性分布。
相似度
相似度Similarity
- 度量两个数据对象有多相似
- 值越大就表示数据对象越相似
- 通常取值范围为 [0,1]
相异度Dissimillarity
- 度量两个数据对象的差别程度
- 值越小就表示数据越相似
- 最小相异度通常为0
邻近性Proximity
- 指相似度或者相异度
非对称的数据
只考虑那些生病的
相似性 聚类 推荐
user-images\1640413985821.png)
上确界距离是指每个属性数据差值绝对值的最大值
标称属性:相异度=(属性总数-匹配次数)/属性总数;
二进制属性:根据邻接表计算(非对称:相似度=杰卡德系数);
区间:闵可夫斯基距离(h=1,曼哈顿距离,h=2,欧氏距离,h=3,上确界距离)
处理方法
丢失数据:忽略元组、手动填写遗漏值、自动填写
噪声数据:利用盒状图检测离群数据删除离群点
不一致数据:计算推理、替换
空缺值:代码实现
卡方测试(用来看两个离散数据特征相关性大不大的)
列一下,联列表,然后 450*300/1500=90
90就是期望
最后,观测值和期望代入,算出来这个值越大,说明这两个特征相关性越大。
连续属性的相关性评测
注意:模式集成、实体识别、数据冲突检测
关于数据冗余,使用相关性来解决
离散型数据:卡方测试
连续性数据:皮尔逊相关系数、协方差
降维

数据规约方法类似数据集的压缩,它通过维度的减少或者数据量的减少,来达到降低数据规模的目的,数据压缩(Data Compression)有无损与有损压缩。方法主要是下面两种:
维度规约(Dimensionality Reduction):减少所需自变量的个数。代表方法为WT、PCA与FSS。
数量规约(Numerosity Reducton):用较小的数据表示形式替换原始数据。代表方法为对数线性回归、聚类、抽样等。
又可以从这个角度来看
数据复杂性较高:采用主成分分析法降维
时间开销大:采用有放回或无放回的简单随机抽样来降数据,降低时间开销
存储开销大:通过降低数据质量,来降低数据规模
数据转化
1.数据规范化:将数据按比例缩放到一个具体区间
方法:最小-最大规范化、Z-得分正常化、小数定标规范化
2.离散化:部分数据挖掘算法只适用于离散数据
方法:等宽法、等频法、聚类法
关联规则
sup conf
支持度(Support)。支持度表示项集{X,Y}在总项集里出现的概率。表示A和B同时在总数I中发生的概率。Support(X->Y) = P(X,Y) / P(I) = P(X∩Y) / P(I) = num(X∩Y) / num(I)。 置信度 (Confidence)。置信度表示在先决条件X发生的情况下,由关联规则”X→Y“推出Y的概率。表示在发生X的项集中,同时会发生Y的可能性,即X和Y同时发生的个数占仅仅X发生个数的比例。Confidence(X->Y) = P(Y|X) = P(X,Y) / P(X) = P(X∩Y) / P(X)。
基础算法
依据支持度找出所有频繁项集。 找出频繁一项集的集合,该集合记作L1。L1用于找频繁二项集的集合L2。如此下去,直到不能找到频繁K项集。找每个Lk都需要一次数据库扫描。核心思想是:连接步和剪枝步。连接步是自连接,原则是保证前k-2项相同,并按照字典顺序连接。剪枝步,由先验原理,如果某个候选的非空子集不是频繁的,那么该候选肯定不是频繁的,从而可以将其删除。依据置信度产生关联规则。对于每个频繁项集L,产生L的所有非空子集。对于L的每个非空子集S,如果P(L)/P(S)大于最小置信度,则生成规则L-S。
Apriori原理简介
如果一个项集是频繁的,则它的所有子集一定也是频繁的。相反,如果一个项集是非频繁的,则它所有的超集也是非频繁的。
此原理基于支持度的反单调性(anti-monotone):一个项集的支持度绝不会超过它的子集的支持度。
基于此原理,我们就能对项集进行 基于支持度的剪枝(support-based pruning),不用计算支持度就能删除掉某些非频繁项集。
于是便出现了基于先验原理的Apriori算法。
贝叶斯



逻辑斯特回归

正则化
是为了
让w别那么大,不然会让扰动变大
L1 会让w取值要么是1 要么是0 稀疏编码——适合降低纬度(很多都是0
L2 岭回归 概率意义
正则化理论就是用来对原始问题的最小化经验误差函数(损失函数)加上某种约束,这种约束可以看成是人为引入的某种先验知识(正则化参数等价于对参数引入先验分布),从而对原问题中参数的选择起到引导作用,因此缩小了解空间,也减小了噪声对结果的影响和求出错误解的可能,使得模型由多解变为更倾向其中一个解。
数值优化

熵

只能算离散的
求对数
开销大
所以 推出来 GINI指数(也是计算纯性的)





启发式算法
例如它常能发现很不错的解,但也没办法证明它不会得到较坏的解;它通常可在合理时间解出答案,但也没办法知道它是否每次都可以这样的速度求解
k-均值算法的基本原理是什么?
(1) K-means算法首先需要选择K个初始化聚类中心
(2) 计算每个数据对象到K个初始化聚类中心的距离,将数据对象分到距离聚类中心最近的那个数据集中,当所有数据对象都划分以后,就形成了K个数据集(即K个簇)
(3)接下来重新计算每个簇的数据对象的均值,将均值作为新的聚类中心
(4)最后计算每个数据对象到新的K个初始化聚类中心的距离,重新划分
(5)每次划分以后,都需要重新计算初始化聚类中心,一直重复这个过程,直到所有的数据对象无法更新到其他的数据集中。

优点:1)原理简单,收敛速度快;2)只需要调整k这一个参数;3)算法的原理简单,可解释性好
缺点:1)离群点和噪音点敏感;2)难确定k值;3)类别距离近k-means的效果不太好;4)初始值对结果影响较大,可能每次聚类结果都不一样;5)结果可能只是局部最优而不是全局最优。
选K
1、把样本的二维、三维散点图画出来,观察一下样本的分布,然后再决定k的值。如果维度大于三维,可以使用PCA降维到三维。
2、使用轮廓系数(Sihouette Coefficient)判断。
肘部法:肘部法所使用的聚类评价指标为:数据集中所有样本点到其簇中心的距离之和的平方。但是肘部法选择的并不是误差平方和最小的k,而是误差平方和突然变小时对应的k值。
轮廓系数法:轮廓系数是一种非常常用的聚类效果评价指标。该指标结合了内聚度和分离度两个因素。