MLLM引导的图像编辑技术报告
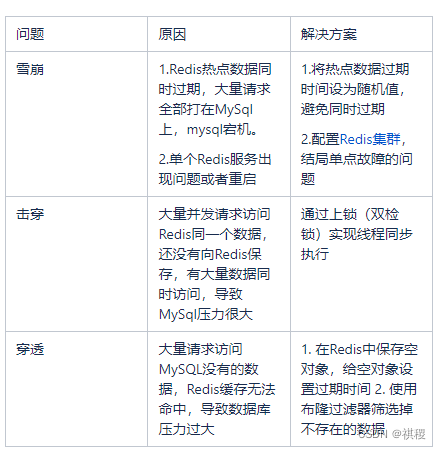
引言
随着视觉设计工具和视觉语言模型的广泛应用,多媒体行业对它们的需求日益增长。为了提高可访问性和控制性,多媒体行业越来越多地采用基于文本或指令的图像编辑技术。这些技术使用自然语言命令,而不是传统的区域掩码或详细描述,使得图像操作更加灵活和可控。然而,基于指令的方法通常提供简短的指导,可能对现有模型来说难以完全捕捉和执行。此外,扩散模型,以其能够创建逼真图像的能力,在图像编辑领域需求量很大。
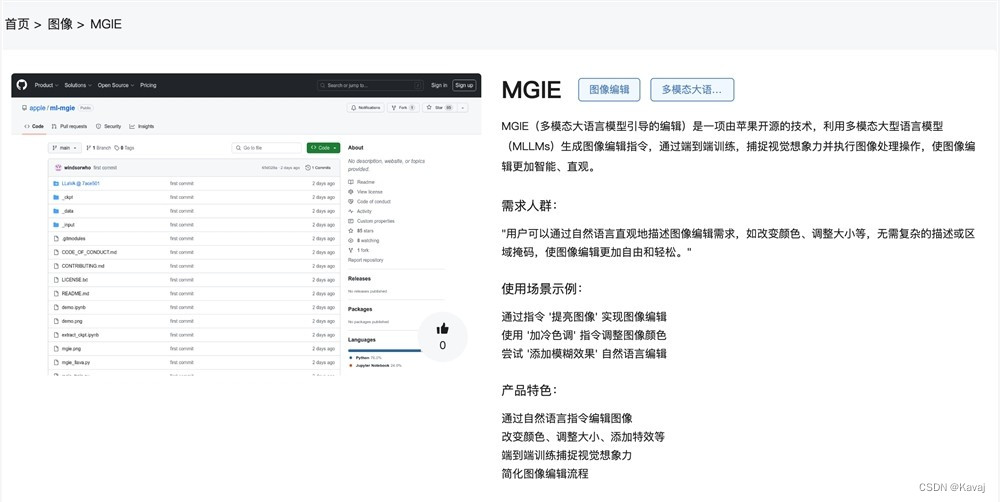
MLLM引导的图像编辑(MGIE)
MLLM和扩散模型
扩散模型通过交换潜在的多模态映射来执行视觉操作,反映输入目标字幕的更改,并可以使用引导掩码来编辑图像的特定区域。而大型语言模型(LLM)在文本摘要、机器翻译、文本生成和回答问题等多样化语言任务中取得了显著进展。基于LLM,多模态大型语言模型(MLLM)可以使用图像作为自然输入并提供适当的视觉感知响应。
MGIE架构和方法
MGIE框架包含一个扩散模型和一个MLLM模型。扩散模型通过端到端训练来执行图像编辑,而MLLM框架学习预测精确的表达性指令。MGIE框架利用固有的视觉推导来处理模糊的人类命令,从而实现逼真的图像编辑。
简洁表达指令
MGIE框架使用文本提示作为主要语言输入,并从图像中提取详细说明。然后,它使用预训练的摘要器来获得简洁的叙述,并将简洁而明确的指导视为表达性指令。
基于潜在想象的图像编辑
MGIE框架采用编辑头将图像指令转换为实际的视觉指导。编辑头是一个序列到序列模型,它帮助将来自MLLM的顺序视觉令牌映射到有意义的潜在语义作为其编辑指导。
MGIE的学习
MGIE框架使用IPr2Pr数据集作为其主要的预训练数据,包含超过100万CLIP过滤的数据,其中包含从GPT-3模型中提取的指令,以及一个Prompt-to-Prompt模型来合成图像。
MGIE结果和评估
MGIE框架在Photoshop风格修改和局部优化方面表现出色,因为它可以学习领域相关的指导,使扩散模型能够展示出具体的编辑场景。此外,由于视觉感知指导与预期的编辑目标更加一致,MGIE框架在性能上持续优于LGIE。
结论
MGIE或MLLM引导的图像编辑是一个受MLLM启发的学习,旨在评估多模态大型语言模型,并分析它们如何通过文本或指导指令支持编辑,同时学习如何提供明确指导并推导表达性指令。MGIE编辑模型捕捉视觉信息,并通过端到端训练执行编辑或操作。与模糊和简短的指导相比,MGIE框架产生明确的视觉感知指令,从而实现合理的图像编辑。