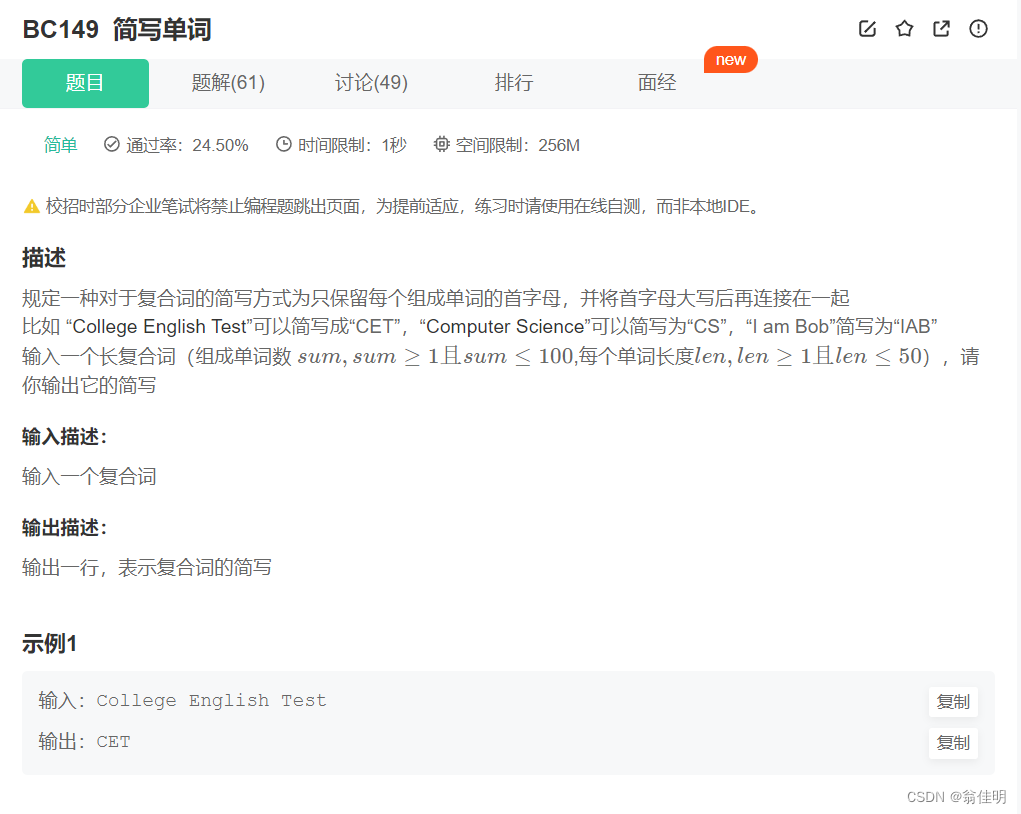
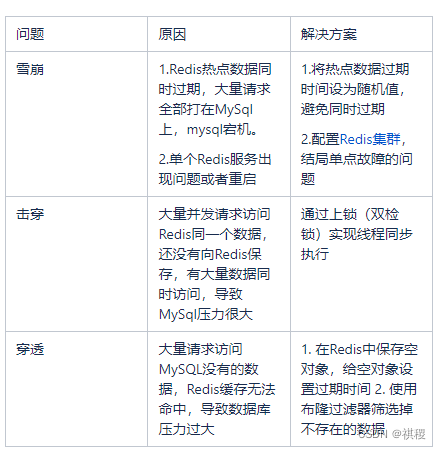
题解 {5556. 牛的语言学}
@LINK: https://www.acwing.com/problem/content/description/5559/;
这题很有意思… 考察你对记忆化DFS的理解;
看一个错误做法: 对于[长度>4] [长度为2/3] [长度>1] 那么中间这个就是答案;
这是错误的, 因为你忽略了一个限制(不可以有两个连续相同的后缀), 即[长度>5] aa aa这是不允许的;
正解是: 记忆化DFS; 即dfs( ind, preStr) 表示ind的前面 已经有一个preStr的后缀, 对于进行记忆化 ind=1e4, preStr=30^3 ;
即便如此, 此时再看一个错误做法:
vector<string> Cur;
unordered_set<int> DP;
void Dfs( int _ind, int _preStr){
int curDP = _ind * 27000 + _preStr;
if( DP.find( curDP) != DP.end()){ return;}
DP.insert( curDP);
if( _ind == N){
for( auto & i : Cur){
ANS.insert( i);
}
return;
}
FOR_( len, 2, 3){
if( _ind + len <= N){
auto cur = S.substr(_ind, len);
auto id = Hash( cur);
if( id != _preStr){
Cur.push_back( cur);
Dfs( _ind + len, id);
Cur.pop_back();
}
}
}
}
Dfs( 5|6|7|..., -1);
即 Cur存的是 你当前的路径状态, 比如[aaaaa] [ab] [xyz] [aa] ..., 当你到达终点时 即Dfs( N, ?)时, 此时 才把ab,xyz,aa,...这些后缀 他们在Cur里面, 把他们都放进ANS里面;
. 如果不使用记忆化, 这个做法是正确的 只不过会超时, 因为你每次都在遍历所有的路径方案;
可是 当你使用记忆化, 此时你会把(令...的开头下标为i) 对于当前这个方案 你会把DP( i, "aa")放到记忆化里面, 这会导致 当你随后遍历一个新的方案[aaaaa] [abx] [yz] [aa] ...时 他也是进入Dfs( i, "aa")这个状态 而他是记忆化了的, 因此 你认为这个路径已经得到过了 也就是abx,yz这两新后缀 不会放入答案里, 这就出错了;
你的记忆化没有错, 关键是 你更新答案的方式 即通过Cur(只有到达了终点 得到整个路径时) 才去更新答案 这种方式 是错误的, 因为即使遇到相同状态Dfs( ind, preStr) 你此时前面的状态 是不同的, 而你没有把前面的状态 放入答案里面;
因此 正确做法是: 不要使用Cur来记录当前路径方案;
即把Dfs(ind, preStr)的返回值 设置为bool, 表示"preStr" [ind,...] 是否可以到达终点 即[ind,...]是否可以是合法的; 然后当进行bool ret = Dfs( _ind+len, id)后, 根据返回值ret 来判断是否把cur放到答案里 (以前是 到了终点再放入, 现在才是真正的记忆化 不是遍历整个路径后才更新 而是在此时就更新答案);
此时再看一个错误做法:
unordered_map<int,bool> DP;
bool Dfs( int _ind, int _preStr){
int curDP = _ind * 27000 + _preStr;
if( DP.find( curDP) != DP.end()){ return DP[curDP];}
if( _ind == N){ return DP[curDP] = 1;}
DP[curDP] = 0;
FOR_( len, 2, 3){
if( _ind + len <= N){
auto cur = S.substr(_ind, len);
auto id = Hash( cur);
if( id != _preStr){
if( Dfs( _ind + len, id)){
DP[curDP] = 1;
ANS.insert( cur);
}
}
}
}
Dfs( _ind+1, -1);
return DP[curDP];
}
Dfs( 5, -1);
错误在于: Dfs( _ind+1, -1)这是错误的, 你想表示的是 不进行分割 即[>4] ...(枚举前面这个[>4]), 可是 假如此时已经分割了 [>4] [pre] ... 那么到了... 你就必须得分割后缀, 不可以不分割; 于是你认为那当preStr != -1时 才执行他, 这也是错误的, 因为这会导致 你Dfs函数 定义是有问题的, 你函数的定义 就是... [preStr] [ind...]是否有解, 也就是[ind...]必须要分割后缀, 而你的Dfs(_ind+1,-1)是不分割后缀的, 因此 总之就是错误的, 正确做法是: 把他去掉, 在外部枚举起点 即Dfs( 5|6|7|..., -1);
正确做法:
set<string> ANS;
int Hash( string _s){
int ans = 0;
for( auto i : _s){
ans *= 30;
ans += (i - 'a' + 1);
}
return ans;
}
unordered_map<int,bool> DP;
bool Dfs( int _ind, int _preStr){
int curDP = _ind * 27000 + _preStr;
if( DP.find( curDP) != DP.end()){ return DP[curDP];}
if( _ind == N){ return DP[curDP] = 1;}
DP[curDP] = 0;
FOR_( len, 2, 3){
if( _ind + len <= N){
auto cur = S.substr(_ind, len);
auto id = Hash( cur);
if( id != _preStr){
if( Dfs( _ind + len, id)){
DP[curDP] = 1; // 注意这里, 他很重要
ANS.insert( cur);
}
}
}
}
return DP[curDP];
}
Dfs( 5|6|7|..., -1);