论文:https://arxiv.org/ftp/arxiv/papers/2403/2403.00953.pdf
代码:https://github.com/windszzlang/AutoRD
提出背景
AutoRD 是一个先进的系统,它利用最新的人工智能技术,特别是大型语言模型(LLM),来自动识别和整理有关罕见疾病的信息。
这种信息通常散布在大量的医学文献和临床报告中,而AutoRD能够高效地从这些文本中提取关键信息,并构建出一个结构化的知识图谱。
这个知识图谱不仅包含了罕见疾病的名称和特征,还涵盖了疾病之间的关系、症状、可能的治疗方法等多方面的信息。
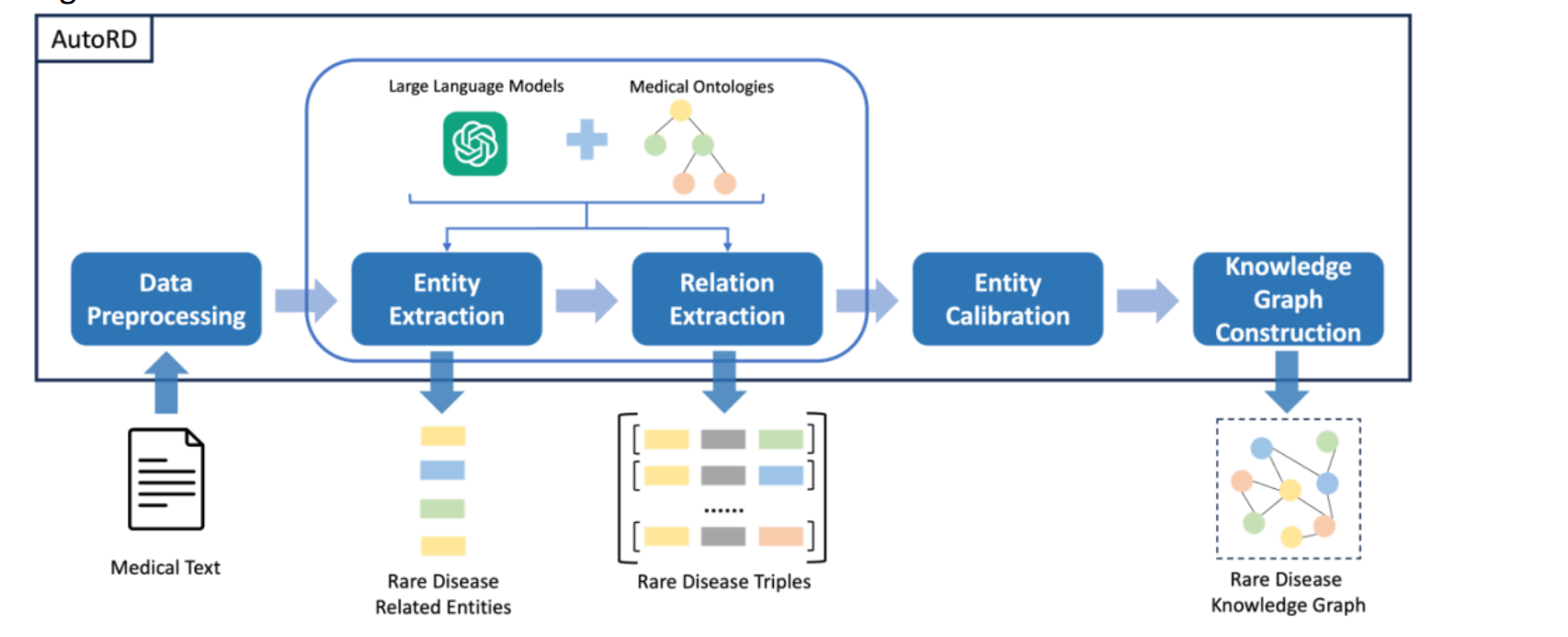
在技术层面,AutoRD的工作流程可以分为几个主要步骤:
- 数据预处理:将收集到的文本数据转换成适合处理的格式,去除无关信息。
- 实体提取:从文本中识别出重要的信息实体,如疾病名称、症状等。
- 关系提取:确定这些实体之间的关系,例如哪些症状是某一疾病的标志。
- 实体校准:确保提取的信息与现有医学知识一致,消除歧义。
- 知识图谱构建:将提取和校准后的信息组织成一个网络,其中节点代表实体,边代表实体间的关系。
通过将大型语言模型与医学本体(一种形式化的知识表示方法)结合使用,AutoRD不仅能提高信息提取的准确性,还能理解和应用医学领域的专业知识,从而在构建知识图谱时实现更高的精确度和可靠性。
在评估AutoRD的性能时,使用了F1得分这一统计量来衡量其准确性,其中包括对实体提取和关系提取的评估。
结果显示,AutoRD在整体上显著超过了基础的大型语言模型,特别是在罕见疾病实体的识别上表现优异。
AutoRD代表了在罕见疾病研究和诊断领域应用人工智能的一大步进。它不仅提高了从大量文本中提取和整理信息的效率,还为医生和研究人员提供了一个强大的工具,以更深入地理解罕见疾病,从而促进更有效的治疗方法的发现和疾病的管理。
在AutoRD(自动化罕见疾病挖掘)系统的研究和开发过程中,我们针对的主要问题是如何从医学文本中自动提取关于罕见疾病的信息,并构建相应的知识图谱。
为了解决这一问题,我们采用了一系列具体的子解法,每个子解法都针对问题的特定特征进行设计。
集成医学本体:为了提高LLMs在医学领域的理解能力,我们集成了三个医学本体:Orphanet罕见疾病本体(ORDO)、HPO-ORDO本体模块(HOOM)和Mondo疾病本体(Mondo)。
之所以采用这个子解法,是因为医学本体提供了丰富的医学知识和术语体系,有助于提高实体和关系提取的准确性和一致性。
数据重处理和修订:使用RareDis-v1数据集进行实体和关系提取能力的评估之前,我们对该数据集进行了重新处理,包括手工复查和修订注释错误,然后重新洗牌。我们将这个新的数据集命名为RareDis2023。
之所以采用这个子解法,是因为数据质量直接影响提取结果的准确性和可靠性,通过优化和校正数据集,可以为实验提供更坚实的基础。
构建AutoRD框架:AutoRD系统设计为自动从医学文本中提取罕见疾病信息并创建知识图谱,包括数据预处理、实体提取、关系提取、实体校准和知识图谱构建等步骤。
之所以采用这个子解法,是因为系统化的流程可以高效地处理大量文本,同时确保从文本提取到知识图谱构建的每一步都经过优化,保证信息提取和整理的准确性和效率。
定义任务和实体类型:在AutoRD中,给定医学文本T,首先提取实体E={E1, E2, …, En}和关系R={R1, R2, …, R},然后基于E和R输出知识图谱KG。实体类型包括’罕见疾病’、‘疾病’、‘症状和体征’以及’代词’。
之所以采用这个子解法,是因为定义清晰的任务和实体类型有助于指导系统精确地识别和分类文本中的关键信息,为后续的关系提取和知识图谱构建奠定基础。
通过综合应用这些子解法,AutoRD系统能够有效地从医学文本中自动提取罕见疾病的相关信息,并构建出详细的知识图谱,从而支持罕见疾病的研究和管理。
提取类别
AutoRD系统中提取的信息,描述了系统如何从医学文本中识别和理解不同的信息类型。
在医学文本分析中,"实体"是指特定的信息片段,例如疾病名称、症状等。
以下是这些实体的定义和例子:
- 罕见疾病(rare_disease):指影响人数相对较少的疾病,例如影响全球不到1/2000的疾病。
- 疾病(disease):指任何身体部位、器官或系统的不正常状况,如感染、炎症导致的疾病。
- 症状和体征(symptom_and_sign):指可能提示某种疾病或医学状况的身体表现,如疼痛、疲劳、异常心率等。
- 指代词(anaphor):在文本中指代已经提及的罕见疾病的词语或短语,比如用"这种疾病"来代替前文提到的具体疾病名称。
在知识图谱中,这些关系帮助表达不同实体间的联系。
以下是这些关系的定义:
- 产生(produces):指一个疾病产生的症状或体征。
- 增加风险(increases_risk_of):指一个疾病存在时,它会增加患上另一种疾病或状况的风险。
- 是一个(is_a):指将一个特定疾病归类为更广泛的疾病类别。
- 首字母缩写(is_acron):指一个缩写词和它的全称或扩展形式之间的关系。
- 同义词(is_synon):指两个不同的词实际上指的是同一个疾病。
- 前指(anaphora):指文本中一个代词指回前文提到的罕见疾病实体。
通过这样的信息提取和关系识别,AutoRD能够构建出一个结构化的知识图谱,这对于罕见疾病的研究和治病非常有帮助。
假设我们有一篇关于某种罕见疾病的医学文本。
这篇文本可能提到了一种名为“Xyz症候群”的疾病,这是一种影响人体免疫系统的罕见疾病。
文本中还提到了与该症候群相关的症状,比如“持续疲劳”和“关节疼痛”,以及这种症候群可能会增加患上其他疾病的风险。
在这个例子中,AutoRD系统将执行以下任务:
数据预处理:将文本清理和格式化,为提取准备。
实体提取:
- 识别“Xyz症候群”作为 rare_disease 实体。
- 识别“持续疲劳”和“关节疼痛”作为 symptom_and_sign 实体。
关系提取:
- 识别“Xyz症候群”与“持续疲劳”和“关节疼痛”之间的 produces 关系。
- 如果文本提到Xyz症候群增加患某心血管疾病的风险,将识别Xyz症候群与该心血管疾病之间的 increases_risk_of 关系。
实体校准:确保所有识别的实体与医学本体中的定义一致。
知识图谱构建:
- 在知识图谱中创建节点,表示“Xyz症候群”以及“持续疲劳”和“关节疼痛”。
- 在节点间创建边,表示不同实体之间的关系,如“Xyz症候群”产生“持续疲劳”和“关节疼痛”。
最终,AutoRD系统利用这些提取的实体和关系构建一个知识图谱,这个知识图谱不仅展现了“Xyz症候群”本身的信息,还展示了它与其他症状和疾病的联系,为医疗专业人员提供了宝贵的信息资源。
数据预处理
为了处理AutoRD系统中的数据,我们采用了一系列的子解法来进行数据预处理,这是因为我们使用的GPT-4语言模型有一定的令牌限制。
分段处理长文本:
- 子解法:将超过2000令牌的长文本文档分割成小段,以适应GPT-4的8000令牌限制。
- 特征:长文本需要被分割以免超过模型的令牌限制,这样可以在不牺牲信息的前提下进行有效处理。
自然段落分割:
- 子解法:在自然段落边界处分割文档,确保每个段落包含少于2000令牌。
- 特征:实体关系通常出现在单个自然段落内,分割在段落边界可减少跨段落实体关系的遗漏。
重复提取关系:
- 子解法:对于被分割的段落,重新从中间部分提取关系,以识别新的关系。
- 特征:分割文本可能会切断实体之间的关系,重复提取可以确保关系的完整性。
处理本体文件:
- 子解法:从官方网站下载的本体文件中提取医学知识数据,如罕见疾病的名称和定义,疾病相关的术语,以及临床实体与表型异常之间的关系等。
- 特征:本体文件包含了丰富的医学知识,通过提取这些信息可以增强LLM的知识库。
数据集预处理和错误校正:
- 子解法:对RareDis数据集进行预处理,包括纠正注释错误,并按6:2:2的比例划分为训练集、验证集和测试集。
- 特征:原始数据集中存在一些错误,需要纠正以确保评估的准确性,并且分割数据集是为了进行模型训练和评估。
合并实体类型:
- 子解法:将原始数据集中的‘Symptom’和‘Sign’合并为一个实体类型‘symptom_and_sign’。
- 特征:在罕见疾病研究的背景下,症状和体征之间的区别不是特别关键,合并可以简化实体提取的任务。
通过上述子解法的应用,我们创建了新的预处理数据集RareDis2023,这样可以更有效地整合和利用医学知识,为罕见疾病信息提取和知识图谱构建奠定基础。
实体提取
在AutoRD系统中,面对的具体问题是如何从医学文本中有效提取出有关罕见疾病的详细信息。
提取医学术语(extract medical terms):这一步骤使用基于字符串匹配的算法和否定检测来识别文本中的基本医学术语。例如,文本提到"非典型肺炎",通过与Mondo医学本体中的术语匹配,我们能识别出这是一种疾病术语。之所以使用这个子解法,是因为识别这些基础术语是理解医学文本的第一步。
提取更多术语(extract more terms):接下来,利用大型语言模型进一步提取相关但可能在本体匹配中被遗漏的医学术语,包括其变体形式。例如,如果文本中提到“气短”,这个词可能没有直接匹配到本体术语,但LLM能够识别它作为“呼吸困难”的同义词。之所以使用这个子解法,是因为它可以扩大我们的术语数据库,包括那些变体和相关术语。
提取实体(extract entities):最后,使用大型语言模型根据上一步提取的术语和指代词(anaphors)识别和分类具体的实体。例如,LLM可能会识别出“非典型肺炎”(已知为一种罕见疾病)和“气短”(症状),并将它们正确分类。之所以使用这个子解法,是因为它是完成实体提取的关键步骤,使我们能够清晰地了解文本中提到的每个医学实体及其类别。
在整个实体提取过程中,我们还采用了链式思考(CoT)和上下文学习(ICL)的概念。这些方法通过分步解释和使用示例来增强LLM的性能。例如,我们可能给LLM提供一个示例:如果文本中提到“Smith病”,并且已知“Smith病”是一种罕见疾病,那么LLM将学会如何识别并以适当的格式输出这一信息。
这三个子解法结合起来,为AutoRD提供了一个强大的框架,用于有效地从医学文本中提取实体信息,并将这些信息整合到知识图谱中。
通过这种方式,我们不仅提高了实体提取的准确性,还提高了处理复杂医学文本的效率。
关系抽取
在我们的方法中,关系提取是在实体提取之后进行的。
所有识别出的实体都被输入到大型语言模型(LLM)中,然后输出提取的关系。
这一过程的逻辑与实体提取类似。
在提示中,我们首先提供当前任务的概述,并为实体和关系类型建立清晰的定义。
我们还包括了额外的考虑因素,供LLM在提取关系时考虑。
最后,我们定义了LLM的输出格式,该格式被设计为易于以JSON格式解析。
对于罕见疾病知识的提取,我们利用HOOM,这是一个由罕见疾病-表型三元组组成的本体。
这个本体提供了与罕见疾病相关的症状和体征的信息。
我们使用罕见疾病作为关键词来构建一个字典,通过字符串匹配来识别相关的三元组。
这些外部的医学知识帮助LLM获取关于罕见疾病和特定表型之间现有关系的信息。
实体校准是我们的目标,旨在基于提取结果构建知识图谱。
我们认为许多实体可能没有与其他实体定义的关系。
此外,在分析提取结果之后,我们观察到没有任何关系的实体更有可能是不相关的或在上下文中错误地归为医学实体。
例如,系统在实体提取阶段识别出“障碍”这一术语。
然而,在关系提取中,系统未能检测到任何“指代”或其他关系,表明它只是一个通用术语,在这一上下文中可以被忽略。
在其他情况下,一些错误的症状和体征也被有效地消除。
因此,我们在关系提取之后引入了实体校准作为额外的步骤。
这项任务的提示模板可以在图2的右侧看到。
在这一步骤中,我们提供了从前几个步骤获得的所有结果,并使用LLM重新分析关系,过滤掉无关的实体。
通过结合实体和关系提取阶段的结果,我们获得了整个提取过程的综合成果。
在提取实体和关系之后,我们对数据进行后处理,为构建知识图谱做准备。
这包括对实体进行对齐,涉及到在知识图谱中合并相同的节点。
对于每个三元组,我们评估主体或客体是否相同。我们首先将名称转换为小写,然后确定它们是否匹配。
此外,我们将所有指代关系转换为它们的原始名称。
经过后处理,我们可以根据这些三元组轻松构建知识图谱。
具体来说,我们为此目的使用Neo4j。
Neo4j是一个高度灵活和可扩展的图形数据库,设计用来存储和处理复杂的数据网络。
它使得查询和管理互联信息变得高效。
使用Neo4j的API,我们逐一将罕见疾病三元组添加到图形数据库中。
结果,我们可以在Neo4j平台内可视化我们的罕见疾病知识图谱。
效果
在实体提取部分,AutoRD在罕见疾病的F1分数上达到了83.5%,而BioClinicalBERT(一种基于BERT的生物医学模型)的F1分数是83.9%,GPT-4是54.7%。
在关系提取方面,AutoRD在所有关系类型的整体F1分数上为37.1%,而BioClinicalBERT为21.4%,GPT-4则为5.8%。
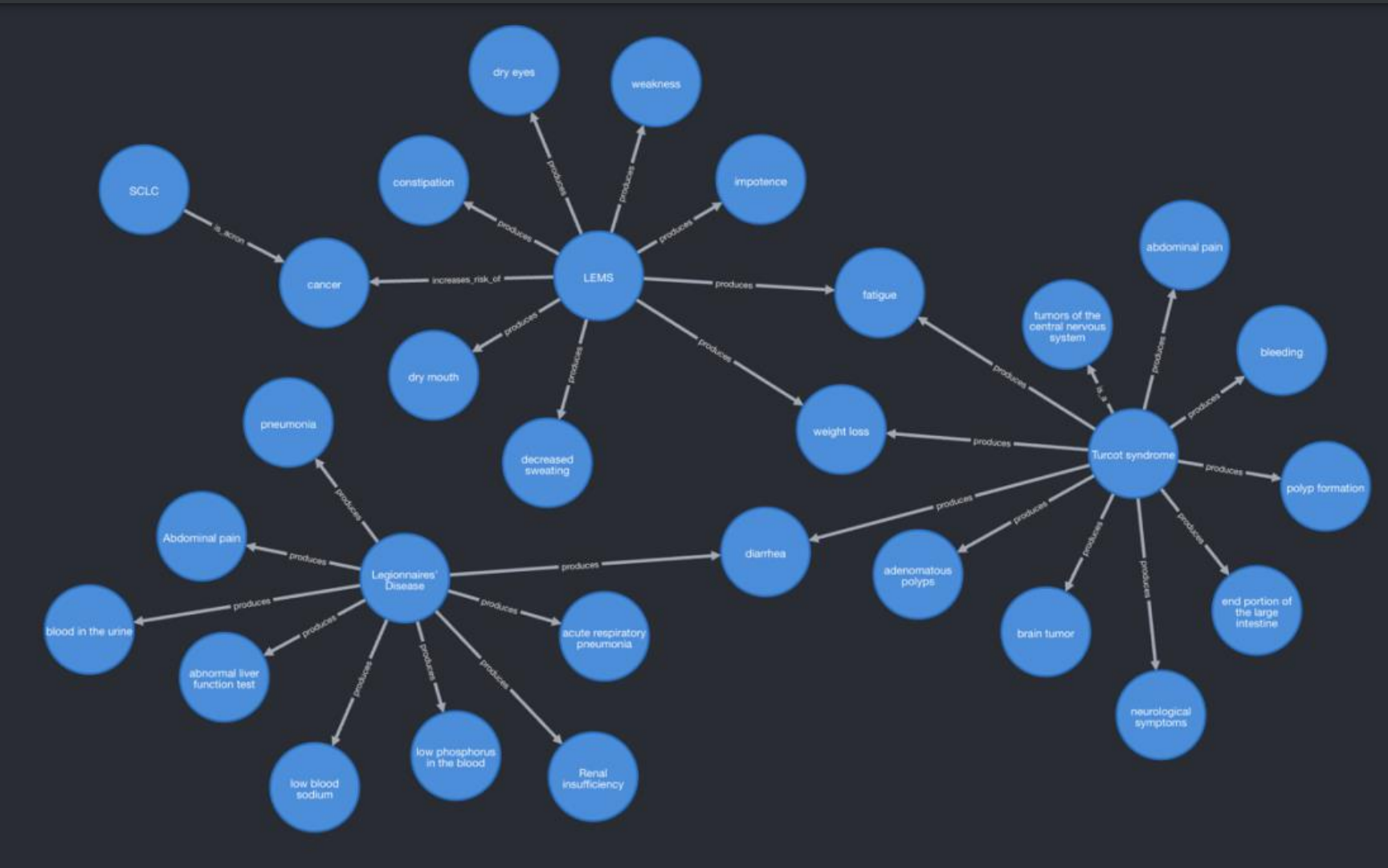
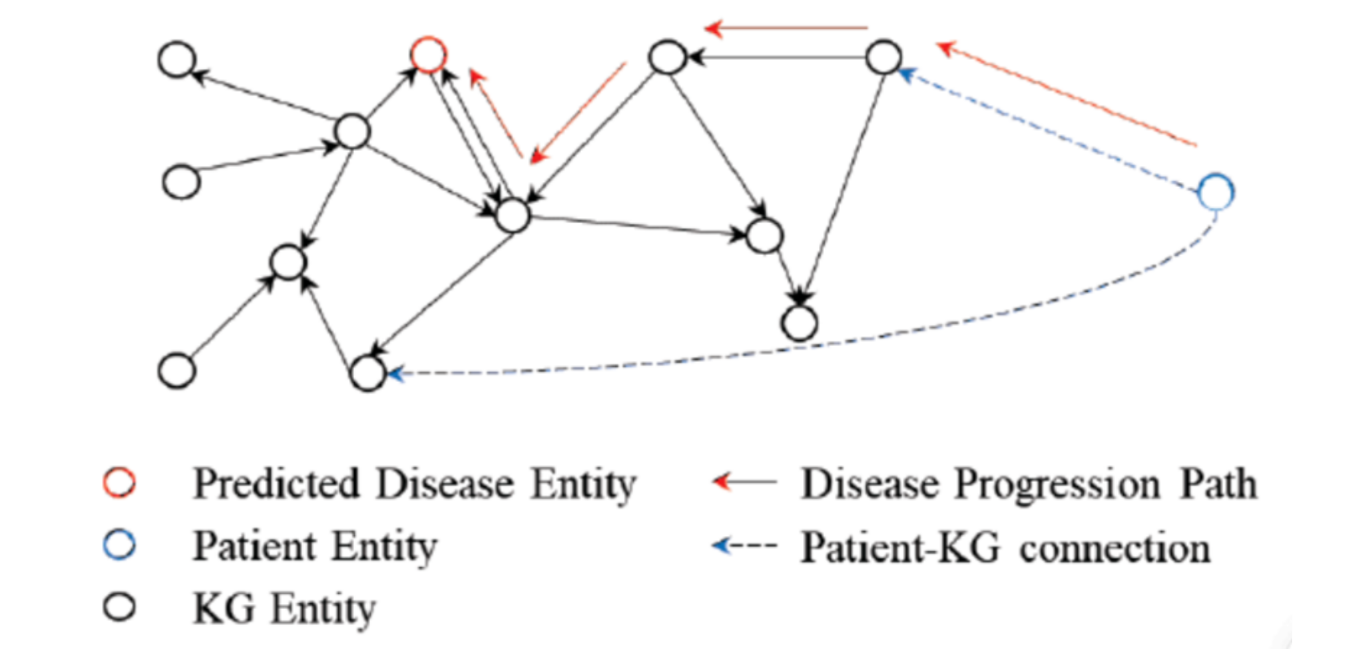
在这个视图中,不同的节点代表不同的医学实体,比如疾病和症状,而连线代表了这些实体之间的关系。
例如,中心的“Turcot综合征”是一种罕见疾病,它与多个症状(如“腹痛”、“出血”、“疲劳”等)直接相关。
其他节点表示其他医学条件或症状,它们通过边与中心的疾病节点相连,展现了它们之间的关系。