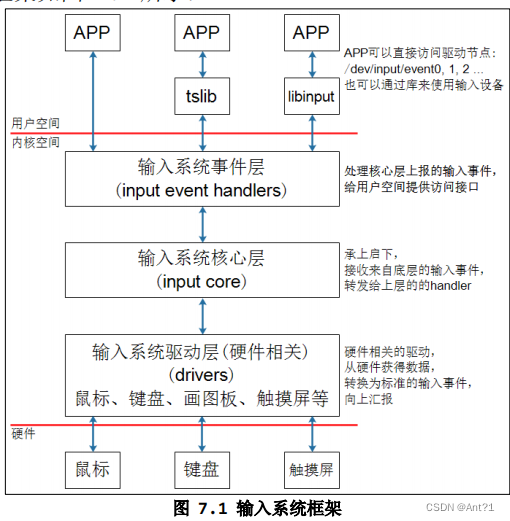
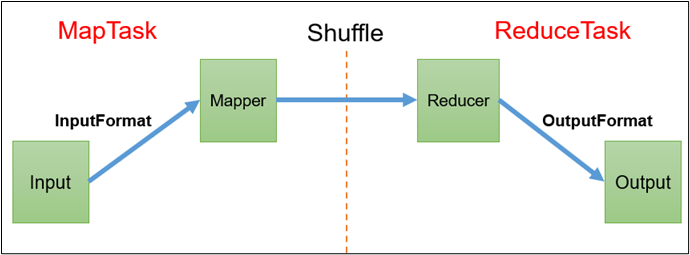
实现bean对象序列化步骤
自定义bean对象实现序列化接口。
1)必须实现Writable接口
2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
public FlowBean(){
super();
}3)重写序列化方法
@Override
public void write(DataOutput out) throws IOException{
out.writeLong(upFlow);
out.writeLong(downFlow);
out.wirteLong(sumFlow);
}4)重写反序列化方法
@override
public void readFields(DataInput in) throws IOException{
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}5)注意反序列化顺序和序列化顺序要完全一致
6)要想把结果显示在文件中,需要重写toString()方法,可用\t分开,方便后续使用
7)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的shuffle过程要求对key必须能排序
@Override
public int compareTo(FlowBean o){
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}代码案例(统计流量)
FlowBean
public class FlowBean implements Writable {
private long upFlow;
private long downFlow;
private long sumFlow;
public FlowBean() {
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public void setSumFlow() {
this.sumFlow = this.upFlow + this.downFlow;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.upFlow = dataInput.readLong();
this.downFlow = dataInput.readLong();
this.sumFlow = dataInput.readLong();
}
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow ;
}
}
FlowMapper
public class FlowMapper extends Mapper<LongWritable, Text,Text,FlowBean> {
private Text outK = new Text();
private FlowBean outV = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(" ");
String phone = split[1];
String upFlow = split[2];
String downFlow = split[3];
outK.set(phone);
outV.setUpFlow(Long.parseLong(upFlow));
outV.setDownFlow(Long.parseLong(downFlow));
// outV.setSumFlow(Long.parseLong(upFlow) + Long.parseLong(downFlow));
outV.setSumFlow();
context.write(outK,outV);
}
}
FlowReducer
public class FlowReducer extends Reducer<Text,FlowBean,Text,FlowBean> {
private FlowBean outV = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context) throws IOException, InterruptedException {
long totalUpFlow = 0;
long totalDownFlow = 0;
for (FlowBean value : values) {
totalUpFlow += value.getUpFlow();
totalDownFlow += value.getDownFlow();
}
outV.setUpFlow(totalUpFlow);
outV.setDownFlow(totalDownFlow);
outV.setSumFlow();
context.write(key,outV);
}
}
FlowDriver
public class FlowDriver{
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FlowDriver.class);
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
FileInputFormat.setInputPaths(job,new Path("Data/input/TestFlowBean"));
FileOutputFormat.setOutputPath(job,new Path("Data/output/TestFlow3"));
Boolean result = job.waitForCompletion(true);
System.exit(result ? 0:1);
}
}