当我们使用 Jupyter 时,很显然我们的主要目的是探索数据。这篇文章将介绍如何利用 JupySQL 来进行数据查询–甚至代替你正在使用的 Navicat, dbeaver 或者 pgAdmin。此外,我们还将介绍如何更敏捷地探索数据,相信这些工具,可以帮你省下 90%的 coding 时间。
原文发表在这里
JupySQL - 替换你的数据库查询工具
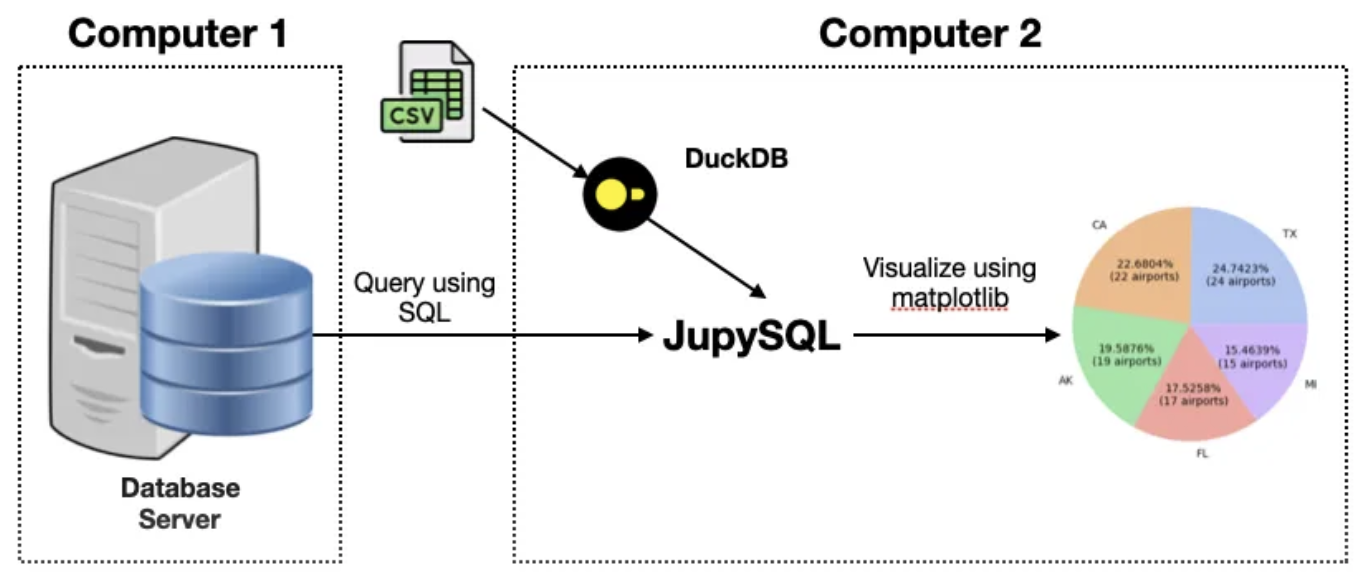
JupySQL 是一个运行在 Jupyter 中的 sql 查询工具。它支持传统关系型数据库(PostgreSQL, MySQL, SQL server)、列数据库(ClickHouse),数据仓库 (Snowflake, BigQuery, Redshift, etc) 和嵌入式数据库 (SQLite, DuckDB) 的查询。
之前我们不得不为每一种数据库寻找合适的查询工具,找到开源、免费又好用的其实并不容易。有一些工具,设置还比较复杂,比如像 Tabix,这是 ClickHouse 有一款开源查询工具,基于 web 界面的。尽管它看起来简单到甚至无须安装,但实际上这种新的概念,导致一开始会引起一定的认知困难。在有了 JupySQL 之后,我们就可以仅仅利用我们已知的概念,比如数据库连接串,SQL 语句来操作这一切。
除了查询支持之外,JupySQL 的另一特色,就是自带部分可视化功能。这对我们快速探索数据特性提供了方便。
安装 JupySQL
现在,打开一个 notebook,执行以下命令,安装 JupySQL:
%pip install jupysql duckdb-engine --quiet
之前你可能是这样使用 pip:
! pip install jupysql
在前一篇我们学习了 Jupyter 魔法之后,现在你知道了,%pip 是一个 line magic。
显然,JupySQL 要连接某种数据库,就必须有该数据库的驱动。接下来的例子要使用 DuckDB,所以,我们安装了 duckdb-engine。
!!! info
DuckDB 是一个性能极其强悍、有着现代 SQL 语法特色的嵌入式数据库。从测试上看,它可以轻松管理 500GB 以内的数据,并提供与任何商业数据库同样的性能。
在安装完成后,需要重启该 kernel。
JupySQL 是作为一个扩展出现的。要使用它,我们要先用 Jupyter 魔法把它加载进来,然后通过%sql 魔法来执行 sql 语句:
%load_ext sql
# 连接 DUCKDB。下面的连接串表明我们将使用内存数据库
%sql duckdb://
# 这一行的输出结果为 1,表明 JUPYSQL 正常工作了
%sql select 1
数据查询 (DDL 和 DML)
不过,我们来点有料的。我们从 baostock.com 上下载一个 A 股历史估值的示例文件。这个文件是 Excel 格式,我们使用 pandas 来将其读入为 DataFrame,然后进行查询:
import pandas as pd
df = pd.read_excel("/data/.common/valuation.xlsx")
%load_ext sql
# 创建一个内存数据库实例
%sql duckdb://
# 我们将这个 DATAFRAME 存入到 DUCKDB 中
%sql --persist df
现在,我们来看看,数据库里有哪些表,表里都有哪些字段:
# 列出数据库中有哪些表