数据集展示
| 7369 | SMITH | CLERK | 7902 | 1980/12/17 | 800 | 20 | |
| 7499 | ALLEN | SALESMAN | 7698 | 1981/2/20 | 1600 | 300 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981/2/22 | 1250 | 500 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981/4/2 | 2975 | 20 | |
| 7654 | MARTIN | SALESMAN | 7698 | 1981/9/28 | 1250 | 1400 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981/5/1 | 2850 | 30 | |
| 7782 | CLARK | MANAGER | 7839 | 1981/6/9 | 2450 | 10 | |
| 7788 | SCOTT | ANALYST | 7566 | 1987/4/19 | 3000 | 20 | |
| 7839 | KING | PRESIDENT | 1981/11/17 | 5000 | 10 | ||
| 7844 | TURNER | SALESMAN | 7698 | 1981/9/8 | 1500 | 0 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987/5/23 | 1100 | 20 | |
| 7900 | JAMES | CLERK | 7698 | 1981/12/3 | 950 | 30 | |
| 7902 | FORD | ANALYST | 7566 | 1981/12/3 | 3000 | 20 | |
| 7934 | MILLER | CLERK | 7782 | 1982/1/23 | 1300 | 10 |
建立三个hadoop编程类EmployeeSortMain、Employee、EmployeeSortMapper这三个类
对应的java代码如下
实例
EmployeeSortMain
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class EmployeeSortMain {
public static void main(String[] args) throws Exception{
//创建一个job
Job job = Job.getInstance(new Configuration());
job.setJarByClass(EmployeeSortMain.class);
//指定job的mapper和输出的类型 k2 v2
job.setMapperClass(EmployeeSortMapper.class);
job.setOutputKeyClass(Employee.class);
job.setMapOutputValueClass(NullWritable.class);
//指定job的输入和输出的路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//提交程序,并且监控打印程序执行的结果
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
Employee
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//1.若要把Employee作为key2,则需要实现序列化
//2.员工对象为Employee类,可被排序
//数据:7654,MARTIN ,SALESMAN,7698,1981/9/28,1250,1400,30
public class Employee implements WritableComparable<Employee> {
private int empno;
private String ename;
private String job;
private int mgr;
private String hiredate;
private int sal;
private int comm;
private int deptno;
@Override
public String toString(){
return "Employee[empno="+empno+",ename="+ename+",sal="+sal+",deptno="+deptno+"]";
}
@Override
public int compareTo(Employee o) {
//多个列的排序:select * from emp order by deptno,sal;
//首先按照deptno排序
if(this.deptno >o.getDeptno()){
return 1;
}else if(this.deptno < o.getDeptno()){
return -1;
}
//如果deptno相等,按照sal排序
if(this.sal >= o.getSal()){
return 1;
}else{
return -1;
}
}
@Override
public void write(DataOutput output) throws IOException {
//序列化
output.writeInt(this.empno);
output.writeUTF(this.ename);
output.writeUTF(this.job);
output.writeInt(this.mgr);
output.writeUTF(this.hiredate);
output.writeInt(this.sal);
output.writeInt(this.comm);
output.writeInt(this.deptno);
}
@Override
public void readFields(DataInput input) throws IOException {
//反序列化
this.empno = input.readInt();
this.ename = input.readUTF();
this.job = input.readUTF();
this.mgr = input.readInt();
this.hiredate = input.readUTF();
this.sal = input.readInt();
this.comm = input.readInt();
this.deptno = input.readInt();
}
public int getEmpno() {
return empno;
}
public void setEmpno(int empno) {
this.empno = empno;
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public String getJob() {
return job;
}
public void setJob(String job) {
this.job = job;
}
public int getMgr() {
return mgr;
}
public void setMgr(int mgr) {
this.mgr = mgr;
}
public String getHiredate() {
return hiredate;
}
public void setHiredate(String hiredate) {
this.hiredate = hiredate;
}
public int getSal() {
return sal;
}
public void setSal(int sal) {
this.sal = sal;
}
public int getComm() {
return comm;
}
public void setComm(int comm) {
this.comm = comm;
}
public int getDeptno() {
return deptno;
}
public void setDeptno(int deptno) {
this.deptno = deptno;
}
}
EmployeeSortMapper
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class EmployeeSortMapper extends Mapper<LongWritable,Text,Employee, NullWritable> {
@Override
protected void map(LongWritable key1, Text value1, Context context) throws IOException, InterruptedException {
//数据:7654,MARTIN ,SALESMAN,7698,1981/9/28,1250,1400,30
String data = value1.toString();
//分词
String[] words = data.split(",");
//创建员工对象
Employee e = new Employee();
//设置员工的属性
// 员工号
e.setEmpno(Integer.parseInt(words[0]));
//姓名
e.setEname(words[1]);
//职位
e.setJob(words[2]);
//老板号(注意:可能没有老板号)
try{
e.setMgr(Integer.parseInt(words[3]));
}catch (Exception ex){
//没有老板号
e.setMgr(-1);
}
//入职日期
e.setHiredate(words[4]);
//月薪
e.setSal(Integer.parseInt(words[5]));
//奖金(注意:奖金也有可能没有)
try{
e.setComm(Integer.parseInt(words[6]));
}catch (Exception ex){
//没有奖金
e.setComm(0);
}
//部门号
e.setDeptno(Integer.parseInt(words[7]));
//输出
context.write(e,NullWritable.get());
}
}
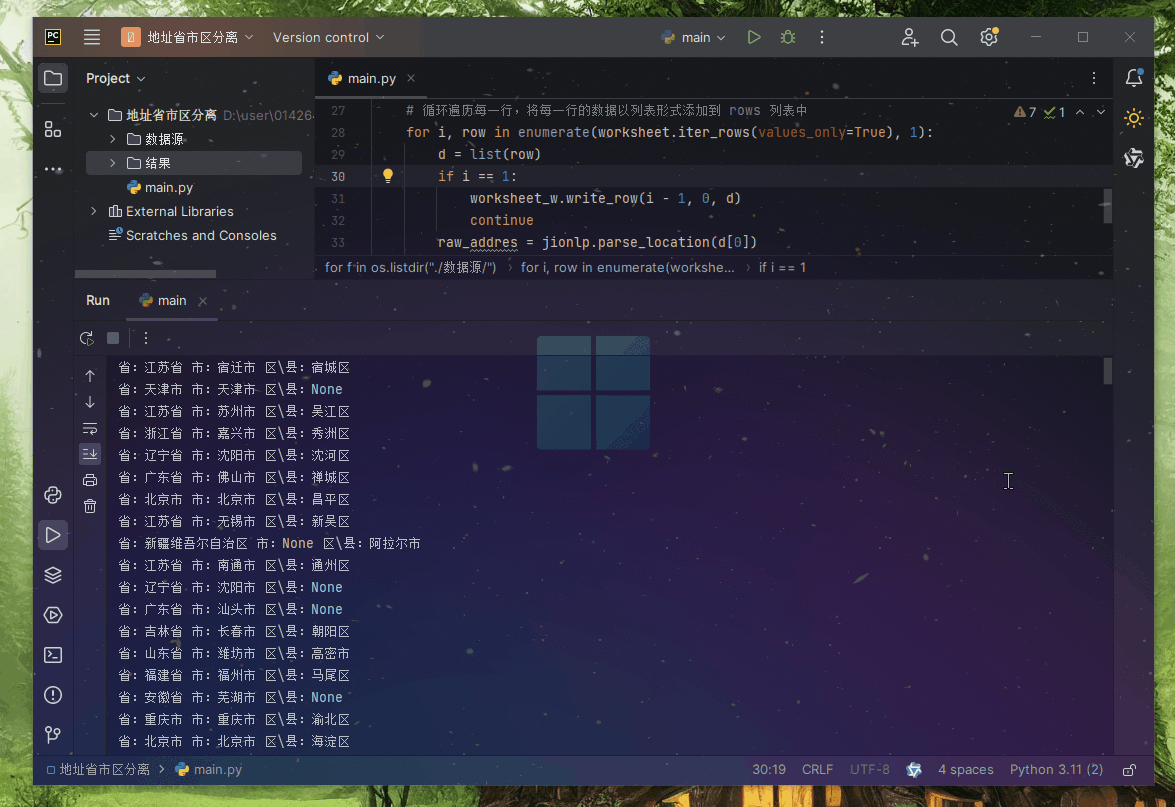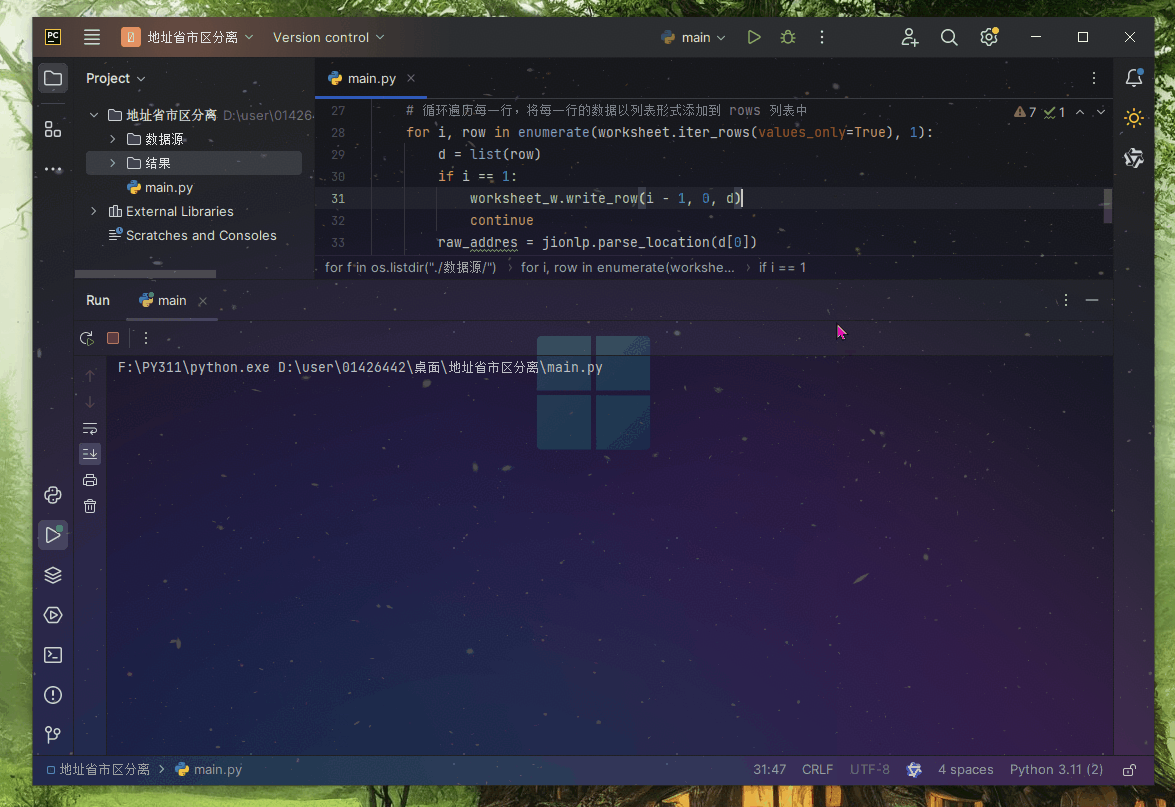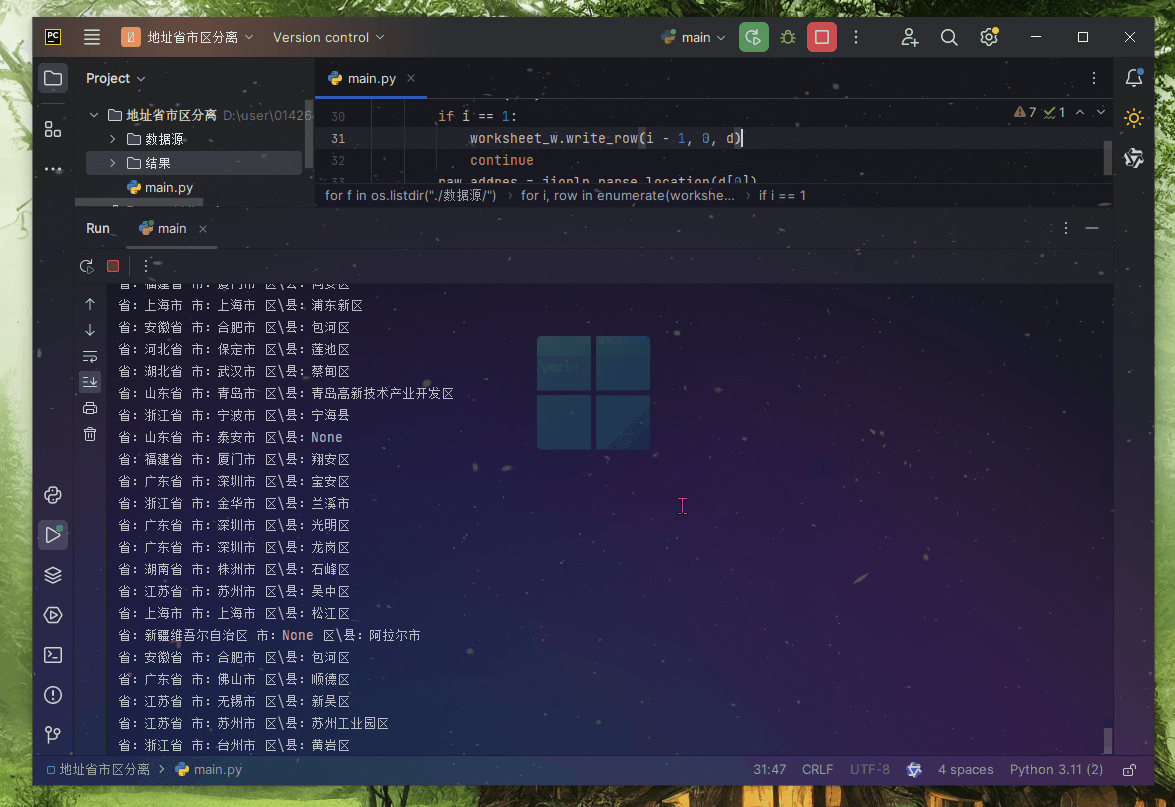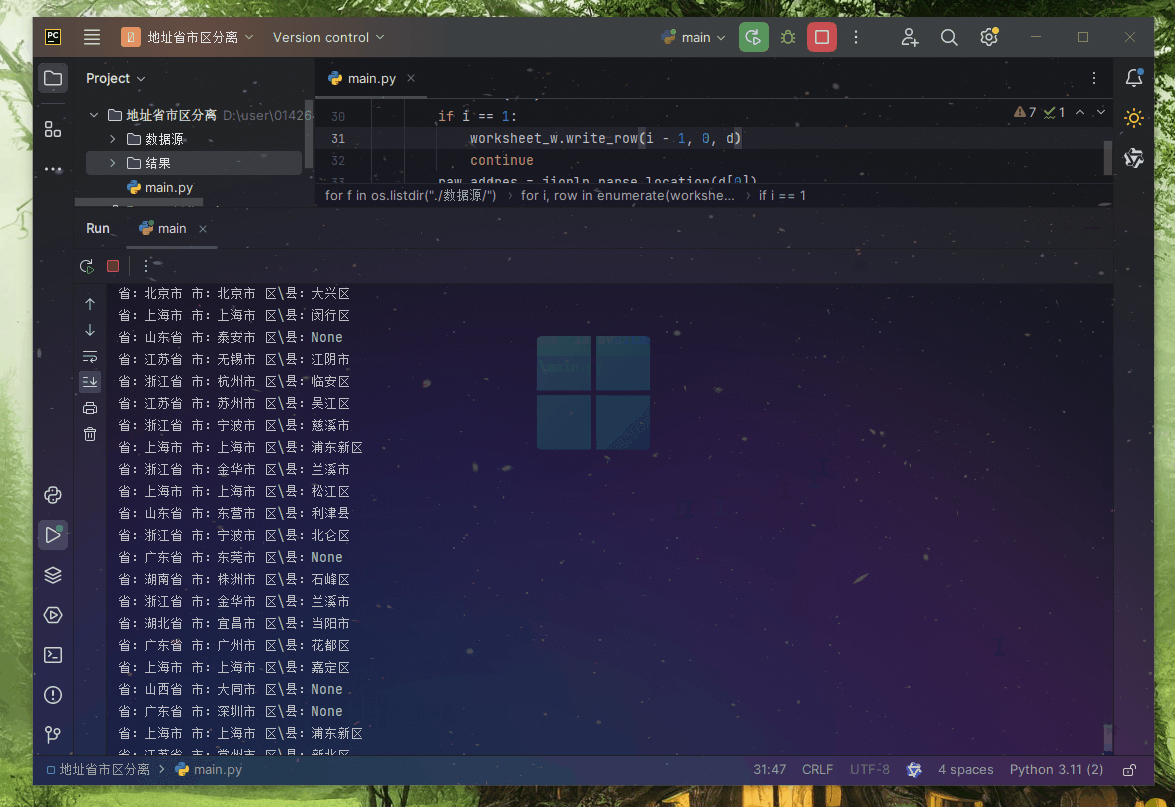
代码命令
hadoop jar 3.jar ch03.EmployeeSortMain /user/data/input/emp.csv /user/data/output/ch3
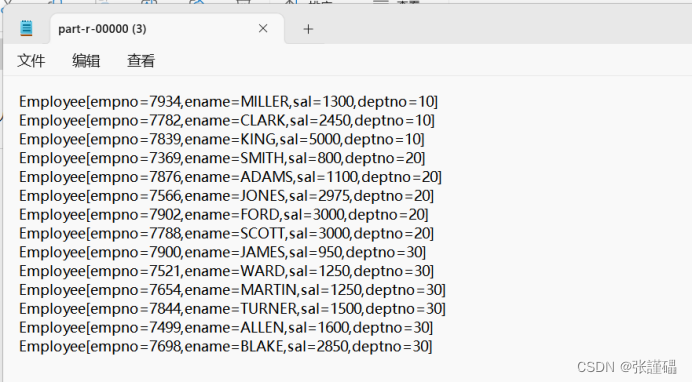
hadoop jar 包名 主类 输入路径 输出路径结果展示:

学习连接
利用mapreduce统计部门的最高工资_使用mapreduce查询某个部门中薪资最高的员工姓名,如果输出结果的格式为“薪资 员-CSDN博客
在Ubuntu上用mapreduce进行词频统计(伪分布式)_mapreduce怎么统计txt文件词频终端-CSDN博客