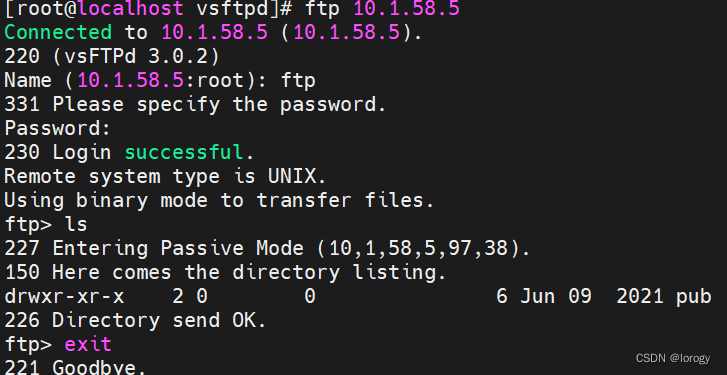
目录
ES数据预处理
Ingest Node
Elasticsearch 5.0后,引入的一种新的节点类型。默认配置下,每个节点都是Ingest Node:
1. 具有预处理数据的能力,可拦截lndex或 Bulk API的请求。
2. 对数据进行转换,并重新返回给Index或 Bulk APl。
无需Logstash,就可以进行数据的预处理,例如:
1. 为某个字段设置默认值。
2. 重命名某个字段的字段名。
3. 对字段值进行Split 操作。
4. 支持设置Painless脚本,对数据进行更加复杂的加工。
Ingest Node VS Logstash
Logstash |
Ingest Node |
|
数据输入与输出 |
支持从不同的数据源读取,并写入不同的数据源 |
支持从ES REST API获取数据,并且写入Elasticsearch |
数据缓冲 |
实现了简单的数据队列,支持重写 |
不支持缓冲 |
数据处理 |
支持大量的插件,也支持定制开发 |
内置的插件,可以开发Plugin进行扩展(Plugin更新需要重启) |
配置和使用 |
增加了一定的架构复杂度 |
无需额外部署 |
Ingest Pipeline
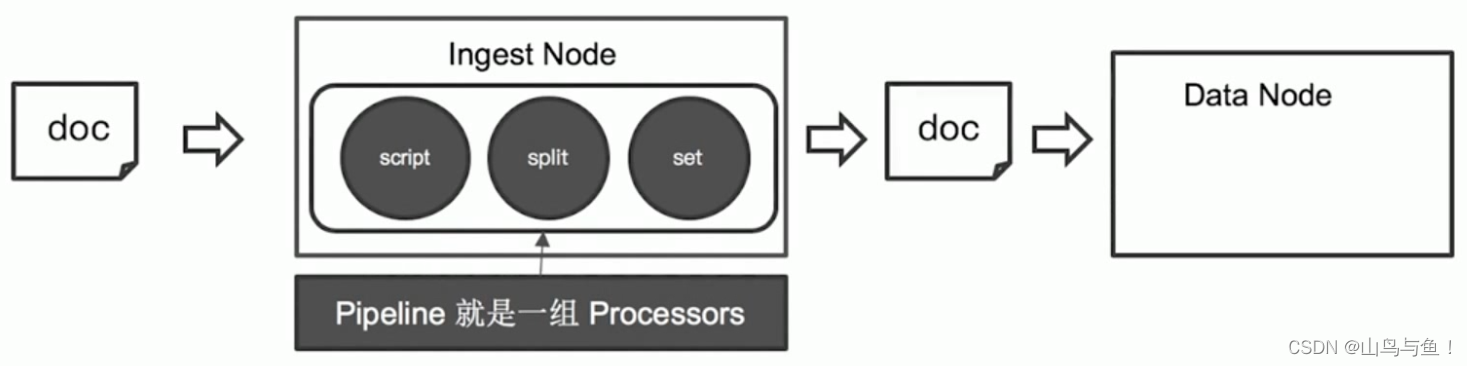
应用场景: 修复与增强写入数据。
案例:后期需要对Tags进行Aggregation统计。Tags字段中,逗号分隔的文本应该是数组,而不是一个字符串。
#Blog数据,包含3个字段,tags用逗号间隔
PUT tech_blogs/_doc/1
{
"title":"Introducing big data......",
"tags":"hadoop,elasticsearch,spark",
"content":"You konw, for big data"
}# 测试split tags
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description": "to split blog tags",
"processors": [
{
"split": {
"field": "tags",
"separator": ","
}
}
]
},
"docs": [
{
"_index": "index",
"_id": "1",
"_source": {
"title": "Introducing big data......",
"tags": "hadoop,elasticsearch,spark",
"content": "You konw, for big data"
}
},
{
"_index": "index",
"_id": "2",
"_source": {
"title": "Introducing cloud computering",
"tags": "openstack,k8s",
"content": "You konw, for cloud"
}
}
]
}
#同时为文档,增加一个字段。blog查看量
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description": "to split blog tags",
"processors": [
{
"split": {
"field": "tags",
"separator": ","
}
},
{
"set":{
"field": "views",
"value": 0
}
}
]
},
"docs": [
{
"_index":"index",
"_id":"1",
"_source":{
"title":"Introducing big data......",
"tags":"hadoop,elasticsearch,spark",
"content":"You konw, for big data"
}
},
{
"_index":"index",
"_id":"2",
"_source":{
"title":"Introducing cloud computering",
"tags":"openstack,k8s",
"content":"You konw, for cloud"
}
}
]
}创建pipeline
# 为ES添加一个 Pipeline
PUT _ingest/pipeline/blog_pipeline
{
"description": "a blog pipeline",
"processors": [
{
"split": {
"field": "tags",
"separator": ","
}
},
{
"set":{
"field": "views",
"value": 0
}
}
]
}
#查看Pipleline
GET _ingest/pipeline/blog_pipeline使用pipeline更新数据
#不使用pipeline更新数据
PUT tech_blogs/_doc/1
{
"title":"Introducing big data......",
"tags":"hadoop,elasticsearch,spark",
"content":"You konw, for big data"
}
#使用pipeline更新数据
PUT tech_blogs/_doc/2?pipeline=blog_pipeline
{
"title": "Introducing cloud computering",
"tags": "openstack,k8s",
"content": "You konw, for cloud"
}Painless Script
自Elasticsearch 5.x后引入,专门为Elasticsearch 设计,扩展了Java的语法。Painless支持所有Java 的数据类型及Java API子集。
Painless Script具备以下特性:
1. 高性能/安全。
2. 支持显示类型或者动态定义类型。
通过Painless脚本访问字段
上下文 |
语法 |
Ingestion |
ctx.field_name |
Update |
ctx._source.field_name |
Search & Aggregation |
doc["field_name"] |
测试
# 增加一个 Script Prcessor
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description": "to split blog tags",
"processors": [
{
"split": {
"field": "tags",
"separator": ","
}
},
{
"script": {
"source": """
if(ctx.containsKey("content")){
ctx.content_length = ctx.content.length();
}else{
ctx.content_length=0;
}
"""
}
},
{
"set":{
"field": "views",
"value": 0
}
}
]
},
"docs": [
{
"_index":"index",
"_id":"1",
"_source":{
"title":"Introducing big data......",
"tags":"hadoop,elasticsearch,spark",
"content":"You konw, for big data"
}
},
{
"_index":"index",
"_id":"2",
"_source":{
"title":"Introducing cloud computering",
"tags":"openstack,k8s",
"content":"You konw, for cloud"
}
}
]
}
DELETE tech_blogs
PUT tech_blogs/_doc/1
{
"title":"Introducing big data......",
"tags":"hadoop,elasticsearch,spark",
"content":"You konw, for big data",
"views":0
}
POST tech_blogs/_update/1
{
"script": {
"source": "ctx._source.views += params.new_views",
"params": {
"new_views":100
}
}
}
# 查看views计数
POST tech_blogs/_search
#保存脚本在 Cluster State
POST _scripts/update_views
{
"script":{
"lang": "painless",
"source": "ctx._source.views += params.new_views"
}
}
POST tech_blogs/_update/1
{
"script": {
"id": "update_views",
"params": {
"new_views":1000
}
}
}
GET tech_blogs/_search
{
"script_fields": {
"rnd_views": {
"script": {
"lang": "painless",
"source": """
java.util.Random rnd = new Random();
doc['views'].value+rnd.nextInt(1000);
"""
}
}
},
"query": {
"match_all": {}
}
}ES文档建模
Elasticsearch中处理关联关系
关系型数据库范式化(Normalize)设计的主要目标是减少不必要的更新,往往会带来一些副作用:一个完全范式化设计的数据库会经常面临“查询缓慢”的问题。数据库越范式化,就需要Join越多的表。范式化节省了存储空间,但是存储空间已经变得越来越便宜。范式化简化了更新,但是数据读取操作可能更多。
反范式化(Denormalize)的设计不使用关联关系,而是在文档中保存冗余的数据拷贝。
优点: 无需处理Join操作,数据读取性能好。Elasticsearch可以通过压缩_source字段,减少磁盘空间的开销。
缺点: 不适合在数据频繁修改的场景。 一条数据的改动,可能会引起很多数据的更新。
关系型数据库,一般会考虑Normalize 数据;在Elasticsearch,往往考虑Denormalize 数据。
Elasticsearch并不擅长处理关联关系,一般会采用以下四种方法处理关联:
对象类型
嵌套对象(Nested Object)
父子关联关系(Parent / Child )
应用端关联
对象类型
案例1: 博客作者信息变更
对象类型:
1. 在每一博客的文档中都保留作者的信息。
2. 如果作者信息发生变化,需要修改相关的博客文档。
DELETE blog
# 设置blog的 Mapping
PUT /blog
{
"mappings": {
"properties": {
"content": {
"type": "text"
},
"time": {
"type": "date"
},
"user": {
"properties": {
"city": {
"type": "text"
},
"userid": {
"type": "long"
},
"username": {
"type": "keyword"
}
}
}
}
}
}
# 插入一条 blog信息
PUT /blog/_doc/1
{
"content":"I like Elasticsearch",
"time":"2024-01-01T00:00:00",
"user":{
"userid":1,
"username":"zhangsan",
"city":"beijing"
}
}
# 查询 blog信息
POST /blog/_search
{
"query": {
"bool": {
"must": [
{"match": {"content": "Elasticsearch"}},
{"match": {"user.username": "zhangsan"}}
]
}
}
}案例2:包含对象数组的文档
DELETE /my_movies
# 电影的Mapping信息
PUT /my_movies
{
"mappings" : {
"properties" : {
"actors" : {
"properties" : {
"first_name" : {
"type" : "keyword"
},
"last_name" : {
"type" : "keyword"
}
}
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
# 写入一条电影信息
POST /my_movies/_doc/1
{
"title":"Speed",
"actors":[
{
"first_name":"Keanu",
"last_name":"Reeves"
},
{
"first_name":"Dennis",
"last_name":"Hopper"
}
]
}
# 查询电影信息
POST /my_movies/_search
{
"query": {
"bool": {
"must": [
{"match": {"actors.first_name": "Keanu"}},
{"match": {"actors.last_name": "Hopper"}}
]
}
}
}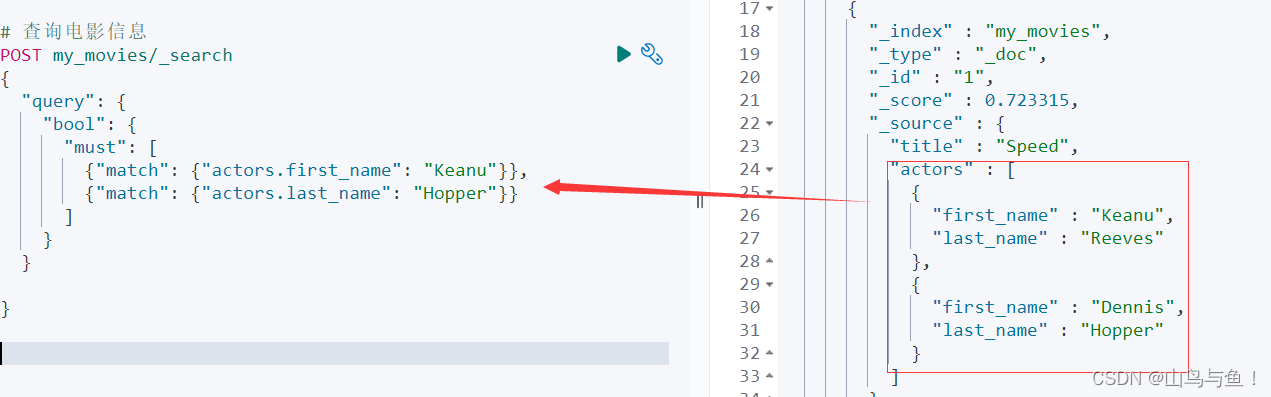
搜不到的原因:存储时,内部对象的边界并没有考虑在内,JSON格式被处理成扁平式键值对的结构。当对多个字段进行查询时,导致了意外的搜索结果。可以用Nested Data Type解决这个问题。
嵌套对象(Nested Object)
什么是Nested Data Type?
Nested数据类型: 允许对象数组中的对象被独立索引。
使用nested 和properties 关键字,将所有actors索引到多个分隔的文档。
在内部, Nested文档会被保存在两个Lucene文档中,在查询时做Join处理。
DELETE /my_movies
# 创建 Nested 对象 Mapping
PUT /my_movies
{
"mappings" : {
"properties" : {
"actors" : {
"type": "nested",
"properties" : {
"first_name" : {"type" : "keyword"},
"last_name" : {"type" : "keyword"}
}},
"title" : {
"type" : "text",
"fields" : {"keyword":{"type":"keyword","ignore_above":256}}
}
}
}
}
POST /my_movies/_doc/1
{
"title":"Speed",
"actors":[
{
"first_name":"Keanu",
"last_name":"Reeves"
},
{
"first_name":"Dennis",
"last_name":"Hopper"
}
]
}
# Nested 查询
POST /my_movies/_search
{
"query": {
"bool": {
"must": [
{"match": {"title": "Speed"}},
{
"nested": {
"path": "actors",
"query": {
"bool": {
"must": [
{"match": {
"actors.first_name": "Keanu"
}},
{"match": {
"actors.last_name": "Hopper"
}}
]
}
}
}
}
]
}
}
}父子关联关系(Parent / Child )
对象和Nested对象的局限性: 每次更新,可能需要重新索引整个对象(包括根对象和嵌套对象)
ES提供了类似关系型数据库中Join 的实现。使用Join数据类型实现,可以通过维护Parent/ Child的关系,从而分离两个对象。
1.父文档和子文档是两个独立的文档。
2. 更新父文档无需重新索引子文档。子文档被添加,更新或者删除也不会影响到父文档和其他的子文档。
设定 Parent/Child Mapping
DELETE /my_blogs
# 设定 Parent/Child Mapping
PUT /my_blogs
{
"settings": {
"number_of_shards": 2
},
"mappings": {
"properties": {
"blog_comments_relation": {
"type": "join",
"relations": {
"blog": "comment"
}
},
"content": {
"type": "text"
},
"title": {
"type": "keyword"
}
}
}
}
索引父文档
#索引父文档
PUT /my_blogs/_doc/blog1
{
"title":"Learning Elasticsearch",
"content":"learning ELK ",
"blog_comments_relation":{
"name":"blog"
}
}
#索引父文档
PUT /my_blogs/_doc/blog2
{
"title":"Learning Hadoop",
"content":"learning Hadoop",
"blog_comments_relation":{
"name":"blog"
}
}
索引子文档
#索引子文档
PUT /my_blogs/_doc/comment1?routing=blog1
{
"comment":"I am learning ELK",
"username":"Jack",
"blog_comments_relation":{
"name":"comment",
"parent":"blog1"
}
}
#索引子文档
PUT /my_blogs/_doc/comment2?routing=blog2
{
"comment":"I like Hadoop!!!!!",
"username":"Jack",
"blog_comments_relation":{
"name":"comment",
"parent":"blog2"
}
}
#索引子文档
PUT /my_blogs/_doc/comment3?routing=blog2
{
"comment":"Hello Hadoop",
"username":"Bob",
"blog_comments_relation":{
"name":"comment",
"parent":"blog2"
}
}
注意:
父文档和子文档必须存在相同的分片上,能够确保查询join 的性能。
当指定子文档时候,必须指定它的父文档ld。使用routing参数来保证,分配到相同的分片。
查询
# 查询所有文档
POST /my_blogs/_search
#根据父文档ID查看
GET /my_blogs/_doc/blog2
# Parent Id 查询
POST /my_blogs/_search
{
"query": {
"parent_id": {
"type": "comment",
"id": "blog2"
}
}
}
# Has Child 查询,返回父文档
POST /my_blogs/_search
{
"query": {
"has_child": {
"type": "comment",
"query" : {
"match": {
"username" : "Jack"
}
}
}
}
}
# Has Parent 查询,返回相关的子文档
POST /my_blogs/_search
{
"query": {
"has_parent": {
"parent_type": "blog",
"query" : {
"match": {
"title" : "Learning Hadoop"
}
}
}
}
}
#通过ID ,访问子文档
GET /my_blogs/_doc/comment3
#通过ID和routing ,访问子文档
GET /my_blogs/_doc/comment3?routing=blog2
#更新子文档
PUT /my_blogs/_doc/comment3?routing=blog2
{
"comment": "Hello Hadoop??",
"blog_comments_relation": {
"name": "comment",
"parent": "blog2"
}
}嵌套文档 VS 父子文档
Nested Object |
Parent / Child |
|
优点 |
文档存储在一起,读取性能高 |
父子文档可以独立更新 |
缺点 |
更新嵌套的子文档时,需要更新整个文档 |
需要额外的内存维护关系。读取性能相对差 |
适用场景 |
子文档偶尔更新,以查询为主 |
子文档更新频繁 |