一、本文介绍
在这篇文章中,我们将讲解如何将LSKAttention大核注意力机制应用于RT-DETR,以实现显著的性能提升。首先,我们介绍LSKAttention机制的基本原理,它主要通过将深度卷积层的2D卷积核分解为水平和垂直1D卷积核,减少了计算复杂性和内存占用。接着,我们介绍将这一机制整合到RT-DETR的方法,以及它如何帮助提高处理大型数据集和复杂视觉任务的效率和准确性。本文改进是基于ResNet18、ResNet34、ResNet50、ResNet101,文章中均以提供,本专栏的改进内容全网独一份深度改进RT-DETR非那种无效Neck部分改进,同时本文的改进也支持主干上的即插即用,本文内容也支持PP-HGNetV2版本的修改。
目录
四、手把手教你将LSKAttention添加到你的网络结构中
4.1 修改Basicclock/Bottleneck的教程
5.1 替换ResNet的yaml文件1(ResNet18版本)
5.2 替换ResNet的yaml文件1(ResNet50版本)
二、LSKAttention的机制原理

论文地址:官方论文地址
代码地址:官方代码地址

《Large Separable Kernel Attention》这篇论文提出的LSKAttention的机制原理是针对传统大核注意力(Large Kernel Attention,LKA)模块在视觉注意网络(Visual Attention Networks,VAN)中的应用问题进行的改进。LKA模块在处理大尺寸卷积核时面临着高计算和内存需求的挑战。LSKAttention通过以下几个关键步骤和原理来解决这些问题:
核分解:LSKAttention的核心创新是将传统的2D卷积核分解为两个1D卷积核。首先,它将一个大的2D核分解成水平(横向)和垂直(纵向)的两个1D核。这样的分解大幅降低了参数数量和计算复杂度。
串联卷积操作:在进行卷积操作时,LSKAttention首先使用一个1D核对输入进行水平方向上的卷积,然后使用另一个1D核进行垂直方向上的卷积。这两步卷积操作串联执行,从而实现了与原始大尺寸2D核相似的效果。
计算效率提升:由于分解后的1D卷积核大大减少了参数的数量,LSKAttention在执行时的计算效率得到显著提升。这种方法特别适用于处理大尺寸的卷积核,能够有效降低内存占用和计算成本。
保持效果:虽然采用了分解和串联的策略,LSKAttention仍然能够保持类似于原始LKA的性能。这意味着在处理图像的关键特征(如边缘、纹理和形状)时,LSKAttention能够有效地捕捉到重要信息。
适用于多种任务:LSKAttention不仅在图像分类任务中表现出色,还能够在目标检测、语义分割等多种计算机视觉任务中有效应用,显示出其广泛的适用性。
总结:LSKAttention通过创新的核分解和串联卷积策略,在降低计算和内存成本的同时,保持了高效的图像处理能力,这在处理大尺寸核和复杂图像数据时特别有价值。
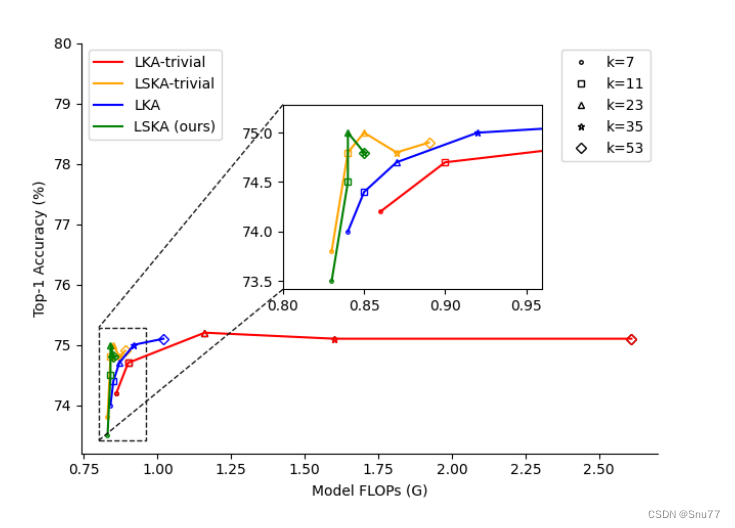
上图展示了在不同大核分解方法和核大小下的速度-精度权衡。在这个比较中,使用了不同的标记来代表不同的核大小,并且以VAN-Tiny作为对比的模型。从图中可以看出,LKA的朴素设计(LKA-trivial)以及在VAN中的实际设计,在核大小增加时会导致更高的GFLOPs(十亿浮点运算次数)。相比之下,论文提出的LSKA(Large Separable Kernel Attention)-trivial和VAN中的LSKA在核大小增加时显著降低了GFLOPs,同时没有降低性能

上图展示了大核注意力模块不同设计的比较,具体包括:
- LKA-trivial:朴素的2D大核深度卷积(DW-Conv)与1×1卷积结合(图a)。
- LSKA-trivial:串联的水平和垂直1D大核深度卷积与1×1卷积结合(图b)。
- 原始LKA设计:在VAN中包括标准深度卷积(DW-Conv)、扩张深度卷积(DW-D-Conv)和1×1卷积(图c)。
- 提出的LSKA设计:将LKA的前两层分解为四层,每层由两个1D卷积层组成(图d)。其中,N代表Hadamard乘积,k代表最大感受野,d代表扩张率。
个人总结:提出了一种创新的大型可分离核注意力(LSKA)模块,用于改进卷积神经网络(CNN)。这种模块通过将2D卷积核分解为串联的1D核,有效降低了计算复杂度和内存需求。LSKA模块在保持与标准大核注意力(LKA)模块相当的性能的同时,显示出更高的计算效率和更小的内存占用。
三、LSKAttention的代码
将下面的代码在"ultralytics/nn/modules" 目录下创建一个py文件复制粘贴进去然后按照章节四进行添加即可(需要按照有参数的注意力机制添加)。
import torch
import torch.nn as nn
class LSKA(nn.Module):
def __init__(self, dim, k_size):
super().__init__()
self.k_size = k_size
if k_size == 7:
self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,(3-1)//2), groups=dim)
self.conv0v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=((3-1)//2,0), groups=dim)
self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,2), groups=dim, dilation=2)
self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=(2,0), groups=dim, dilation=2)
elif k_size == 11:
self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,(3-1)//2), groups=dim)
self.conv0v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=((3-1)//2,0), groups=dim)
self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,4), groups=dim, dilation=2)
self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=(4,0), groups=dim, dilation=2)
elif k_size == 23:
self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)
self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)
self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 7), stride=(1,1), padding=(0,9), groups=dim, dilation=3)
self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(7, 1), stride=(1,1), padding=(9,0), groups=dim, dilation=3)
elif k_size == 35:
self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)
self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)
self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 11), stride=(1,1), padding=(0,15), groups=dim, dilation=3)
self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(11, 1), stride=(1,1), padding=(15,0), groups=dim, dilation=3)
elif k_size == 41:
self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)
self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)
self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 13), stride=(1,1), padding=(0,18), groups=dim, dilation=3)
self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(13, 1), stride=(1,1), padding=(18,0), groups=dim, dilation=3)
elif k_size == 53:
self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)
self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)
self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 17), stride=(1,1), padding=(0,24), groups=dim, dilation=3)
self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(17, 1), stride=(1,1), padding=(24,0), groups=dim, dilation=3)
self.conv1 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0h(x)
attn = self.conv0v(attn)
attn = self.conv_spatial_h(attn)
attn = self.conv_spatial_v(attn)
attn = self.conv1(attn)
return u * attn
四、手把手教你将LSKAttention添加到你的网络结构中
修改教程分两种,一种是替换修改ResNet中的Basicclock/Bottleneck模块的,一种是在主干上即插即用的修改教程,如果你只需要一种那么修改对应的就行,互相之间并不影响,需要注意的是即插即用的需要修改ResNet改进才行,链接如下:
ResNet文章地址:【RT-DETR改进涨点】ResNet18、34、50、101等多个版本移植到ultralytics仓库(RT-DETR官方一比一移植)
4.1 修改Basicclock/Bottleneck的教程
4.1.1 修改一
第一还是建立文件,我们找到如下ultralytics/nn/modules文件夹下建立一个目录名字呢就是'Addmodules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。

4.1.2 修改二
第二步此处需要注意,因为我这里默认大家修改了ResNet系列的模型了,同级目录下应该有一个ResNet.py的文件夹,我们这里需要找到我们'ultralytics/nn/Addmodules/ResNet.py'创建的ResNet的文件夹(默认大家已经创建了!!!)
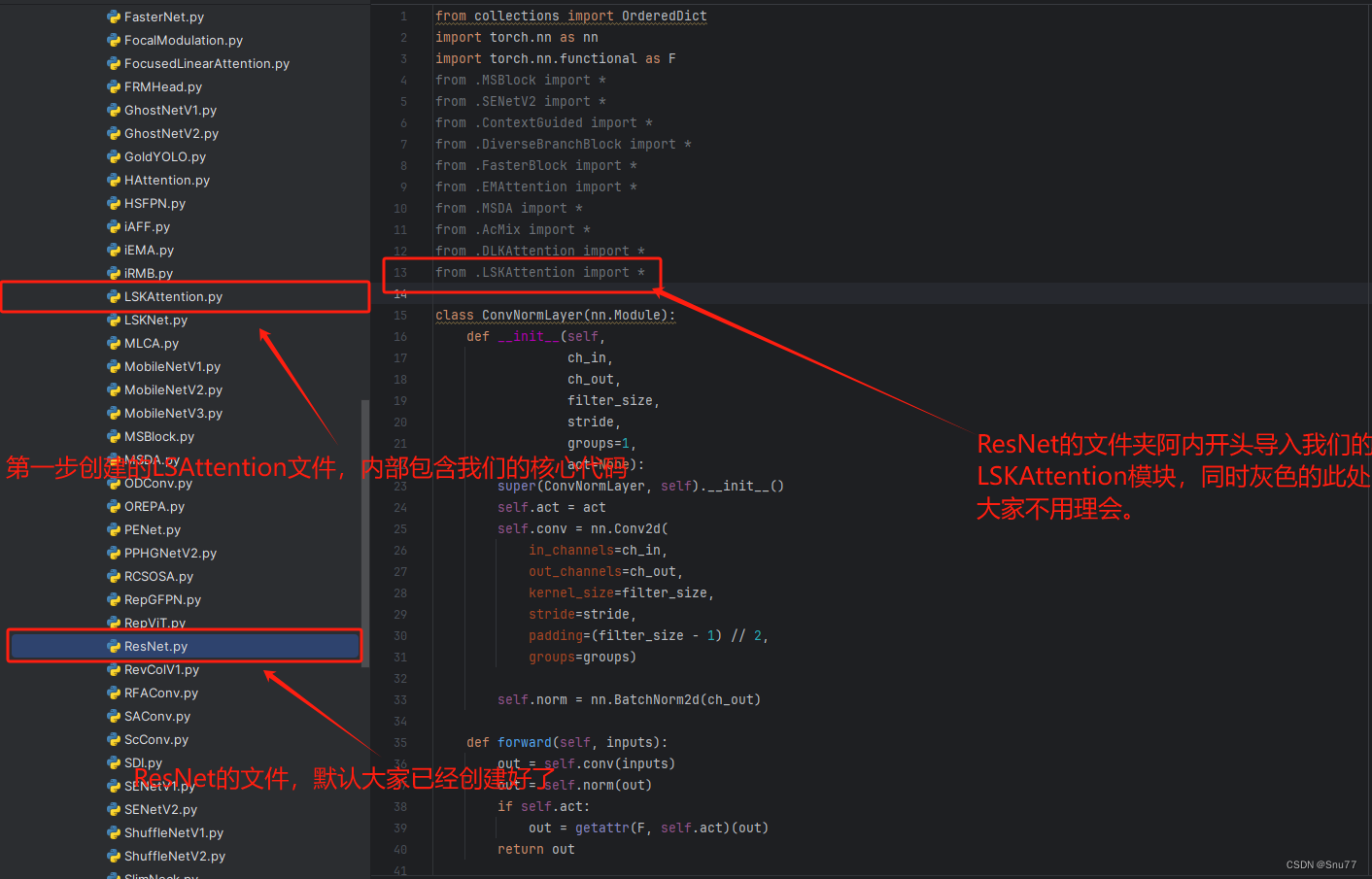
我们只需要修改上面的两步即可,后面复制yaml文件进行运行即可了,修改方法大家只要仔细看是非常简单的。
4.2 修改主干上即插即用的教程
4.2.1 修改一(如果修改了4.1教程此步无需修改)
第一还是建立文件,我们找到如下ultralytics/nn/modules文件夹下建立一个目录名字呢就是'Addmodules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。
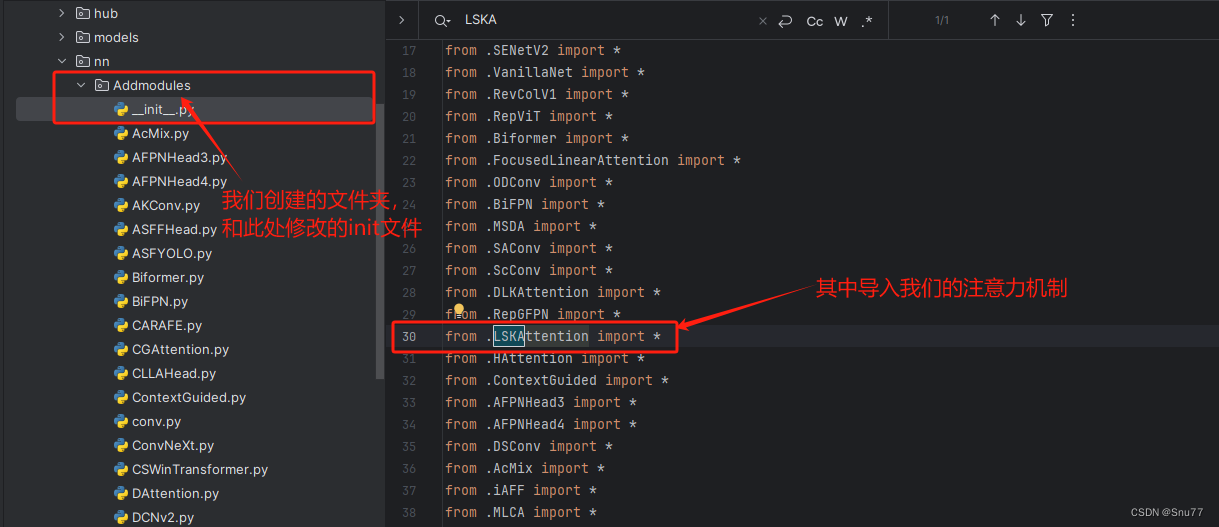
4.2.2 修改二
第二步我们在该目录下创建一个新的py文件名字为'__init__.py'(用群内的文件的话已经有了无需新建),然后在其内部导入我们的检测头如下图所示。
4.2.3 修改三
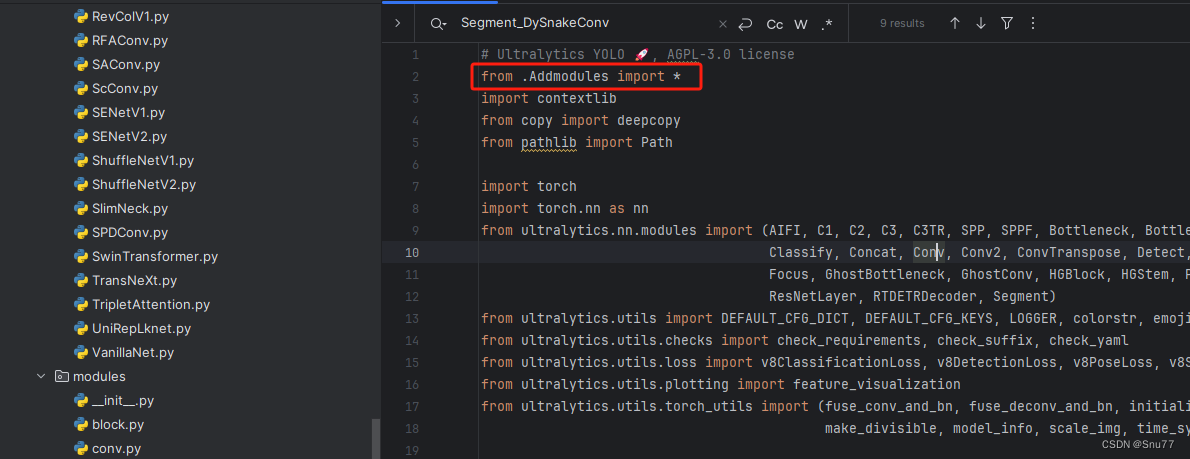
第三步我门中到如下文件'ultralytics/nn/tasks.py'进行导入和注册我们的模块(用群内的文件的话已经有了无需重新导入直接开始第四步即可)!
从今天开始以后的教程就都统一成这个样子了,因为我默认大家用了我群内的文件来进行修改!!
4.2.4 修改四
按照我的添加在parse_model里添加即可。
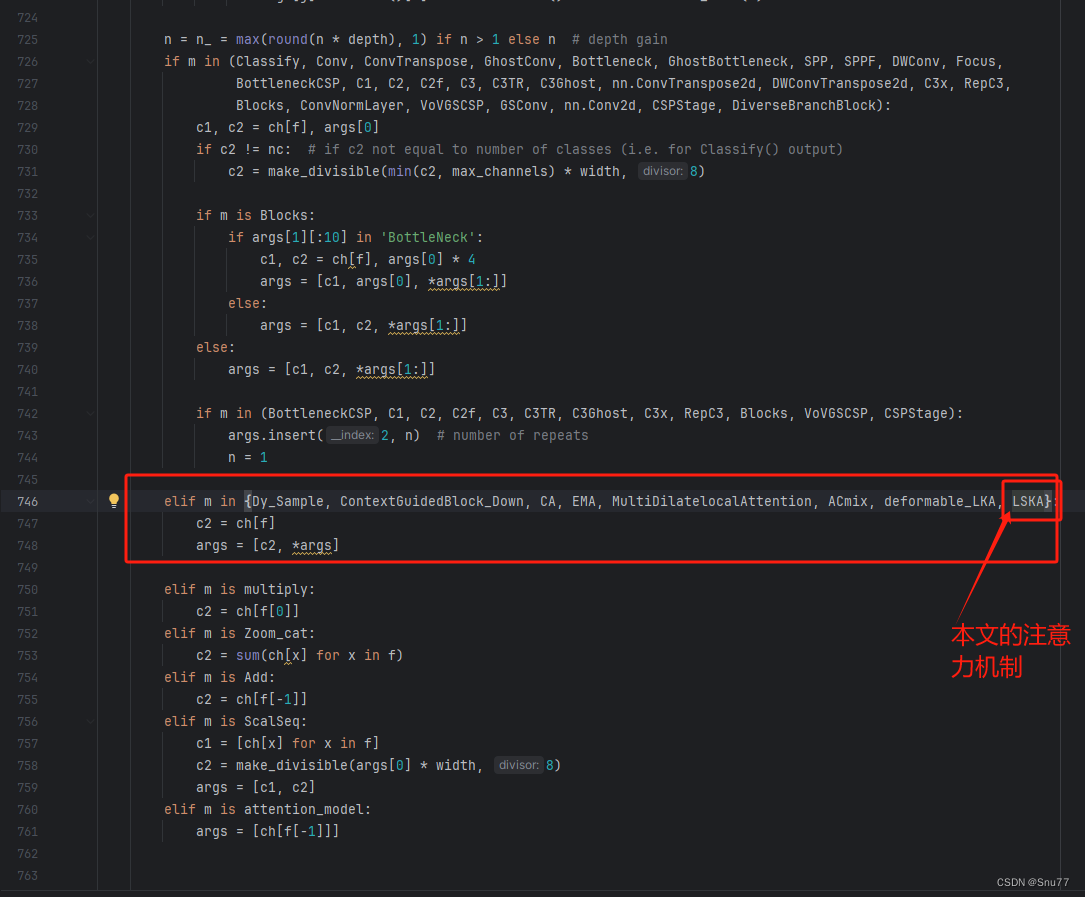
elif m in {LSKA}:
c2 = ch[f]
args = [c2, *args]到此就修改完成了,大家可以复制下面的yaml文件运行。
五、LSKAttention的yaml文件
5.1 替换ResNet的yaml文件1(ResNet18版本)
需要修改如下的ResNet主干才可以运行本文的改进机制 !
ResNet文章地址:【RT-DETR改进涨点】ResNet18、34、50、101等多个版本移植到ultralytics仓库(RT-DETR官方一比一移植)
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, ConvNormLayer, [32, 3, 2, 1, 'relu']] # 0-P1
- [-1, 1, ConvNormLayer, [32, 3, 1, 1, 'relu']] # 1
- [-1, 1, ConvNormLayer, [64, 3, 1, 1, 'relu']] # 2
- [-1, 1, nn.MaxPool2d, [3, 2, 1]] # 3-P2
- [-1, 2, Blocks, [64, BasicBlock_LSKA, 2, True]] # 4
- [-1, 2, Blocks, [128, BasicBlock_LSKA, 3, True]] # 5-P3
- [-1, 2, Blocks, [256, BasicBlock_LSKA, 4, True]] # 6-P4
- [-1, 2, Blocks, [512, BasicBlock_LSKA, 5, True]] # 7-P5
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 8 input_proj.2
- [-1, 1, AIFI, [1024, 8]]
- [-1, 1, Conv, [256, 1, 1]] # 10, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 11
- [6, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 12 input_proj.1
- [[-2, -1], 1, Concat, [1]]
- [-1, 3, RepC3, [256, 0.5]] # 14, fpn_blocks.0
- [-1, 1, Conv, [256, 1, 1]] # 15, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 16
- [5, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 17 input_proj.0
- [[-2, -1], 1, Concat, [1]] # 18 cat backbone P4
- [-1, 3, RepC3, [256, 0.5]] # X3 (19), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 20, downsample_convs.0
- [[-1, 15], 1, Concat, [1]] # 21 cat Y4
- [-1, 3, RepC3, [256, 0.5]] # F4 (22), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 23, downsample_convs.1
- [[-1, 10], 1, Concat, [1]] # 24 cat Y5
- [-1, 3, RepC3, [256, 0.5]] # F5 (25), pan_blocks.1
- [[19, 22, 25], 1, RTDETRDecoder, [nc, 256, 300, 4, 8, 3]] # Detect(P3, P4, P5)
5.2 替换ResNet的yaml文件1(ResNet50版本)
需要修改如下的ResNet主干才可以运行本文的改进机制 !
ResNet文章地址:【RT-DETR改进涨点】ResNet18、34、50、101等多个版本移植到ultralytics仓库(RT-DETR官方一比一移植)
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, ConvNormLayer, [32, 3, 2, 1, 'relu']] # 0-P1
- [-1, 1, ConvNormLayer, [32, 3, 1, 1, 'relu']] # 1
- [-1, 1, ConvNormLayer, [64, 3, 1, 1, 'relu']] # 2
- [-1, 1, nn.MaxPool2d, [3, 2, 1]] # 3-P2
- [-1, 3, Blocks, [64, BottleNeck_LSKA, 2, True]] # 4
- [-1, 4, Blocks, [128, BottleNeck_LSKA, 3, True]] # 5-P3
- [-1, 6, Blocks, [256, BottleNeck_LSKA, 4, True]] # 6-P4
- [-1, 3, Blocks, [512, BottleNeck_LSKA, 5, True]] # 7-P5
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 8 input_proj.2
- [-1, 1, AIFI, [1024, 8]] # 9
- [-1, 1, Conv, [256, 1, 1]] # 10, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 11
- [6, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 12 input_proj.1
- [[-2, -1], 1, Concat, [1]] # 13
- [-1, 3, RepC3, [256]] # 14, fpn_blocks.0
- [-1, 1, Conv, [256, 1, 1]] # 15, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 16
- [5, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 17 input_proj.0
- [[-2, -1], 1, Concat, [1]] # 18 cat backbone P4
- [-1, 3, RepC3, [256]] # X3 (19), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 20, downsample_convs.0
- [[-1, 15], 1, Concat, [1]] # 21 cat Y4
- [-1, 3, RepC3, [256]] # F4 (22), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 23, downsample_convs.1
- [[-1, 10], 1, Concat, [1]] # 24 cat Y5
- [-1, 3, RepC3, [256]] # F5 (25), pan_blocks.1
- [[19, 22, 25], 1, RTDETRDecoder, [nc, 256, 300, 4, 8, 6]] # Detect(P3, P4, P5)
5.3 即插即用的yaml文件(HGNetV2版本)
此版本为HGNetV2-l的yaml文件!
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, HGStem, [32, 48]] # 0-P2/4
- [-1, 6, HGBlock, [48, 128, 3]] # stage 1
- [-1, 1, DWConv, [128, 3, 2, 1, False]] # 2-P3/8
- [-1, 6, HGBlock, [96, 512, 3]] # stage 2
- [-1, 1, DWConv, [512, 3, 2, 1, False]] # 4-P3/16
- [-1, 6, HGBlock, [192, 1024, 5, True, False]] # cm, c2, k, light, shortcut
- [-1, 6, HGBlock, [192, 1024, 5, True, True]]
- [-1, 6, HGBlock, [192, 1024, 5, True, True]] # stage 3
- [-1, 1, DWConv, [1024, 3, 2, 1, False]] # 8-P4/32
- [-1, 6, HGBlock, [384, 2048, 5, True, False]] # stage 4
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 10 input_proj.2
- [-1, 1, AIFI, [1024, 8]]
- [-1, 1, Conv, [256, 1, 1]] # 12, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [7, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 14 input_proj.1
- [[-2, -1], 1, Concat, [1]]
- [-1, 3, RepC3, [256]] # 16, fpn_blocks.0
- [-1, 1, Conv, [256, 1, 1]] # 17, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [3, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 19 input_proj.0
- [[-2, -1], 1, Concat, [1]] # cat backbone P4
- [-1, 3, RepC3, [256]] # X3 (21), fpn_blocks.1
- [-1, 1, LSKA, []] # 22
- [-1, 1, Conv, [384, 3, 2]] # 23, downsample_convs.0
- [[-1, 17], 1, Concat, [1]] # cat Y4
- [-1, 3, RepC3, [256]] # F4 (25), pan_blocks.0
- [-1, 1, LSKA, []] # 26
- [-1, 1, Conv, [384, 3, 2]] # 27, downsample_convs.1
- [[-1, 12], 1, Concat, [1]] # cat Y5
- [-1, 3, RepC3, [256]] # F5 (29), pan_blocks.1
- [-1, 1, LSKA, []] # 30
- [[22, 26, 30], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5)
六、成功运行记录
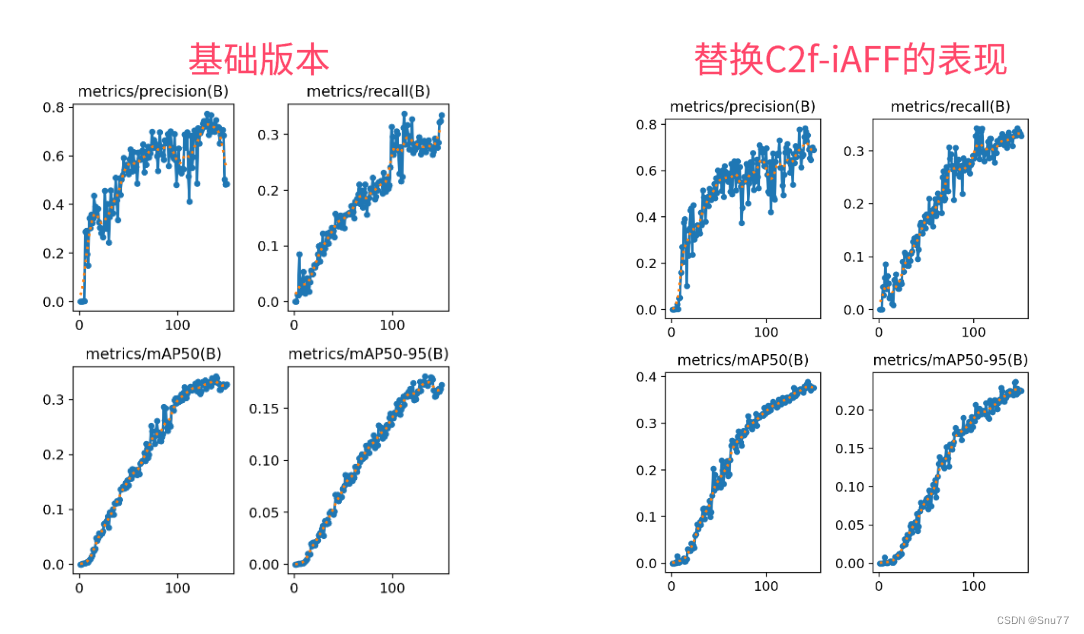
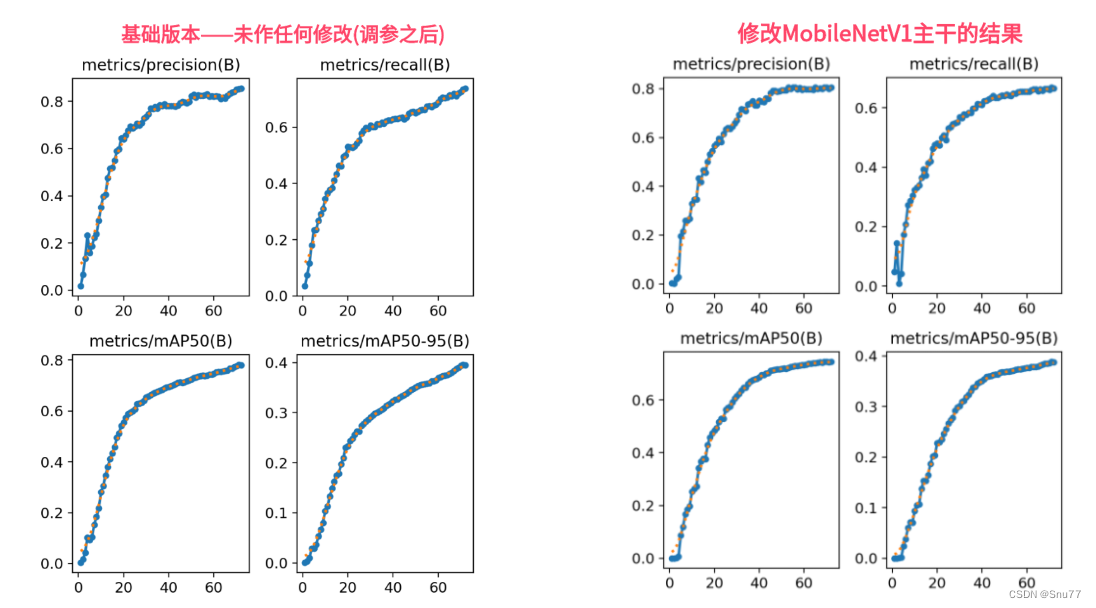
6.1 ResNet18运行成功记录截图
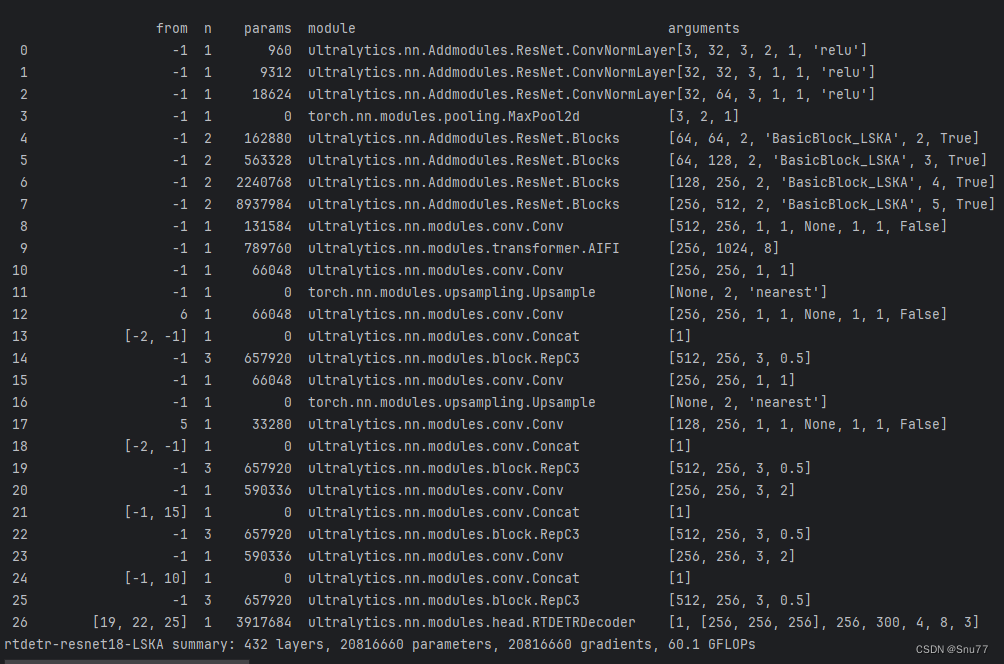
6.2 ResNet50运行成功记录截图
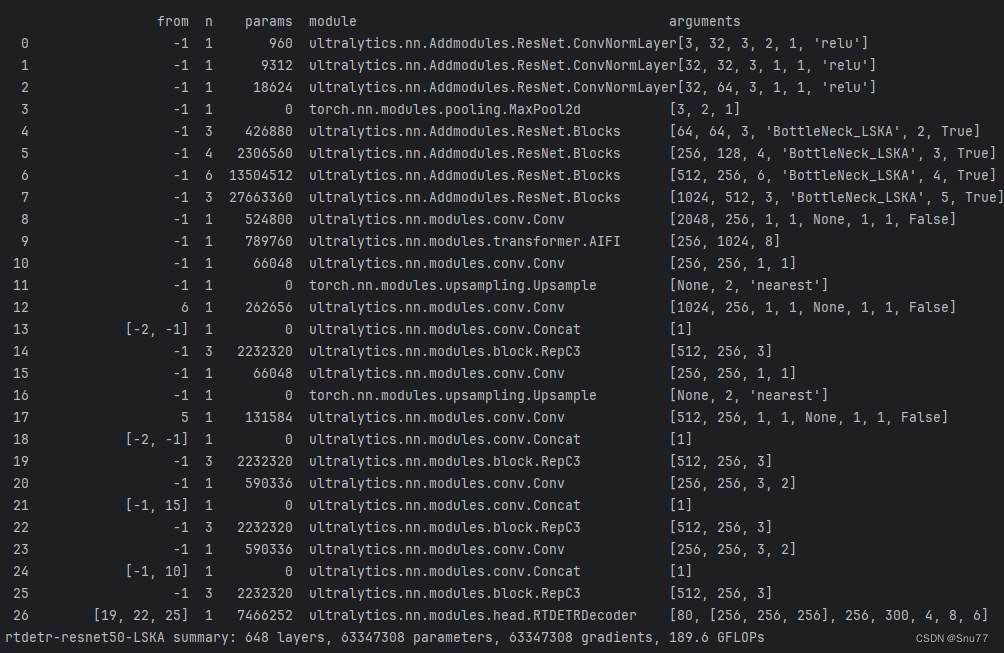
6.3 HGNetv2运行成功记录截图

七、全文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的RT-DETR改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~

![【YOLOv8<span style='color:red;'>改进</span>[<span style='color:red;'>注意力</span>]】YOLOv8添加DAT(Vision Transformer with Deformable Attention)<span style='color:red;'>助力</span><span style='color:red;'>涨</span><span style='color:red;'>点</span>](https://img-blog.csdnimg.cn/direct/bdba9039a3134667a95f2716f695c943.png)