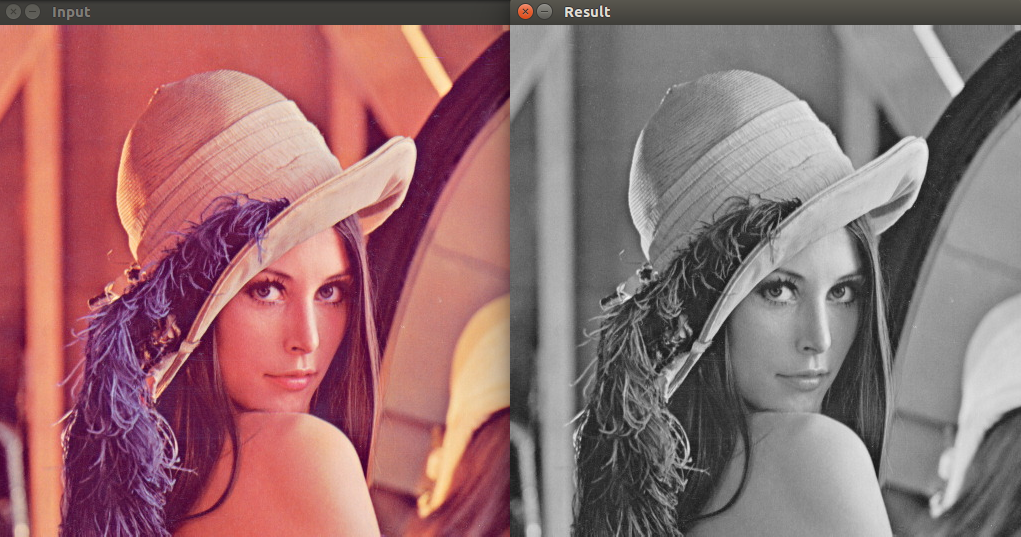
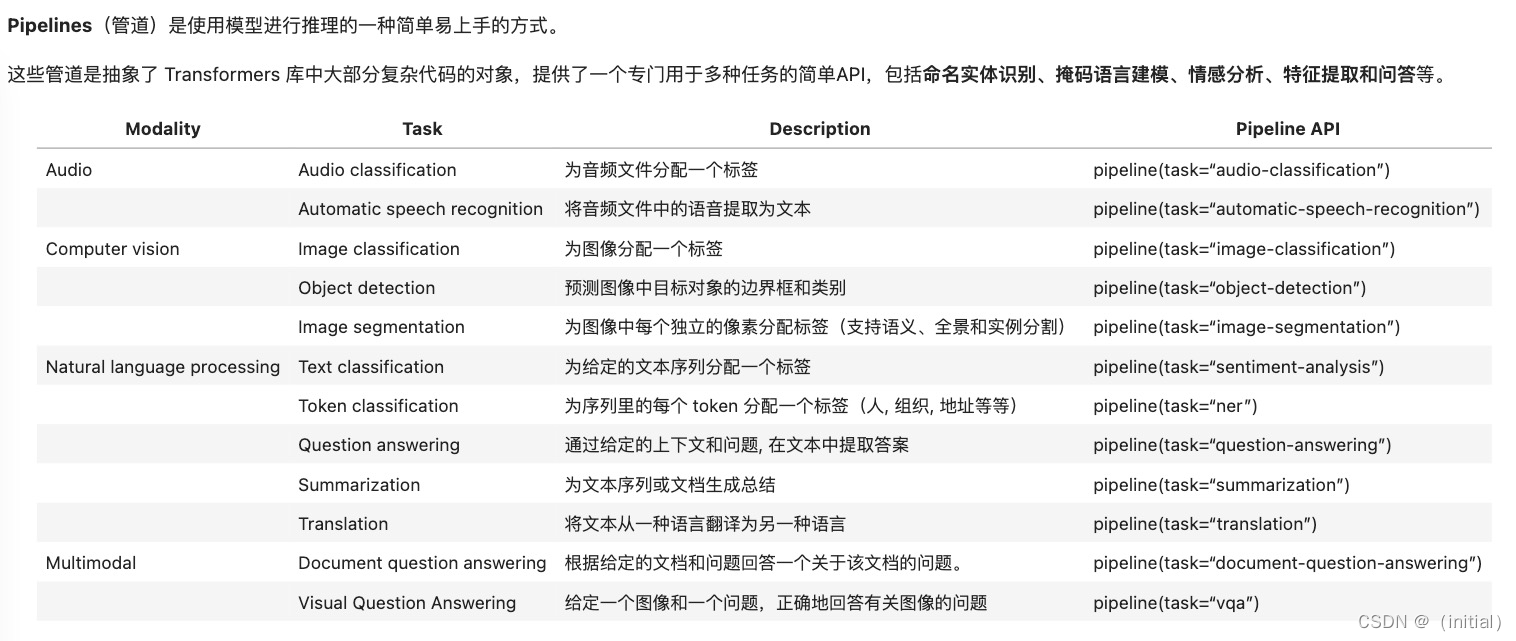
图像分割是指将图像划分成多个具有独立语义的区域或对象的过程。目标是根据像素级别的信息将图像中的不同区域进行分离和分类,以获得更具语义和结构的图像表示。
图像分割在计算机视觉和图像处理中具有广泛的应用,包括目标检测、图像增强、医学影像分析、自动驾驶、虚拟现实等领域。以下是一些常见的图像分割方法:
基于阈值的分割:将图像中的像素按照其灰度值与预先设定的阈值进行比较,大于或小于阈值的像素被分到不同的区域中。这种方法简单直观,适用于对比较明显的目标进行分割。
基于边缘的分割:利用图像中的边缘信息进行分割,通过检测边缘的变化来确定不同区域的边界。常用的边缘检测算法包括Canny边缘检测、Sobel算子等。
基于区域的分割:将图像分割成具有类似纹理、颜色或形状特征的区域。这种方法通常基于区域生长、区域分裂与合并等策略,通过定义合适的相似性度量来判断像素是否属于同一区域。
基于图割的分割:将图像分割转化为图论中的最小割/最大流问题,通过最小化能量函数来获得最优分割结果。常用的算法包括GrabCut算法、GraphCut算法等。
基于深度学习的分割:利用深度卷积神经网络(如U-Net、FCN等)对图像进行端到端的语义分割。这些网络能够学习到图像中的特征表示,并生成像素级别的分割结果。
需要根据具体问题选择适合的图像分割方法,不同的方法在不同的场景下可能会有不同的效果。此外,图像分割也可以结合其他图像处理技术,如特征提取、目标检测等,以进一步提高分割的精确度和鲁棒性。