ALBEF
论文信息
标题:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
作者:Junnan Li(Salesforce Research)
期刊:NeurIPS 2021
发布时间与更新时间:2021.07.16 2021.10.07
主题:多模态、预训练、图像、文本、对比学习、知识蒸馏、动量模型
arXiv:https://arxiv.org/abs/2107.07651
代码:salesforce/ALBEF: Code for ALBEF: a new vision-language pre-training method (github.com)
概述
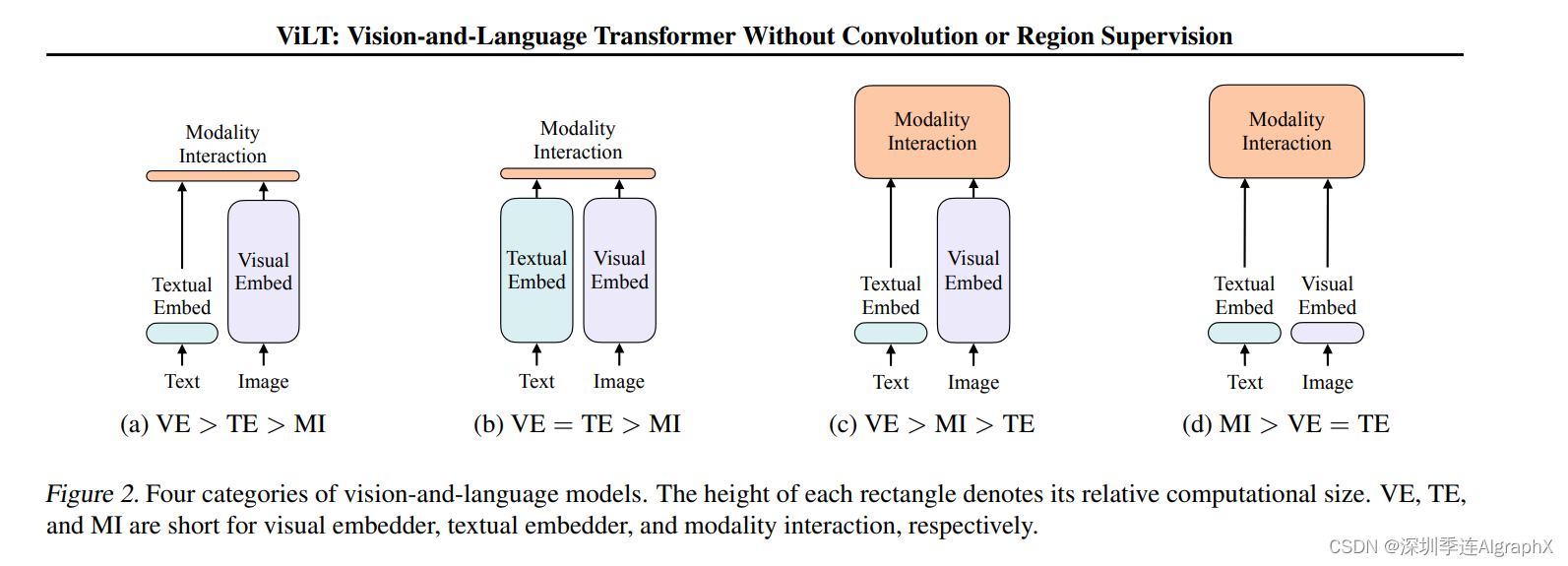
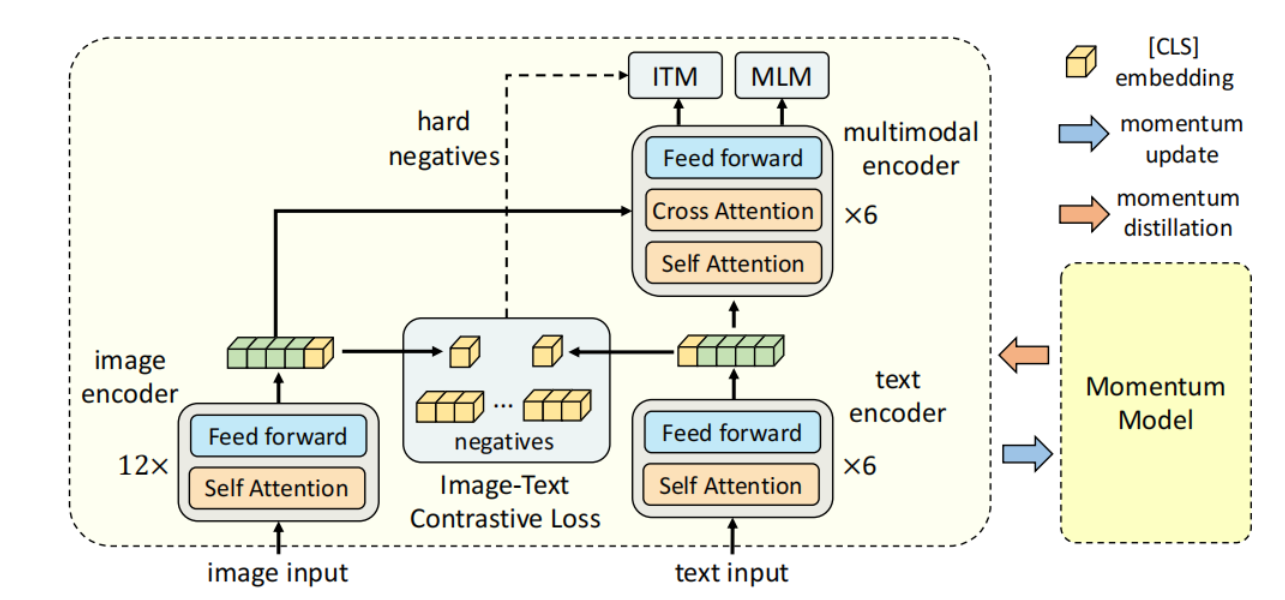
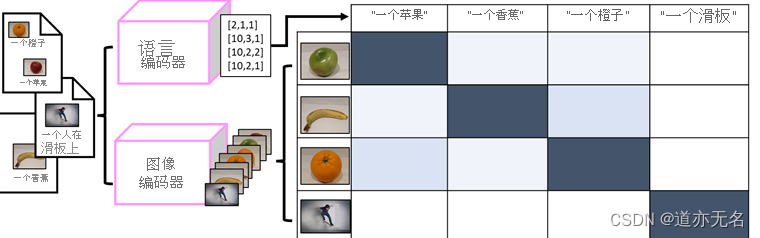
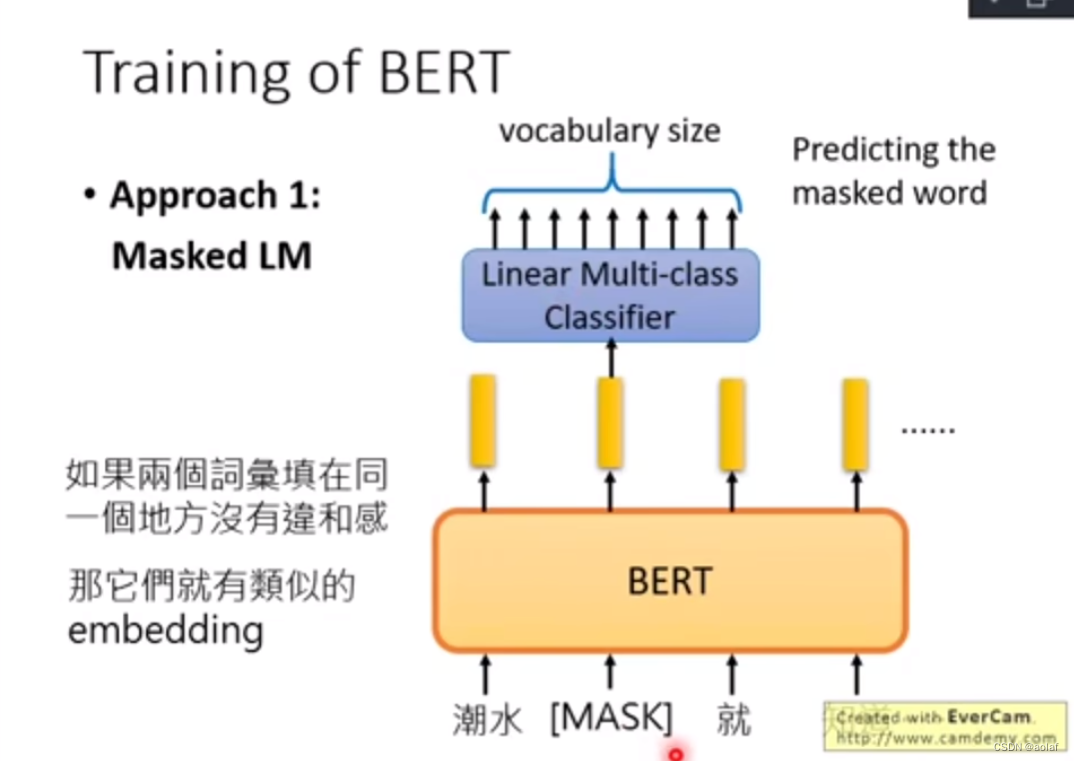
作者认为之前的模型存在三个问题:① 使用预训练好的目标检测器(object detector)对图像目标识别的结果作为图像的单模态特征,与来自文本编码器的文本特征的对齐程度很低,因为目标检测器没有与文本特征一同进行端到端的训练,用于捕获两个模态交互信息的模块无法很好地将来自两个独立语义空间的特征进行融合。另外,推理阶段的目标检测器需要接收高分辨率的图像,计算量较大,时间开销较大;② 直接使用来自视觉编码器和文本编码器的单模态特征对多模态交互信息进行建模是非常困难