今天我们就来过一下多模态的串讲,其实之前,我们也讲了很多工作了,比如说CLIP,还有ViLT,以及CLIP的那么多后续工作。多模态学习在最近几年真的是异常的火爆,那除了普通的这种多模态学习,比如说视觉问答,图文检索这些,那其实之前讲的,所有这种language guided detection,或者这些language guided segmentation任务都是多态。而且包括最近大的这种文本图像生成,或者文本视频生成,我们耳熟能详的DALLE2,Stable Diffusion所有的这些,通通都属于多模态学习。
我们这期多模态串讲,可能更多的还是讲传统的这种多模态学习,也就是说当下游任务是这种图文检索,就是image text retrieval,或者VQA,就视觉问答,或者visual reasoning,就是视觉推理,还有就是visual entailment,视觉蕴含,就是这些传统的多模态任务。
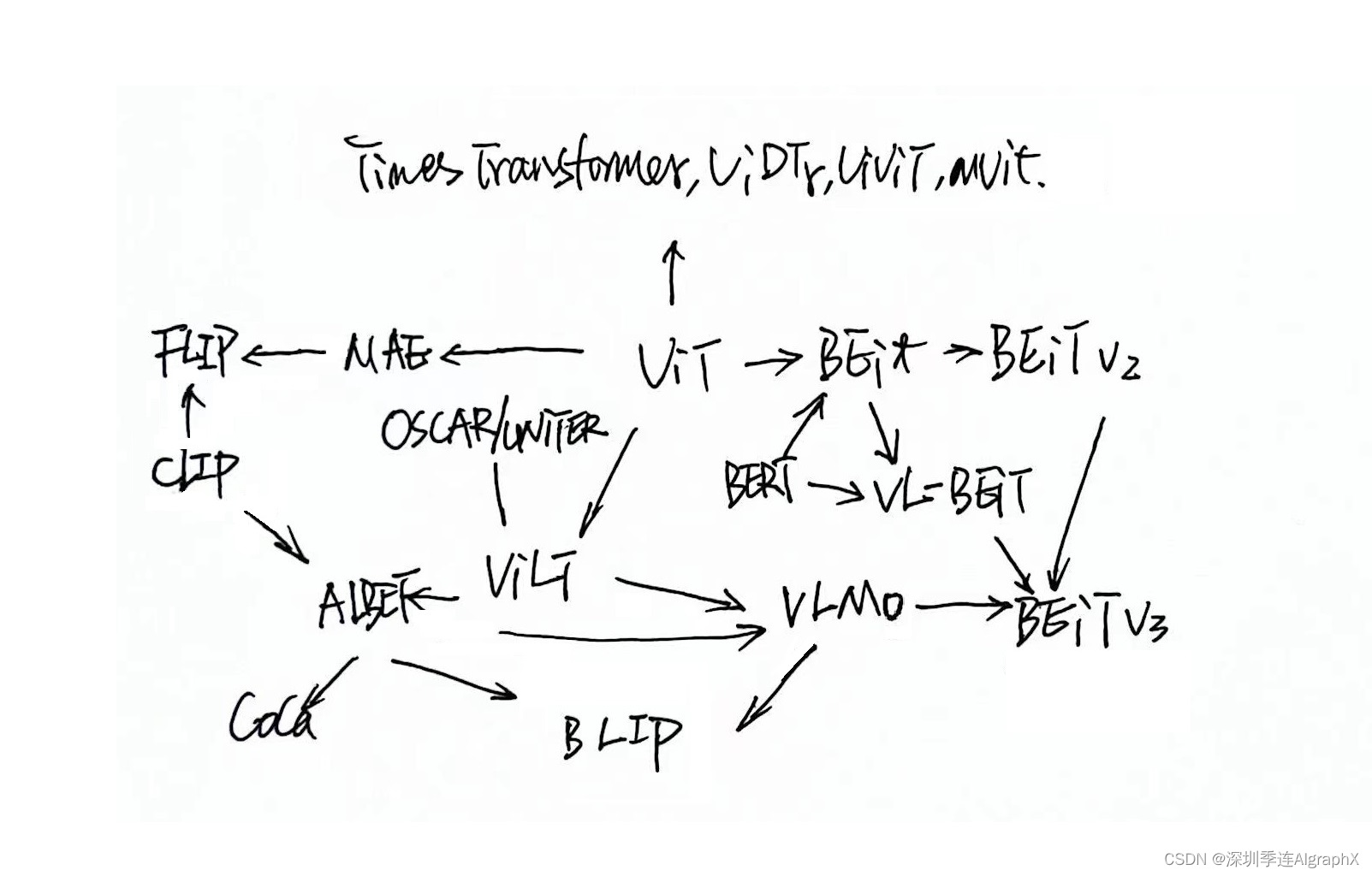
但即使如此,相关的工作也是多的数不胜数。我们这个串讲的第一部分,应该就是讲一下只用transformer decoder的一些方法,比如说之前的这个ViLT、CLIP,还有我们今天要讲的ALBEF,MoME,VLMo。
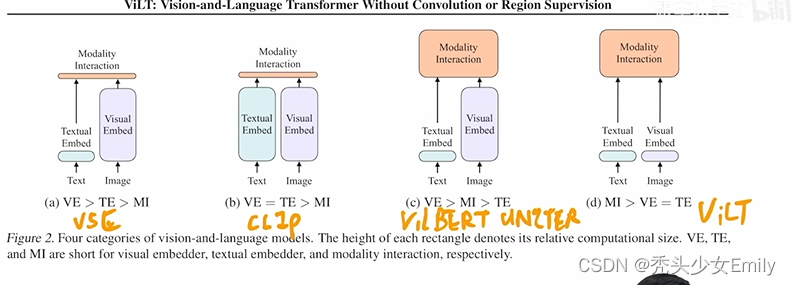
然后在第二部分,我们会讲到用transformer encoder和decoder一起的一些方法,比如说BLIP、CoCA、BEiT v3和PaLI。在我们开始讲ALBEF之前,那我们先简单回顾一下ViLT和CLIP,鉴于ViLT论文里这个图二真的是总结的比较好,我们就先从这张图开始。
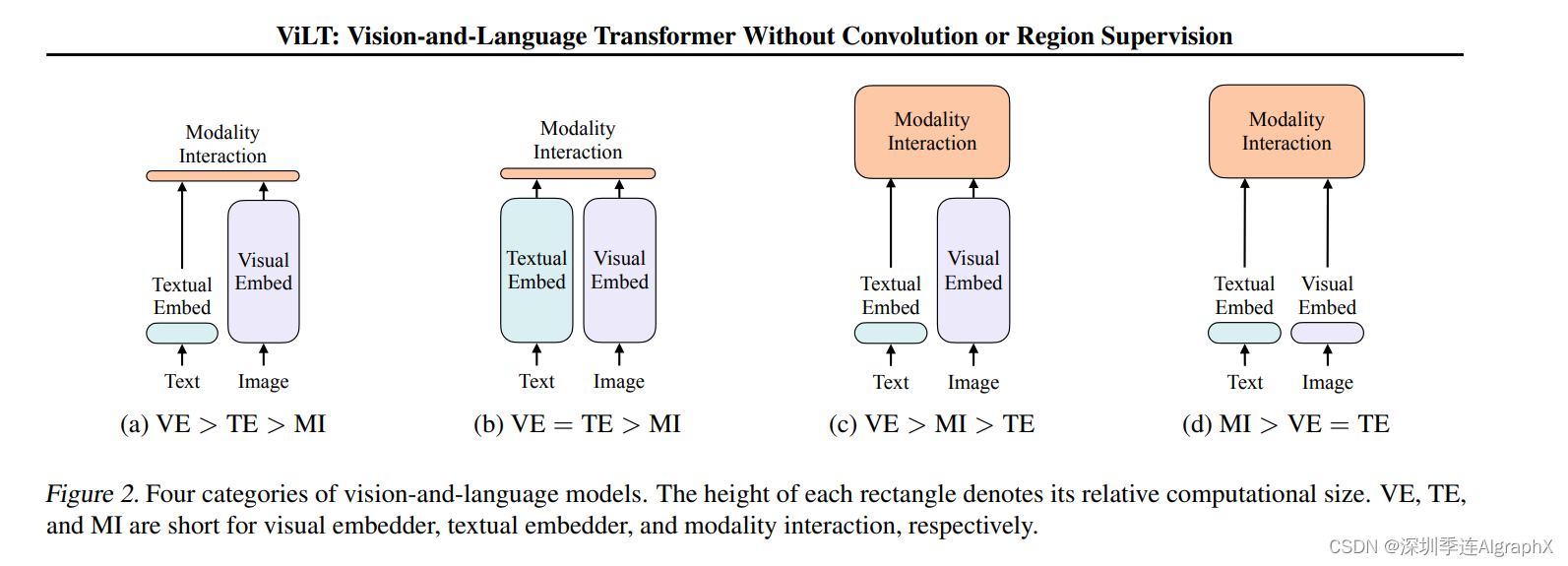
ViLT这篇论文的研究动机,其实就是为了把这个目标检测,从这个视觉端给拿掉。原因很简单,因为你用一个预训练的这个目标检测器,去抽这个视觉特征的时候,它就会面临很多很多的这个局限性,我们之前也都讲过了,但是,直到21年之前,也就是在vision transformer出现之前,很难有什么很好的办法能把这个预训练的目标检测器移除掉。所以说最早期的工作,比如说这个分类A,就有一些VSE或者VSE++的工作,他们的文本端,就是直接抽一个文本特征,但是他们的视觉端,就非常的大,就是说它需要的这个计算量非常的多,因为它是一个目标检测器。然后当得到了这个文本特征和视觉特征之后,他最后只能做一个很简单的,这个就是模态之间的交互,从而去做这种多模态的任务。那后续这些工作,也就这个分类C的工作,就像我们耳熟能详的这个OSCAR,ViLBERT,UNITER。他们发现,对于这种多模态的任务来说,最后的这个模态之间的交互,是非常重要的。
只有有了这个模态之间更深层的这个交互,对于这种VQA,VR,VE这些任务来说,效果才会非常的好。所以他们,就把最初的这种简单的点成的这种模态之间的交互,就变成了一个transformer encoder,或者变成别的更复杂的模型结构去做这种模态之间的交互。这些方法的性能,都非常非常的好,但是,随之而来的缺点也很明显,就是说所有的这一系列的工作,它通通都用了这个预训练的这个目标检测器。最后再加上这么一个更大的模态融合的部分,这个模型不论是训练还是部署都非常的困难,所以说,当vision transformer出来之后,ViLT这篇论文也就应运而生了,因为他们发现,在vision transformer这种基于patch的视觉特征(分类D),其实跟之前这种基于Bounding Box视觉特征的算法,也没什么太大的区别。它也能很好的拿来做这种图片分类,或者目标检测的任务,那这样,我们就可以把这么大的一个预训练好的这个目标检测器,直接就换成一层patch embedding,就能去抽取这个视觉的特征了,所以大大的降低了这个运算复杂度,尤其是在做推理的时候。但是,如果你的文本特征,只是简单的tokenized一下,视觉特征,也只是简单的patch embedding一下,那肯定是远远不够的,那所以对于多模态任务来说,这个后面的模态融合非常关键,所以ViLT(分类D),就把之前C类里的这些方法的这个模态融合的方法,直接借鉴了过来。用一个很大的transformer encoder,去做这种模态融合,从而达到了还不错的这个效果。
那因为移除掉了这个预训练的目标检测器,而换成了这个可以学习的这个patch embedding layer,所以说ViLT模型,极其的简单。
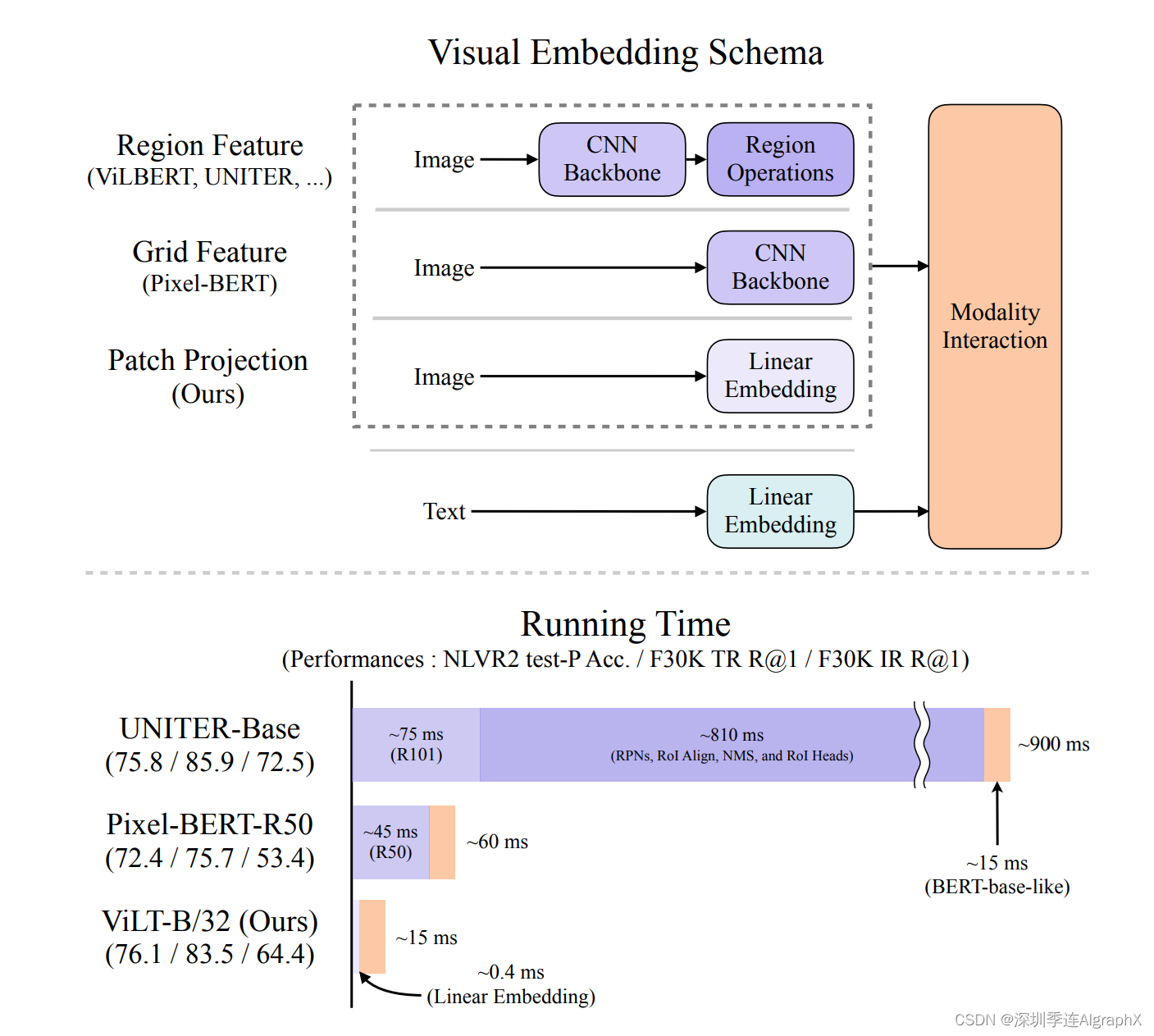
它虽然作为一个多模态学习的框架,但其实就跟NLP那边的框架没什么区别,无非就是先tokenized一下,直接扔给transformer去学习了,所以非常的简单易学。
但是,ViLT也有它自己的缺点,那首先第一个缺点就是它的这个性能不够高,ViLT在很多任务上是比不过C类里的这些方法的,原因,之前其实我们也讲过很多遍了,对于现有的这些多模态任务而言,有可能是这个数据级的bias,也有可能是这个任务就需要更多的这个视觉能力,但总之,我们是需要更强的这个视觉部分。简单来说,就是我们视觉的那个模型应该要比文本的那个模型要大,最后的这个效果才能好。但是在里,文本端用的tokenize其实是很好的,但是visual embedding是random initialized,所以它的效果自然就很差。其次,ViLT虽然说它的这个推理时间很快,但其实它的训练时间,非常非常的慢。我们后面也会提到,在非常标准的一个4m set上,需要64张,32G的GPU训练3天,所以他在训练上的这个复杂度和训练上的这个时间,丝毫不亚于这个C列的方法,是有过之而无不及。所以它只是结构上简化了这个多木态学习,但没有真的让这个多木态学习,让所有人都玩得起。所以基于这两个局限性,其实今天我们要讲的第一篇论文ALBEF就已经呼之欲出了。
不过在讲之前,我们还是要快速的回顾一下这个CLIP。CLIP模型,也是非常简单的一个结构(分类B),它是一个典型的双塔模型,就是它有两个model,一个对应文本,一个对应视觉,然后在训练的时候,就是通过对比学习,让这个已有的这个图像文本对,那这个在空间上拉得更近,然后让不是一个对的那个图片文本,就拉的尽量更远,从而最后学到了非常的这个图像文本特征。然后一旦学到很好的这个图像文本特征之后,,只需要做这种很简单的点成,就能去做这种多模态任务。尤其是对那种图像文本匹配,或者图像文本检索的这种任务来说,CLIP简直就是神一样的存在。因为它不光效果好,而且很高效。因为往往你去做这种图像文本匹配,或者图像文本检索任务的时候,你是有一个很大的已有的数据库的,这个时候,如果你新来一张图片,或者新来一个文本,你要去跟已有的数据库去做匹配。那其他所有的方法,比如说这里的A,C,D呀,都会非常的慢,因为它所有的数据都要过一遍这个编码器,但是CLIP模型,就不用,它可以提前把那个数据库里所有的这个图像文本的特征,提前都抽好,而且是想什么时候抽就什么时候抽,抽好放在那儿就行了,等你真正想用的时候,直接就做一个点成就好。那矩阵乘法还是相当快的,所以说CLIP的这个实际应用非常的广泛。但是CLIP模型,也有它自己的缺陷,它虽然对这种图文匹配的任务非常在行,但是对别的任务,比如说VQA,VR,VE这些任务来说,它的性能就不够好了,因为毕竟光靠一个简单的点乘,还是不能够分析特别复杂的情况。那回顾到这儿,我们现在就来捋一捋,总结一下之前的这些方法,哪些是好的,哪些是不好的,那我们接下来,该提出怎样的改进?
首先,我们就来看这个模型的结构。
那因为我没有图像的输入和文本的输入,那刚开始的模型,肯定是有两只的,因为他要去抽这个图像文本特征,但是我们一直都在强调,在这个多模态学习里,这个视觉特征远远要大于这个文本特征。所以我们知道,使用这个更大更强的这个视觉模型,比如说一个更大的这个ViLT是好的,这我们需要坚持使用的,同时,作为这个多模态学习,这个模态之间的融合,也是非常关键的,我们也要保证这个模态融合的这个模型,也要尽可能的大。那所以总结完了之后,我们就大概知道,最后如果想做一个很好的这个多模态学习,它的这个网络结构,就应该很像这个C,也就是说,它这个文本编码器,应该比这个图像编码器要小。然而这个多模态融合的这个部分,要尽可能的大。当然这里的这个视觉模型,肯定不想要再用一个这个目标检测模型了,所以更多的,是我们会采取一个比较大的这个transformer,而不是简单的一个patching embedding去做,总之,模型结构,大概就是长这个样子。
那模型有了,接下来该怎么去训练?那之前我们知道,这个CLIP模型,就用了一个这个对比学习的loss,也就是这个Image text contrastive,ITC loss效果就经很好了,所以我们知道,这个ITC loss应该是不错,而且也很高效,我们应该采纳。那对于之前C类的这种方法,他们往往因为有这个目标检测,所以他们提出了一个loss叫做word patch Alignment,就是这个文本的一个单词和这个图像上的一个patch,它应该有一个这个对应关系。但是,因为现在这个目标检测模型已经没有了,而且,在ViLT里头我们发现,这个wpa loss算起来是非常的慢,所以才导致这个ViLT模型训练起来这么费劲,所以我们就不太想要这个wpa loss了。然后剩下,常用的还有两个loss,一个,就是这个我们耳熟能详的mask language modeling,也就是BERT的训练方式,遮住一个词,然后再去预判这个词,完形填空,那这个loss肯定是非常有用,因为到现在为止,不是NLP还是vision,基本都大一统的全都用mask modeling,那另外还有一个image text matching loss。在之前的C和D的这种方法之中,都取得了很好的结果,所以我们也想继续采纳。那我们这轮总结完之后,我们就会发现,可能对于一个好的这个多模态学习的模型结构来说,我们的目标函数,应该也就是这个ITC,ITM和MLM这三个的这个合体,最后的效果应该就不错。
那现在,如果我们直接跳过来看ALBEF的这个论文的模型结构。其实就会发现,我们通过总结做出来的这些预测,基本都是正确的。

比如从模型结构来说,在图像这边的这个编码器,其实就是一个12层的这个transformer base model,但是,在文本这边,它把一个12层的一个BERT model,劈成了两个部分,前半部分就是前六层,拿来做这个文本的编码器。后面的这六层,用来去做那个多模态融合的编码器。所以这就满足了我们刚才做的两个假设,第一个假设,就是这个图像编码器会比文本编码器要大,因为这边是12层transformer block,这边只有六层transformer block。那另外一个,就是模态之间的融合也必须要大,所以这里面,并不是一个简单的点,而是使用了六层的这个transformer block。所以这就跟我们之前做出来的假设,这个模型结构是一模一样的。
那另外从这个目标函数上来说,就是用了这个image-text contrastive ITC,image text matching ITM和mask language modeling MLM三个loss的合体。
那之所以,我们能通过之前的一些对比和总结,得到接下来研究方向的一些假设,而且真的被一些后续的工作所验证。这个,其实完全不是巧合,因为大部分工作的这个出发点,或者他的研究动机,其实就是在总结前人工作这个优缺点之中得到的。所以如果大家,没有一些研究的idea,或者说不知道接下来这个研究方向该怎么走的时候,还是需要去阅读更多更相关的文献。而且不光是读这些文献,更重要的,是要做一个总结,每一篇论文你都得到了什么样的insight,有什么东西是可取的,可以继续发扬光大,有什么东西是不好的,最好我能把它移除掉,通过这种不停的阅读,总结对比,不说100%吧,但绝大多数时候,都是应该能够给你一个很明确的研究方向。
那接下来,我们就开始精读今天的第一篇论文ALBEF,叫做Align before Fuse: Vision and Language
Representation Learning with Momentum Distillation。作者团队,全来自于salesforce research这个团队,在做出这个论文之后,又相继做了blip,MUST还有video那边的ALPRO那的一系列的工作质量都很高,所以大家如果有时间,都可以去读一读。
然后摘要上来就说,最近,这个就是图像文本的这种大规模的特征学习已经变得非常火爆,因为这个时候,CLIP还有Align,这些工作都已经出来了,那些基于CLIP的后续工作,都已经出来很多了,所以说这个方向,在21年的时候真的是非常非常的火,但是到现在,还是很火。作者说里说,大部分已有的方法都是用一个transformer模型,当做多模态的一个编码器,去同时编码视觉token和文本token。然后这里,作者还专门强调,这里的这个视觉token,也就这个视觉特征,其实就是region-based的这个抽象特征。因为在那个时候,大部分之前的这个工作都还是用这个目标检测器的。虽然ALBEF 跟ViLT,它的这个出发动机,都是说我不想要这个目标检测的模型,但是细节上还是有差异的。ViLT只是说用了这个目标检测模型以后,速度太慢了,我想让它这个推理时间变得更快一些。但是,ALBEF的出发的动机就不一样,但是说,你用了这个预训练的目标检测器之后,你这边的这个视觉特征,和那边的文本特征,其实不是Align,因为你的目标检测器,是提前训练好的,然后就只用抽特征,它没有在进行这种end to end的这个训练。所以这就导致,你的这个视觉特征和那边的文本特征,可能相隔的很远。那这个时候把这两个特征同时扔给这么一个多模态的这个编码器之后,有可能这个编码器就不好学,也就作者这里说了,对于这个多模态的编码器来说,可能去学这种图像文本之间的这种交互信息,就会变得很challenging。
那怎么去解决这个问题?也就是说如何在这种multi-model encoder之前,你就去把这个图像和文本的特征起来?作者这里就说,我们提出了一个这个对比学习loss,就能把这个图像和文本在fusing之前,就把它们Align上了。所以顾名思义,也就是他们论文的题目,也就是Align before fuse。那这对比 loss是什么?其实就是CLIP的那个训练loss,就是图像文本的ITC。具体,之后我们会讲,所以这个,就是论文的第一个贡献,也就是作者认为最重要的贡献,那甚至拿这个贡献来命名他们的方法。那接下来还有什么贡献,因为已经有了CLIP和ViLT这一系列的工作,所以大家都知道了,你就用patch embedding就用vision transformer就可以了,所以说ALBEF是这么做的。那自然而然,这样ALBEF也就不需要预训练的这个目标检测器,自然,输入图像也就不需要是那种目标检测需要的高分辨率的图像。但这个,因为CLIP和ViLT已经有了,所以作者就不过多复述了,那更多的,是作者要讲下一个他的contribution。
作者这里说,为了能够从这种特别noisy的这种上爬下来的数据,去有效的学习这种文本图像特征。所以作者,提出了一个方法,叫做momentum distillation,也就是这种自训练self-trainning的方式去学习,那自训练,你一听,大概率其实就是用pseudo label,也就用伪标签,那伪标签从哪儿来?肯定得是有额外的一个模型,去提供这个伪标签。那在这篇论文里,就是除了已有的模型之外,作者还采用了MoCO那篇论文里提出的,这个momentum encoder的形式,从而使用这个momentum model去生成这种pseudo-targets,从而达到一个这个的结果。那这个noisy web,到底有多noisy?它为什么是noisy的?是因为,所有这个图像文本对儿,就是从网上直接爬下来这些图像文本对儿,在很多情况下,它那个文本,并没有很好的去描述这个图像。能从网上大规模爬下来的那些文本,其实它有名字,叫做alt text,就是另外一种形式的文本。他并不是说,如果你有一幅,青山绿水的画,上面有几个人在玩,他就会说,有几个人在一个山下面玩,旁边有一个小溪,他是不会这样去写的。因为这样的文本,不具备关键词,也就是说对于那些搜索引擎来说,它就不具备价值,对于搜索引擎来说,最具备价值的东西,都是关键词,就是它需要的,比如说你喝的饮料,你不能说我在喝饮料,你得说我在喝可口可乐,或者你得再说我在喝冰红茶,或者是哪个牌子的冰红茶。这样子,当大家去搜的时候,他就会搜到这张图片。
同样的道理,你去哪个著名的旅游景点,打卡的时候,你也不能说我看到了一座山,也不是搜索引擎想看到的,他想看到的是你去了哪座山,你去了哪个旅游景点,所以这个时候,其实从搜索引擎下来,下下来的这些图片文本段,它里面的文本,都是这种具备搜索属性的,但是不是那种特别好的描述性的一个句子。他有时候,甚至真的没有去描述这张图片里是什么内容,他可能就是一些关键词,一些hash tag,所以说这里作者为什么想要去解决这个问题,因为你的数据如果大多数都是这种很noisy的数据,对的话,那可能不太能学到一个很好的这个文本特征表示,事实上,作者不光在ALBEF里这么做,他在后续BLIP的里头也是这么做的。他也针对这个问题,他去设计了一个模块,叫做caption filtering,这个我们下一期会讲到去解决这个noisy web data的问题,同样,还有很多其他的论文,也针对这个noisy的问题,提出了很多不同的解决方式,但总之,我就是解释一下,这里为什么会有这个noisy web
data的问题。其实之前,我记得有一篇论文做了这个数据清洗的工作,他们当时,就是把那个YFCC100M那个数据集给清洗了一下。只通过很简单的一些方式,直接就把100m给筛选到15m,就是把5/6的数据都筛掉了,都是noisy的,只有1/6,可能质量还比较高,可以用来训练,所以可见,这个noise的程度是非常高的。
好,那说完了文章的两个contribution,第一个contribution,就是Align before fuse,其实就是用了CLIP里的这个contrastive loss,第二个contribution,就是为了克服这个noisy data,提出了一个用momentum model去生成pseudo-target,从而做这种自训练的方式。
然后作者,就是通过这个互信息最大化的这个角度,去做了一些理论分析。
结论就是说,文章里的这些训练的目标函数,包括LIM,ITM呀,还有就是momentum distillation,其实他们最终的作用,都是为同一个这个图像文本段,去生成不同的这个视角,其实也就是变相的在做一种这个data augmentation。从而让最后训练出来的模型,具备semantic preserving的功能,就是说只要是语义匹配的这个图像文本对,它就应该被当成是一对。
那contribution也说完了,理论分析也做了,最后,就是秀一下结果。
作者这里说,在这个图文检索的任务上,ALBEF的效果,是最厉害的。它比之前的方法,尤其是有一些模型,在这种特别特别大的数据之上训练过的模型,其实说的就是CLIP的性能,还反超他们。然后在VQA和VR这些任务上,也比之前的这个SOTA,绝对的提升了2.37%,还有3.84%的这个准确度,而且这个推理时间也更快。最后,代码其实也开源。
他们的这个模型,在正规的那个4m的训练数据集下,能做到一个8卡机,可能是训练三四天的时间,已经是多模态学习里头比较亲民的,或者说最亲民的一个方法了。
所以其实我这边很多后续的工作,也全都是基于ALBEF做的。那因为是论文串讲,所以说这个引言部分,和相关工作部分,我就直接跳过了,我们直接来看文章的这个主体方法部分第三章。
那3.1和3.2,分别讲了这个模型的结构,以及模型在一训练的时候用的三个这个loss函数。
这些内容,其实我们通通可以通过下图能了解到。
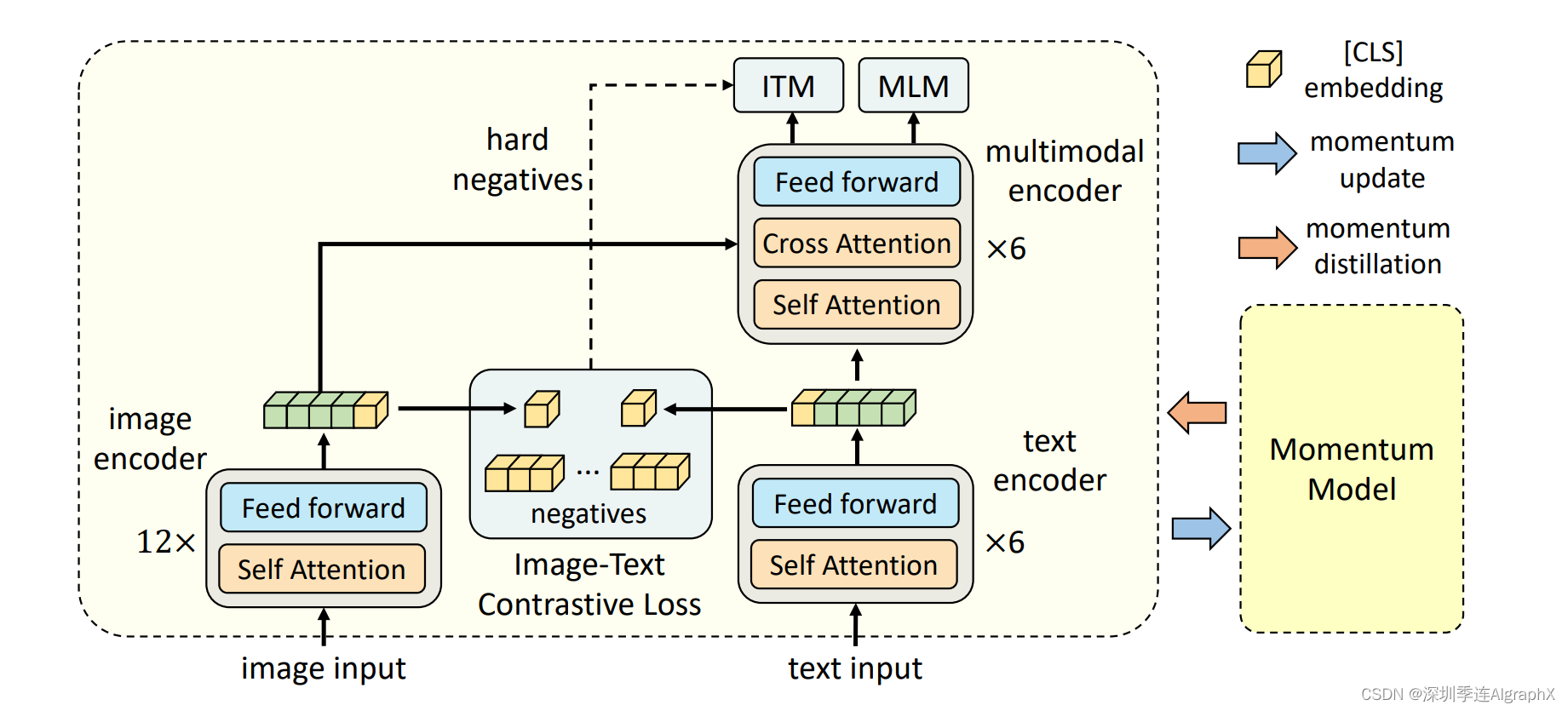
方便阅读,再附上ALBEF模型架构图。
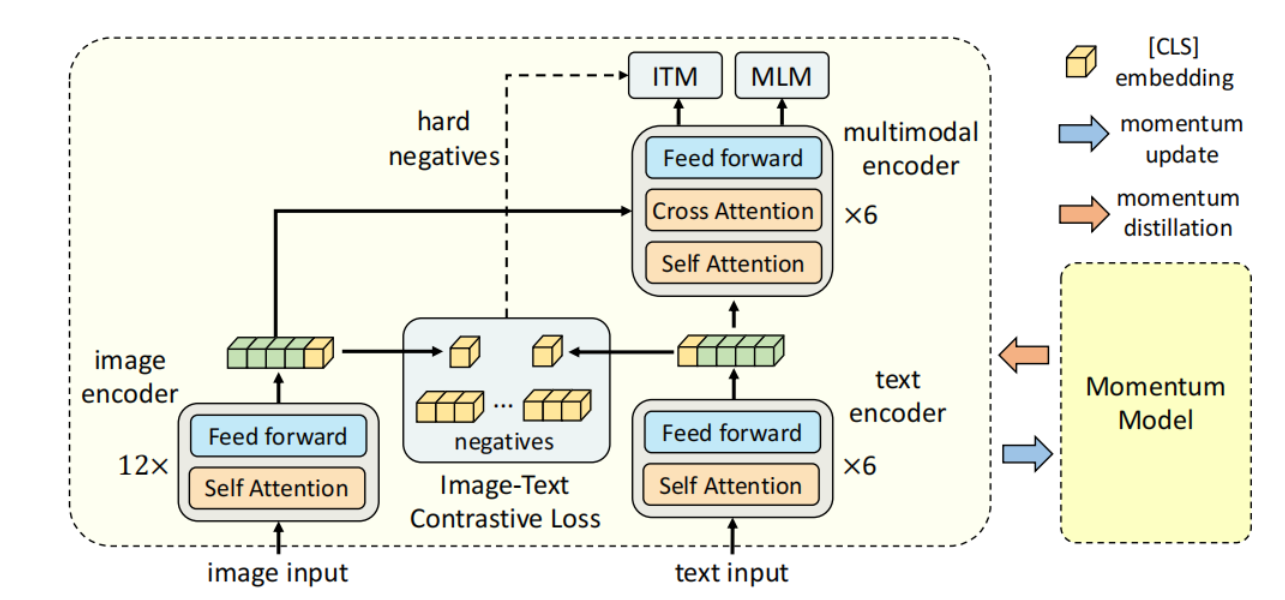
那我们先来看模型结构,那其实刚才也大概说过了。那现在,我们就讲的更细致一些。首先我们来看一下图像这边,就是给定任何一张图片,按照vision transform的做法,我们就把它打成patch,然后通过patch embedding layer,然后送给一个vision transformer。那这里,其实这就是一个非常标准的12层的rvision transform的base模型。那如果这里的图片是224*224的话,那我们之前也说过,那它这里的这个sequence length,就是196,然后加上额外的一个这个cls token,那就是197。然后它的这个特征维度是768,所以说这里面这个绿黄色的这个特征,就是197*768。在这篇论文里,作者也说了,在预训练阶段,他们用的这个图片,是256*256,所以说这里这个绿色的这个sequence length,就会相应的再长一些,但总之,这个transformer的模型,是没有什么可讲的,就是非常标准的。而且它的这个预训练参数,其实也就是用的DEiT,也就是data efficient vision那篇论文里,再ImageNet 1k数据集,训练出来的一个初始化参数。
那文本这边,其实就有点儿意思。
那按道理来说,如果你先把ALBEF这个模型,看成是一个CLIP模型的话,那其实就是左边一个vit,右边一个BERT model,那如果你在这上,直接做对比学习的话,它就变成CLIP了。
但是我们刚开始在介绍的时候也说过,这个多模态的任务,它就必须得有一个多模态的这个融合的一个过程。如果你只是单纯的有一个图像模型,然后还有一个文本模型的话,,没有这个多模态特征的融合,他做这些VQA,VR任务的时候,效果就不会很好。那有人可能就会说,那我就在这个一个vision transformer和一个BERT model上面,我再加一个这个multi-model编码器不就行了吗?当然也是可以这么做的,但这样,你的计算量就进一步加大了,而且我们之前也提到过,说这个视觉模型,是应该比这个文本模型要大一些的。这样他在做模态的这些任务上,效果才会好,那所以综合这两方面考虑,最简单直白的一种方式,那就说我把文本这边的这一个大模型,给劈开,劈成两个部分。我只用前六层,去做这个文本编码,因为本来我就希望这个文本编码器的比这个图像编码要弱一些,然后把剩下的那六层encoder,就直接当成multimodal encoder。这样一举两得,跟之前的方法,保持同样的计算复杂度,但是我满足了之前总结出来的这个最优配比。至于文本模型这边,其实它就是用一个模型去做的这个初始化,然后它中间的这个特征维度,也是768,然后它也有这么一个CLS token,代表了整个句子的这个文本信息。
除了有vit和BERT这份模型参数之外,它还有对应VIT和BERT另外的一份模型参数,右边的这个模型参数,是由这边在训练的模型参数,通过moving average得到,也就是这个momentum model这个,就跟MoCo是一模一样的。通过把moving average的那个参数设的非常高,在论文里是0.995,从而来保证这边的这个momentum model不会那么快的更新,所以说它产生的特征,就更加的稳定,不仅可以拿来做更稳定的这个negative sample,而且还可以去做这种momentum distillation。这个具体,我们会再回头在momentum distillation里提到。总之整个模型结构,就是长这个样子了。
那接下来我们就来说一下这个目标函数。
首先我们就来说一下最开始遇到的这个ITC loss。那说到对比学习,我们之前就知道,只要你能定义一个正样本对,然后定义很多负样本对,然后我们就可以去对比了。我们希望这个正样本队之间的距离越来越近,希望正负样本队之间的距离越来越远。首先我们要做的,就是去抽取这种全局特征,然后在这个特征之间,去做这种embedding space上的这种拉近和拉远。那在ALBEF里,首先一个图像i,它通过这个transformer之后,就会得到这些的特征,那这里我们把这个黄色这个CLS,也就当它的这个全特征,就是一个768*1的一个向量。那文本这边,也一样,先是tokenization之后,就把这个文本text变成一个tokenization的序列,然后我们把它扔给BERT前六层,得到了一系列的特征,那这边的,也就当了这个文本的全局特征,是一个768*1。那接下来的操作,跟MoCo是一模一样的。首先我们先做一下downsample和normalization,就把这个768*1,变成了256*1的一个向量,同样的这个文本这边也是768变成256*1。那一旦你有了这个正样本的两个特征,就是这两个特征,你就希望他尽可能的近。那它的副样本,全都存在一个Q里,这个Q里有65536,这个副样本,就很大很大的一个Q,但因为它没有gradient,因为它是由这个momentum model产生的,所以说它并不占很多内存。那这样,因为你有很多很多的这个负样本,然后,你通过这种正负样本之间的这个对比,你就可以去对这个模型进行第一阶段的学习了。
这其实也就是作者在这篇文章中说的Algin before Fuse的Align,也就是说,在我们把这个图像特征和这个文本特征扔到这个multi-model fusion的encoder之前。我就已经通过这个ITC loss,这个对比学习的Loss,让这个图像特征,文本特征尽可能的拉近了,尽可能的在同一个embedding space。那因为这里的ITC loss的这个实验,是完全按照MoCo来的,就是算了一个cross entropy loss,所以这里我就不过多述。有了这个ITC loss之后,其实这个vision transformer的12层和这个BERT的前6层其实都可以练了。但是,这个BERT后六层,也就是这个多模态的这个融合部分该怎么办?我们就先说ITM loss,Image text matching,其实很简单,就是说你给定一个图片,给定一个文本,然后这个图像文本,通过这个ALBEF的模型之后,就会出来一个特征,那在这个特征之后,加一个分类头,也就是一个FC层,然后我去判断到底这个I和T是不是一个对,那说白了,这个ITM,就是一个二分类任务。那这个loss,虽然听起来很合理,我们确实应该用它,但是实际操作的时候,你会发现这个loss,太简单了。因为判断正样本,可能还有点难度,但是判断谁和谁是负样本,这个就太简单了。因为如果你不对这个负样本做什么要求,那基本上很多很多的这个图片文本,它都它都可以当成是现代图像文本的副样本。所以这个分类任务,很快它的准确度就提升的很高很高,那在预训练的时候,训练再久其实也没有任何意义了。那这个时候,一个常见的做法,就是说我在选这个副样本的时候,我给他一些constraint,那在ALBEF这篇论文里,那就是采取了最常用的一个方法,就是通过某种方式,去选择最难的那个副样本。也就是最接近于正样本的那个副样本,具体来说,那在ALBEF这篇论文里,他的这个batch size是512。那对TIM这个loss来说,它的这个正样本就是512个。那对于这个mini batch里的每一张图像,我去哪找它的这个hard negative文本?这个时候,ITM还依赖于之前的这个ITC,他就把这张图片,和同一个batch里所有的这个文本都算一遍这个相似度cosine similarity。然后他在这里,选择一个除了他自己之外,相似度最高的那个文,当做negative。也就是说,其实这个文本和这个图像,已经非常非常相似了,它基本都可以拿来当正样本用,但是我非说它是一个负样本,也就是hard negative的定义。
那这个时候ITM loss就变得非常challenging了。
那最后一个目标函数?就是我们耳熟能详的mask language mode,BERT里用的完形填空。那其实,就是把原来完整的句子,这个text 的t变成一个t’,也就是说有些单词,被mask掉。然后他把这个缺失的句子,和这个图片,一起通过这个ALBEF的模型,然后最后去把之前的这个完整的句子给预测出来。那在这里,其实它不是像NLP那边单纯的一个MLM了,那其实,也借助了图像这边的信息,去帮助他更好的恢复这个那个单词被mask。但这里,有一个小细节,很值得关注,就是说,在我们算这个ITC loss和这个ITM loss的时候,其实我们的输入都是原始的i和t,原始的i和t。
但是,当我们算这个loss的时候,它的输入是原始i,但是是mask的t’。这意味着什么?这说明ALBEF这个模型,每一个训练的,其实它做了两次模型的forward,一次模型的forward,是用了这个原始的I和T,一模型的forward,是用了原始的i和mask的t’。当然了,不光是ALBEF这篇论文,会有这种多次前向的这个过程,其实ViLT,包括之前的很多模型,他都会做好几次前项,甚至做三次前向过程。这也是其中一个原因,就是为什么多模态学习普遍的方法,它的训练时间都比较长。因为他为了算好几个不同的loss,他还得做好几次不同的forward,去满足各种各样的条件。
那到这儿,3.1和3.2节就讲完了,最后我们可以看到,这个ALBEF的所有在训练时候用的这个目标函数,也就是ITC和ITM,MLM的这个合体。
那说完了模型结构,和所有的这个目标函数,接下来我们就来说一下这篇文章的另一个贡献,也就是这个momentum dation,动量蒸馏。
那作者上来就先说,他为什么要做这个动量蒸流,他的这个动机是什么?,主要就是这个noisy web。这个其实我们在讲摘要的时候也说过了,就是从网上爬下来的这些正的这个图像文本对,其实它经常都是这个weakly correlated,就他们之间的关联,不是那么强,有的时候,甚至都不匹配。经常的情况,就是说它里面的那个文本,有的时候会包含很多单词,就是说其实跟这个图像没什么关系,或者说这个图像里,也包含很多的物体,但是在这个文本里,并没有得到体现。那这个时候,这种noisy的会造成什么影响?那主要就是在算这个目标函数的时候,这个有时候就会有偏差。比如说我们在算这个ITC,就是对比学习的loss的时候,对于一张图片来说,它的这个所谓的样本文本,其实很有可能也描述了这个图像里的很多内容。它可能不是下来的那个ground truth one hot的那个image text pair,但是其实这个文本可能已经很好的描述了这个图像,甚至可能比ground truth描述的还好。但是,我们非要把它当成是一个副样本,那这个时候就会对ITC的学习造成很大的影响。另外,对于这个MLM loss来说,完形填空,那其实我们做过那么多年的完形填空也知道,有很多时候,这个空里是可以填很多单词的。有的时候,是会存在这种比ground truth还要描述这个图片更好,或者说差不多好的这个文字出现的。所以综合这些考量,作者最后的结论就是说你用这种one hot label,就是你从网上爬下来的,就是这个图片和这个文本就是一对,其他跟他都不是一对的,这种one label对于ITC和MLM这两个loss来说,是不好的,因为有的副样本,也包含了很多很多的信息,一味的在loss的时候去惩罚这些副样本,其实会让模型的学习非常的困难。那既然这个问题,是由这个noisy data里的one label带来的。那很直接的一个想法就是说,我如果能找到额外的这个监督信号,最好,它不是one hot,它是multi hot,或者说它就是另外一个模型的这个输出,不就好了吗。那这个时候,这两年比较火的一种方式,叫做self training,就是自训练。就很自然的,能够应用到这个场景里来解决这个问题。从最开始的nosiy student,在ImageNet上把分刷得的那么高,还有到最近自监督的这个DINO,其实也算是一种自监督模式。所以说作者这里,也就采取了这种方式,就是先构建一个momentum model,然后用这个动量模型,去生成这种pseudo-targets。
那具体这个动量模型是怎么构建的?那其实就是在有的模型之上,去做这种exponential-moving-average,EMA这个技术,其实是很成熟的,现在大部分的这个代码库里,都是支持这个EMA的,包括这个DEiT, Swin transformer都是自带的。它的目的,就是说在这个模型训练的时候,我们希望在训练原始的这个model的时候,我们不光是让它的这个预测,跟这个ground one hot label去尽可能的接近,我们还想让他这个预测,跟这个动量模型出来的这个pseudo-targets去尽可能的match。那这样,就能达到一个比较好的折中点,就是说很多的信息,我们从one hard label里去学,但是当这个one hot label是错误的,或者是noisy的时候,我们希望这个稳定的momentum能够提供一些改进。那具体,我们现在拿ITC loss做个例子来说的话,原来我们的ITC loss就是这个LIC。但是因为,它是基于这个one hot label,所以这个时候,我们想希望再算一个pseudo-target loss,去弥补他的一些缺陷和不足。那最后,因为我们有两个loss,一个是原来的这个ITC,一个是基于pseudo-target的ITC,就得到我们这个momentum版本的这个ITC loss。
那同样的道理,对于这个MLM来说,它也是用这个新生成的pseudo-garget,去代替了原来的ground truth。所以在原始的这个MLM loss之外,我们现在又有一个新的,基于这个pseudo-target的这个MLM loss。所以最终,ALBEF的这个训练,其实有五个,就是有两个ITC,两个MLM,一个ITM。
那这个时候大家可能会想,为什么IM loss我们不也给他一个自训练,给他一个这个动量模型的版本?是因ITM loss本身是基于ground truth的。
那到这儿,其实文章的这个主体方法部分就讲完了,两个contribution,一个是Align before fuse ,另外一个是momentum distillation,接下来,我们就来快速过一下,文章预训练时候用的数据集,那这个下游任务的一些任务描述和数据集,以及最后的一些实验结果。
那接下来,我们就看这个3.4,在预训练的时候使用的数据集,这个还是比较标准,作者上来就说,我们是follow这个之前的这个uniter。他们,一共用了四个数据集来预训练,分别是Conceptual captions ,SBU caption,coco和visual genome,加起来有400多万张图片,那但这里面,有两个点值得说一下,第一个点,就是虽然coco和visual genome是原来的作者,就已经提供了这个数据,所以你永远都可以下到原始版本的数据,谁都不会缺少,但是,对于前面这两个这个CC和SBU个数据集来说,原来的那个论文作,只是提供了一个URL。大家每次下载的数据可能不一样,所以说这里面,也比较trick。就是你预训练的时候用的数据,应该和别人都不一样,每个人和每个人都不一样。但因为这个数据集,本身也比较noisy,所以你有的时候差个几万个这个图像文本,对,对最后的这个训练影响,也不是很大,但如果你差个几十万,那其实一般还是会有一些影响。所以以后,大家如果想做什么任务,看到一个什么新的数据集,不管你做不做,如果感兴趣的话,你可以先把这个数据集下着,免得以后真想做这个数据集的时候,因为缺失数据,所以总比不过别人的分。那第二个想强调的点,就是说对于前面这两个数据集来说,它都是一个图片,对应一个文本。但是对于后面这两个数据集来说,它其实是一个图片,对应好几个文本。那比如说像coco这里,一张图片,就对应了五个文本,所以也就是作者这句话说的意思,就是说这个不一样的图片,一共有400多万,这个是对的。但是,其实这个图像文本队,有500多万。那多出来的这100多万的这个图像文本对,其实就是因为这个coco和visual genome,每个图片它都有额外的这个文本所导致。然后最后作者,还做了一个实验。如果你扩大这个数据集,就是用更noisy更大的一个数据集去训练的时候,是不是就能获得更大的成效?那在这篇论文里确实如此,当他们使用了这个CC12m的时候,,就是第五个数据的时候,他们把这个数据集,总共就扩大到14m这么大,就跟ImageNet 21K那么大,这个时候,他们在各个下游任务上的性能,又猛涨了一波。
总之,在这篇论文里,他的这个预序列数据集,就有两个setting,非常标准,一个就是这个4m的setting,就是有四个数据集。一个,就是这个14m的setting,就是把这个CC12也加进去了。两个settinging,是最常被用的,包括之前19年20年,一直到现在22年,都是比较常用的。当然了,现在这个医学院数据集,规模也越来越大,大家很多人,已经不满足于使用,就是只有14m这么多图像文本对了,这个开源的这个LAION,已经有了400m,而且已经有了2B 5B这么大的数据集。所以以后这个多模态的预训练方面,可能不是一般人能玩得动的了。
那说完了预训练用的数据集,后面就是做的任务文章前后做了五个任务,不复述。
最后,终于到了这个看结果的时候,作者首先,是做了一个这个消融实验来验证,他们文章里提出来的这么多东西,到底哪个有用,哪个没用。消融实验,一般也是我最爱看的部分,因为可以得到很多有用的insight。
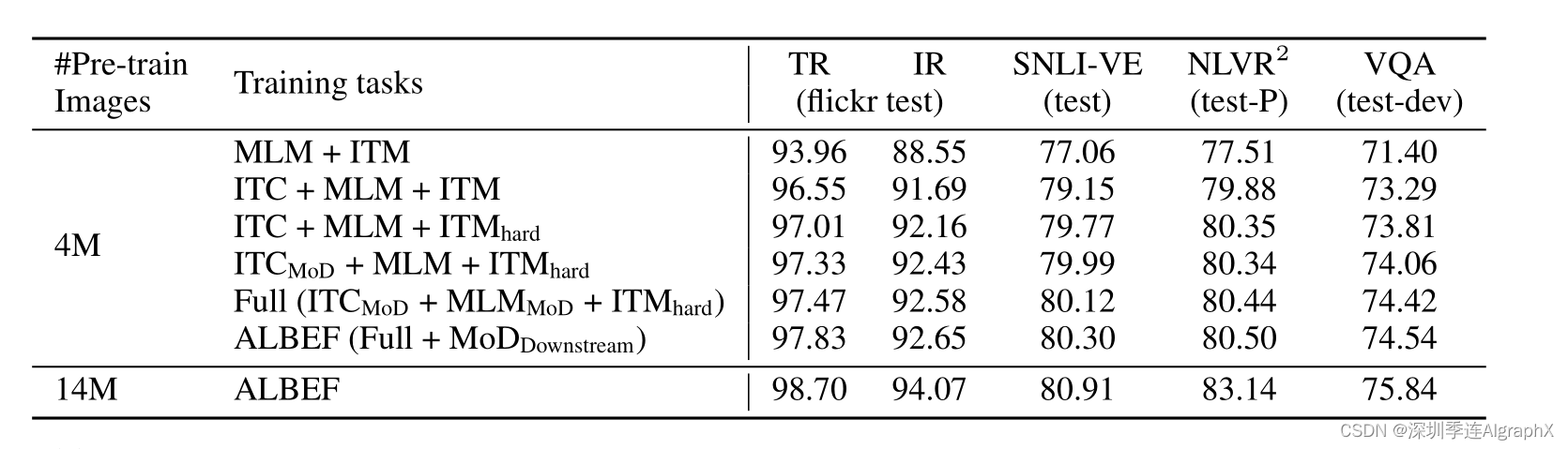
那首先作者,用了MLM和ITM training loss当做了基线,因为基本上所有的之前的工作和现在的工作,里面都会有这两个loss。既然所有人都有,我就可以把它当做一个基线模型去对比了。然后作者就给上面加了这个ITC,就是然后我们就会发现这个提升,是非常大的,基本这里是2或者3个点的提升。而且是在这么多任务上,这个检索IR VR VQA任务上都有明显的提升,所以这个ITC loss真的是YYDS。也就是说,这种对比学习的方式,还是很厉害。即使是mask modeling当前非常火爆的情况下,我觉得这个对比学习,还是有值得挖掘的点,或者值得继续做下去的潜力的。
那接下来的一个小贡献,就是作者在这ITM里提出的这个Hard negative。我们可以看到,大概都有0.5左右的这个提升,虽然看起来不是那么显著,但是毕竟所有任务上都有提升,所以也是相当不错的一个技巧,这个也是意料之中,毕竟在对比学习出来之后,有很多很多篇论文,大家都去研究这个Hard negative对对比学习的影响。而且Hard Negative这个概念,在很早之前就有,而且应用到了各个方面的领域,甚至是目标检测或者物体分割,里面也都有negative的应用。那最后,我们就来看一下这个momentum distillation,也就这里这个简写mod,那其实我们可以看到,如果给这个ITC上加这个mod,大概就是0.3左右的提升。然后最后,是在downstream,就是下周任务上再去做mod,然后大概,会有0.3左右的这个提升。但是这个研究方向还是很好的,怎么从noisy data里去学习有效的表征,我觉得也是一个非常有趣的研究方向。
那接下来,我们可以再快速看一下,在每个具体任务上ALBEF的表现。自己看论文,大部分省略,哈哈哈。
有一个小点,其实要说的,Flickr 30K这个数据集,其实也已经被刷爆了,我们可以看到这都已经到100了,而且COCO也已经非常的高,所以说图文检索领域,其实是需要新的数据集,也有可能是一个更大的数据集,也有可能是一个标注的更好的数据集,或者是一个视频文本的这个检索数据集。总之,这也算是一个可以填的坑。
总之,ALBEF,不论是在训练速度上,还是在推理速度上,还是在这个通用性,或者在这个性能表现上,都是非常的亮眼。
摘录
多模态论文串讲·上【论文精读·46】_哔哩哔哩_bilibili
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
https://arxiv.org/pdf/2102.03334.pdf
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
https://arxiv.org/pdf/2107.07651.pdf
VLMO: Unifified Vision-Language Pre-Training with Mixture-of-Modality-Experts
https://arxiv.org/abs/2111.02358
Masked Unsupervised Self-training for Zero-shot Image Classification
GitHub - salesforce/MUST: PyTorch code for MUST
Align and Prompt: Video-and-Language Pre-training with Entity Prompts
https://github.com/salesforce/alpro
CoCa: Contrastive Captioners are Image-Text Foundation Model
https://arxiv.org/abs/2205.01917
PaLI: A Jointly-Scaled Multilingual Language-Image Model
https://arxiv.org/abs/2209.06794