系列文章目录
【论文精读】CLIP:Learning Transferable Visual Models From Natural Language Supervision 从自然语言监督中学习可迁移的视觉模型
论文精读】CLIP 改进工作(LSeg、GroupViT、VLiD、 GLIPv1、 GLIPv2、CLIPasso、CLIP4clip、ActionCLIP)
文章目录
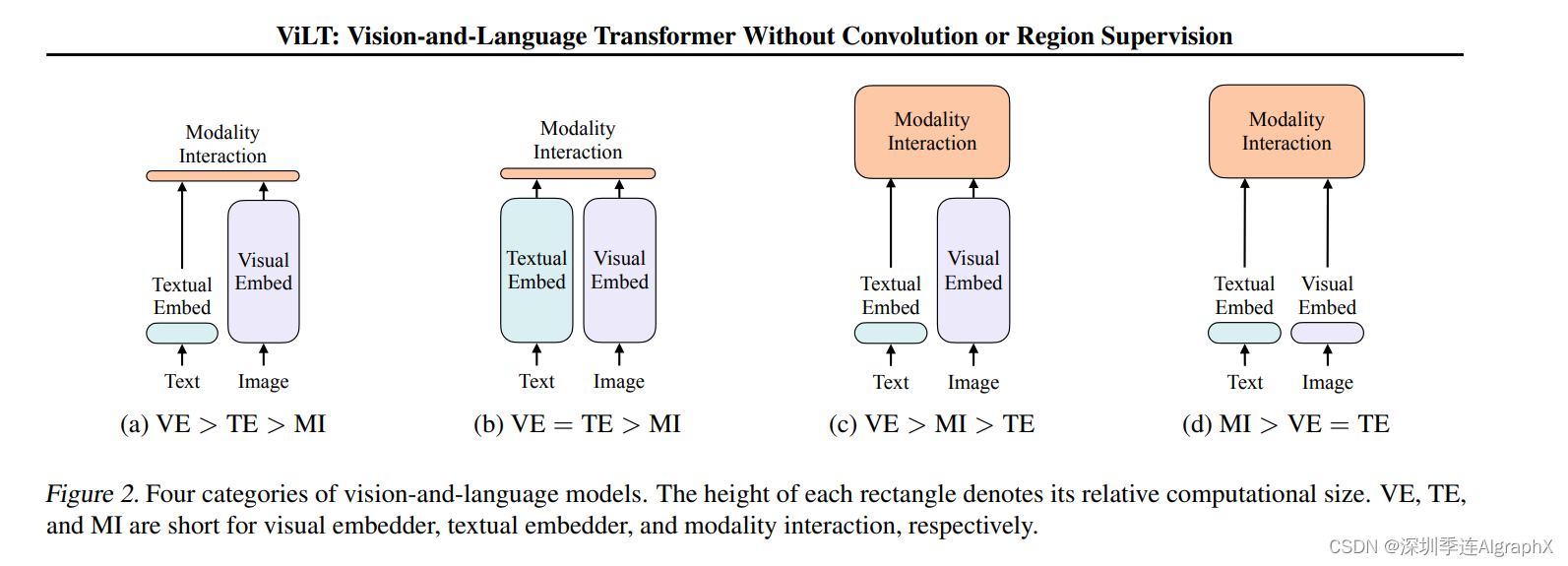
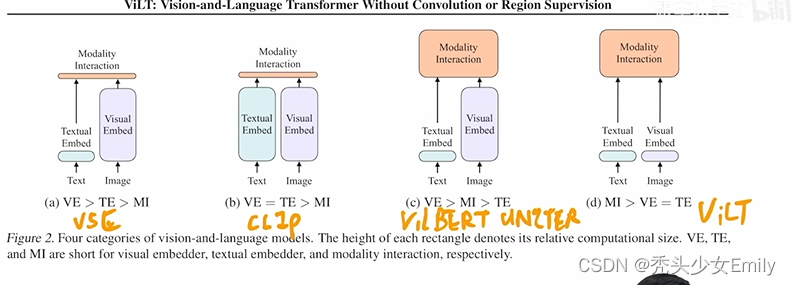
只用transformer的encoder的一些方法:CLIP、ViLT、ALBEF、VLMo
transformer的encoder和decoder一起的一些方法:BLIP、CoCa、BEIT v3、PaLI
一、ALBEF:基于动量蒸馏的视觉语言表示学习
(一)主要贡献
- 引入了一种对比损失,通过跨模态注意力在融合之前将图像和文本表示对齐(Align before Fuse)
- 类似ViLT模型采用vision transformer对图像特征进行处理,因此预训练过程也不需要目标检测器,进而不需要边界框注释或高分辨率图像
- 提出动量蒸馏(从动量模型产生的伪目标中学习的自训练方法),从而解决noisy web data的问题
(二)模型架构
图像处理:
给定任何一张图片,按照vision transformer的方法,打成patch,然后通过patch embedding layer,送进vision transformer,图像这边对应的编码器就是一个标准的12层的vision transformer的base模型
文本处理:
将12层的bert model拆分成了两个部分,前6层用于做文本编码器,后6层用于做多模态融合的编码器。
momentum model: 不仅用于完成momentum distillation,而且能够生成更多的negatives

(三)损失函数
损失函数:ITC Loss、ITM Loss、MLM Loss
ITC Loss: Image-text 对比学习损失

ITM Loss: Image-Text 匹配损失

MLM Loss:遮蔽语言模型交叉熵损失

最终的损失函数为:

(四)动量蒸馏
提出动量蒸馏的动机:
- 用于预训练的图像文本对主要是从网络上收集的,并且它们往往是有噪声的。正对通常是弱相关的:文本可能包含与图像无关的单词,或者图像可能包含文本中未描述的实体。
- 对于 ITC 学习,图像的否定文本也可能与图像的内容匹配。
- 对于 MLM,可能存在与同样好(或更好)描述图像的注释不同的其他词。
- 然而,ITC 和 MLM 的独热标签会惩罚所有负面预测,无论其正确性如何。
动量蒸馏的思想: 从动量模型生成的伪目标中学习(自训练模式)
- 这里的伪标签其实就是一个softmax score,它不再是一个one hot label了
- 动量模型的构建其实就是在已有的模型之上,去做指数移动平均(EMA)
- 训练的目的不仅仅是使得预测结果与ground truth的one hot label尽可能的接近,而且能够与动量模型生成的伪标签尽可能的匹配。


二、VLMo:混合模态专家的统一视觉语言预训练
(一)主要贡献
- 模型结构上的改进:Mixture of experts,其实就是自注意力中所有的模态都是共享的,但是在feed forward FC层,每个模态会对应自己不同的expert。
- 训练方式上的改进:考虑到视觉领域和nlp领域都有自己各自的大规模数据集,而多模态领域当时还缺乏较大的数据集,作者提出了分阶段的模型预训练方法,利用视觉数据集训练好vision expert,然后把language expert在language数据集上训练好,然后再在多模态的数据集上做pre-training
(二)模型架构
VLMo实际上也是一个transformer encoder的结构,但是在每个transformer block里做了一些改动:
- 一个标准的transformer block:一个Layer Norm+一个MSA(multi-head self-attention)+一个Layer Norm+一个FFN(feed-forward network)+一个residual
- 改动之后的transformer block的feed-forward network不是一个,而是根据不同的输入不同的模态有对应的vision FFN、language FFN、vision language FFN
VLMo的损失函数也是ITC、ITM和MLM

(三)训练方式(分阶段的训练策略)
使用纯图像和纯文本语料库进行阶段性预训练。
- vision pre-training:在大规模纯图像数据上预训练视觉专家(V-FFN)和自注意力模块,如 BEIT中所示。
- language pre-training:冻结视觉专家和自注意力模块的参数,并通过对大量纯文本数据进行掩码语言建模来训练语言专家(L-FFN)。
- vision-language pre-training:通过视觉语言预训练来训练整个模型。

三、BLIP:用于统一视觉语言理解和生成的引导语言图像预训练
(一)主要贡献
- Bootstrapping:如果你有一个从网页上爬取下来的很嘈杂的数据集,先用它去训练一个模型,然后通过一些方法得到一些更干净的数据,然后用这些更干净的数据能不能训练得到更好的模型
- unified:统一了视觉语言理解和生成的任务
(二)模型架构
BLIP模型主要包括了四个部分:
- 图像方面:一个完整的ViT模型
- 文本方面:三个模型,分别用于计算三个目标函数
- 第一个文本模型:根据输入的文本去做understanding的分类任务,因此当得到文本特征之后,与视觉特征做ITC Loss
- 第二个文本模型:是一个多模态编码器(image-grounded text encoder),借助了图像的信息,然后去完成多模态的任务,对应ITM Loss
- 第三个文本模型:(image-grounded text decoder),第一层采用的是causal self-attention(因果关系的自注意力),从而完成生成任务,目标函数基于GPT系列的language modelling,给定一些词去预测剩下的词

三个文本模型对应的token不一样:cls token、encode token、decode token
(三)Bootstrapping
采用标题和过滤策略(Captioning and Filtering, CapFilt)来提高文本语料库的质量,包含了两个模块:一个是给定网络图像生成字幕的Captioner,另一个是去除噪声图像-文本对的Filter。Captioner和Filter都是从同一个预训练的MED模型初始化的,在COCO数据集上单独进行微调。
- Captioner以LM为目标进行微调,对给定的图像进行文本解码生成caption;
- Filter以ITC和ITM的目标进行微调,以学习文本是否与图像匹配,该Filter去除原始网络文本和合成文本中的噪音文本,如果ITM头预测一个文本与图像不匹配,则该文本被认为是噪音。
将最终获得的新的干净的数据集拿来再次训练BLIP,获得的模型效果提升非常显著

四、CoCa:对比字幕是图像文本基础模型
CoCa模型结构与ALBEF模型很像,因为想做caption的文本生成,因此文本端使用的decoder
CoCa模型的两个loss:
- contrastive loss:就是ITC loss
- captioning loss:其实就是BLIP里用的language modeling loss,也就是GPT用的loss

五、BeiTv3:把图像作为一种语言
通过对海量数据进行大规模预训练,可以轻松地将模型转移到各种下游任务中。有吸引力的是,我们可以预训练一个处理多种模式的通用基础模型。以下三个方面推进了视觉-语言预训练的融合趋势:
- transformer适用于各种modality,从语言领域渗透到了视觉和多模态等领域
- dual-encoder:双编码器架构(CLIP),适合做高效检索(retrieval)任务
- encoder-decoder:编码器-解码器架构(BLIP,CoCa),适合做生成任务
- fusion-encoder:融合编码器架构(ALBEF,VLMo),适合做图像文本编码
- 预训练目标函数:masked data modeling已经成功的应用到了各类模态当中了
- 当前的视觉语言基础模型通常会同时处理其他预训练目标(例如图像文本匹配),导致扩展不友好且效率低下。
- 相比之下,文章提出的BeiTv3仅使用一项预训练任务,即“mask-then-predict”来训练通用的多模态基础模型。通过将图像视为外语(即 Imglish),以相同的方式处理文本和图像,而没有基本的建模差异。因此,图像-文本对被用作“平行句子”,以学习模态之间的对齐。
- 扩大模型规模和数据规模

BEIT3使用了多路Transformer来作为图像,文本和多模态数据的统一架构,之前大部分的工作都是各个部分有独立的子模型。这个多路Transformer其实也是微软之前的工作VLMo,多路Transformer的核心是模型的MHSA模块是共享的,而设置不同的FFN来分别处理图像(V-FFN),文本(L-FFN)和多模态数据(VL-FFN)。

这种设计让不同的数据共享了模型架构,而且还可以灵活地应用在各种下游任务中:比如对纯视觉任务,只需要用MHSA+V-FFN部分就好,而纯文本任务只用MHSA+L-FFN,而对于多模态任务和灵活地组合不同的FFN。