BERT
1.前言
self-supervised learning是一种无监督学习的特殊形式,算法从数据本身生成标签或者目标,然后利用这些生成的目标来进行学习。(也就是说数据集的标签是模型自动生成的,不是由人为提供的。)例如,可以通过在图像中遮挡一部分内容来创建自监督任务,让模型预测被遮挡的内容。self-supervised learning 应用十分广泛,不仅用于文字方面,还可以用于语音和图像上。

self-supervised Learning 自监督学习的一些模型如下:
ELMO(Embeddings from Language Models)—> 最原始的
BERT(Bidirectional Encoder Representations from Transformers)
ERNIE(Enhanced Representation through Knowledge Integration)
Big Bird(Transformers for Longer Sequences)
GPT-3 —> 有 175 billion 个参数
2.BERT结构
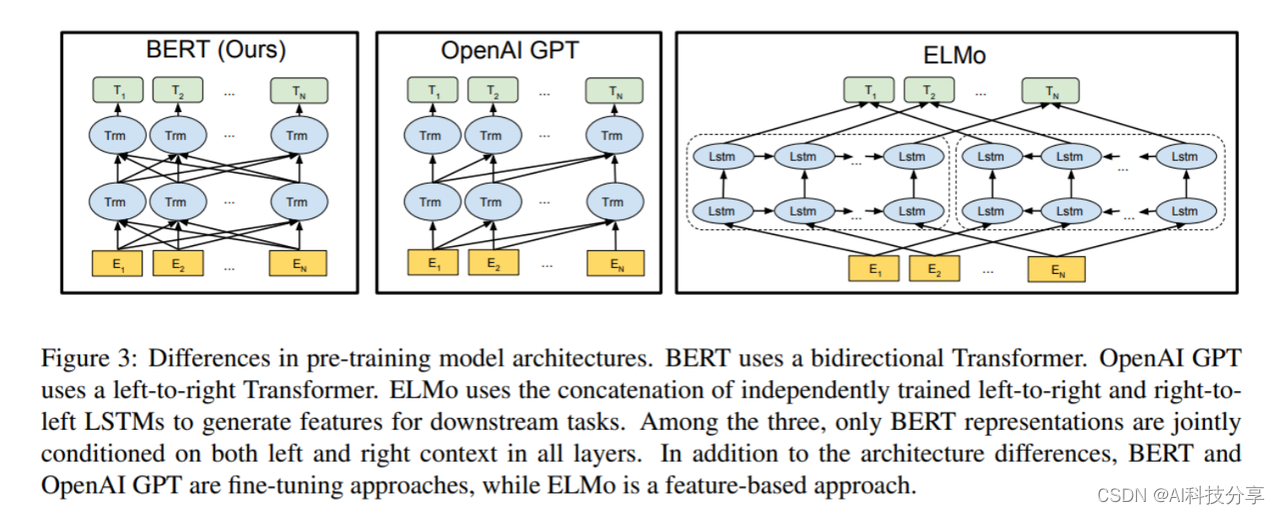
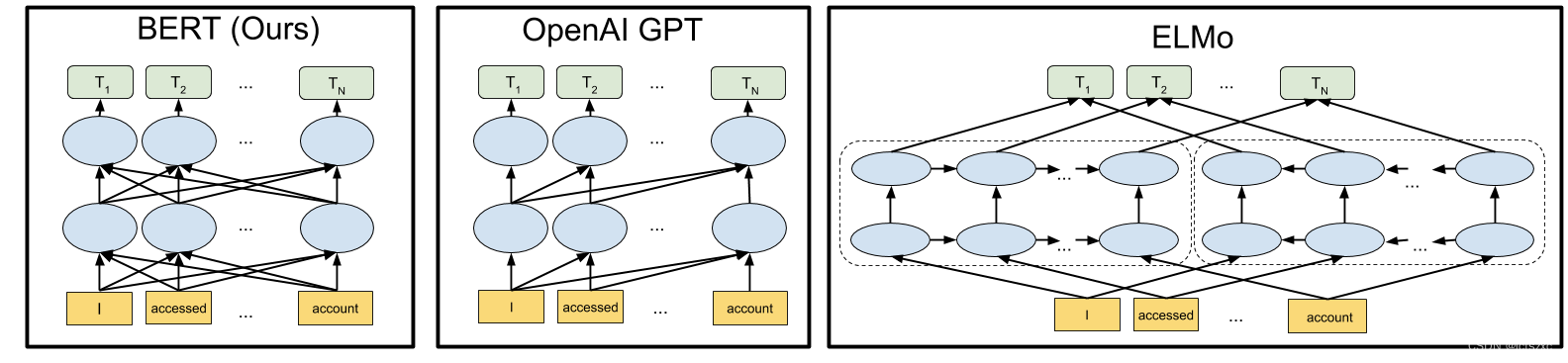
BERT 是一个非常巨大的模型,有340 million 个参数。BERT的架构就是 Transformer 的 Encoder 部分(self-attention,residual,normalization)。
训练BERT有俩种方式:Masking Input 和 Next Sentence Prediction
1.Masking Input

BERT 的输入,某些部分被随机的盖住,盖住有两种方式(随机的选择一种盖住方式):
- MASK:将句中的一些符号换为MASK符号。(这个MASK是一个新的符号,字典中没有的,表示盖住)
- Random:随机把某一个字换为另外一个字(随机从字典中挑选一个词盖住)。
输入通过BERT后就得到了对应的Sequence(但是只关注输入被盖住所输出的 vector),然后通过Linear transformer(Linear transformer的意思就是乘以一个矩阵),并进行Softmax,就可以得到一个有关所有符号的概率分布。在训练的时候,将真实值与预测出来的值进行对比,通过minimize cross entropy不断缩小损失,进而提升模型的ACU。
2.Next Sentence Prediction

从资料库里面随机选两个句子,在句子中间加入一个特殊符号 [SEP] 来代表分割。在最前面加入一个特别的符号 [CLS]。将这个整体送入BERT中,在得到的sequence中只关注 [CLS] 对应输出的vector。然后经过一个Linear transformer,来进行一个二元的预测(Yes or No),表示这两个句子是否是相连接的。
3.Downstream Tasks
Downstream tasks就是利用BERT真正做的任务。而不是上面的预测某个Masked token,或者判断两句话是否是有连接关系的任务。
BERT 分化为各种任务叫做Fine-tune,中文叫做微调。产生BERT的过程叫做 Pre-train。
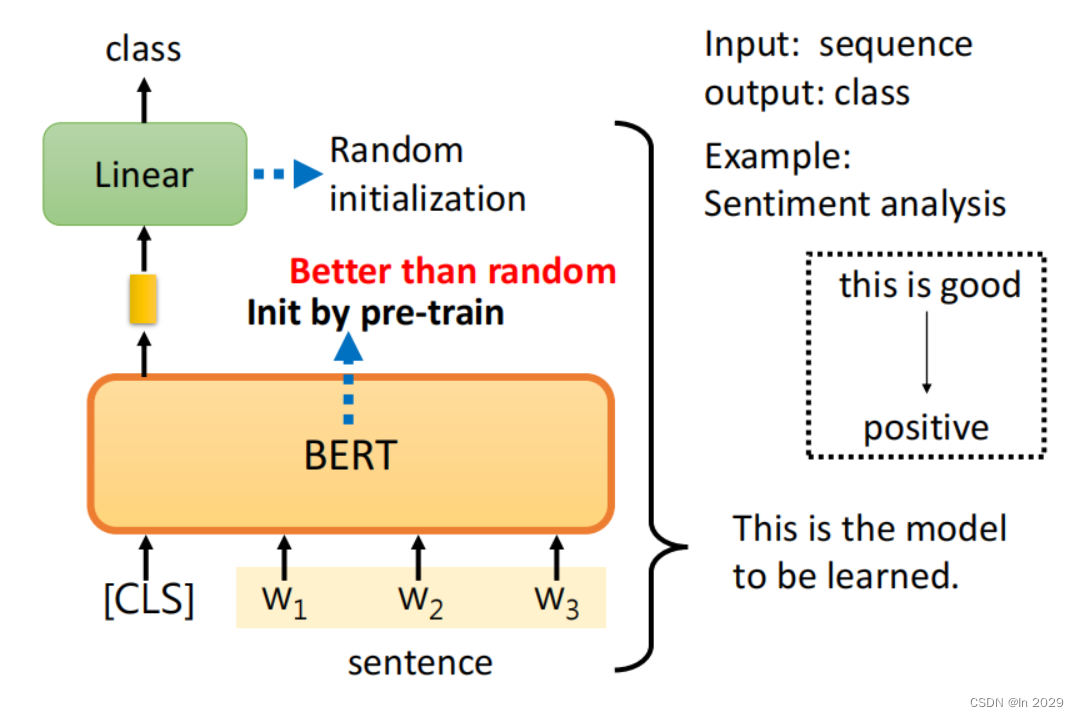
3.1 Sentiment analysis

BERT初始化用的参数是pre-train的初始化参数(也就是用于填空任务的参数),Linear用的参数是Random初始化参数。
3.2 POS tagging(词性标注)

3.3 NLI(自然语言推理)


3.4 Extraction-based Question Answering



上面的那两个向量是随机初始化的,BERT初始化依旧是利用pre-train的参数。
4.为什么BERT有用?
BERT输出的向量代表了输入的意思。具有相似含义的符号,输出具有相似的嵌入向量。而且在输出的时候还考虑了上下文,因为内部有一个self-attention的结构。

5.Multi-lingual BERT
Multi-lingual BERT是一个多语言的BERT模型,再训练BERT的时候是通过许多不同的语言训练出来的。尽管是不同语言,但是每个词的意思是相近的,所以输出的嵌入向量距离就很近,因此效果较好。

6.GPT
BERT做的是填空题,GPT做的就是预测接下来出现的token是什么。

首先给一个开始标记,然后通过Linear Transform输出一个embedding向量h1,然后经过Softmax得到一个概率分布,概率最大的就是下一个token的值。(在训练的时候,GPT类似于transformer的decoder,不看右边的输入),下一次将和台输入进去,重复上面的过程。
😃😃😃
本文是根据台大李宏毅教授的BERT课程所做的笔记,有想学习的小伙伴,大家直接去看这个课程就可以了。点击跳转
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding