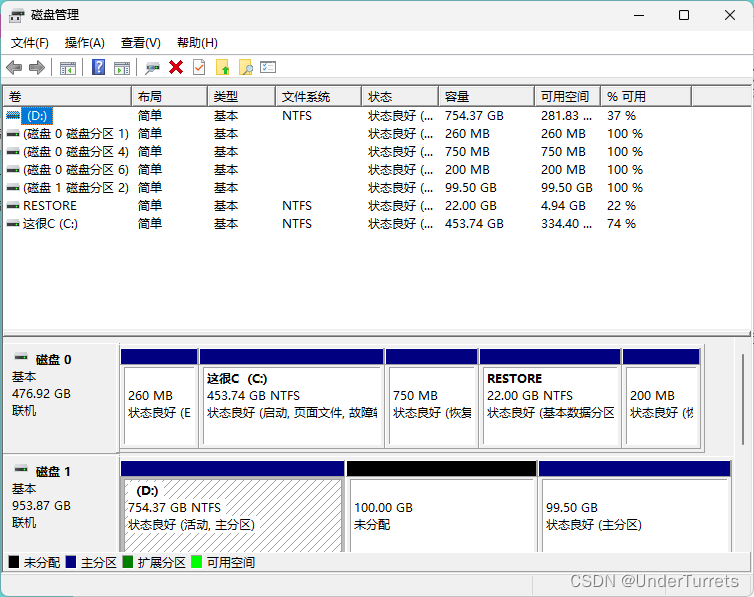
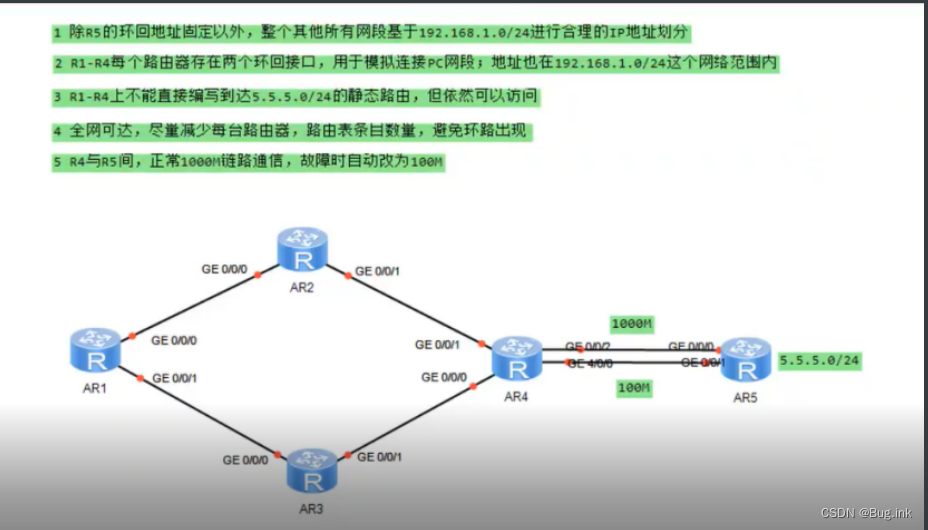
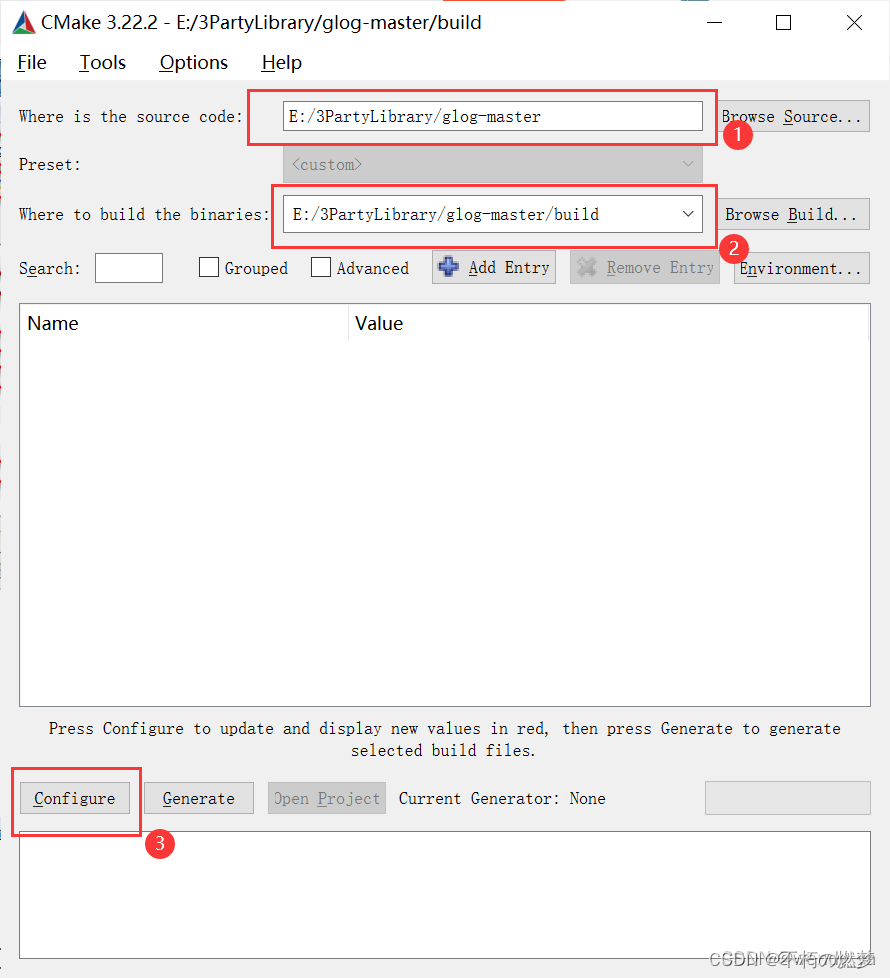
一、说明
BERT:适合所有人的架构概述:我们将分解 BERT 的核心组件,解释该模型如何改变机器理解人类语言的方式,以及为什么它比以前的模型有重大进步。
BERT的变体: 在BERT取得成功之后,已经开发了几种适应措施来满足特定需求或解决某些限制。我们将探讨这些变体,例如 RoBERTa、DistilBERT、ALBERT 和 MobileBERT,重点介绍它们的独特功能和应用。
迁移学习在NLP中的作用:深入研究迁移学习如何彻底改变 NLP,特别是在增强 BERT 等模型的功能方面。我们将讨论它的效率、适应性以及 Hugging Face 等平台在使高级 NLP 更易于访问方面的影响。
针对特定任务微调 BERT:了解为各种 NLP 任务微调 BERT 的关键过程。我们将指导您选择正确的 BERT 模型、准备数据集、调整模型架构以及根据特定数据训练模型以获得最佳结果。
动手示例:使用 BERT 进行情绪分析: 为了巩固您的理解,我们将提供一个代码片段,说明如何针对特定的 NLP 任务(例如情感分析)微调 BERT。
二、BERT:适合所有人的架构概述
- 双向情境分析
它的作用:想象一下,通过一次查看所有单词而不是逐字逐句地阅读一个句子。这就是 BERT 所做的。它一起检查整个单词序列。
为什么它很重要:通过分析周围所有单词(之前和之后)的上下文中的单词,BERT可以更全面、更准确地理解它们的含义。 - 蒙版语言模型(MLM)
它是如何工作的:在训练过程中,BERT玩一种猜谜游戏。它隐藏(掩盖)句子中的一些单词,并尝试仅根据它们周围的其他单词正确猜测它们。
区别:与猜测一行中下一个单词(如完成一个句子)的旧模型不同,BERT侧重于填充句子中的空白。 - 下一句话预测 (NSP)
任务: BERT 还学会了成为一名侦探,弄清楚两个句子是否应该在逻辑上相互跟随。
应用:这对于理解对话或文本的流程特别有用,例如确定问题后面的答案是否有意义。 - 神奇的内核:变压器编码器
BERT的大脑由一种叫做“变压器编码器”的东西组成。让我们分解一下这些是什么:
功能: 当BERT查看一个单词时,这一层可以帮助它同时考虑句子中其他单词的含义。这就像进行对话一样,你要注意整个讨论的背景,而不仅仅是说的最后一句话。
例:在“银行已关闭”这句话中,BERT使用周围的词语来弄清楚“银行”是指河岸还是金融机构。角色:在考虑了周围的单词后,BERT使用这个网络进一步处理这些信息,完善其对每个单词的理解。
会发生什么:这就像再看一遍句子,确保对每个单词的理解尽可能准确。BERT-base 与 BERT-large:BERT 有不同的尺寸。“基本”模型有 12 层这些编码器,而“大”模型则翻了一番,有 24 层。
堆垛效果:每一层编码器都增加了BERT的理解深度,使其更加细致入微。更多的层意味着BERT可以理解更复杂的语言模式。
三、BERT的变体
在 BERT 取得成功之后,出现了几种适应措施,每种调整措施都针对特定需求或解决某些限制而量身定制:
RoBERTa(鲁棒优化的 BERT 预训练方法):由 Facebook AI 开发,RoBERTa 修改了 BERT 的预训练程序,包括更长时间地训练模型、使用更多数据和更大的批量。
DistilBERT:此版本旨在减小 BERT 的大小,同时保留其大部分性能,使其部署效率更高。
ALBERT(A Lite BERT):它引入了参数缩减技术来扩展 BERT 并提高训练速度,使其内存效率更高。
MobileBERT:针对移动设备优化的 BERT 的紧凑版本,专注于速度和尺寸效率。
3.1 迁移学习在NLP中的作用
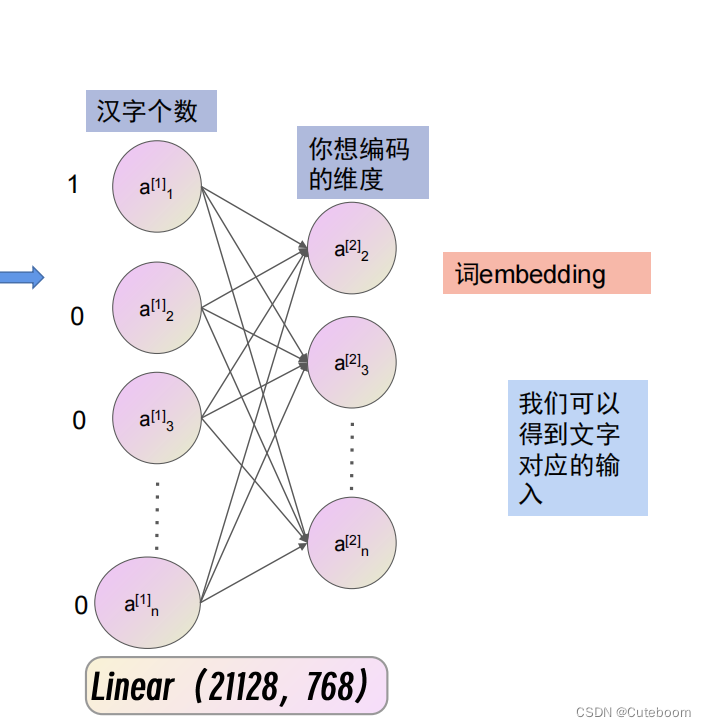
迁移学习彻底改变了自然语言处理 (NLP) 领域,特别是在增强 BERT 等模型的能力方面。这种方法涉及采用在大型且多样化的数据集上预先训练的模型,然后针对特定任务对其进行微调。理解这个概念及其影响,尤其是在 NLP 领域的一个著名平台 Hugging Face 的背景下,至关重要。
理解迁移学习:从本质上讲,NLP 中的迁移学习就像为模型提供一般语言理解的综合课程,然后针对特定任务进行专门培训。它从像 BERT 这样的模型开始,该模型经过大量文本的训练,为其提供了对语言的基础掌握。然后对模型进行微调,这意味着它会在与特定任务相关的更集中的数据集上接受额外的训练,例如分析法律文件或评估客户情绪。
效率和适应性:迁移学习的最大好处之一是它的效率。从头开始训练模型来理解语言是一项资源密集型工作。通过利用预先训练的模型,大部分基础训练已经就位。此外,迁移学习允许像 BERT 这样的通用模型适应各种专门任务,从而在不同的 NLP 领域得到广泛的应用。
抱脸部在迁移学习中的作用:拥抱脸部在使迁移学习更容易实现方面发挥了重要作用。他们的平台为开发人员和研究人员提供了多种预训练模型,包括 BERT 的变体。此外,Hugging Face 还提供了工具和资源,可以简化针对特定任务微调这些模型的过程。这大大降低了高级 NLP 应用的进入门槛。
对 NLP 开发的影响:Hugging Face 等平台的可用性使较小的团队和组织能够在没有大量资源的情况下利用最先进的模型。这种民主化导致 NLP 领域的创新和实验不断增加。此外,微调使模型能够更加熟练地完成特定任务,从而增强其在实际应用中的性能和实用性。
总之,迁移学习,尤其是与 Hugging Face 等平台结合使用时,对 NLP 产生了变革性的影响。它简化了复杂语言模型的开发,实现了针对特定任务的定制,并为更广泛的用户参与高级 NLP 项目提供了机会。先进建模技术和可访问平台之间的协同作用正在推动 NLP 向前发展,使其成为人工智能研究和应用中最具活力和令人兴奋的领域之一
3.2 针对特定任务微调 BERT
针对特定任务微调 BERT 是使这种强大的语言模型适应各种 NLP 应用程序的关键步骤。这个过程涉及几个关键阶段,每个阶段都是为了确保BERT有效地解决特定任务的细微差别而量身定制的。以下是这些阶段的更清晰细分:
目的:第一步是选择与您的特定任务相符的适当 BERT 版本。
注意事项:此选择取决于任务的大小和复杂性、可用的计算资源以及任务是否从速度或准确性中获益更多等因素。例如,对于移动应用程序,人们可能会选择MobileBERT来提高效率,而对于深度语言理解任务,BERT-large或RoBERTa可能更合适。
定制:用于微调的数据集应紧密表示模型在实际任务中将遇到的数据类型。这意味着它应该包括风格、上下文和内容相似的示例。
注解:在问答或情绪分析等情况下,应适当地注释数据集,为模型提供需要学习的输入-输出对的示例。
修改:根据任务的不同,您可能需要修改 BERT 的体系结构。这可能涉及添加新层(如用于情绪分析的分类层)或更改层的交互方式。
任务对齐:这些修改的目标是重塑模型的体系结构,以便它能够以对特定任务有用的方式处理和输出信息。
结合知识:在此阶段,预训练的 BERT 模型将在特定数据集上进一步训练(微调)。此步骤利用了 BERT 从对大型数据语料库的初始训练中获得的广泛知识。
微调:在微调过程中,模型会调整其权重和参数,以更好地适应任务的特定模式和细微差别。这个过程不需要像初始培训那样长,因为BERT已经在语言理解方面打下了坚实的基础。
3.3 动手示例:使用 BERT 进行情绪分析
下面是一个 Python 代码片段,演示了如何微调 BERT 以进行情绪分析。这个实际示例使用了 Hugging Face transformers库,这是处理 BERT 等模型的常用选择。
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
import torch
# Load a pre-trained BERT model and tokenizer
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# Sample texts for sentiment analysis
texts = ["I love this product!", "I hate this movie."]
labels = [1, 0] # 1 for positive sentiment, 0 for negative
# Tokenize the texts
tokens = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
input_ids, attention_mask = tokens["input_ids"], tokens["attention_mask"]
# Convert labels to tensor
labels = torch.tensor(labels).unsqueeze(0)
# Training arguments
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=8,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
)
# Initialize the Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset
)
# Train the model
trainer.train()
# Save the fine-tuned model
model.save_pretrained("./sentiment_model")
四、结论
本章阐明了BERT和迁移学习之间的协同作用,重点介绍了它们如何共同增强NLP应用。BERT对语言的深刻理解,加上迁移学习提供的效率和适应性,在该领域树立了新的标杆。