Bert Base:12层编码器,768维词嵌入,12个注意力头(对标GPT)
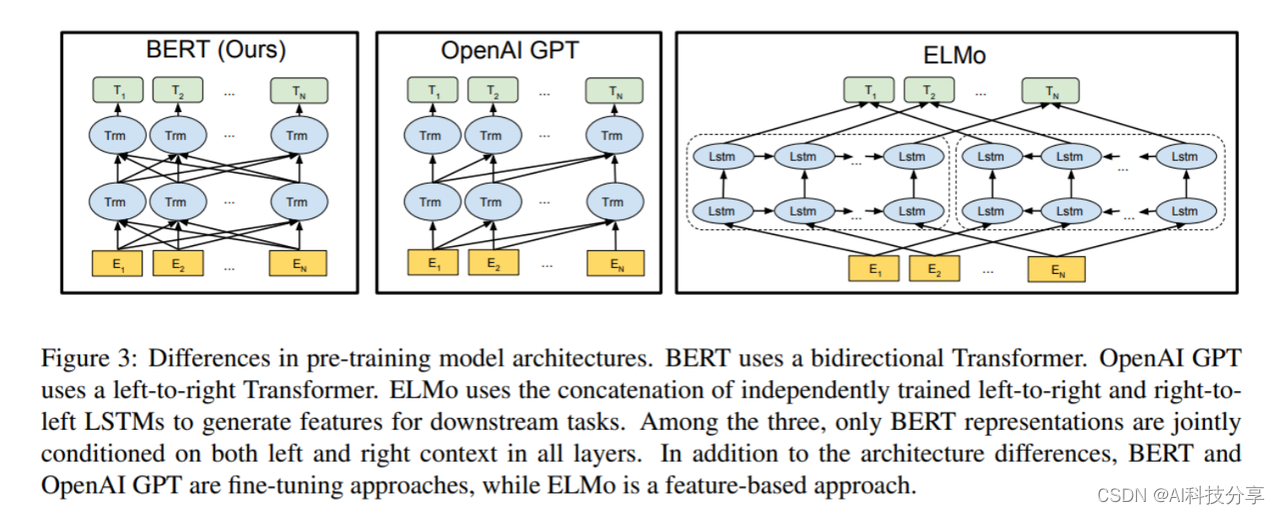
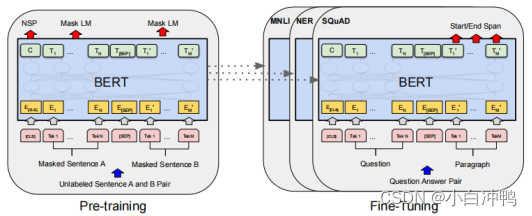
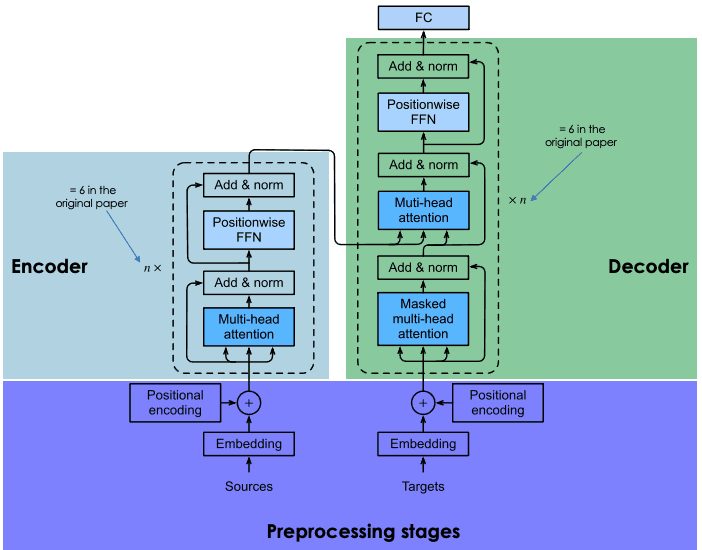
这张图讲的非常简单,对比了BERT、OpenAI和ELMo,其中ELMo是相对比较落后的,因为它没有用Transformer,而是只是用了双向的LSTM模型,把一个从左到右的RNN和一个从右到左的RNN拼接起来。GPT和BERT都是用了Transformer,但GPT用的是解码器,所以在当前时间步,“注意”不到后面时间步的信息。参考第二张图·,它是没有向左的箭头的。而BERT则是用了编码器,所以可以看到全部时间步的信息。这样一来,模型的训练会变得容易很多,让他去做判别式的任务(多分类),就容易以更小的数据集、更小的参数数量体现出更强的效果。
AI科技智库👉️👉️👉️www.aigchouse.com,一站式AI工具、资料、课程资源学习平台,每日持续更新。通过分享最新AI工具、AI资源等,帮助更多人了解使用AI,提升工作和学习效率。这里有海量AI工具整合包、AI学习资料、AI免费课程和AI咨询服务,AI之路不迷路,2024我们一起变强。

























![[Linux] TCP协议介绍(3): TCP协议的“四次挥手“过程、状态分析...](https://img-blog.csdnimg.cn/img_convert/9d53c94ab9382ef09b2e2020a241df74.webp?x-oss-process=image/format,png)