一、分布式计算概述
1. 什么是计算、分布式计算?
- 计算:对数据进行处理,使用统计分析等手段得到需要的结果
- 分布式计算:多台服务器协同工作,共同完成一个计算任务
- 2. 分布式计算常见的2种工作模式
- 分散->汇总 (MapReduce就是这种模式)
- 将数据分片,多台服务器各自负责一部分数据处理
- 然后将各自的结果,进行汇总处理
- 最终得到想要的计算结果
- 中心调度->步骤执行 (大数据体系的Spark、Flink等是这种模式)
-
1. 由一个节点作为中心调度管理者
2. 将任务划分为几个具体步骤
3. 管理者安排每个机器执行任务
4. 最终得到结果数据
二、MapReduce概述
MapReduce是“分散->汇总”模式的分布式计算框架,开发人员开发相关程序进行分布式数据计算。
MapReduce提供了2个编程接口:
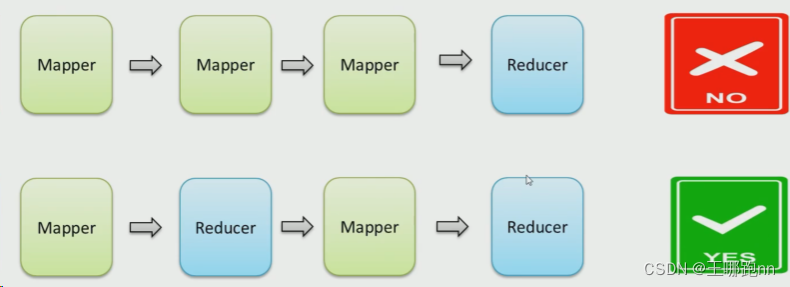
• Map• Reduce其中
• Map 功能接口提供了 “ 分散 ” 的功能, 由服务器分布式对数据进行处理• Reduce 功能接口提供了 “ 汇总(聚合) ” 的功能,将分布式的处理结果汇总统计
用户如需使用MapReduce框架完成自定义需求的程序开发
只需要使用Java、Python等编程语言,实现Map Reduce功能接口即可。
•注:MapReduce尽管可以通过Java等语言进行程序开发,但当下年代基本没人会写它的代码了,因为太过时了。 尽管MapReduce很老了,但现在仍旧活跃在一线,主要是Apache Hive框架非常火,而Hive底层就是使用的MapReduce。 所以对于MapReduce的代码开发,课程会简单扩展一下,但不会深入讲解,对MapReduce的底层原理会放在Hive之后,基于Hive做深入分析。
MapReduce的运行机制
•将要执行的需求,分解为多个Map Task和Reduce Task
•将Map Task 和 Reduce Task分配到对应的服务器去执行
三、YARN概述
MapReduce是基于YARN运行的,即普遍情况下,没有YARN”无法”运行MapReduce程序(有约束才能达到最好资源利用率)
YARN 即