🤵♂️ 个人主页: @AI_magician
📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。
👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!🐱🏍
🙋♂️声明:本人目前大学就读于大二,研究兴趣方向人工智能&硬件(虽然硬件还没开始玩,但一直很感兴趣!希望大佬带带)

摘要: 本系列旨在普及那些深度学习路上必经的核心概念,文章内容都是博主用心学习收集所写,欢迎大家三联支持!本系列会一直更新,核心概念系列会一直更新!欢迎大家订阅
该文章收录专栏
[✨— 《深入解析机器学习:从原理到应用的全面指南》 —✨]
基于实例学习
KDD
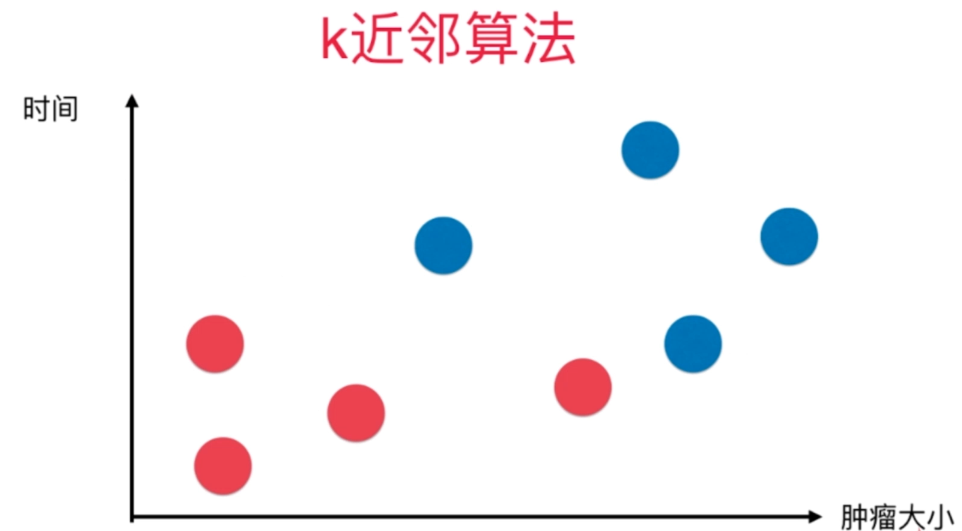
K最近邻(K Nearest Neighbors,简称KNN)算法是一种常用的分类和回归算法。它基于实例之间的相似性进行预测,即通过找到距离新样本最近的K个训练样本,根据这K个样本的标签来预测新样本的标签。
下面是KNN算法的详细步骤
计算训练样本中每个样本与其他样本的距离。常用的距离度量方法是欧氏距离(Euclidean Distance),它可以通过以下公式计算:
d ( x , y ) = ∑ i = 1 n ( x i − y i ) 2 d(\mathbf{x}, \mathbf{y}) = \sqrt{\sum_{i=1}^{n} (x_i - y_i)^2} d(x,y)=i=1∑n(xi−yi)2
其中, x \mathbf{x} x和 y \mathbf{y} y分别是两个样本的特征向量, n n n是特征的数量。
对距离进行排序,选择距离最近的K个样本作为邻居。
在面对问题一般通过投票(加权)、平均方法。
对于分类问题,使用投票法(Voting)确定新样本的标签。即,根据K个最近邻居的标签中出现次数最多的标签作为预测结果。如果存在多个标签出现次数相同的情况,可以随机选择其中一个标签。
对于回归问题,使用平均法(Averaging)确定新样本的标签。即,计算K个最近邻居的标签的平均值作为预测结果。
下面是使用Python实现KNN算法的示例代码:
# 使用sklearn库的KNN模型
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载经典的鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建KNN分类器模型
knn = KNeighborsClassifier(n_neighbors=3)
# 训练模型
knn.fit(X_train, y_train)
# 预测
y_pred = knn.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
不使用库的KNN实现
# 不使用库的KNN实现
import numpy as np
# 计算欧氏距离
def euclidean_distance(x1, x2):
return np.sqrt(np.sum((x1 - x2) ** 2))
# KNN算法
class KNN:
def __init__(self, k=3):
self.k = k
def fit(self, X, y):
self.X_train = X
self.y_train = y
def predict(self, X):
```python
y_pred = [self._predict(x) for x in X]
return np.array(y_pred)
def _predict(self, x):
# 计算距离
distances = [euclidean_distance(x, x_train) for x_train in self.X_train]
# 对距离排序并获取最近的K个邻居的索引
k_indices = np.argsort(distances)[:self.k]
# 获取最近的K个邻居的标签
k_labels = [self.y_train[i] for i in k_indices]
# 进行投票,确定标签
most_common = np.argmax(np.bincount(k_labels))
return most_common
# 使用示例
X_train = np.array([[1, 2], [1.5, 1.8], [5, 8], [8, 8], [1, 0.6], [9, 11]])
y_train = np.array([0, 0, 1, 1, 0, 1])
knn = KNN(k=3)
knn.fit(X_train, y_train)
X_test = np.array([[3, 4], [5, 6], [0, 0]])
y_pred = knn.predict(X_test)
print("预测结果:", y_pred)
相关学习资源:
李航,《统计学习方法》
Trevor Hastie, Robert Tibshirani, Jerome Friedman,《The Elements of Statistical Learning》
Sebastian Raschka, Vahid Mirjalili,《Python Machine Learning》
Scikit-learn官方文档:https://scikit-learn.org/stable/modules/neighbors.html

🤞到这里,如果还有什么疑问🤞 🎩欢迎私信博主问题哦,博主会尽自己能力为你解答疑惑的!🎩 🥳如果对你有帮助,你的赞是对博主最大的支持!!🥳
















![[Kubernetes]2. k8s集群中部署基于nodejs golang的项目以及Pod、Deployment详解](https://img-blog.csdnimg.cn/direct/1b93ccdefd8840cbb95922996ead98d6.png)