Prompt-Free Diffusion: Taking “Text” out of Text-to-Image Diffusion Models
- 开发
- 27
-
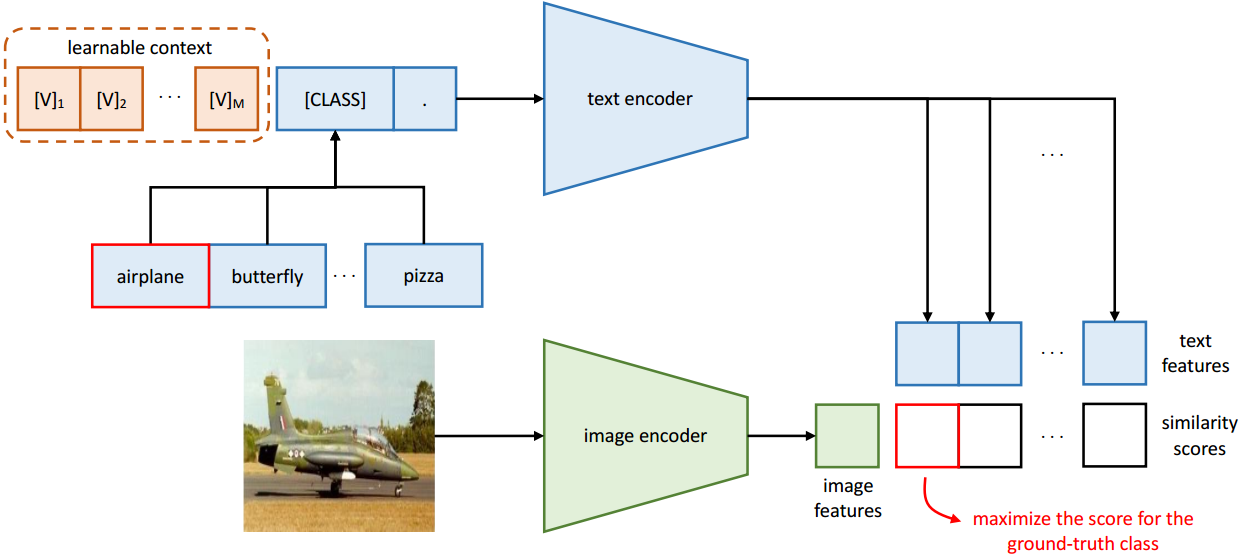
- 问题引入
- 在SD模型的基础之上,去掉text prompt,使用reference image作为生成图片语义的指导,optional structure image作为生成图片structure的指导来进行生成;
- 使用SeeCoder来提取参考图片的embedding作为生成条件,且SeeCoder是可以重复使用的,可以直接集成到另外的T2I模型中;
- methods
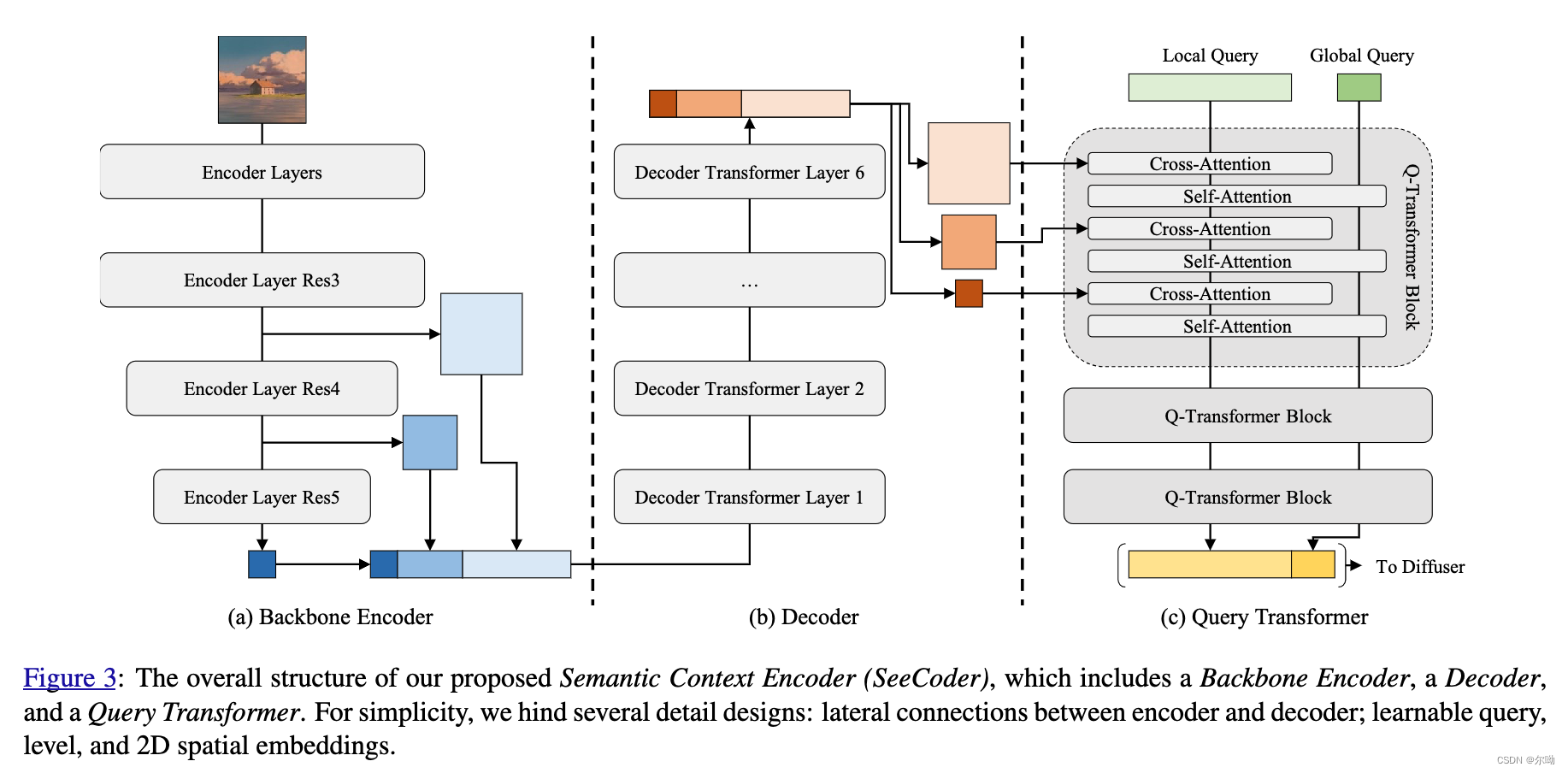
- 使用SeeCoder代替CLIP text embedding;
- SeeCoder包含三个部分,Backbone Encoder, Decoder, and Query Transformer,其中Backbone Encoder使用SWIN-L提取多尺度特征,该部分参数是冻结的;之后decoder使用卷积来使得多尺度特征通道数相同,然后进行flatten+concat,得到的结果通过self attn + ffn;之后Query Transformer输出视觉embedding;
原文地址:https://blog.csdn.net/weixin_44994838/article/details/140172470
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。
本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:https://www.suanlizi.com/kf/1810920908802625536.html
如若内容造成侵权/违法违规/事实不符,请联系《酸梨子》网邮箱:1419361763@qq.com进行投诉反馈,一经查实,立即删除!