1.线性回归算法 Linear Regression
线性回归算法(Linear Regression)是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。线性回归假设目标值与特征之间线性相关,即满足一个多元一次方程。
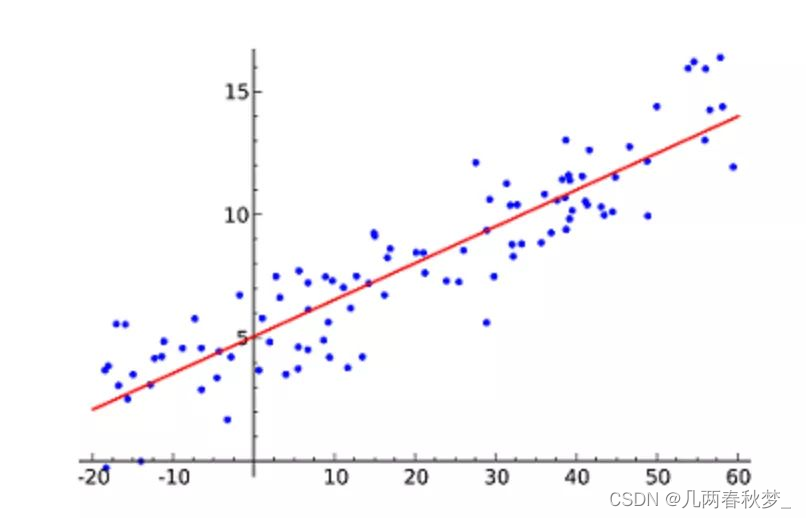
线性回归算法通过构建损失函数,求解损失函数最小时的参数w和b。公式为y = mx + c,其中y是因变量,x是自变量,m和c是参数,利用给定的数据集可以求得m和c的值。线性回归分为简单线性回归和多元线性回归。简单线性回归只有一个自变量,而多元线性回归则涉及两个或更多的自变量。
在求解最佳参数时,需要一个标准来对结果进行衡量,这通常是通过定量化一个目标函数式,使得计算机可以在求解过程中不断地优化。最小二乘法(又称最小平方法)是一种常用的数学优化技术,它通过最小化误差的平方和来寻找数据的最佳函数匹配。
线性回归算法常被用于连续型变量的预测问题,如某地区的玉米产量、某个公司的营收等。这种算法简单易懂,且在很多实际问题中都能取得不错的效果。

此图片来源于网络
2.支持向量机算法 (Support Vector Machine,SVM)
支持向量机(Support Vector Machine,SVM)是一种经典的二分类模型,属于监督学习算法。它的基本思想是在特征空间中寻找一个超平面,将不同类别的样本分开,同时使得不同类样本之间的间隔最大化。
在SVM中,支持向量就是那些离分隔超平面最近的样本点,这些点对于确定分隔超平面的位置起着决定性作用。而分隔超平面则是根据支持向量计算得出的,它能够将不同类别的样本最大程度地分隔开来。
SVM既可以处理线性分类问题,也可以处理非线性分类问题。对于非线性问题,SVM通常通过核方法(Kernel Method)将原始数据映射到更高维度的特征空间,然后在这个高维空间中寻找最佳线性分隔超平面。
SVM的优势在于其对于小样本、非线性及高维数据集的处理能力,因此在许多领域都有广泛的应用,如图像识别、文本分类、生物信息学等。同时,由于SVM在解决二分类问题时表现出色,它也经常被用于多分类问题的处理,通常是通过构建多个二分类器来实现。
总的来说,SVM是一种强大且灵活的分类算法,它通过寻找最佳分隔超平面来实现对数据的分类,并在处理非线性及高维数据集时展现出独特的优势。

此图片来源于网络
3.最近邻居/k-近邻算法 (K-Nearest Neighbors,KNN)
最近邻居/k-近邻算法(K-Nearest Neighbors,KNN)是一种简单且常用的监督学习算法,用于解决分类和回归问题。其核心思想是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
在KNN算法中,我们首先需要有一个已标记的训练数据集。对于一个新的测试对象,KNN算法会计算该对象与训练集中所有对象的距离,常用的距离度量方式包括欧式距离和余弦距离等。然后,算法会找出距离测试对象最近的k个训练样本,这k个样本就是测试对象的“邻居”。最后,根据这k个邻居的类别标签,通过多数投票等方式确定测试对象的类别。
KNN算法的优点在于其思想简单直观,易于理解,无需进行参数估计和训练,特别适合处理稀有事件或类别不平衡的分类问题。此外,KNN算法对多分类问题也有很好的处理能力。然而,KNN算法也有一些缺点,例如当样本数量很大时,计算量会非常大,导致算法运行缓慢;同时,KNN算法对数据的局部结构非常敏感,如果数据中存在噪声或异常值,可能会影响分类的准确性。
在选择K值时,通常需要根据具体问题和数据集的特性进行交叉验证。一般来说,K值越小,模型越复杂,越容易过拟合;K值越大,模型越简单,但可能欠拟合。因此,需要在两者之间找到一个平衡点。
总的来说,KNN算法是一种简单而有效的机器学习算法,广泛应用于各种分类和回归问题中。然而,在使用KNN算法时,需要注意其计算复杂度和对数据局部结构的敏感性,以便在实际应用中取得良好的效果。
4.逻辑回归算法 Logistic Regression
逻辑回归算法(Logistic Regression)是一种重要的有监督二类分类模型,它基于Sigmoid函数(又称“S型函数”)来实现分类。Sigmoid函数可以将任意实数映射到0和1之间,这使得逻辑回归算法可以处理二分类问题,即预测一个实例属于正类或负类的概率。
在逻辑回归中,我们首先通过训练集学习样本特征到样本标签的转换函数。训练集中的每个样本都由一系列特征组成,并通过一个线性组合来表示。然后,我们使用Sigmoid函数将线性组合的结果转换为一个概率值,这个概率值代表了样本属于正类的可能性。通过调整模型的参数,我们可以使得模型在训练集上的预测结果尽可能准确。
逻辑回归的结果并非数学定义中的概率值,而是对可能性的估计。因此,在实际应用中,我们通常会将逻辑回归的输出结果作为一个连续性的指标,而不是严格的概率值。
逻辑回归算法的优点包括实现简单、计算效率高、易于解释等。同时,它也可以处理一些非线性问题,通过引入多项式特征或者核方法等方式来实现。然而,逻辑回归对于多分类问题的处理能力相对较弱,通常需要采用一些扩展方法,如One-Vs-All或Softmax回归等。
总的来说,逻辑回归算法是一种强大且灵活的分类算法,广泛应用于各个领域,如广告点击率预测、疾病诊断、信用评分等。
5.决策树算法 Decision Tree
决策树算法(Decision Tree)是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。决策树算法以实例(Instance)为核心,通过归纳分类方法从无序的、无特殊领域知识的数据集中提取出决策树表现形式的分类规则。
决策树是一个树结构,其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别或回归值。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别或回归值作为决策结果。
决策树算法具有构造速度快、结构明显、分类精度高等优点。在决策树模型构建完成后,可以方便地应用于新数据的分类或回归预测。决策树算法在各个领域都有广泛的应用,特别是在分类问题上,它能够表示成分类规则,易于理解和解释。
常见的决策树算法包括ID3、C4.5、CART等。这些算法在构建决策树时采用了不同的特征选择准则和剪枝策略,以适应不同的数据集和问题需求。例如,ID3算法以信息增益为准则来选择划分属性,而C4.5算法则对ID3进行了改进,使用了信息增益比来克服信息增益偏向选择取值多的特征的不足。
总的来说,决策树算法是一种强大且灵活的有监督学习方法,它通过构建树状结构的决策规则来解决分类和回归问题,具有广泛的应用前景。