正则表达式
概念
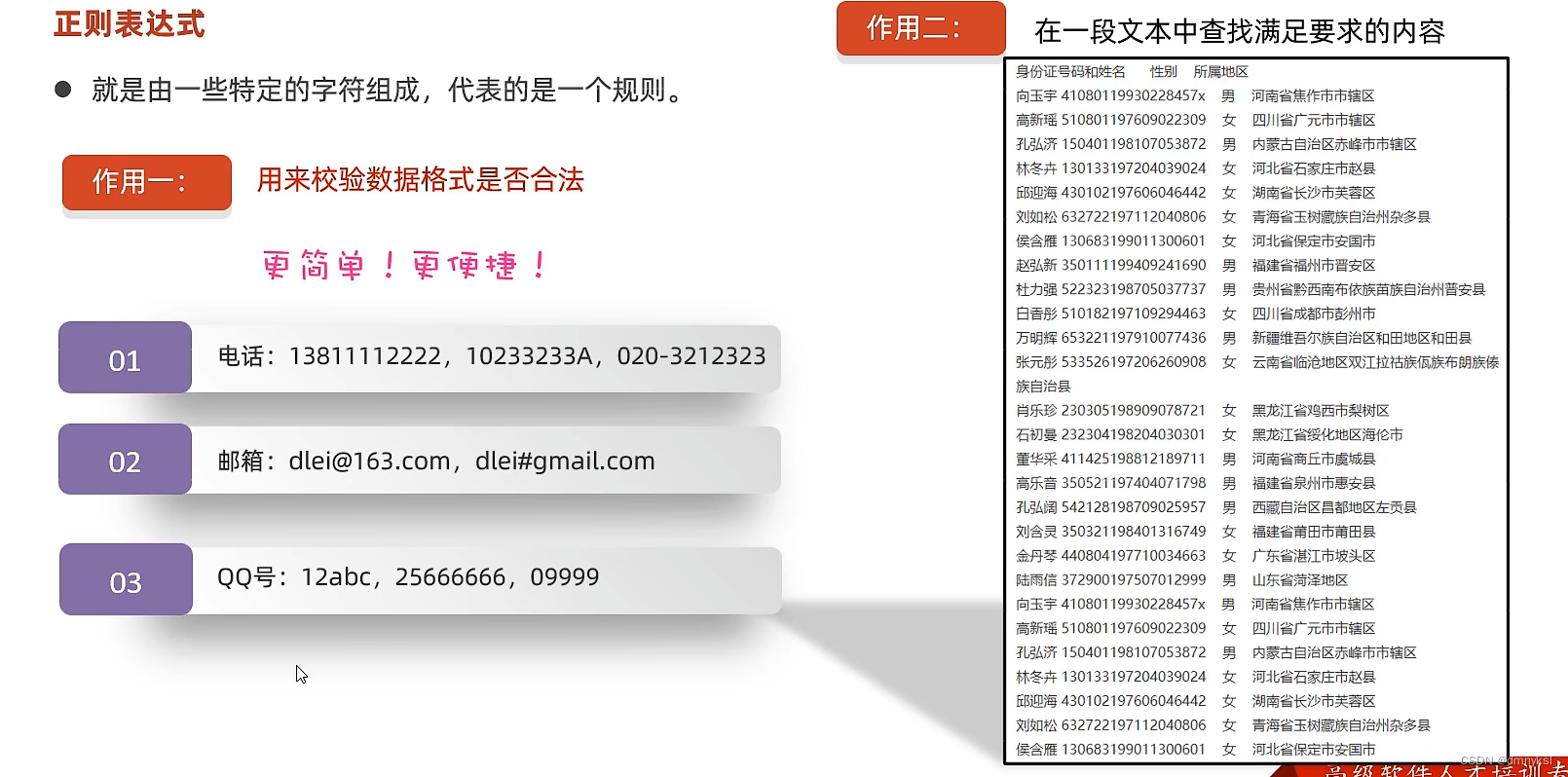
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:RegularExpression,在代码中常简写为regex、regexp或RE),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本
re模块
一个正则表达式(或RE)指定了一集与之匹配的字符串;模块内的函数可以让你检查某个字符串是否跟给定的正则表达式匹配模块定义了几个函数,常量,和一个例外。有些函数是编译后的正则表达式方法的简化版本(少了一些特性)。绝大部分重要的应用,总是会先将正则表达式编译,之后在进行操作
compile方法
re.compile(pattern[,flags])
把正则表达式语法转化成正则表达式对象
flags定义匹配模式包括
re.I:忽略大小写
re.L:表示特殊字符集 \w,\W,\b,\B,\s,\S 依赖于当前环境
re.M:多行模式
re.S:’ . ‘并且包括换行符在内的任意字符(注意:’ . '匹配任意字符但不包 括换行符)
re.U:表示特殊字符集 \w,\d,\D,\S 依赖于 Unicode 字符属性数据库
search方法
re.search(pattern, string[, flags=0])
扫描整个字符串,并返回第一个成功的匹配。如果匹配失败,则返回None
match方法
re.match(pattern, string[, flags=0])
从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
匹配结果
re.Match object 对象
span=()搜索结果在文本索引位置
match匹配结果
Match对象
Match对象是一次匹配的结果,包含匹配的很多信息
Match对象的属性

元字符
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为"元字符")组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配


表示字符

[]的用法
# 导入模块
>>> import re
# 匹配字符集,区间中的集合,可匹配其中任意一个字符,使用的re中的match方法
# 如果hello的首字符小写,那么正则表达式需要小写的h
>>> print(re.match("h","hello Python").group())
'h'
# 如果hello的首字符大写,那么正则表达式需要大写的H
>>> print(re.match("H","Hello Python").group())
'H'
# 大小写h都可以的情况
>>> print(re.match("[hH]","hello Python").group())
'h'
>>> print(re.match("[hH]","Hello Python").group())
'H'
# 匹配0到9第一种写法
>>> print(re.match("[0123456789]","7Hello Python").group())
'7'
# 匹配0到9第二种写法
>>> print(re.match("[0-9]","7Hello Python").group())
'7'
# 这里我们看到匹配的字符串里面没有 0到9的数字,返回来None,这里没有group,是因为空对象没有这个属性
>>> print(re.match("[0-9]","Hello Python"))
None
转义字符
’ \ ’ 在正则表达式中,使用反斜杠进行转义,与其他的方法类似相同转义特殊字符(允许你匹配 ‘*’ , ‘?’ , 或者此类其他字符),或者表示一个特殊序列我们知道在Python中也存在反斜杠的转义字符,其中我们还有更简便的方法,就是原生字符如果没有使用原始字符串( r’raw’ )来表达样式,要牢记Python也使用反斜杠作为转义序列;只有转义序列没有被Python的分析器识别,反斜杠和字符才能出现在字符串中。如果Python可以识别这个序列,那么反斜杠就应该重复两次。这会导致理解上非常的麻烦,所以高度推荐使用原始字符串,就算是最简单的表达式,也要使用原始字符串
表示数量

- 默认位贪婪模式,尽可能多的匹配
表示边界

^用法1:
"^[a-z]"
- 以…开始
^用法2:
"[^a-z]"
- 非小写字母
表示分组

|用法
"[a-z]|100"
- 小写字母或者数字100
() 用法
(组合),匹配括号内的任意正则表达式,并标识出组合的开始和结尾。匹配完成后,组合的内容可以被获取,并可以在之后用 \number 转义序列进行再次匹配,之后进行详细说明。要匹配字符 ‘(’ 或者 ‘)’ , 用 \( 或\) , 或者把它们包含在字符集合里: [(] , [)] .
import re
# |表示或者的意思,要么按照前面的规则,要么按照后面的规则
match_result = re.search(r'[1-9]?\d$|100', '100')
print(match_result)
# 匹配网易邮箱
emails = '''
afasdf@163.com
afffffffffffffffffffffffffffff@163.com
afa_@163.com
225afafa@163.com
aaaa______@126.com
aaaa______@163.comgg
'''
match_result = re.search(r'^[a-zA-Z][\w]{5,17}@(163|126|qq)\.com$', emails, re.MULTILINE)
print(match_result)
# 需求:匹配<h1>xxxx</h1>
match_result = re.match(r'^<[a-zA-Z]+>\w*</[a-zA-Z]+>', '<p>hello</span>')
# 非法标签<p></div>处理
print(match_result)
# 使用数字进行引用
match_result = re.match(r'^<([a-zA-Z]+)>\w*</\1>', '<p>hello</span>') # None
print(match_result)
# 分组用法2
# 定义别名分组语法:(?P<alias_name>express) 引用别名分组语法:(?P=ref_alias_name)
page = '''<div><span>hello python</span></div>'''
match_result = re.match(r'^<(?P<p1>\w+)><(?P<p2>\w+)>.*</(?P=p2)></(?P=p1)>', page)
print(match_result)
findall
re.findall(pattern, string, flags=0)
pattern 在 string 里所有的非重复匹配,返回为一个迭代器 iterator保存了 匹配对象 。 string 从左到右扫描,匹配按顺序排列。空匹配也包含在结果里。也就是说以字符串列表的形式返回所有的非重叠的匹配结果。从左到右扫描字符串,并按照找到的顺序返回匹配项,如果存在一个或多个字符串,返回一个列表的组织;如果匹配表达式中有多个分组,这将是一个元组列表。结果中包含空匹配项
sub
参数:re.sub(pattern, repl, string, count=0, flags=0)
• pattern: 是re.compile()方法生成Pattern类型,也就是索要匹配的模式
• repl : 可以是一段字符串,或者是一个方法
• string: 需要被匹配和替换的原字符串
• count: 指的是最大的可以被替换的匹配到的字符串的个数,默认为0,就是所有匹配到的字符串
• flags : 标志位
作用:返回repl字符串或者调用repl函数而得到的字符串。如果没有找到模式,则返回字符串不变
# sub函数 参数:正则表达式 回调函数|字符串 被匹配的字符
def add(match: re.Match) -> str:
result = match.group()
return str(int(result) + 1)
replace_result = re.sub(r'\d+', add, 'python996')
# python997
print(replace_result)
split
re.split(pattern, string, maxsplit=0, flags=0)
贪婪与非贪婪
- 什么是贪婪模式?
Python里数量词默认是贪婪的, 总是尝试匹配尽可能多的字符
- 什么是非贪婪?
与贪婪相反,总是尝试匹配尽可能少的字符,可以使用"*“,”?“,”+“,”{m,n}"后面加上?,使贪婪变成非贪婪
正则表达式模式中使用到通配字,那它在从左到右的顺序求值时,会尽量“抓取”满足匹配最长字符串,在我们上面的例子里面,“.+”会从字符串的启始处抓取满足模式的最长字符,其中包括我们想得到的第一个整型字段的中的大部分,“\d+”只需一位字符就可以匹配,所以它匹配了数字“4”,而“.+”则匹配了从字符串起始到这个第一位数字4之前的所有字符。
解决方式:非贪婪操作符“?”,这个操作符可以用在"*“,”+“,”?"的后面,要求正则匹配的越少越好。