文章目录
正则表达式概述
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(视则)的文本。
正则表达式可以:
(1)测试字符串的某个模式,即数据有效性验证(查找)
(2)实现按照某种规则替换文本
(3)根据模式匹配从字符串中提取一个子字符串(爬虫)
正则表达式的构成: 原子(普通字符,如英文字符)、元字符(有特殊功能的字符)、以及模式修正字符组成。注意:一个正则表达式中至少包含一个原子。
正则表达式测试工具: RegexBuddy
匹配单个字符
| 字符 | 功能 |
|---|---|
| . | 匹配任意1个字符(除了\n 换行) |
| [] | 匹配[ ]中列举的字符 |
| \d | 匹配数字,0-9 |
| \D | 匹配非数字,即不是数字 |
| \s | 匹配空白,即空格、\t tab键、\n 换行 |
| \S | 匹配非空白 |
| \w | 匹配单词字符(字母、数字、下划线),即a-z、A-Z、0-9,、_ |
| \W | 匹配非单词字符(非字母、非数字、非下划线) |
匹配多个字符
| 字符 | 功能 |
|---|---|
| * | 匹配前一个字符出现0次或者无限次,即可有可无 |
| + | 匹配前一个字符出现1次或者无限次,即至少有1次 |
| ? | 匹配前一个字符出现1次或者0次,即要么有1次,要么没有 |
| {m} | 匹配前一个字符出现m次 |
| {m,n} | 匹配前一个字符出现从m到n次,m<n |
匹配开头结尾
| 字符 | 功能 |
|---|---|
| ^ | 匹配字符串开头,注意^[4-7]和[^4-7]的区别 |
| $ | 匹配字符串结尾 |
注意: ^有两个作用
(1)匹配已指定字符开头
(2)用在[]内部,用于取反,如:[^he] 匹配不含有h和e的字符
练习:
1、匹配出,一个字符串第一字母为大写字符,后面都是小写字母并且这些小写字母可有可无:^[A-Z][a-z]*
2、匹配出,变量名是否有效(由字母、数字、下划线组成,不能以数字开头):^[a-zA-Z_]+\w*
3、匹配出,0到99之间的数字:^\d?\d$
4、匹配出,不是以4、7结尾的手机号码(11位):^\d{10}[0-35689]$
5、匹配出,8到20位的密码,可以是大小写英文字母、数字、下划线:^\w{8,20}$
6、匹配出,163的邮箱地址,且@符号之前有4到20位,例如nello@163.com:^\w{4,20}@163\.com$
re模块操作
re模块是python中提供的用于正则操作的模块。
re模块的使用步骤:
导入模块:import re
使用match()方法进行检测:result = re.match('正则表达式', '要验证/检测的字符串’)
判断是否检测/匹配成功:print('匹配成功') if result else print('匹配失败')
取出匹配的具体内容:result.group()
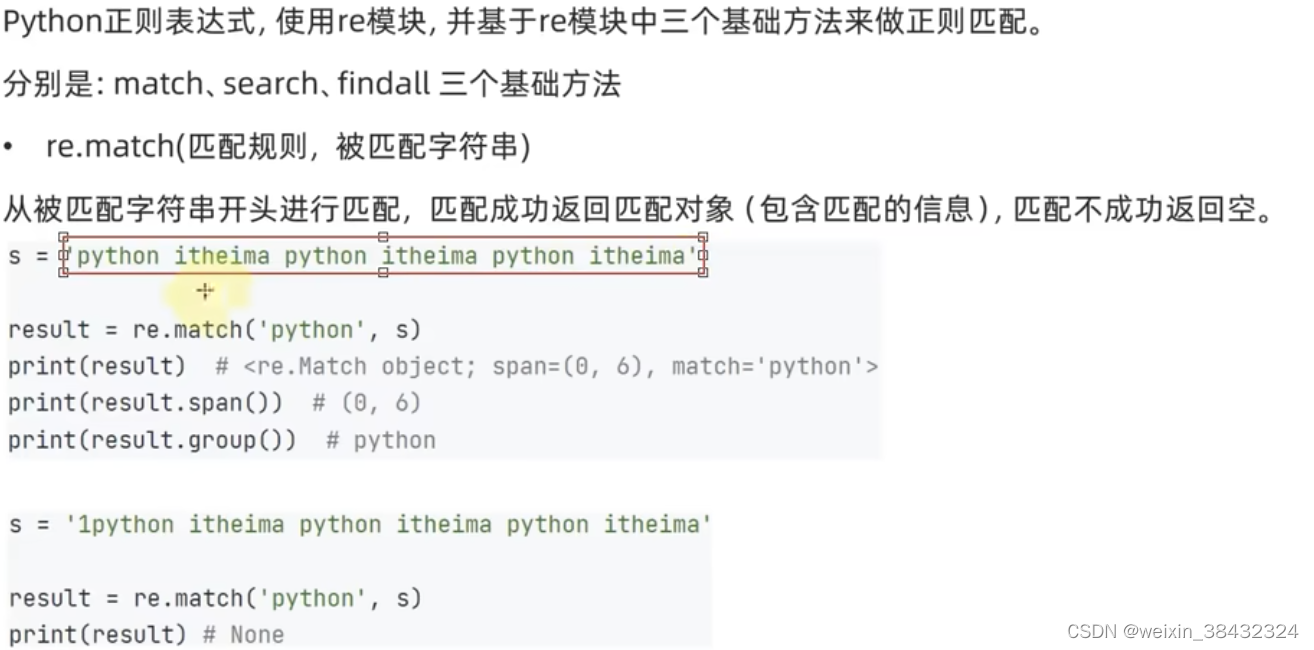
re.match(pattern, string, flags=0)
从头匹配一个符合规则的字符串,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
pattern:正则模型
string:要匹配的字符串
flags:匹配模式
注:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符$
match()方法一旦匹配成功,就是一个match object对象,而match object对象有以下方法:
- group()返回被RE匹配的字符串
- start()返回匹配开始的位置
- end()返回匹配结束的位置
- span()返回一个元组包含匹配(开始,结束)的位置
"""匹配出文章的阅读次数"""
import re
result = re.match('\d+', '9999 - 阅读次数') # 匹配成功!结果: 9999
# match从头开始匹配
# result = re.match('\d+', '阅读次数为 9999') # 匹配失败!结果: None
if result:
print('匹配成功!结果:', result.group())
else:
print('匹配失败!结果:', result)
re.search(pattern, string, flags=0)
re.search函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回None。
"""匹配出文章的阅读次数"""
import re
result = re.search('\d+', '阅读次数为 9999') # 匹配成功!结果: 9999
if result:
print('匹配成功!结果:', result.group())
else:
print('匹配失败!结果:', result)
match()和search()的区别:
match()函数只检测RE是不是在string的开始位置匹配,search()会扫描整个string查找匹配;
也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none。
如:print(re.match('super','superstar').span())会返回(0,5);print(re.match('super', 'insuperable')),则返回None。
如:print(re.search'super'','superstar).span()),返回(0,5),print(re.search('super','insuperable').span()),返回(2,7)
re.findall(pattern, string, flags=0)
re.findal()遍历匹配,可以获取字符串中所有匹配的字符串,返回一个列表。
"""匹配出阅读次数、转发次数和评论次数"""
import re
# result = re.search('\d+', '阅读次数:9999,转发次数:6666,评论次数:88')
result = re.findall('\d+', '阅读次数:9999,转发次数:6666,评论次数:88')
if result:
# print('匹配成功!结果:', result.group()) # 匹配成功!结果: 9999
print('匹配成功!结果:', result) # 匹配成功!结果: ['9999', '6666', '88']
else:
print('匹配失败!结果:', result)
re.sub(pattern, repl, string, count)
使用re替换string中每一个匹配的子串后返回替换后的字符串。
实例:将匹配到的阅读次数加1
import re
"""方法一"""
result = re.sub('\d+', '10000', '阅读次数:9999,转发次数:6666,评论次数:88', 1)
if result:
print('匹配成功!结果:', result) # 匹配成功!结果: 阅读次数:10000,转发次数:6666,评论次数:88
else:
print('匹配失败!结果:', result)
"""方法二"""
def add(temp):
strNum = temp.group()
num = int(strNum) + 1
return str(num)
result = re.sub('\d+', add, '阅读次数:9999,转发次数:6666,评论次数:88', 1)
if result:
print('匹配成功!结果:', result) # 匹配成功!结果: 阅读次数:10000,转发次数:6666,评论次数:88
else:
print('匹配失败!结果:', result)
re.split(pattern, string[, maxsplit])
按照能够匹配的子串将string分割后返回列表。
可以使用re.split来分割字符串,如:re.split(r'\s+', text),将字符串按空格分割成一个单词列表。
"""切割字符串info:xiaoZhang 33 shandong"""
import re
# re.split("正则表达式", “待拆分的字符串") 按照正则拆分字符串,返回值是一个列表
result = re.split(r':| ', 'info:xiaoZhang 33 shandong')
if result:
print('匹配成功!结果:', result) # 匹配成功!结果: ['info', 'xiaoZhang', '33', 'shandong']
else:
print('匹配失败!结果:', result)
匹配分组
| 字符 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中字符作为一个分组 |
| \num | 引用分组num匹配到的字符串 |
| (?P<name>) | 分组起别名为name |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
匹配分组之“|”
|的作用:或者关系,多个正则表达式满足任意一个都可以。
匹配出0-100之间的数字:^[0-9]?[0-9]$|^100$ (满足^[0-9]?[0-9]$或者满足^100$任意一个,返回值都是一个match object对象)
匹配分组之“()”
()的作用:
(1)分组,整体匹配。例如:匹配出163、126、qq邮箱,且@符号之前有4到20位:^\w{4,20}@(163|126|qq).com$
(2)提取子字符串。例如:提取区号和电话号码:
import re
result = re.match('(\d{3,4})-(\d{7,8})', '010-12345678')
if result:
print('匹配成功!')
print('提取区号:', result.group(1))
print('提取电话号码:', result.group(2))
else:
print('匹配失败!')
运行结果:
匹配成功!
提取区号: 010
提取电话号码: 12345678
匹配分组之“\”
\的作用:引用分组。\1表示引用第一组,\是转义字符,转义后代表一个
匹配出2个标签页中的值,如:<html><h1>hhaaaaa</h1></html>
import re
# 注意:\1 有特殊用法; \\-->\
result = re.match('<([a-zA-Z0-9]+)><([a-zA-Z0-9]+)>(.*)</\\2></\\1>', '<html><h1>hhaaaaa</h1></html>')
if result:
print('匹配成功!')
print('匹配结果:', result.group(3))
else:
print('匹配失败!')
运行结果如下:
匹配成功!
匹配结果: hhaaaaa
匹配分组之“起别名”
起名:?P<name>
引用别名:?P=name
import re
# ?P<name1> 给分组起别名,别名为name1
# ?P=name1 引用别名为name1的分组
result = re.match('<(?P<name1>[a-zA-Z0-9]+)><(?P<name2>[a-zA-Z0-9]+)>(.*)</(?P=name2)></(?P=name1)>', '<html><h1>hhaaaaa</h1></html>')
if result:
print('匹配成功!')
print('匹配结果:', result.group(3))
else:
print('匹配失败!')
运行结果如下:
匹配成功!
匹配结果: hhaaaaa
贪婪和非贪婪
贪婪: 默认,表示在满足正则的情况下尽可能多的取内容
非贪婪: 表示在满足正则的情况下,尽可能少的取内容
贪婪转变为非贪婪: 在* ? + {m, n}后面加上?就可以了
import re
# 非贪婪:满足正则的情况下,尽可能少的取内容
result = re.search('data-imgurl=\"(.*?)\"', '<img class="main_img img-hover" data-imgurl="https://img1.baidu.com/it/u=1546227440,2897989905&fm=253&fmt=auto&app=138&f=JPEG?w=889&h=500" src="data:image/jpeg;base64,/9j/4AAQSkZJRgAB" style="width: 258px; height: 160px;">') # 匹配成功!结果: https://img1.baidu.com/it/u=1546227440,2897989905&fm=253&fmt=auto&app=138&f=JPEG?w=889&h=500
# 贪婪:满足正则的情况下,尽可能多的取内容。
result = re.search('data-imgurl=\"(.*)\"', '<img class="main_img img-hover" data-imgurl="https://img1.baidu.com/it/u=1546227440,2897989905&fm=253&fmt=auto&app=138&f=JPEG?w=889&h=500" src="data:image/jpeg;base64,/9j/4AAQSkZJRgAB" style="width: 258px; height: 160px;">') # 匹配成功!结果: https://img1.baidu.com/it/u=1546227440,2897989905&fm=253&fmt=auto&app=138&f=JPEG?w=889&h=500" src="data:image/jpeg;base64,/9j/4AAQSkZJRgAB" style="width: 258px; height: 160px;
if result:
print('匹配成功!结果:', result.group(1))
else:
print('匹配失败!结果:', result)
r的作用
Python中在正则字符串前面加’r’表示,让正则中的’\'不再具有转义功能(默认为转义),就是表示原生字含义一个斜杠\,仅仅对\起作用。
原来的写法:result= re.match("<([a-zA-Z0-9]*)>.*</\\1>", "<html>helloworld</html>")
使用r的写法:result= re.match(r"<([a-zA-Z0-9]*)>.*</\1>", "<html>helloworld</html>")
说明:
与大多数编程语言相同,正则表达式里使用“\”作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符“\”,那么使用编程语言表示的正则表达式里将需要4个反斜杠“\”:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解法了这个问题,有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。


























![[递归回溯]连接卡片最短路径](https://img-blog.csdnimg.cn/img_convert/27652da9d9d6ebc377ffeccd5389c8e4.png)