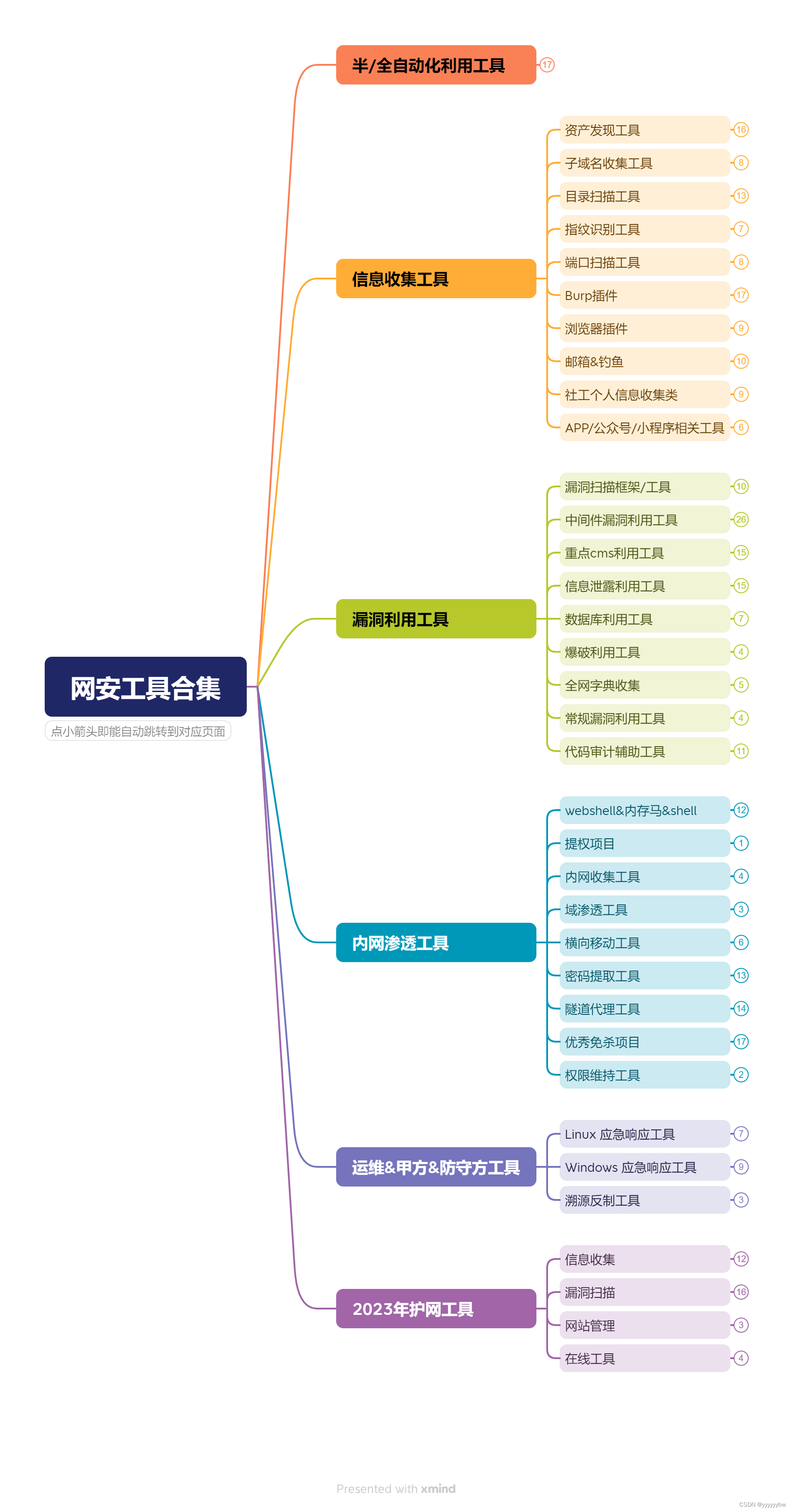
目录

一、概述
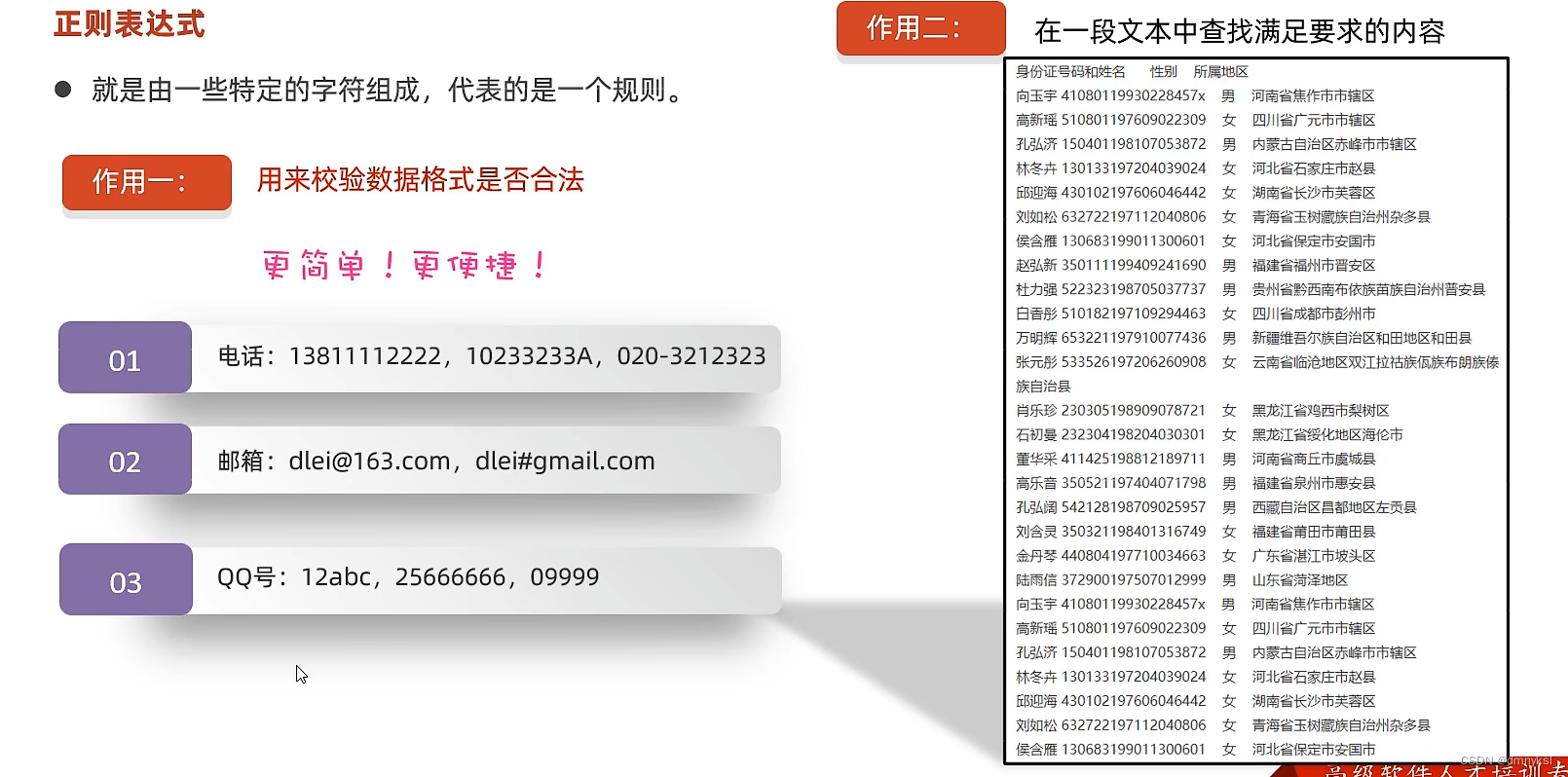
正则表达式是一种用于匹配字符串模式的工具。它是一种高度灵活的文本处理工具,可以用于验证、筛选、查找和替换字符串。正则表达式基于一种特定的语法构建模式,这种模式可以用来描述和匹配字符串中的子串。
二、正则表达式的基本构成
- 元字符:元字符是用来描述字符串中的特殊字符的。例如,
.表示任何字符,*表示零个或多个之前的字符,+表示一个或多个之前的字符,?表示零个或一个之前的字符。 - 字符类:用方括号
[]来表示字符类,可以包含一个或多个字符。例如,[aeiou]表示任何元音字母。 - 边界:用
^和$来表示字符串的开始和结束。 - 选择:用
|来表示选择,即匹配该符号左侧的子表达式或右侧的子表达式。 - 重复:用
{}来表示重复,可以指定一个范围,如{3,5}表示匹配3到5次。 - 反向引用:用
\n来表示反向引用,其中 n 是一个数字,表示匹配之前出现的第n个子表达式。 - 模式修饰符:用来修改模式的含义,如
g表示全局匹配,i表示不区分大小写匹配等。
三、正则表达式的使用场景
- 验证输入:例如,验证一个密码是否符合要求,可以通过正则表达式来匹配密码中的特定字符模式。
- 数据筛选:例如,从一段文本中筛选出所有的电子邮件地址或电话号码,可以通过正则表达式来匹配这些特定的字符模式。
- 查找替换:例如,将所有的电话号码替换为其他文本,可以通过正则表达式来匹配电话号码的模式,并用其他文本替换它。
- 分词断句:例如,将一段文本按照特定的规则进行分词断句,可以通过正则表达式来匹配这些规则。
四、正则表达式的语法规则
- 普通字符:直接匹配该字符。
- 元字符:
.、^、$、*、+、?、|、{、}、[、]、(、)、\需要进行转义,即前面加\。 - 字符类:用方括号
[]来表示字符类,可以包含一个或多个字符。例如,[aeiou]表示任何元音字母。可以用^来表示否定字符类,即不包含某个字符。例如,[^aeiou]表示不是元音字母的任何字符。 - 边界:用
^和$来表示字符串的开始和结束。 - 选择:用
|来表示选择,即匹配该符号左侧的子表达式或右侧的子表达式。 - 重复:用
{}来表示重复,可以指定一个范围,如{3,5}表示匹配3到5次。还可以指定一个特定的重复次数,如{3}表示匹配3次。 - 反向引用:用
\n来表示反向引用,其中 n 是一个数字,表示匹配之前出现的第n个子表达式。例如,在模式a(b|c)d\1e中,\1表示匹配前面的(b|c)中的内容。
五、正则表达式的使用技巧
- 使用非贪婪匹配:在正则表达式中,可以使用问号
?来表示非贪婪匹配。例如,a.*?b表示匹配尽可能少的字符,直到遇到字符 b。 - 使用捕获组:在正则表达式中,可以使用括号
()来表示捕获组,即匹配括号内的子表达式,并将其作为一个整体进行反向引用。 - 使用前瞻断言:在正则表达式中,可以使用
(?=...)来表示前瞻断言,即匹配后面紧跟着某个字符串的文本。例如,a(?=b)表示匹配以 a 结尾的文本,但只有当后面紧跟着 b 时才匹配成功。 - 使用后顾断言:在正则表达式中,可以使用
(?<=...)来表示后顾断言,即匹配前面紧挨着某个字符串的文本。例如,a(?<=b)表示匹配以 b 开头的文本,但只有当前面紧挨着 a 时才匹配成功。 - 使用负向预测:在正则表达式中,可以使用
(?!...)来表示负向预测,即匹配不包含某个字符串的文本。例如,a(?!b)表示匹配以 a 开头的文本,但只有当后面不包含 b 时才匹配成功。 - 使用零宽断言:在正则表达式中,可以使用
(?=...)和(?!...)来进行前瞻和负向预测,这些称为零宽断言。此外,还可以使用(?<=...)和(?<!...)来进行后顾和负向后顾预测。 - 使用转义字符:在正则表达式中,需要使用反斜杠
\来转义特殊字符。例如,\d表示匹配任意数字字符。 - 使用多行模式:在正则表达式中,可以使用
^和$来匹配字符串的开始和结束。但是,当文本跨越多行时,使用^和$可能无法正确匹配。此时可以使用m和s标志来启用多行模式。在多行模式下,^和$分别表示当前行的开始和结束。 - 使用标志:在正则表达式中,可以使用标志来修改模式的含义。例如,使用
g标志表示全局匹配,即匹配所有符合模式的文本;使用i标志表示不区分大小写匹配;使用m标志表示多行模式,即在每行上进行匹配。
六、正则表达式的常见问题
- 重复匹配:正则表达式默认会重复匹配尽可能多的字符。例如,在字符串 "aaab" 中,模式
a+b会匹配整个字符串。如果想要匹配单个字符或单词,可以使用边界或字符类等技巧来限制匹配范围。 - 贪婪匹配:正则表达式默认会贪婪匹配尽可能多的字符。例如,在字符串 "abab" 中,模式
a(b*)b\1会匹配整个字符串而不是第一个 "ab"。如果想要非贪婪匹配或惰性匹配,可以使用问号?来修改元字符的重复次数。 - 特殊字符的转义:在正则表达式中,特殊字符需要进行转义才能匹配其本身。例如,在字符串 "abc" 中,模式
.bc会匹配 "abbc" 而不是 "abc"。如果想要匹配特殊字符本身,可以使用反斜杠\来转义它。
七、日常使用案例
在日常使用中,正则表达式可以用于各种场景,如数据验证、文本处理、自动化脚本等。以下是一些常见的日常使用正则表达式示例:
验证电子邮件地址:
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$ |
该正则表达式用于验证电子邮件地址的格式是否正确。
验证手机号码:
^\+?[1-9]\d{1,14}$ |
该正则表达式用于验证手机号码的格式是否正确,可以匹配国际电话号码和国内手机号码。
2.验证密码:
^(?=.*[A-Za-z])(?=.*\d)[A-Za-z\d]{8,}$ |
该正则表达式用于验证密码的格式是否正确,要求包含字母和数字,且长度至少为8个字符。
3.提取日期:
^\d{4}-\d{2}-\d{2}$ |
该正则表达式用于匹配日期格式,如2023-03-17。
4.提取时间:
^\d{2}:\d{2}:\d{2}$ |
该正则表达式用于匹配时间格式,如13:45:30。
以上仅是一些常见的日常使用正则表达式示例,根据具体需求和场景,还可以使用更复杂的正则表达式来实现更高级的功能。
作者的其他文章: