系列文章目录
文章目录
高阶篇:
docker安装mysql、redis集群
docker-compose,dockerfile一键部署多个实例
docker微服务实战
docker网络、集群化部署
安装mysql主从复制
1、新建主服务器容器实例3307
- 创建/mydata/mysql-master/conf目录,在下面新建my.cnf
mkdir -p /mydata/mysql-master/conf
touch my.cnf
- 修改配置
vim my.cnf
内容(注意:主从同步需要通过该配置开启二进制日志功能,从节点会通过读取日志实现数据同步)
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
- 启动mysql容器
docker run -p 3307:3306 --name mysql-master \
-v /mydata/mysql-master/log:/var/log/mysql \
-v /mydata/mysql-master/data:/var/lib/mysql \
-v /mydata/mysql-master/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
- 进入容器,进行登录
docker exec -it mysql-master /bin/bash
mysql -uroot -proot
show databases;
其中的mysql库我们设置了不需要同步

mysq新建数据同步用户(数据安全加固,只有固定用户可以进行数据同步)
CREATE USER 'slave'@'%' IDENTIFIED BY '123456';
授权
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'%';
账号slave,密码123456的用户可以同步数据
2、新建从服务器3308
- 先启动容器3308(mysql从节点)
docker run -p 3308:3306 --name mysql-slave \
-v /mydata/mysql-slave/log:/var/log/mysql \
-v /mydata/mysql-slave/data:/var/lib/mysql \
-v /mydata/mysql-slave/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
- 进入/mydata/mysql-slave/conf目录下新建my.cnf
mkdir -p /mydata/mysql-slave/conf
cd /mydata/mysql-slave/conf
- 编辑从节点配置
vim my.cnf
内容
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=102
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能,以备Slave作为其它数据库实例的Master时使用
log-bin=mall-mysql-slave1-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
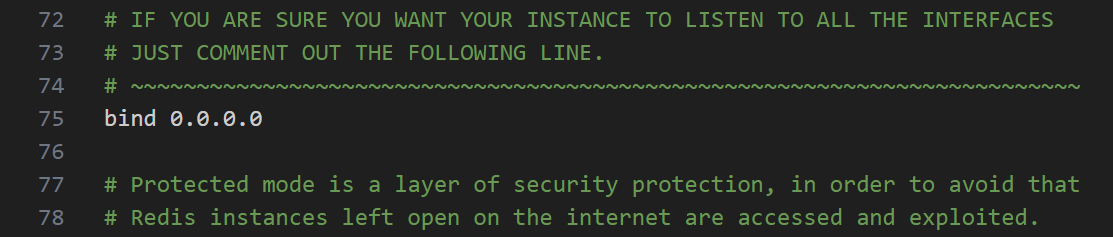
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
## relay_log配置中继日志
relay_log=mall-mysql-relay-bin
## log_slave_updates表示slave将复制事件写进自己的二进制日志
log_slave_updates=1
## slave设置为只读(具有super权限的用户除外)
read_only=1
- 修改完配置后重启slave实例
docker restart mysql-slave
- 在主数据库中查看主从同步状态
docker exec -it mysql-master /bin/bash
mysql -uroot -proot
show master status;
表示从mall-mysql-bin.000001文件的第154行开始同步

- 进入从数据库,配置开启主从复制
docker exec -it mysql-slave /bin/bash
mysql -uroot -proot
配置主从复制(注意:master_log_file和master_log_pos需要修改为上一步show master status查出来的结果mall-mysql-bin.000001和164)

change master to master_host='宿主机ip', master_user='slave', master_password='123456', master_port=3307, master_log_file='mall-mysql-bin.000001', master_log_pos=154, master_connect_retry=30;
主从复制配置参数说明:
master_host:主数据库的IP地址;
master_port:主数据库的运行端口;
master_user:在主数据库创建的用于同步数据的用户账号;
master_password:在主数据库创建的用于同步数据的用户密码;
master_log_file:指定从数据库要复制数据的日志文件,通过查看主数据的状态,获取File参数;
master_log_pos:指定从数据库从哪个位置开始复制数据,通过查看主数据的状态,获取Position参数;
master_connect_retry:连接失败重试的时间间隔,单位为秒。
在从数据库(mysql-slave)查看主从同步状态
show slave status;

在从数据库启动主从同步
start slave;
再次在从数据库(mysql-slave)查看主从同步状态
show slave status;
已经开始同步了

3. 主从复制测试
主机新建库-使用库-新建表-插入数据
create database syn_test;
use syn_test;
create table mytest (id int,name varchar(20));
insert into mytest value (1,‘zhangsan’);
从机使用库-查看记录
use syn_test;
select * from mytest;

OK。Mysql主从复制已经成功开启。
Redis篇
穿插Redis面试题
cluster(集群)模式-docker版
哈希槽分区进行亿级数据存储
1-2亿条数据需要缓存,你如何设计这个存储案例?
这时单节点Redis不足以支持,我们就需要使用集群的方式来进行存储,那么问题来了,如何使用集群的方式进行存储呢?
通常我们有三种方案(负载均衡)
Hash取余分区
hash(key)%集群个数来决定存储在哪台服务器上,这种方式的有点是简单,通过这种简单的方式实现数据的读写负载均衡,每台服务器都处理它固定的请求,但这样的缺点也很明显,就是我们进行扩容时不方便,集群个数会动态变化,或者某个机器宕机了,都会导致所有的数据都重新洗牌(计算公式的分母改变了)。
一致性Hash算法分区

这里简单介绍一下吧,一致性hash算法共分三大步:
第一步:构建一致性hash环,通常是0-2^32次方。
第二步:服务器节点IP映射到环上。
第三步:key落到服务器上的规则(通常是在环上顺时针找到的第一个服务器)。
服务器和数据落在环上的位置通过一致性算法来得到。
这样做,不再以服务器数量作为分母,减少了服务器扩展对数据的影响(不是完全消除)。
如果出现错误,某个服务器宕机,或需要扩展新增服务器,我们不需要全部重新录入数据,只需要将环上离新服务器或坏掉的服务器直接的数据进行重新录入。
这样做的缺点:如果节点太少,且离得很近,就很容易发生数据倾斜,大量的数据都存在少量的服务器上(可以通过引入虚拟节点来解决)。
Hash槽分区(通常都使用这种方式)
hash槽是为了解决均匀分配的问题,在数据和节点间又加入了一层叫做hash槽,用于管理数据和节点的关系。
Redis集群中内置了16384个哈希槽,redis会根据节点的数量大致均等的将哈希槽映射到不同的节点,当需要在Redis集群中放置一个key-value时,redis会先对key用crc16算法算出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的hash槽,也就是映射到某个节点上。如下代码:key之A、B在Node2,key之C在Node3上。


Redis集群配置(三主三从)
集群部署

- 新建6个Docker Redis容器实例
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
docker run -d --name redis-node-2 --net host --privileged=true -v /data/redis/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382
docker run -d --name redis-node-3 --net host --privileged=true -v /data/redis/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383
docker run -d --name redis-node-4 --net host --privileged=true -v /data/redis/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384
docker run -d --name redis-node-5 --net host --privileged=true -v /data/redis/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385
docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386

如果运行成功,效果如下:

- 进入Redis容器构建主从关系
进入容器redis-node-1并为6台机器构建集群关系
docker exec -it redis-node-1 /bin/bash
构建集群和主从关系(注意:ip需要换成自己的虚拟机IP)
//注意,进入docker容器后才能执行一下命令,且注意自己的真实IP地址
redis-cli --cluster create 192.168.248.128:6381 192.168.248.128:6382 192.168.248.128:6383 192.168.248.128:6384 \
192.168.248.128:6385 192.168.248.128:6386 --cluster-replicas 1
–cluster-replicas 1 表示为每个master创建一个slave节点


输入yes,表示确认信息正常

一切OK的话,3主3从搞定~
- 链接进入6381作为切入点,查看节点状态
redis-cli -h 127.0.0.1 -p 6381
cluster info

cluster nodes

这也说明的redis集群的主从映射关系随机分配

- 验证集群
登录6381,验证Redis集群
docker exec -it redis-node-1 /bin/bash
连接Redis,集群模式需要指定端口
redis-cli -p 6381
尝试放入数据
set k1 v1
失败

set k2 v2
set k3 v3
多试几个,发现有的能成功,有的不能成功,这是因为hash槽存在,我们使用redis-cli -p 6381的方式只连上了单节点的redis,不能分配到该机器上的存储是会存储失败。
加上-c参数,连接到集群节点
redis-cli -h 127.0.0.1 -p 6381 -c
-c:连接集群节点
-h:连接的节点ip
-p:连接的节点端口(默认6379)
再次存入数据
set k1 v1
k1的哈希值是12706,被分配到了6383节点

查看集群信息
redis-cli --cluster check 192.168.248.128:6381

演示主节点宕机,从节点上位(主从容错)

把master1关掉,模拟宕机
docker stop redis-node-1
这是node1已经停掉了,我们通过node2上redis看下集群信息
docker exec -it redis-node-2 /bin/bash
redis-cli -p 6382 -c
看下集群信息
cluster nodes

演示集群扩容
 随着数据增大,集群不够用了,我们需要将Redis三主三从扩容为四主四从,下面介绍一下扩容的步骤以及扩容后槽位发生的变化。
随着数据增大,集群不够用了,我们需要将Redis三主三从扩容为四主四从,下面介绍一下扩容的步骤以及扩容后槽位发生的变化。
- 启动6387和6388
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387
docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388
8个redis全都启动了

进入6387容器实例内部
docker exec -it redis-node-7 /bin/bash
将新增的6387节点(空槽号)作为master节点加入原集群
redis-cli --cluster add-node IP:6387 IP:6381
6387就是将要作为master新增节点6381 就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群

检查集群情况
redis-cli --cluster check 127.0.0.1:6381
可以看到6387在集群上,但没有分配槽位(0 slots),加入了集群,但没完全加入。

重新分派槽号命令:
redis-cli --cluster reshard IP地址:端口号
这里我执行的命令是,相当于对6381Redis集群进行了槽位重新分配
redis-cli --cluster reshard 192.168.248.128:6381

要分给新的集群多少个节点?这里我们四台均分,每台4096
输入4096,进行回车



接着yes
等待分配完成
再次检查集群情况
redis-cli --cluster check 127.0.0.1:6381
已经有槽位了,原来的集群槽位每个节点平均的匀出了一部分给新的节点。
为什么这么分配呢?我们思考一下,是把原来的三个节点全都打乱重新分配更快还是每个节点都只匀出固定的一部分给新节点更快。

接下来为主节点6387分配从节点6388
redis-cli --cluster add-node ip:新slave端口 ip:新master端口 --cluster-slave --cluster-master-id 新主机节点ID
这里我执行的命令,新主机节点ID 需要改为集群中6387的节点ID
redis-cli --cluster add-node 192.168.248.128:6388 192.168.248.128:6387 --cluster-slave --cluster-master-id fafca651f3f5dafd2f61922baf8190ec42c848e7
再次检查集群状态(不一定非得6381,集群的主节点任意一个都可以)
redis-cli --cluster check 127.0.0.1:6381

好节点已经分配完成。
最后再说明一下,通过观察集群的key我们发现,重新分配槽位后数据也相应的变化过了(redis做的)。

演示集群缩容
扩容完了,我们流量高峰期撑过去了,现在不需要集群那么多机器了,为了合理利用资源我们又要进行缩容。
将扩容好的四主四从缩容回三主三从。
检查集群情况1获得6388的节点ID
redis-cli --cluster check 192.168.248.128:6382

命令:
redis-cli --cluster del-node ip:从机端口 从机6388节点ID
执行的命令
redis-cli --cluster del-node 192.168.248.128:6388 f7089480b0c40ef966d907cb930c1d4697f3f9a6
检查一下发现,6388被删除了,只剩下7台机器了。
redis-cli --cluster check 192.168.248.128:6382

将6387的槽号清空,重新分配,本例将清出来的槽号都给6382
先进入槽位重新分配
redis-cli --cluster reshard 192.168.248.128:6381

现在我们是去掉一个节点,所以是4096


这里我们选择全部给6382节点,输入6382的节点ID,下一步会让我们输入谁来出这个节点(删除哪个节点)。
注意!!! 这里分配的接收节点只能是主节点,我们之前测试容错时把6381和6382的主从关系互换了,所以这里6382是主节点。

接下来输入从哪里出这个节点,我们输入6387的节点ID

回车,会出现下一个,这里意思是可以从多个节点出,但是我们就只需要一个,所以输入done,敲回车即可,就会重新开始分配。


接着,输入yes表示确认重新分配。
完成。
再次检查集群状态。
redis-cli --cluster check 192.168.248.128:6382

接着,将6387节点删除。
redis-cli --cluster del-node ip:从机端口 从机6387节点ID
redis-cli --cluster del-node 192.168.248.128:6387 fafca651f3f5dafd2f61922baf8190ec42c848e7
再次检查集群状态。
redis-cli --cluster check 192.168.248.128:6382

缩容完成,我们的Redis的弹性扩缩容,以及容错切换已经学习完成!!!
可以在项目中灵活的进行扩容缩容啦~