前言
这两天工作需求研究了下 Django 如何进行日志配置,做下简单的总结。
需求
- 控制台需要打印日志,格式要求如下,显示时间,trace_id, 线程号,方法名,日志打印文件行数,日志级别,日志信息:
2024-07-19 09:02:34 [5aa0d491-d155-439e-b240-dd21a2a4eef6] [Thread-6] [healthcheck] [views.py:25] [INFO]- p
同时需要将日志以 JSON 格式写入日志文件,info 级别日志写入 info.log, error 及以上级别日志写入 error.log,便于后边通过
Filebeat将日志文件采集到 Kafka 中(在下篇文章会总结如何使用 Filebeat 采集日志输出 Kafka, 然后使用 FlinkSQL 将 kafka 中的日志写入 Clickhouse 进行日志查询与分析),写入日志文件的内容如下: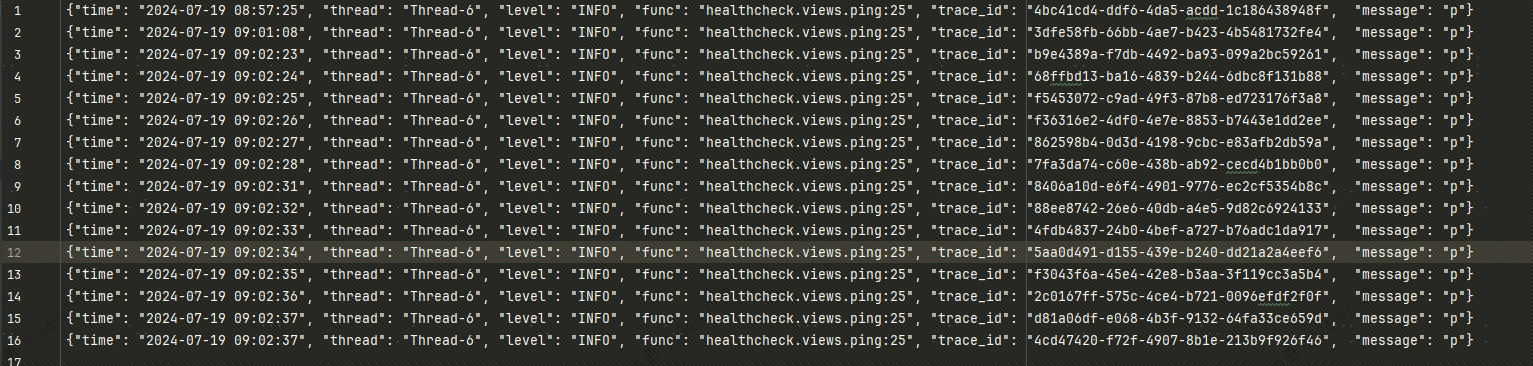
对于单个请求上下文内的所有日志拥有同一个 trace_id (全局唯一),比如说用户请求我们的接口,我们会在接口中将耗时任务发送到 celery 中异步处理,该 celery 任务应该和我们的请求使用一个 trace_id, 下边我会说明如何在请求同步代码和 celery 异步任务中使用同一个 trace_id。
同样的,如果说用户请求我们的接口,我们需要调用外部接口,那么我们就可以通过 headers 之类的将 trace_id 传递给外部服务。
settings 配置
首先需要在 Django 的 settings.py文件中对日志进行配置:
from logging.config import dictConfig
from settings.log import InfoFilter, TraceIdFilter
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
LOG_PATH = f"{os.path.join(BASE_DIR, 'logs')}"
if not os.path.exists(LOG_PATH):
os.makedirs(LOG_PATH)
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
# 用于在控制台输出格式化日志
'simple': {
'format': '%(asctime)s [%(trace_id)s] [%(threadName)s] [%(name)s] [%(filename)s:%(lineno)d] [%(levelname)s]- %(message)s',
"datefmt": "%Y-%m-%d %H:%M:%S"
},
# 用于保存 JSON 格式日志到日志文件中
'standard': {
'format': '{"time": "%(asctime)s", "thread": "%(threadName)s", "level": "%(levelname)s", "func": "%(name)s.%(module)s.%(funcName)s:%(lineno)d", "trace_id": "%(trace_id)s", "message": "%(message)s"}',
'datefmt': '%Y-%m-%d %H:%M:%S'
}
},
'filters': {
'info_filter': {
'()': InfoFilter,
},
'trace_id_filter': {
'()': TraceIdFilter,
}
},
'handlers': {
'console': {
'level': 'INFO',
'class': 'logging.StreamHandler',
'formatter': 'simple',
'filters': ['trace_id_filter']
},
'info_file': {
'level': 'INFO',
'class': 'logging.handlers.TimedRotatingFileHandler',
'filename': os.path.join(LOG_PATH, 'info.log'),
'when': "D",
'backupCount': 7, # 保留最近7天的日志文件
'formatter': 'standard',
'filters': ['trace_id_filter', 'info_filter']
},
'error_file': {
'level': 'ERROR',
'class': 'logging.handlers.TimedRotatingFileHandler',
'filename': os.path.join(LOG_PATH, 'error.log'),
'when': "D",
'backupCount': 7, # 保留最近7天的日志文件
'formatter': 'standard',
'filters': ['trace_id_filter']
},
},
'loggers': {
'celery': {
'handlers': ['console', 'info_file', 'error_file'],
'propagate': False,
'level': 'INFO',
},
# root logger
'': {
'handlers': ['console', 'info_file', 'error_file'],
'propagate': False,
'level': 'INFO',
}
}
}
dictConfig(LOGGING)
InfoFilter是为了防止 info.log 文件中出现 error 及以上日志TraceIdFilter用于给我们自己打印的日志加上 trace_id, 并且过滤掉没有 trace_id 的日志,有一些第三方包也会打印日志,但是没有 trace_id, 这些日志不是我们想要的,不利于后续进行日志分析,属于垃圾日志,应当过滤掉。
InfoFilter 和 TraceIdFilter都在和 settings.py 同级目录下的 log.py 文件中:
import os
from datetime import datetime
import json
import logging
import contextvars
import uuid
# 自定义 Trace ID 管理器,保证在一个请求上下文中 trace_id 一样且唯一
trace_id_var = contextvars.ContextVar('trace_id', default=None)
def set_trace_id(trace_id=None):
if trace_id is None:
trace_id = str(uuid.uuid4())
trace_id_var.set(trace_id)
return trace_id
def get_trace_id():
return trace_id_var.get()
class TraceIdFilter(logging.Filter):
def filter(self, record):
# 给日志加上 trace_id
record.trace_id = get_trace_id()
# 过滤掉没有 trace_id 的日志
if not record.trace_id:
return False
return True
class InfoFilter(logging.Filter):
# 过滤掉第三方库的日志
def filter(self, record):
if record.name == 'casbin.policy':
return False
# 过滤掉 info 以上级别(error 等)日志
return record.levelno < logging.ERROR
# trace_id 中间件,每一个请求都会通过该中间件生成一个唯一 trace_id
class TraceIdMiddleware:
def __init__(self, get_response):
self.get_response = get_response
def __call__(self, request):
# 设置 trace ID
set_trace_id()
response = self.get_response(request)
return response
两个文件目录结构如下: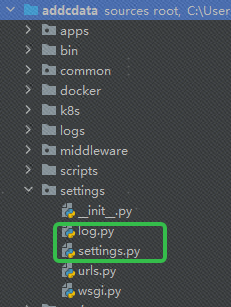
同时我们需要将上边 log.py中的 TraceIdMiddleware 中间件在 settings.py 中进行注册: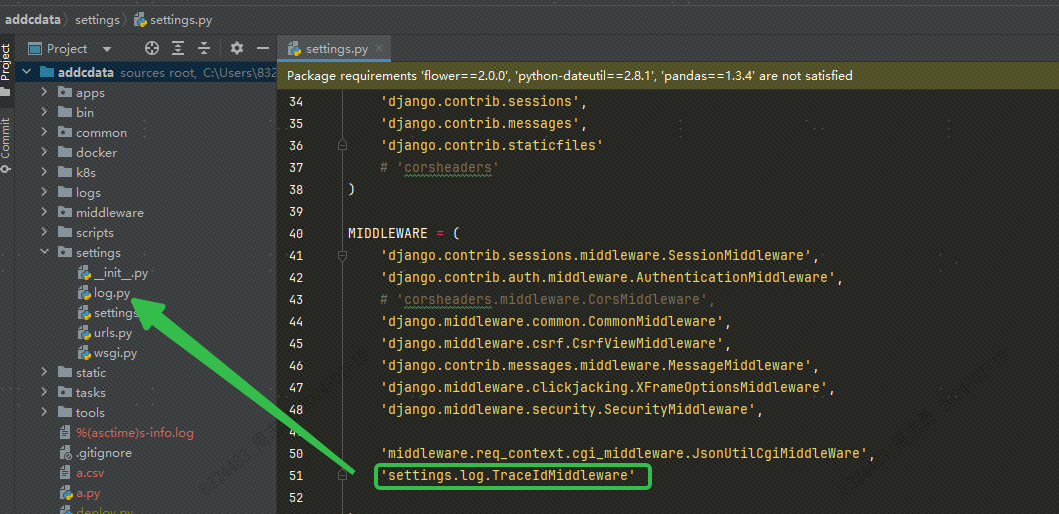
celery 任务增加 trace_id
上边的配置完后,就可以启动我们的 Django 项目,请求下接口打印日志,可以观察到在项目目录下会生成 log 文件夹,里边同时包含 info.log 和 error.log文件。
我们进行简单的接口打印日志验证,接口代码以及日志内容打印如下: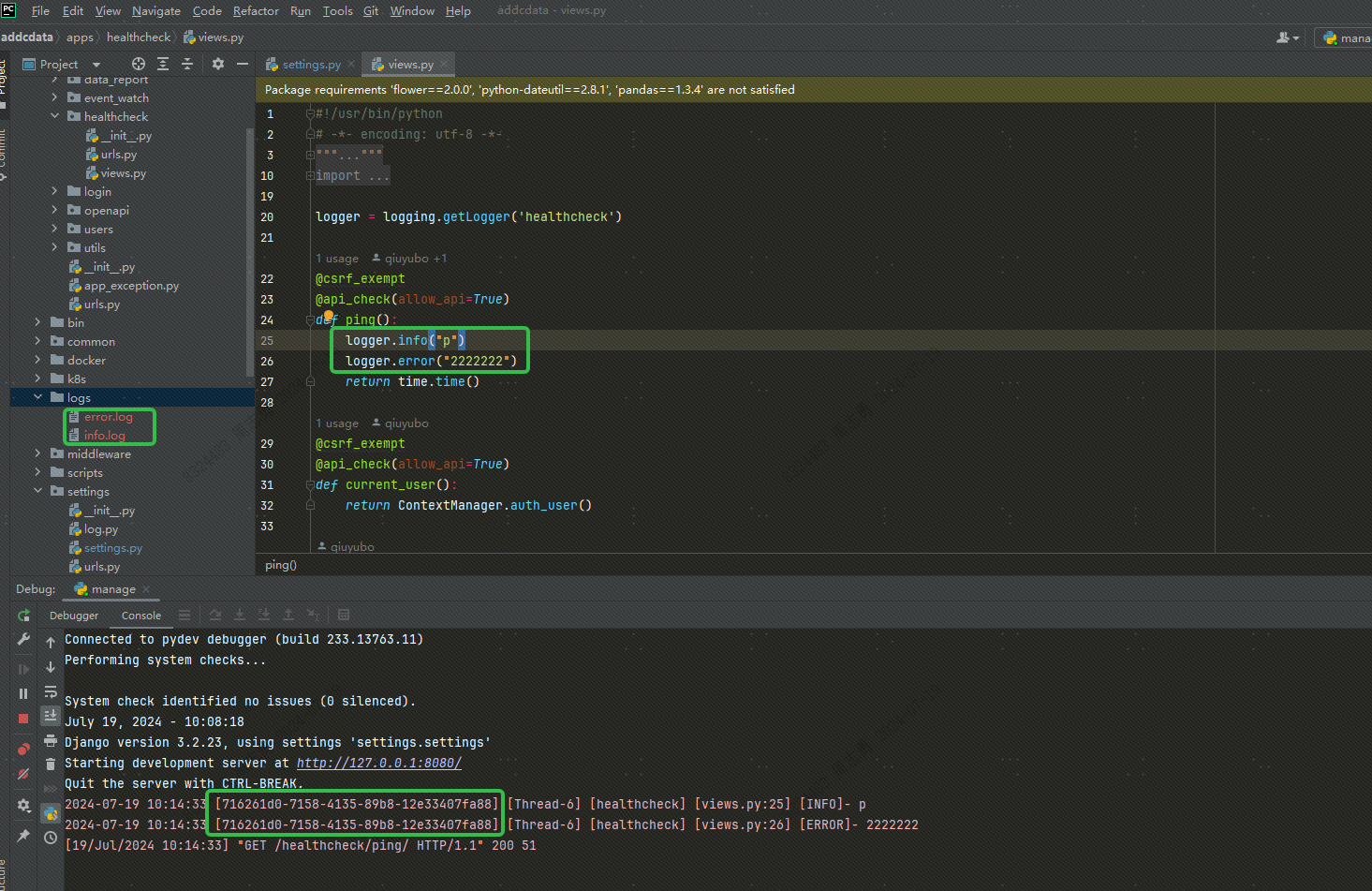
可以看到两个级别的日志分别存储到了两个日志文件中,并且在控制台进行了打印,并且两个日志的 trace_id 是一样的。
上边的都是同步代码中的日志打印,如果说我们的代码中发送了一个 celery 任务,如何让 celery 的异步任务中也使用同一个 trace_id? 其实也很简单,我们在发送异步任务的时候,只需要获取到当前上下文件中的 trace_id,然后作为参数同时发送给异步任务就行了: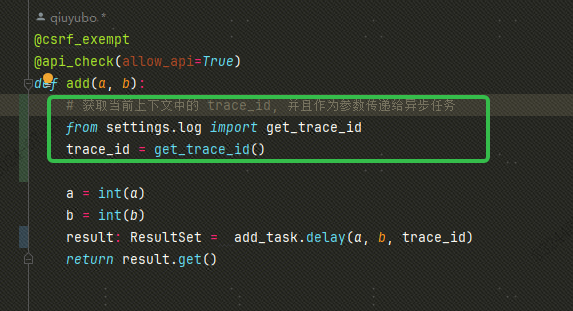
然后在我们的异步任务中将该 trace_id 设置为当前上下文中的 trace_id: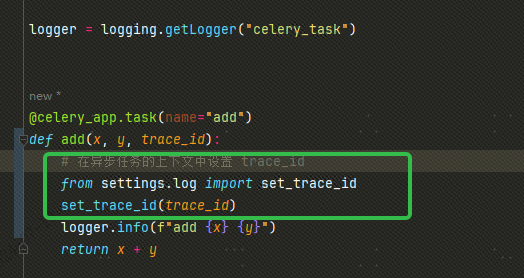
上边的 get_trace_id 和 set_trace_id 都是 log.py 中定义的。
总结
本文总结了如何在 Django 中进行日志配置,不同级别的日志输出到不同的文件中,以及如何给日志加上唯一 trace_id。
后边我会总结如何将日志文件通过 filebeat 采集到 kafka,然后使用 FlinkSQL 实时将 kafka 中的日志数据同步到 clickhouse 中进行日志分析。