YOLOv7是YOLO系列目标检测模型的最新版本之一,由Chien-Yao Wang等人在2022年提出。YOLOv7在YOLOv5的基础上进行了多项创新和改进,旨在提供更高的检测精度,同时保持较快的检测速度。以下是YOLOv7的一些关键特性和改进点:
特性与改进
EffiDet-D0 Backbone:
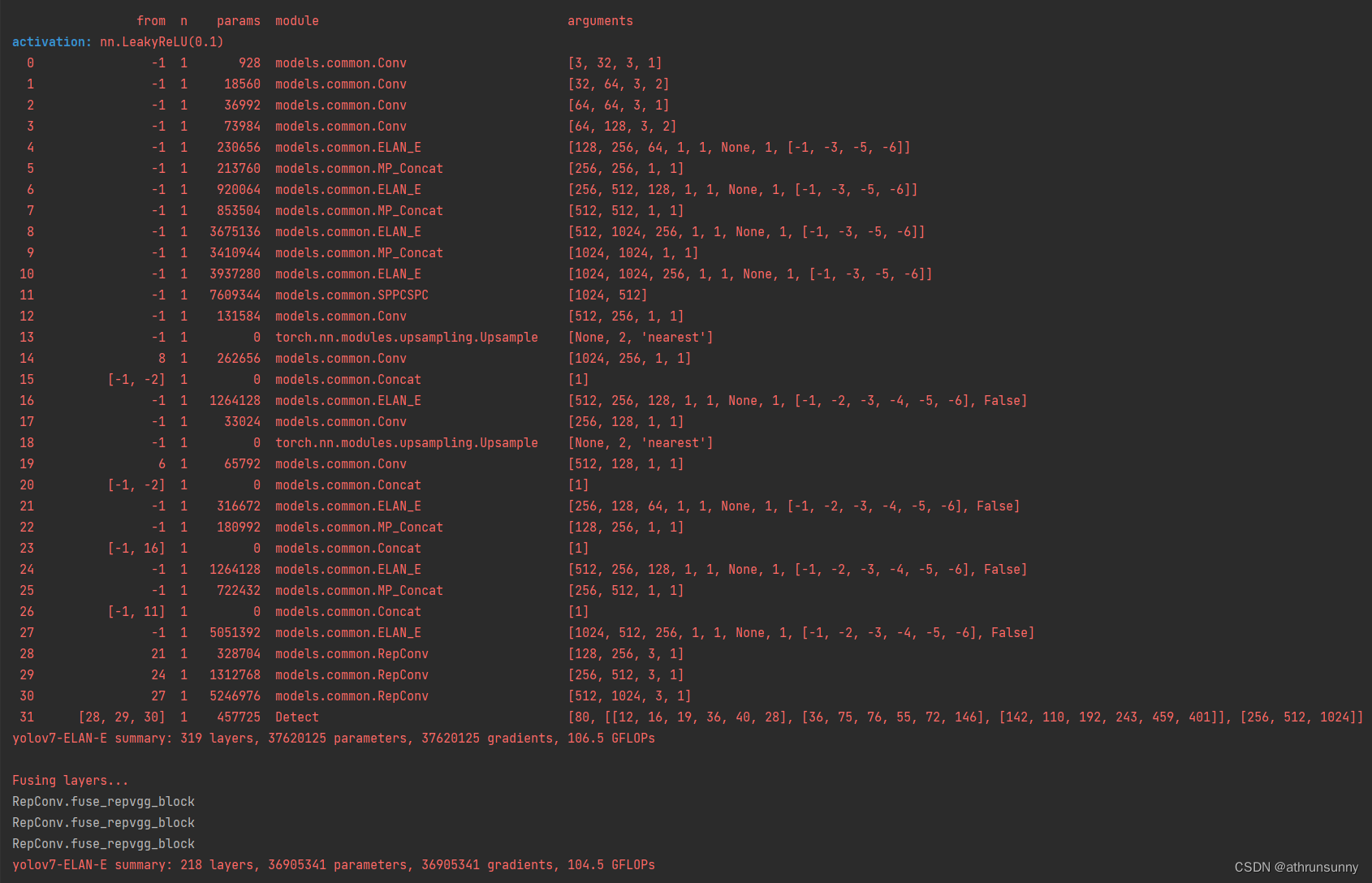
YOLOv7采用了一个名为EffiDet-D0的backbone,这是基于EfficientNet的变体,它结合了EfficientNet-B6和BiFPN(Bi-directional Feature Pyramid Network)的优点。EffiDet-D0提供了强大的特征提取能力,同时保持计算效率。自适应聚合注意力模块(E-ELAN):
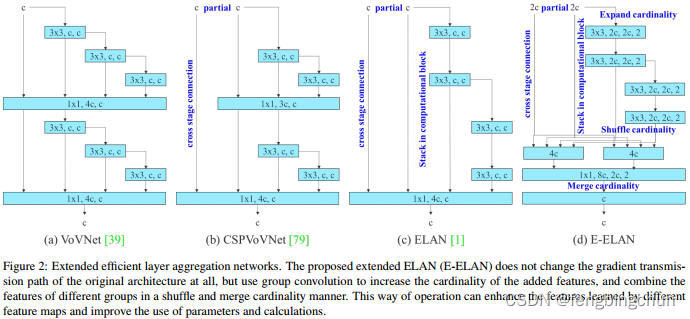
YOLOv7引入了一种新的注意力机制,称为E-ELAN(Enhanced Efficient Layer Aggregation Network),用于更有效地融合不同层次的特征图。E-ELAN模块可以自动调整不同特征的重要性,提高模型的鲁棒性和准确性。动态头部设计:
在检测头部分,YOLOv7采用了动态设计,允许模型根据输入图像的尺寸自动调整其结构,这意味着YOLOv7可以在不同的输入分辨率下保持稳定的性能。自适应锚点机制:
YOLOv7使用了自适应锚点(Adaptive Anchor)机制,这使得模型能够更好地适应不同尺度和比例的对象,提高小目标的检测性能。集成多种优化技术:
YOLOv7集成了多种先进的优化技术,包括但不限于Mish激活函数、空间金字塔池化(SPP)、DropBlock正则化、CutMix数据增强等,这些技术共同提升了模型的检测效果。超参数优化:
YOLOv7对训练过程中的超参数进行了细致的优化,包括学习率调度、权重衰减、批量大小等,以达到最佳的训练效果。
训练与评估
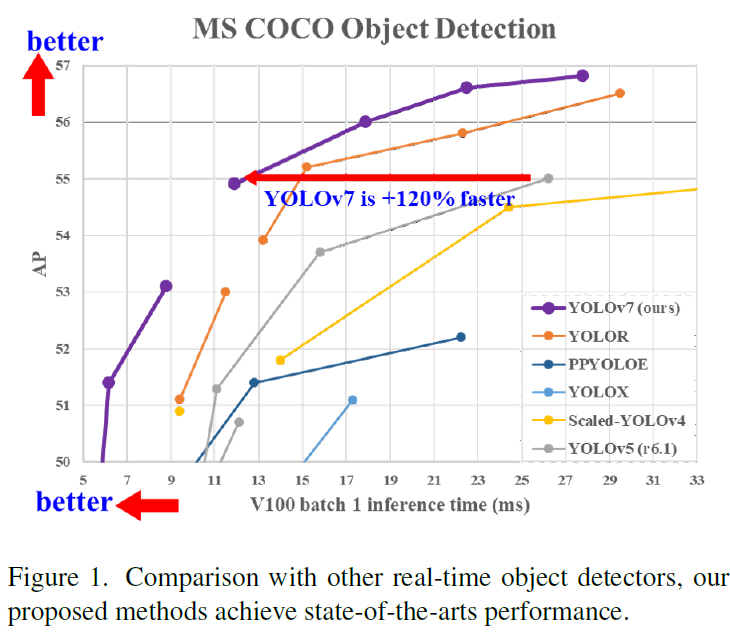
YOLOv7在COCO数据集上进行了广泛的实验,与其他目标检测模型相比,它在AP(平均精度)和FPS(每秒帧数)之间取得了很好的平衡。具体而言,YOLOv7在保持高检测速度的同时,其检测精度接近甚至超过了某些复杂的模型,如DETR和SparseRCNN。
实现与应用
YOLOv7的代码通常使用PyTorch框架编写,并且是开源的,这使得研究者和开发者能够轻松地对其进行修改和扩展。YOLOv7可以应用于各种计算机视觉任务,包括实时视频监控、自动驾驶车辆、无人机视觉系统等。
结论
YOLOv7代表了YOLO系列在目标检测领域的最新进展,它通过一系列创新性的设计和优化,实现了检测速度与精度之间的良好折衷,成为目标检测领域的一个重要里程碑。