一、判别式模型和生成式模型
1)判别式模型Discriminative
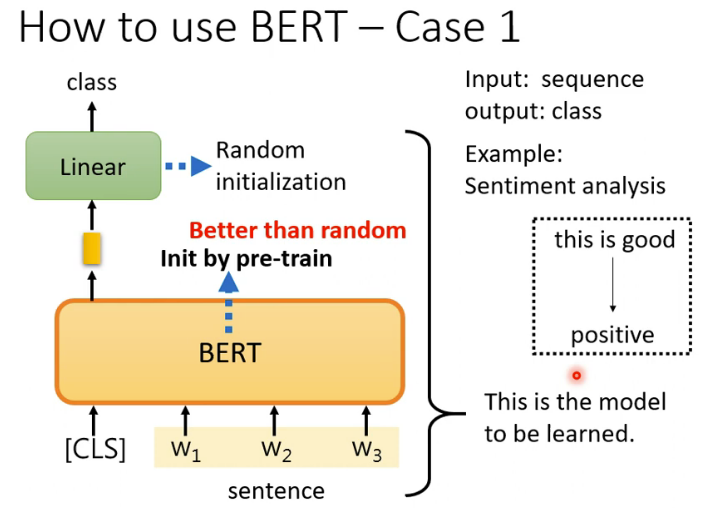
①给某一个样本,判断属于某个类别的概率,擅长分类任务,计算量少。(学习策略函数Y =f(X)或者条件概率P(YIX))
②不能反映训练数据本身的特性
③学习成本低(需要的训练样本量少)
④无法转为生成式
2)生成式模型Generative
①学习联合概率密度分布概率P(X,Y,学习所有数据的分布
②能够反映训练数据本身的特性,能掌握数据本身的边界信息
③学习成本高(需要的样本数更多)0
④一定条件下可以转换为判别式
- 示意图

二、生成式模型技术路径
2.1 AutoEncoder自编码器
- 组成
编码器和解码器(其实就是特征压缩和特征拟合) - 示意图

- 注意
①AE中的隐变量是不具有语义特性的

2.2 VAE变分自编码器(解决生成特定内容图像的问题)
- 原理
每一个特征对应一个正态分布的区间,比如微笑、皮肤、性别、胡须、毛发颜色等采样取差值

- 使用
那我们只需要修改某个特征分布就可以达到想要的效果 - 缺陷
联合高斯密度生成信息损失大,图片比较粗糙
2.3 Diffusion Model扩散模型
- 需求
保留更多图片信息 - 包括两个过程
①正向扩散过程:向输入数据中逐渐加入噪声的过程
②反向去噪过程:通过去噪方式学习数据生成过程 - 示意图
 + 预测的是什么?
+ 预测的是什么?
预测的是前一步正向扩散加的噪声 - 步骤
①每一步迭代都是从数据集中取一个初始的图像样本作为Xo
②把Xo从0到1000之间采样一个时间步的Xt,就是步数,比如取500步,就是给图片加500步噪声
③训练利用X500得到X499这样一个去噪过程 - 公式

- 使用模型案例
DiT Block

2.4 Stabel Diffusion 模型结构
与DM的不同(引入条件信息:对象分类、文本、排版布局、图片参考)

特点
①引入VAE模型减少计算量(图像特征压缩到原始尺寸的1/4),推理的时间复杂度会降低很多
②通过统一方式注入条件类型到模型
③CLIP只支持英文版本更新迭代(以前用的CLIP,普遍有文本内容理解问题,容易生成图文不对齐的情况)

特制模型(C站扩展举例)
- Indigo Furry mix
模型地址:https://civitai.com/models/34469?modelVersionId=109229
发布者:indigowing(个人主页:https://civitai.com/user/indigowing/models)
介绍:这是一系列的模型,主要专注于雄性兽/龙人(还有非全年龄向内容)。其模型有偏混合向的,偏动漫向的,还有偏现实向的。所以可根据你想画什么风格画风的画,来选择对应表现较好的模型 作者:琉璃汐阳 https://www.bilibili.com/read/cv24890845/ 出处:bilibili

2. Crosskemono(furry_model&human_model)
模型地址:https://civitai.com/models/11888?modelVersionId=47368
注:此系列模型附带VAE,配合它来一起使用(VAE的作用可以理解为滤镜,在生成 AI 绘画时,会对输出的颜色和线条产生影响)
发布者:toynya(个人主页:https://civitai.com/user/toynya/models)
介绍:这个系列的模型主要是萌系日系那种风格的,可生成可爱的雄性或者雌性兽人,据演示图来看还可以生成兽娘(Furry程度表中的2级福瑞)。不过需要注意,这个模型也会生成非全年龄向的内容 作者:琉璃汐阳 https://www.bilibili.com/read/cv24890845/ 出处:bilibili

- 定制路线
①阶段一:图文对其训练,得出基础模型
②阶段二:图文对其训练,得出社区微调模型 - 使用