目录
大模型的结构主要分为三种
Encoder-only(自编码模型,代表模型有BERT),Decoder-only(自回归模型,代表模型有GPT系列和LLaMA),Encoder-Decoder(序列到序列模型,代表模型有GLM),大语言模型在自然语言处理和文本处理领域具有广泛的应用,其应用场景多种多样。
参考:
https://zhuanlan.zhihu.com/p/687531361
大模型分布式训练方法主要包括以下几种:
数据并行:这是最常见的分布式训练策略。数据被切分为多份并分发到每个设备(如GPU)上进行计算。每个设备都拥有完整的模型参数,计算完成后,设备间的梯度会被聚合并更新模型参数。这种方法能够充分利用多个设备的计算能力,加快训练速度。
模型并行:在模型并行中,模型的不同部分被分配到不同的设备上进行计算。每个设备仅拥有模型的一部分,这使得超大的模型能够在有限的计算资源上训练。模型并行通常与流水线并行结合使用,数据按顺序经过所有设备进行计算。
流水线并行:流水线并行是一种特殊的模型并行方式。它将网络切分为多个阶段,并将这些阶段分发到不同的设备上进行计算。数据按照流水线的方式依次通过每个阶段,从而实现高效的并行计算。
混合并行:混合并行结合了上述多种并行策略。根据模型的结构和计算资源的特点,可以选择最适合的并行策略组合进行训练。
参考:
https://zhuanlan.zhihu.com/p/645649292
token Token是构成句子的基本单元
但并不一定是最小单元。Token可以是一个单词、一个字符或一个子词,具体取决于使用的分词方法。在自然语言处理(NLP)中,常见的分词方法有以下几种:
在进行文本分词时,可以使用不同的分词方法来拆分 "我喜欢吃红色的苹果" 这句话。以下是几种常见的分词方法及其结果:
1. 词级别的分词
每个单词或词组作为一个token。这种方法在中文中一般使用词典或分词算法进行分词。 例如:
我 / 喜欢 / 吃 / 红色的 / 苹果
这句话被分成了5个token: "我"、"喜欢"、"吃"、"红色的" 和 "苹果"。
2. 字符级别的分词
每个字符作为一个token。 例如:我 / 喜 / 欢 / 吃 / 红 / 色 / 的 / 苹 / 果
结巴分词
import jieba
sentence = "我喜欢吃红色的苹果"
tokens = jieba.lcut(sentence)
print(tokens)运行上述代码可能会得到以下结果:
['我', '喜欢', '吃', '红色', '的', '苹果']
总之,分词的方法不同,结果也会有所不同。在实际应用中,选择合适的分词方法取决于具体的任务和需求。
GPT-3/4训练流程
GPT-3/4训练流程模型训练分为四个阶段:
预训练(Pretraining)、监督微调SFT(Supervised Finetuning)、奖励建模RM(Reward Modeling)、以及强化学习RL(Reinforcement Learning)。
ChatGPT是最典型的一款基于OpenAI的GPT架构开发的大型语言模型,主要用于生成和理解自然语言文本。其训练过程分为两个主要阶段:预训练和微调。
以下是关于ChatGPT训练过程的详细描述:
- 预训练:在预训练阶段,模型通过学习大量无标签文本数据来掌握语言的基本结构和语义规律。这些数据主要来源于互联网,包括新闻文章、博客、论坛、书籍等。训练过程中,模型使用一种名为“掩码语言模型”(Masked Language Model, MLM)的方法。这意味着在训练样本中,一些词汇会被随机掩盖,模型需要根据上下文信息预测这些被掩盖的词汇。通过这种方式,ChatGPT学会了捕捉文本中的语义和语法关系。
- 微调:在微调阶段,模型使用特定任务的标签数据进行训练,以便更好地适应不同的应用场景。这些标签数据通常包括人类生成的高质量对话,以及与特定任务相关的问答对。在微调过程中,模型学习如何根据输入生成更准确、更相关的回复。
- 损失函数和优化:训练过程中,模型会最小化损失函数,以衡量其预测结果与真实目标之间的差异。损失函数通常采用交叉熵损失(Cross-Entropy Loss),它衡量了模型生成的概率分布与真实目标概率分布之间的差异。训练过程中使用优化算法(如Adam)来更新模型参数,以便逐步降低损失函数的值。
- Tokenization:在进入模型之前,输入和输出文本需要被转换为token。Token通常表示单词或字符的组成部分。通过将文本转换为token序列,模型能够更好地学习词汇之间的关系和结构。
- 参数共享:GPT-4架构采用了参数共享的方法,这意味着在预训练和微调阶段,模型的部分参数是共享的。参数共享可以减少模型的复杂性,提高训练效率,同时避免过拟合问题。
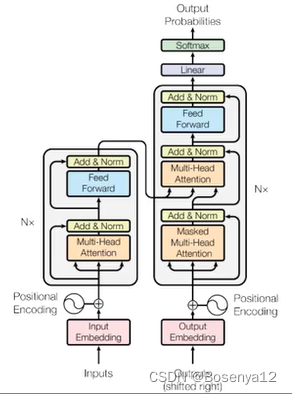
- Transformer架构:ChatGPT基于Transformer架构进行训练。这种架构使用自注意力(self-attention)机制,允许模型在处理序列数据时,关注与当前词汇相关的其他词汇,从而捕捉文本中的长距离依赖关系。此外,Transformer还包括多层堆叠的编码器和解码器结构,以便模型学习更为复杂的语言模式。
- 正则化和抑制过拟合:为了防止模型在训练过程中过拟合,可以采用各种正则化技巧。例如,Dropout技术可以在训练时随机关闭部分神经元,从而降低模型复杂性。另一种方法是权重衰减,通过惩罚较大的权重值来抑制过拟合现象。
- 训练硬件和分布式训练:由于GPT-4模型的庞大规模,其训练过程通常需要大量计算资源。因此,训练通常在具有高性能GPU或TPU的分布式计算系统上进行。此外,为了提高训练效率,可以采用各种分布式训练策略,如数据并行、模型并行等。
- 模型验证和评估:在训练过程中,需要定期对模型进行验证和评估,以监控其性能和收敛情况。通常情况下,会将数据集划分为训练集、验证集和测试集。模型在训练集上进行训练,在验证集上进行调优,并在测试集上进行最终评估。
- 模型调优和选择:在模型微调阶段,可以尝试不同的超参数设置,以找到最优的模型配置。这可能包括学习率、批次大小、训练轮数等。最终选择在验证集上表现最佳的模型作为最终输出。
总之,ChatGPT的训练过程包括预训练和微调两个阶段,通过学习大量无标签文本数据和特定任务的标签数据,模型能够掌握语言的基本结构和语义规律。在训练过程中,采用了诸如Transformer架构、参数共享、正则化等技术,以实现高效、可靠的训练。训练过程还涉及模型验证、评估和调优,以确保最终产生的模型能够提供高质量的自然语言生成和理解能力。

























![[初始计算机]——计算机网络的基本概念和发展史及OSI参考模型](https://img-blog.csdnimg.cn/direct/3b7ecfb50593488a85d6a18de8a57bc8.gif)