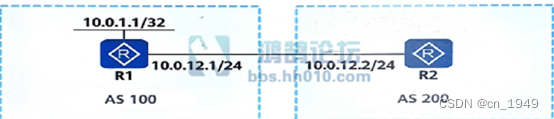
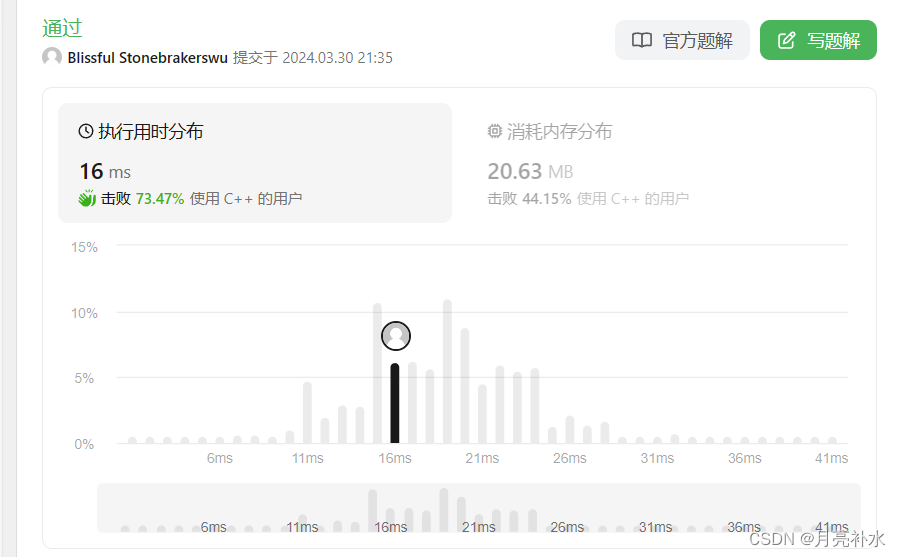
数据加载
国内用户建议到 https://modelscope.cn/datasets 下载数据,但是下载后发现并不能和huggingface datasets无缝衔接,而是报了个错
- AttributeError: ‘MsDataset’ object has no attribute ‘column_names’
因此,可以继续采用魔搭下载数据,但是转换到dataset适应的形式,顺便也对整个数据过程更加了解一下。
但最简单的修改方法是:
dataset = MsDataset.load()
train_dataset = dataset.to_hf_dataset() # 魔搭社区下载
然后是:
- https://github.com/modelscope/modelscope/blob/a903ec7a898f5dfb44349e2ce15971ec5f08e528/examples/pytorch/llm/utils/dataset.py#L34
- https://github.com/hiyouga/LLaMA-Factory/blob/6c94305e4746c9a735ff62a6428e295d1a67da52/src/llmtuner/data/loader.py#L83
几种方法
train_dataset = load_from_disk(args.dataset_name, split="train[:1024]")
def preprocess_function(examples):
queries = examples["sentence"]
queries = get_detailed_instruct(task, queries)
batch_dict = tokenizer(queries, max_length=args.max_length - 1, return_attention_mask=False, padding=False, truncation=True)
batch_dict['input_ids'] = [input_ids + [tokenizer.eos_token_id] for input_ids in batch_dict['input_ids']]
batch_dict = tokenizer.pad(batch_dict, padding=True, return_attention_mask=True, return_tensors='pt')
result = {f"sentence_{k}": v for k, v in batch_dict.items()}
queries = examples["positive"]
batch_dict = tokenizer(queries, max_length=args.max_length - 1, return_attention_mask=False, padding=False, truncation=True)
batch_dict['input_ids'] = [input_ids + [tokenizer.eos_token_id] for input_ids in batch_dict['input_ids']]
batch_dict = tokenizer.pad(batch_dict, padding=True, return_attention_mask=True, return_tensors='pt')
for k, v in batch_dict.items():
result[f"positive_{k}"] = v
queries = examples["negative"]
batch_dict = tokenizer(queries, max_length=args.max_length - 1, return_attention_mask=False, padding=False, truncation=True)
batch_dict['input_ids'] = [input_ids + [tokenizer.eos_token_id] for input_ids in batch_dict['input_ids']]
batch_dict = tokenizer.pad(batch_dict, padding=True, return_attention_mask=True, return_tensors='pt')
for k, v in batch_dict.items():
result[f"negative_{k}"] = v
result["labels"] = [0] * len(examples["sentence"])
return result
processed_datasets = dataset.map(
preprocess_function,
batched=True,
remove_columns=dataset["train"].column_names,
desc="Running tokenizer on dataset",
)