1 缘起
最近在研究与应用混合搜索,
存储介质为ES,ES作为大佬牌数据库,
非常友好地支持关键词检索和向量检索,
当然,支持混合检索(关键词检索+向量检索),
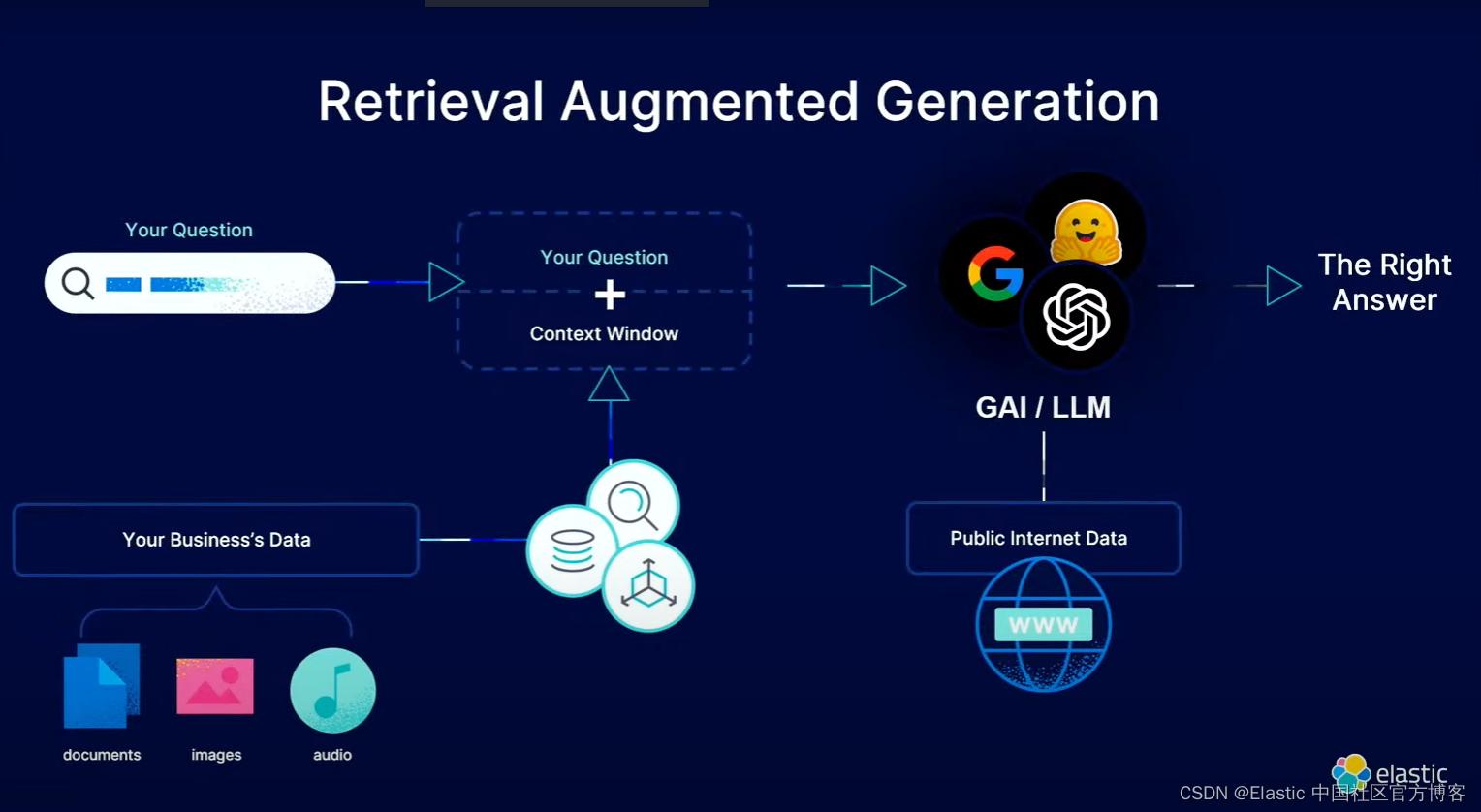
是提升LLM响应质量RAG(Retrieval-augmented Generation)的一种技术手段,
那么,如何通过ES实现混合搜索呢?
请看本篇文章。
本系列分为两大部分:实践和理论。
先讲实践,应对快速开发迭代,可快速上手实践;
再讲理论,应对优化,如归一化。
RAG理论:ES混合搜索BM25+kNN(cosine)以及归一化https://blog.csdn.net/Xin_101/article/details/140237669

2 实践
2.1 环境准备
2.1.1 部署ES
- 下载ES镜像:8.12.2版本
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.12.2
- 下载ik分词器
https://github.com/infinilabs/analysis-ik/releases
选择与ES版本一致或者可用的版本,这里选择8.12.2版本分词器。

添加分词器
将分词器文件添加到目录:/home/xindaqi/data/es-8-12-2/plugins
新建分词器文件夹:mkdir -p /home/xindaqi/data/es-8-12-2/plugins/ik_analyzer_8.12.2
将zip文件复制到文件夹:ik_analyzer_8.12.2启动ES
docker run -dit \
--restart=always \
--name es01-8-12-2 \
-p 9200:9200 \
-p 9300:9300 \
-v /home/xindaqi/data/es-8-12-2/data:/usr/share/elasticsearch/data \
-v /home/xindaqi/data/es-8-12-2/logs:/usr/share/elasticsearch/logs \
-v /home/xindaqi/data/es-8-12-2/plugins:/usr/share/elasticsearch/plugins \
-e ES_JAVA_OPS="-Xms512m -Xmx1g" \
-e discovery.type="single-node" \
-e ELASTIC_PASSWORD="admin-es" \
-m 1GB \
docker.elastic.co/elasticsearch/elasticsearch:8.12.2
2.1.2 数据准备
实践之前,需要准备数据,包括索引和索引中存储的数据。
为了演示混合搜索,这里创建两种类型的数据:text和dense_vector。
(1)创建索引
curl -X 'PUT' \
'http://localhost:9200/vector_5' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'Authorization: Basic ZWxhc3RpYzphZG1pbi1lcw==' \
-d '{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 1,
"refresh_interval": "3s"
}
},
"mappings": {
"properties": {
"dense_values": {
"type": "dense_vector",
"dims": 5,
"index": true,
"similarity": "cosine"
},
"id": {
"type": "keyword"
},
"ik_text": {
"type": "text",
"analyzer": "ik_max_word"
},
"default_text": {
"type": "text"
},
"timestamp": {
"type": "long"
},
"dimensions": {
"type": "integer"
}
}
}
}'
(2)新建数据
新建两条数据:
curl -X POST 'http://localhost:9200/vector_5/_doc/1' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic ZWxhc3RpYzphZG1pbi1lcw==' \
--data '{
"dense_values": [0.1, 0.2, 0.3, 0.4, 0.5],
"id": "1",
"ik_text": "今天去旅游了",
"default_text":"今天去旅游了",
"timestamp": 1715659103373,
"dimensions": 5
}'
curl -X POST 'http://localhost:9200/vector_5/_doc/2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic ZWxhc3RpYzphZG1pbi1lcw==' \
--data '{
"dense_values": [0.1, 0.2, 0.3, 0.4, 0.5],
"id": "1",
"ik_text": "好美的太阳",
"default_text":"好美的太阳",
"timestamp": 1715659103373,
"dimensions": 5
}'
2.2 向量搜索
kNN搜索
ES中向量搜索使用k-Nearest Neighbor(k最近邻分类算法)进行搜索。
输入的请求参数如下:
| 参数 | 参数 | 描述 |
|---|---|---|
| knn | 向量搜索k-Nearest Neighbor | |
| field | 向量字段名称 | |
| query_vector | 向量值 | |
| k | 召回结果数量 | |
| num_candidates | 召回范围,每个分片选取的数量 |
请求样例如下:
由样例可知,存储向量数据的字段名称为:dense_values,填充向量值字段为query_vector(为固定属性),召回结果k为3个,每个分片选择100条数据(num_candidates),最大值为:10000。
实际应用过程中,又有向量数据较多(依据维度而定),为节约内存,检索时,在结果中排除,excludes。
curl -X POST 'http://localhost:9200/vector_5/_search' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic ZWxhc3RpYzphZG1pbi1lcw==' \
--data '{
"knn": {
"field": "dense_values",
"query_vector": [
0.1,
0.1,
0.1,
0.1,
0.1
],
"k": 3,
"num_candidates": 100
},
"_source": {
"excludes": [
"dense_values"
]
}
}'
检索结果如下,
由于创建过程中使用的向量数据相同,因此计算的结果也是相同的,
使用
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.8427159,
"hits": [
{
"_index": "vector_5",
"_id": "1",
"_score": 0.8427159,
"_source": {
"id": "1",
"ik_text": "今天去旅游了",
"default_text": "今天去旅游了",
"timestamp": 1715659103373,
"dimensions": 5
}
},
{
"_index": "vector_5",
"_id": "2",
"_score": 0.8427159,
"_source": {
"id": "1",
"ik_text": "好美的太阳",
"default_text": "好美的太阳",
"timestamp": 1715659103373,
"dimensions": 5
}
}
]
}
}
2.2 混合搜索
混合搜索即将搜索拆分成多个部分,每个部分使用不同的权重,实现混合搜索的效果。
ES中使用boost参数来分配不同部分的权重,搜索案例如下。
由案例可知,混合搜索使用关键词+向量搜索,关键词b1与向量总权重b2,其中b1+b2=1,
案例中关键词权重为0.6,向量权重0.4,
关键词搜索将搜索的内容映射到query上,权重映射到boost上,
default_text为实际存储的属性名称。
curl -X POST 'http://localhost:9200/vector_5/_search' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic ZWxhc3RpYzphZG1pbi1lcw==' \
--data '{
"query": {
"bool": {
"must": [
{
"match": {
"default_text": {
"query": "好美的太阳",
"boost": 0.6
}
}
}
]
}
},
"knn": {
"field": "dense_values",
"query_vector": [
0.1,
0.1,
0.1,
0.1,
0.1
],
"k": 3,
"num_candidates": 100,
"boost": 0.4
},
"_source": {
"excludes": [
"dense_values"
]
}
}'
3 小结
(1)ES混合搜索:通过boost配置比例,其中,关键词计算使用BM25计算分数,同时加入boost参数;
(2)关键词搜索boost基础比例为2.2,计算过程boost=2.2boost;
(3)向量搜索的最终分数为:final_score=boostkNN。
计算过程参见文章:RAG理论:ES混合搜索BM25+kNN(cosine)以及归一化
https://blog.csdn.net/Xin_101/article/details/140237669

![[Elasticsearch]<span style='color:red;'>ES</span>近似<span style='color:red;'>实时</span><span style='color:red;'>搜索</span>的原因|<span style='color:red;'>ES</span>非<span style='color:red;'>实时</span><span style='color:red;'>搜索</span>的原因|<span style='color:red;'>ES</span> Near real-time search](https://i-blog.csdnimg.cn/direct/8a3fe643806e483ba97a27a0b4e5601d.png#pic_center)