评估指标:精确率(Precision)、召回率(Recall)、F1分数(F1 Score)

前言
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入人工智能知识点专栏、Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏或我的个人主页查看
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
相关介绍
在人工智能领域,特别是在监督学习的任务中,评估模型性能是非常关键的步骤。
评估指标是衡量模型或系统性能的关键参数,不同的应用场景会采用不同的评估指标。它们将抽象的评估目标转化为具体可量化的数值,帮助我们了解模型在特定任务上的表现。
以下是一些常用的评估指标,包括它们的定义、计算公式以及优缺点:
1. 准确率(Accuracy)
定义:模型正确分类的样本数占总样本数的比例。
公式: A c c u r a c y = TP + TN TP + FN + FP + TN Accuracy = \frac{\text{TP} + \text{TN}}{\text{TP} + \text{FN} + \text{FP} + \text{TN}} Accuracy=TP+FN+FP+TNTP+TN
其中,TP(True Positive)是真的正类被正确预测的数量,TN(True Negative)是真的负类被正确预测的数量,FP(False Positive)是假的正类预测,FN(False Negative)是假的负类预测。
优点:简单直观,容易理解。
缺点:在数据类别不平衡的情况下,准确率可能产生误导,因为模型可能只是简单地预测多数类而忽略了少数类的表现。
2. 精确率(Precision)
定义:预测为正类中真正是正类的比例。
公式: P r e c i s i o n = TP TP + FP Precision = \frac{\text{TP}}{\text{TP} + \text{FP}} Precision=TP+FPTP
优点:关注预测为正例的准确性,适用于错误的正面预测成本较高的场景。
缺点:不考虑真负例,因此在负例很多且预测很少时,精确率可能很高,但模型可能错过许多正例。
3. 召回率(Recall)
定义:真正是正类的样本中被正确预测为正类的比例。
公式: R e c a l l = TP TP + FN Recall = \frac{\text{TP}}{\text{TP} + \text{FN}} Recall=TP+FNTP
优点:强调对正类的识别能力,适用于不能遗漏正例的场景。
缺点:可能会忽视假阳性预测的影响,即预测为正类但实际上为负类的情况。
4. F1分数 (F1 Score)
定义:精确率和召回率的调和平均值,旨在同时考虑精确率和召回率。
公式: F 1 = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l F1 = 2 \times \frac{Precision \times Recall}{Precision + Recall} F1=2×Precision+RecallPrecision×Recall
优点:在单一指标中平衡了精确率和召回率,适用于两者都重要的情况。
缺点:当精确率和召回率中有一个非常低时,F1分数可能无法准确反映模型性能。

5. ROC曲线和AUC(Area Under the Curve)
定义:ROC曲线通过改变分类阈值,展示真正率(TPR)与假正率(FPR)的关系。AUC是ROC曲线下的面积。
优点:提供了一个整体评估模型分类能力的方法,不受单一阈值影响,AUC接近1表示分类器优秀。
缺点:对于多分类问题,需要计算多个二分类ROC曲线,或使用多分类的ROC曲线变体。
6. PR曲线(Precision-Recall Curve)
定义:同样通过改变分类阈值,显示精确率和召回率之间的权衡关系。
优点:在类别不平衡的数据集中更为有用,能更清晰地看到不同阈值下的性能变化。
缺点:不像AUC那样有统一的标准解释,比较不同模型时可能需要直接对比曲线形状。
选择合适的评估指标时,应考虑具体应用场景的需求,比如是否重视查准还是查全,或者数据集是否平衡等。

F1分数 (F1 Score)
F1分数(F1 Score)是一种广泛应用于二分类和多分类问题中的性能评价指标,特别是对于类别不平衡的数据集而言,它能提供比单一的精确率或召回率更为全面的性能评估。下面是F1分数的详细解析,包括其计算方法、优势和局限性:
F1分数的计算
F1分数是精确率(Precision)和召回率(Recall)的调和平均数,旨在综合这两个指标,以反映模型在分类任务中的平衡表现。其计算公式为:
F 1 = 2 × Precision × Recall Precision + Recall F1 = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} F1=2×Precision+RecallPrecision×Recall
- 精确率(Precision) 表示模型预测为正类别的样本中,真正为正类别的比例,计算公式为 (\frac{\text{真正例(TP)}}{\text{真正例(TP)} + \text{假正例(FP)}})。
- 召回率(Recall) 表示所有实际为正类别的样本中,被模型正确识别的比例,计算公式为 (\frac{\text{真正例(TP)}}{\text{真正例(TP)} + \text{假阴例(FN)}})。
F1分数的优点
- 平衡精确率和召回率:F1分数同时考虑了模型预测的精确性和完整性,对于需要两者都达到较高水平的应用非常适用。
- 类别不平衡数据集:在正负样本数量差距较大的情况下,F1分数能够给出更为公平的性能评估,相比单独使用精确率或召回率更能反映出模型的整体效能。
- 单一指标:作为一个单一的数值指标,F1分数简化了模型性能的比较,便于理解和沟通。
F1分数的缺点
- 权重固定:F1分数对精确率和召回率给予相同的权重(即1:1),但在某些应用场景下,根据具体需求,可能需要对二者赋予不同的重要性(例如,某些情况下召回率可能比精确率更重要)。
- 忽视真负例(TN):F1分数完全依赖于正例的预测情况,忽略了模型正确预测为负例的能力,因此在某些场景下可能不足以全面评估模型性能,尤其是当错误地分类负例成本也很高时。
- 极端情况:当精确率和召回率中有一个为0时,F1分数也会变为0,即使另一个指标非常高,这可能在某些情况下显得过于苛刻。
综上所述,F1分数是衡量分类模型性能的有效工具,尤其适合评估那些需要均衡考虑精确率和召回率的应用场景。然而,在选择评估指标时,应考虑具体任务的需求,有时可能需要结合其他指标如AUC-ROC、Precision-Recall曲线等进行综合分析。
计算实例
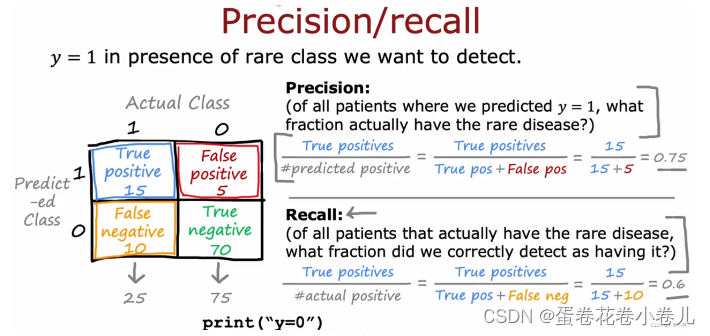
F1分数是一种统计度量,用于评估二分类(或多标签分类中的每一个类别)模型的性能,它是精确率(Precision)和召回率(Recall)的调和平均值。下面通过一个简单的例子来说明如何计算F1分数:
示例数据
假设我们有一个二分类问题,模型预测的结果和实际标签如下:
- 真实正例(TP,True Positives): 25个
- 假正例(FP,False Positives): 5个
- 真实负例(TN,True Negatives): 70个
- 假负例(FN,False Negatives): 10个
计算精确率(Precision)
精确率是指模型预测为正例中实际确实是正例的比例。
Precision = TP TP + FP = 25 25 + 5 = 25 30 = 0.8333 \text{Precision} = \frac{\text{TP}}{\text{TP} + \text{FP}} = \frac{25}{25 + 5} = \frac{25}{30} = 0.8333 Precision=TP+FPTP=25+525=3025=0.8333
计算召回率(Recall)
召回率是指实际正例中被模型正确识别出来的比例。
Recall = TP TP + FN = 25 25 + 10 = 25 35 = 0.7143 \text{Recall} = \frac{\text{TP}}{\text{TP} + \text{FN}} = \frac{25}{25 + 10} = \frac{25}{35} = 0.7143 Recall=TP+FNTP=25+1025=3525=0.7143
计算F1分数 (F1 Score)
F1分数结合了精确率和召回率,公式如下:
F1 Score = 2 × Precision × Recall Precision + Recall \text{F1 Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} F1 Score=2×Precision+RecallPrecision×Recall
将上面计算的精确率和召回率代入公式中:
F1 Score = 2 × 0.8333 × 0.7143 0.8333 + 0.7143 ≈ 2 × 0.5972 1.5476 ≈ 2 × 0.3864 = 0.7728 \text{F1 Score} = 2 \times \frac{0.8333 \times 0.7143}{0.8333 + 0.7143} \approx 2 \times \frac{0.5972}{1.5476} \approx 2 \times 0.3864 = 0.7728 F1 Score=2×0.8333+0.71430.8333×0.7143≈2×1.54760.5972≈2×0.3864=0.7728
因此,基于这个示例,模型的F1分数大约为0.7728。F1分数越接近1,表明模型在精确率和召回率方面的综合性能越好。
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入人工智能知识点专栏、Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏或我的个人主页查看
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目


























![[分享]Simulink电力系统仿真恒功率负荷功率不平衡现象的解释以及需求侧响应受控负荷的建模建议](https://i-blog.csdnimg.cn/direct/c043f4bbbc454c649841e96651071af0.png)