相信大家对哈希表都不陌生,其本质和数组类似。下标通过hash函数计算;当出现冲突时,使用链表解决;当元素超过一定数量时触发rehash,减少冲突链表的长度,使数据分布更加均衡、查找更加迅速,诸如此类大家可能能说出来很多。
那么实际情况下,C++中哈希表是如何实现的、其细节有哪些呢?了解这些有助于我们理解系统库的实际实现,让我们在开发项目的过程中更有底气,接下来我们就一起看看。
在开始之前,我把Hashtable的主要数据结构画出来,方便大家有个宏观印象。
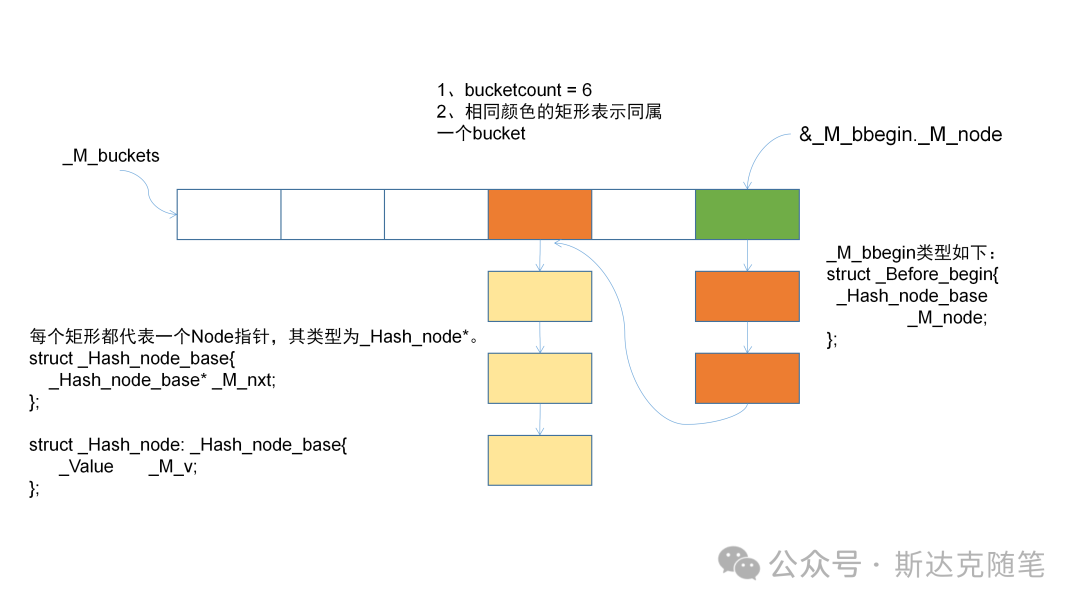
总体来说:
所有bucket首节点构成一个连续的节点指针数组,其大小为bucket_count,buckets指向第一个bucket。空白的矩形代表空指针。
除了每个bucket之内的节点构成链表之外,整个hashtable的节点也构成了一个链表,链表头为&_M_bbegin._M_node,_M_bbegin是一个虚拟头节点,这样就能支持迭代器遍历整个hashtable。
每个bucket的第一个元素相当于一个哑结点,其本身不属于这个bucket,哑结点后的第一个节点,才是这个bucket的第一个节点,同时也可以看到,这个哑结点也是另一个bucket的最后一个数据节点。这样一个好处就是除了第一个头节点之外,整个hashtable中都是数据节点,没有多余的哑结点,提高了内存利用率。
上图展示了某一时刻Hashtable的内部结构,那么随着数据的增加和删除,其内部结构会怎样变化呢?下面我们看一下相关的核心逻辑,为了方便大家理解,我在关键地方加了注释。
哑结点的获取:
__node_base& _M_before_begin(){
return _M_bbegin._M_node;
}Hashtable首数据节点的获取:
__node_type* _M_begin() const{
return static_cast<__node_type*>(_M_before_begin()._M_nxt);
}每个bucket首数据节点的获取:
__node_type* _M_bucket_begin(size_type __bkt) const{
__node_base* __n = _M_buckets[__bkt];
return __n ?
//取bucket节点中的下一项
static_cast<__node_type*>(__n->_M_nxt) : nullptr;
}构造函数:
// 第一种
//没指定元素,只有大小,那就只分配bucket数组,并初始化为空。
_M_bucket_count = _M_rehash_policy._M_next_bkt(__bucket_hint);
_M_buckets = _M_allocate_buckets(_M_bucket_count);
// 第二种
//指定了一个初始化容器,那么依次插入。__f代表初始化序列开始,__l代表
//初始化序列结束
auto __nb_elems = __detail::__distance_fw(__f, __l);
//决定bucket大小
_M_bucket_count =
_M_rehash_policy._M_next_bkt(
std::max(_M_rehash_policy._M_bkt_for_elements(__nb_elems),
__bucket_hint));
//分配bucket数组
_M_buckets = _M_allocate_buckets(_M_bucket_count);
//依次插入
for (; __f != __l; ++__f)
this->insert(*__f);
// 第三种
//拷贝构造 ht代表另一个Hashtable
//分配bucket数组
_M_buckets = _M_allocate_buckets(_M_bucket_count);
//如果ht数据元素为空,不做后续操作
if (!__ht._M_before_begin()._M_nxt)
return;
//拷贝ht的首数据节点
const __node_type* __ht_n = __ht._M_begin();
__node_type* __this_n = _M_allocate_node(__ht_n->_M_v);
this->_M_copy_code(__this_n, __ht_n);
//把hashtable首数据节点链到hashtable哑结点后面
_M_before_begin()._M_nxt = __this_n;
//更新首数据节点对应的bucket项,这里更新为hashtable哑结点
_M_buckets[_M_bucket_index(__this_n)] = &_M_before_begin();
// Then deal with other nodes.
__node_base* __prev_n = __this_n;
for (__ht_n = __ht_n->_M_next(); __ht_n; __ht_n = __ht_n->_M_next()){
__this_n = _M_allocate_node(__ht_n->_M_v);
__prev_n->_M_nxt = __this_n;
this->_M_copy_code(__this_n, __ht_n);
//确定当前节点的bucket,如果bucket为空,把当前节点的上一个节点放到
//bucket中
size_type __bkt = _M_bucket_index(__this_n);
if (!_M_buckets[__bkt])
_M_buckets[__bkt] = __prev_n;
__prev_n = __this_n;
}hashtable的clear操作:
void clear() noexcept{
//从首数据节点开始,释放每个数据节点
_M_deallocate_nodes(_M_begin());
//置空各bucket
__builtin_memset(_M_buckets, 0, _M_bucket_count * sizeof(__bucket_type));
_M_element_count = 0;
//置空数据节点
_M_before_begin()._M_nxt = nullptr;
}rehash操作:
void _M_rehash_aux(size_type __n, std::true_type){
//按照新大小,重新分配bucket数组
__bucket_type* __new_buckets = _M_allocate_buckets(__n);
__node_type* __p = _M_begin();
_M_before_begin()._M_nxt = nullptr;
std::size_t __bbegin_bkt = 0;
while (__p){
//next为当前要插入的数据节点,p为上一数据节点
__node_type* __next = __p->_M_next();
//计算新的bucket下标
std::size_t __bkt = __hash_code_base::_M_bucket_index(__p, __n);
if (!__new_buckets[__bkt]){
//当数据节点对应的bucket为空时,要将哑结点移动到此bucket
//表示整个hashtable的首节点
__p->_M_nxt = _M_before_begin()._M_nxt;
_M_before_begin()._M_nxt = __p;
__new_buckets[__bkt] = &_M_before_begin();
//移东哑结点后,假如之前哑结点所在的bucket有数据节点,那么
//这个bucket不能为空,填入当前节点的上一节点。
//__bbegin_bkt记录哑结点所在上一个bucket index。
//初始时,nxt为空,开头已置空。
if (__p->_M_nxt)
__new_buckets[__bbegin_bkt] = __p;
__bbegin_bkt = __bkt;
}
else{
__p->_M_nxt = __new_buckets[__bkt]->_M_nxt;
__new_buckets[__bkt]->_M_nxt = __p;
}
__p = __next;
}
//释放老的bucket数据
_M_deallocate_buckets(_M_buckets, _M_bucket_count);
_M_bucket_count = __n;
//指向新的bucket数组
_M_buckets = __new_buckets;可以看到rehash时,只是重新分配了bucket数组,数据节点重新做了链接,没有重新分配。相比起vector的自动扩容,少了重新分配数据节点内存和初始化的开销。
insert操作:
//bucket不为空,正常在链表头插入。
if (_M_buckets[__bkt]){
// Bucket is not empty, we just need to insert the new node
// after the bucket before begin.
__node->_M_nxt = _M_buckets[__bkt]->_M_nxt;
_M_buckets[__bkt]->_M_nxt = __node;
}
else{
// The bucket is empty, the new node is inserted at the
// beginning of the singly-linked list and the bucket will
// contain _M_before_begin pointer.
__node->_M_nxt = _M_before_begin()._M_nxt;
_M_before_begin()._M_nxt = __node;
if (__node->_M_nxt)
// We must update former begin bucket that is pointing to
// _M_before_begin.
//哑节点可能发生变化,如果哑结点后面还有节点,那么需要更新后面
//节点对应的bucket
_M_buckets[_M_bucket_index(__node->_M_next())] = __node;
//bucket为空时,其第一个元素为哑结点,也是整个Hashtable的首节点
_M_buckets[__bkt] = &_M_before_begin();
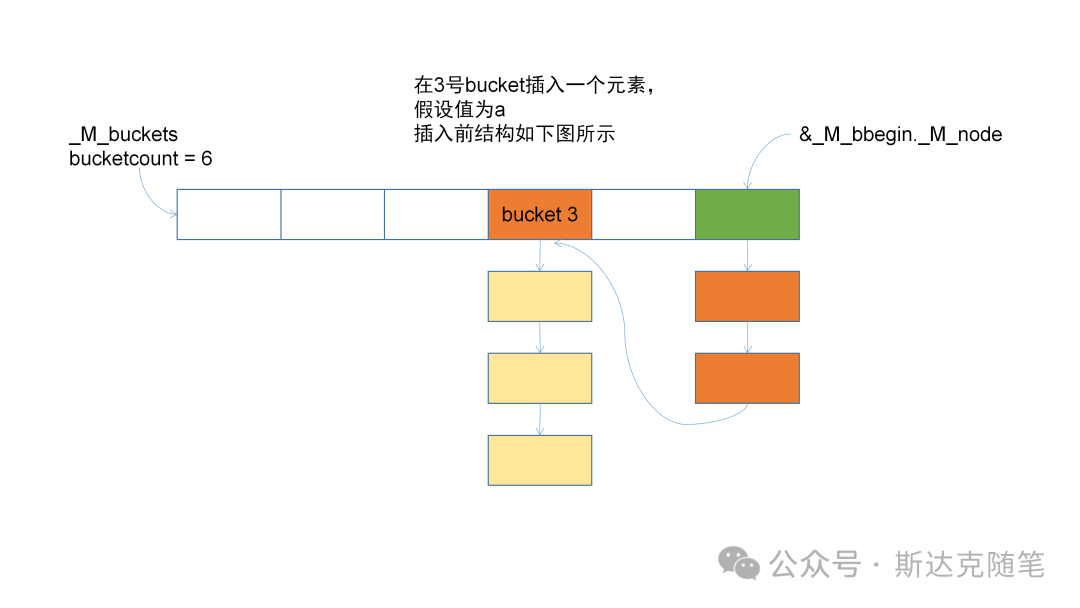
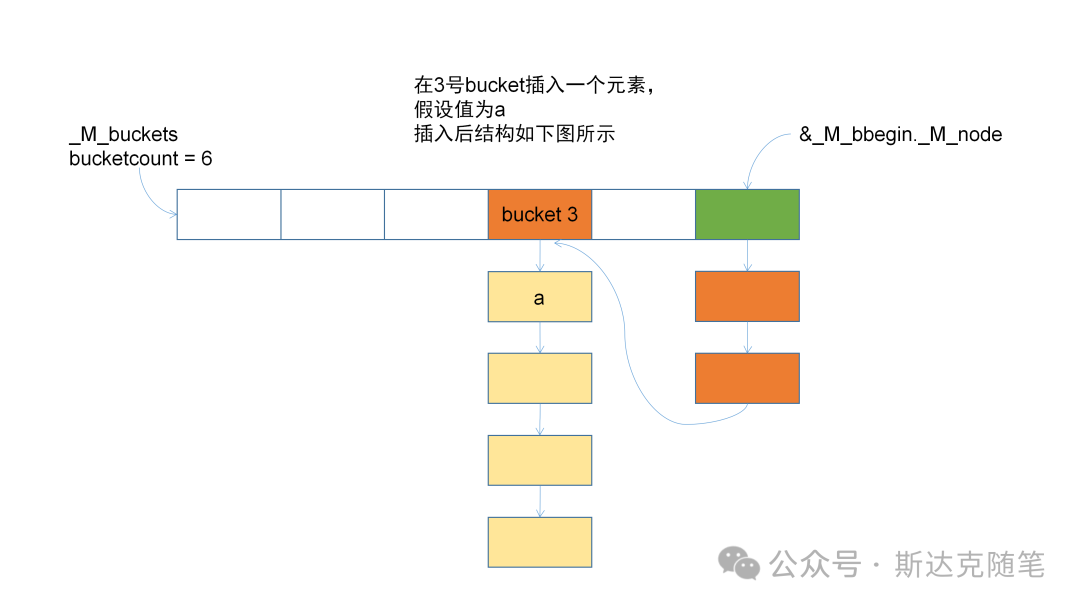
}放几张插入的变化图,供大家参考。
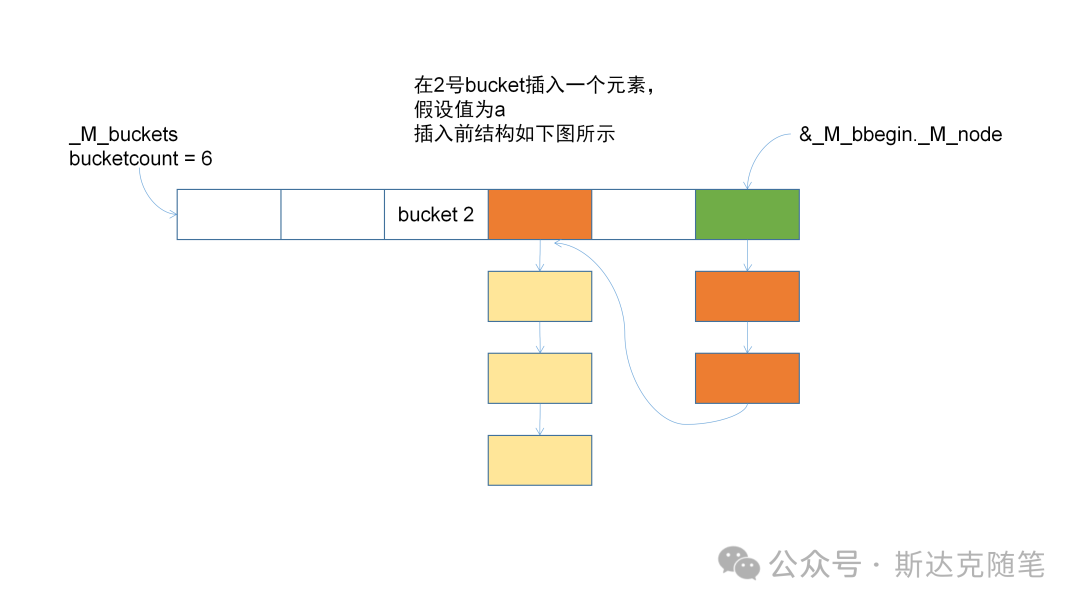
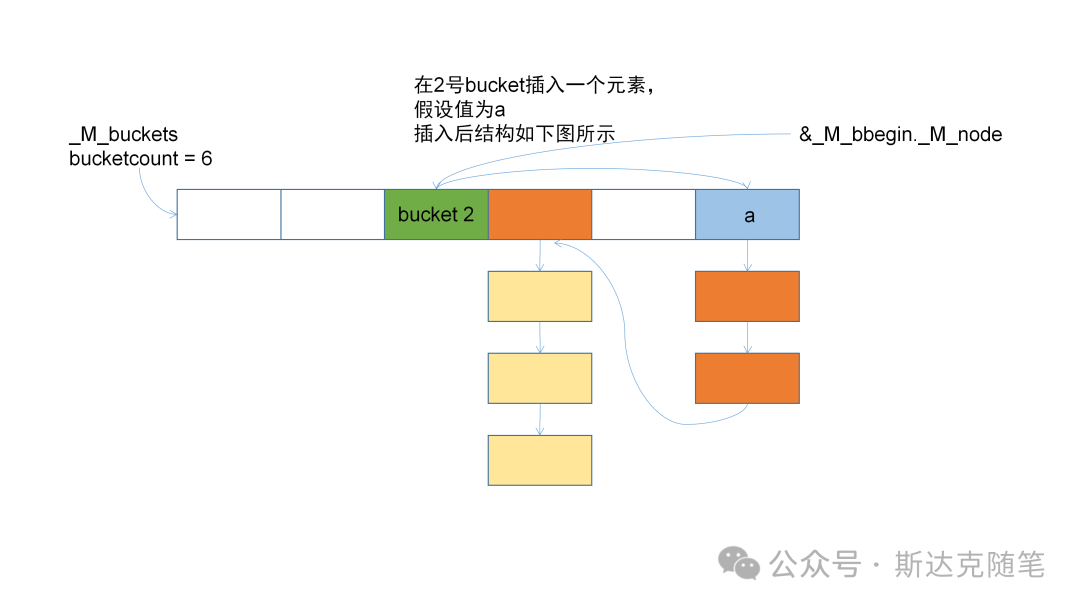
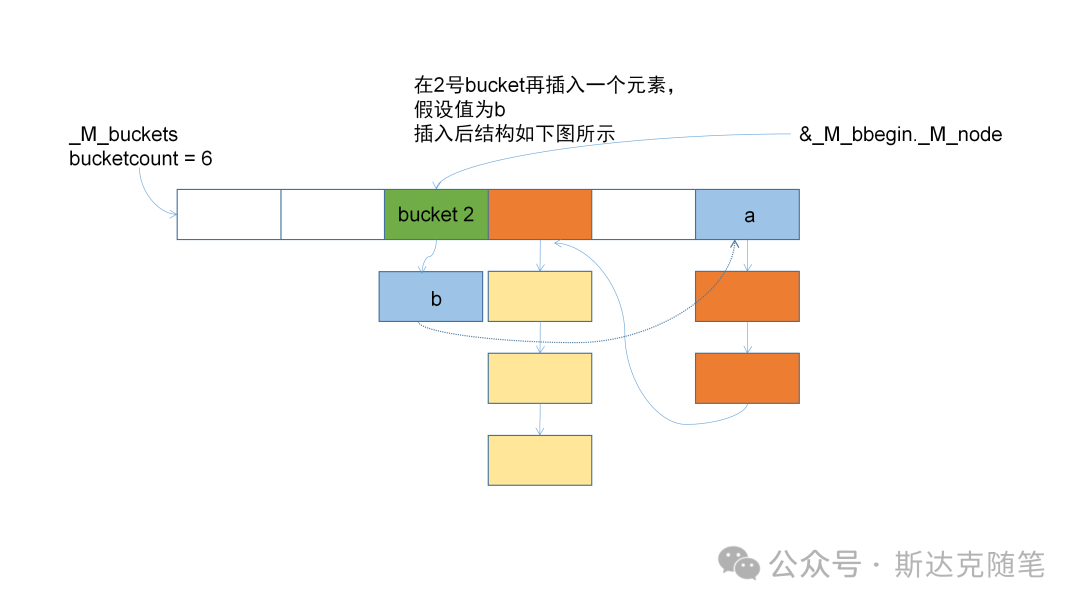
erase操作:
//删除时需要prev节点,因为需要修改prev的next指针
iterator _M_erase(size_type __bkt, __node_base* __prev_n, __node_type* __n){
//删除bucket头数据节点的情况
if (__prev_n == _M_buckets[__bkt])
_M_remove_bucket_begin(__bkt, __n->_M_next(),
__n->_M_nxt ? _M_bucket_index(__n->_M_next()) : 0);
else if (__n->_M_nxt){
size_type __next_bkt = _M_bucket_index(__n->_M_next());
//不等时,说明删除的是bucket的最后一个节点
if (__next_bkt != __bkt)
_M_buckets[__next_bkt] = __prev_n;
}
//考虑完上面两个情况后,删除只需要修改prev的next指针
__prev_n->_M_nxt = __n->_M_nxt;
iterator __result(__n->_M_next());
_M_deallocate_node(__n);
--_M_element_count;
return __result;
}
//删除bucket头数据节点的情况
void _M_remove_bucket_begin(size_type __bkt, __node_type* __next,size_type __next_bkt){
if (!__next || __next_bkt != __bkt){
// Bucket is now empty
// First update next bucket if any
//说明__next_bkt == __bkt,要删除的既是头结点,又是尾节点
if (__next)
_M_buckets[__next_bkt] = _M_buckets[__bkt];
// Second update before begin node if necessary
//要删除的是hashtable头结点所指向的bucket的唯一一个节点,此时需要
//更新头节点
if (&_M_before_begin() == _M_buckets[__bkt])
_M_before_begin()._M_nxt = __next;
_M_buckets[__bkt] = nullptr;
}
}可以看到删除时会涉及prev指针的修改,Hashtable的哑结点就方便了此类操作。放几张删除的变化图,供大家参考:
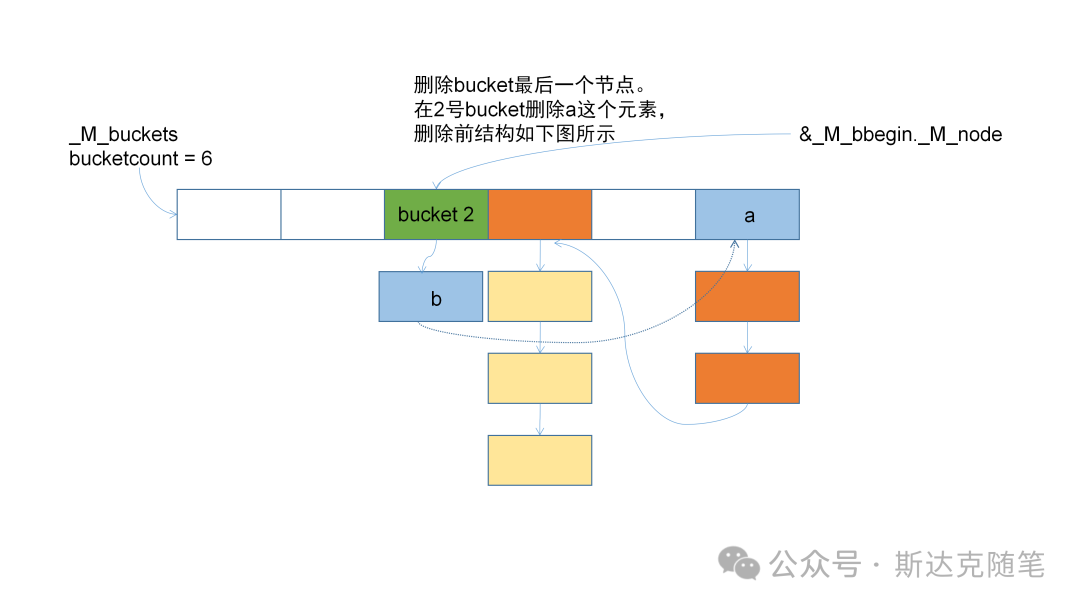
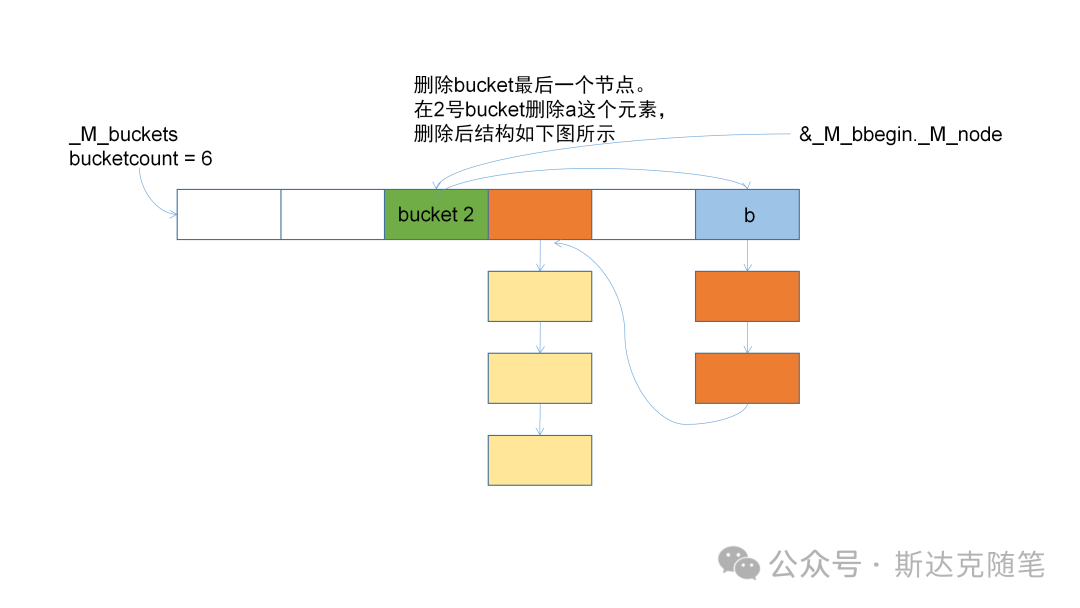
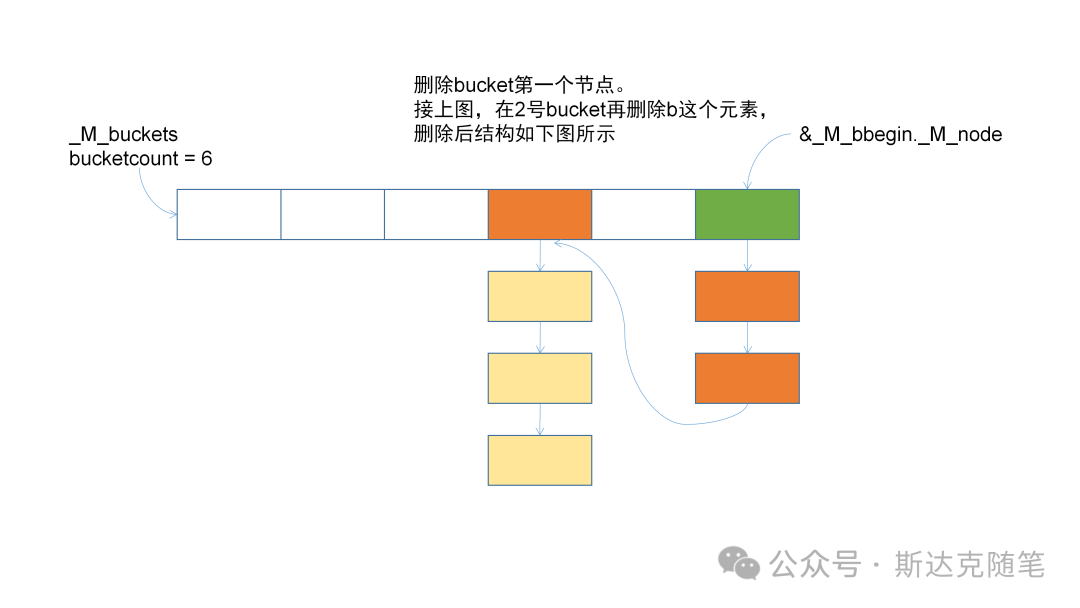
经过实际阅读源码发现,Hashtable内部的实现和我们平时想的还是有些差别,大家看了之后有什么想法呢,欢迎留言评论。
原文链接:聊聊C++的Hashtable
山重水复疑无路,柳暗花明又一村