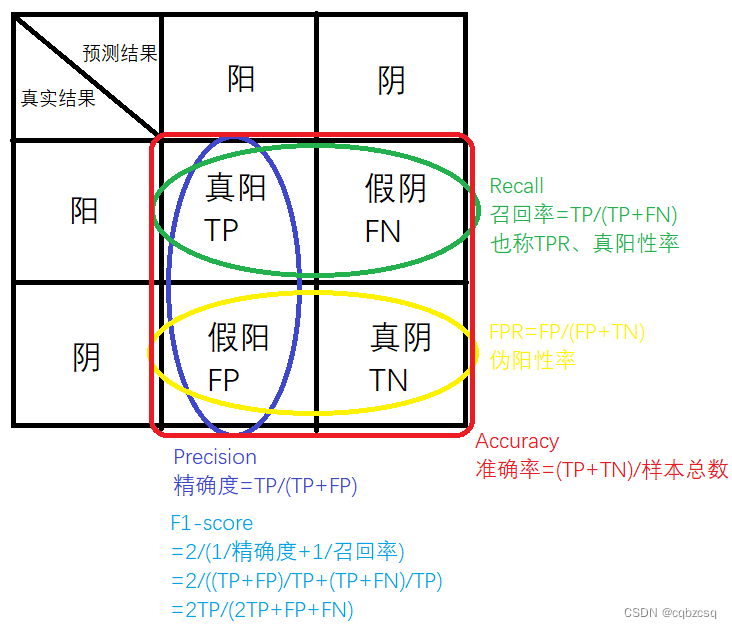
1 混淆矩阵
混淆矩阵是一种用于评估分类模型性能的重要工具。它通过矩阵形式清晰地展示了模型对样本进行分类的结果,帮助我们理解模型在不同类别上的表现。
| ———— | 预测为正类 | 预测为负类 |
|---|---|---|
| 实际为正类 | True Positive (TP) | False Negative (FN) |
| 实际为负类 | False Positive (FP) | True Negative (TN) |
- True Positive (TP): 模型将实际为正类别的样本正确预测为正类别。
- False Negative (FN): 模型将实际为正类别的样本错误预测为负类别。
- False Positive (FP): 模型将实际为负类别的样本错误预测为正类别。
- True Negative (TN): 模型将实际为负类别的样本正确预测为负类别。
通过上述指标,可以计算出一系列性能指标,例如准确率、精确率、召回率和F1分数。这些指标帮助我们量化模型的分类准确性、可靠性和全面性。
- 注意:混淆矩阵的目的是帮助理解分类模型在不同类别上的表现,即只要是分类模型,可以考虑利用混淆矩阵,例如医学领域中,判断病人是否有某种疾病
2 混淆矩阵指标
2.1 准确率
准确率表示模型正确分类的样本占总样本数的比例,计算方式为:
准确率( A c c u r a c y ) = T P + T N T P + T N + F P + F N 准确率(Accuracy)=\frac{TP+TN}{TP+TN+FP+FN} 准确率(Accuracy)=TP+TN+FP+FNTP+TN
如下图所示:

准确率可以判断总的正确率,但有如下缺点:
- 在样本不平衡的情况下,并不能作为很好的指标来衡量结果。例如在一个样本中,正样本占99%,负样本占1%,样本是严重不平衡的,无论什么算法,只需要将全部样本预测为正样本即可有99%的准确率,这体现不出算法的性能
2.2 精确率
精确率又叫查准率。精确率表示所有被预测为正的样本中实际为正的样本的概率,它是针对预测结果而言的,计算方式为:
精确率( P r e c i s i o n ) = T P T P + F P 精确率(Precision)=\frac{TP}{TP+FP} 精确率(Precision)=TP+FPTP
如下图所示:

准确率和精确率的区别如下:
- 精准率代表对预测的正样本结果中的预测准确程度
- 准确率则代表整体的预测准确程度
2.3 召回率
召回率,也称为 True Positive Rate (TPR) 或灵敏度或查全率,它表示在实际为正的样本中被正确预测为正样本的概率,它是针对原样本而言的,计算公式如下:
召回率( T P R ) = T P T P + F N 召回率(TPR)=\frac{TP}{TP+FN} 召回率(TPR)=TP+FNTP
如下图所示:

召回率的应用场景:例如银行贷款等,将无信用的用户设定为正样本,这就需要保证召回率要足够高。如果召回率过低,就会把无信用用户预测为有信用用户,这样会造成严重损失。
2.4 特异度
特异度,也称为 True Negative Rate (TNR),它表示在实际为负的样本中被正确预测为负样本的概率,它是针对原样本而言的,计算公式如下:
特异度( T N R ) = T N T N + F P 特异度(TNR)=\frac{TN}{TN+FP} 特异度(TNR)=TN+FPTN
如下图所示:

特异度的应用场景:例如银行贷款等,将无信用的用户设定为负样本,这就需要保证召回率要足够高。如果召回率过低,就会把无信用用户预测为有信用用户,这样会造成严重损失。
2.4 假正率
假正率,也称为False Positive Rate (FPR) ,它表示在实际为负的样本中被错误预测为正样本的概率,它是针对原样本而言的,计算公式如下:
假正率( F P R ) = F P F P + T N 假正率(FPR)=\frac{FP}{FP+TN} 假正率(FPR)=FP+TNFP
如下图所示:

2.5 假负率
假负率,也称为False Negative Rate (FNR) ,它表示在实际为正的样本中被错误预测为负样本的概率,它是针对原样本而言的,计算公式如下:
假负率( F N R ) = F N T P + F N 假负率(FNR)=\frac{FN}{TP+FN} 假负率(FNR)=TP+FNFN
如下图所示:

2.6 F1 分数
F1 分数是精确率和召回率的调和平均数,它综合了两者的性能,计算方式为:
F 1 = 2 × 精确率 × 召回率 精确率 + 召回率 F1=\frac{2×精确率×召回率}{精确率+召回率} F1=精确率+召回率2×精确率×召回率
F1的特点如下:
- F1 分数的取值范围是 [0, 1],越接近 1 表示模型的性能越好,同时考虑到了模型在精确率和召回率之间的平衡。
- F1 分数非常适合二分类问题
- F1 分数越高则越意味着模型在查准率和查全率之间取得了良好的平衡
3 总结
混淆矩阵的主要性能指标,作如下总结:
- 准确率:模型正确分类的样本占总样本数的比例,准确率衡量了模型在所有样本上的整体表现
- 精确率:模型预测为正类别的样本中实际是正类别的概率,精确率衡量了模型在预测为正类别的样本上的准确性
- 召回率:实际为正类别的样本中,正确预测为正样本的概率,召回度衡量了在实际为正样本中正确预测为正样本的预测概率
- F1分数:精确率和召回率的调和平均数,F1分数衡量了精确率和召回率之间的平衡
混淆矩阵和上述性能指标共同提供了对分类模型性能全面的理解,并帮助评估模型的优缺点,进而进一步优化模型
参考如下:
- 机器学习,周志华
- 混淆矩阵(Confusion Matrix)
- 机器学习中的召回率、精确率、准确率