1、继承的父类不同
Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。但二者都实现了Map接口
2、线程安全性不同
javadoc中关于hashmap的一段描述如下:此实现不是同步的。如果多个线程同时访问一个哈希映射, 而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
Hashtable 中的方法是Synchronize的,而HashMap中的方法在缺省情况下是非Synchronize的。
在多线程并发的环境下,可以直接使用Hashtable,不需要自己为它的方法实现同步,但使用
HashMap时就必须要自己增加同步处理。(结构上的修改是指添加或删除一个或多个映射关系的任
何操作;仅改变与实例已经包含的键关联的值不是结构上的修改。)这一般通过对自然封装该映射
的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedMap方
法来“包装”该映射。最好在创建时完成这一操作,以防止对映射进行意外的非同步访问
3、是否提供contains方法
HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey,因为contains方
法容易让人引起误解。
Hashtable则保留了contains,containsValue和containsKey三个方法,其中contains和
containsValue功能相同。
4、key和value是否允许null值
其中 key 和 value 都是对象,并且不能包含重复 key ,但可以包含重复的 value 。
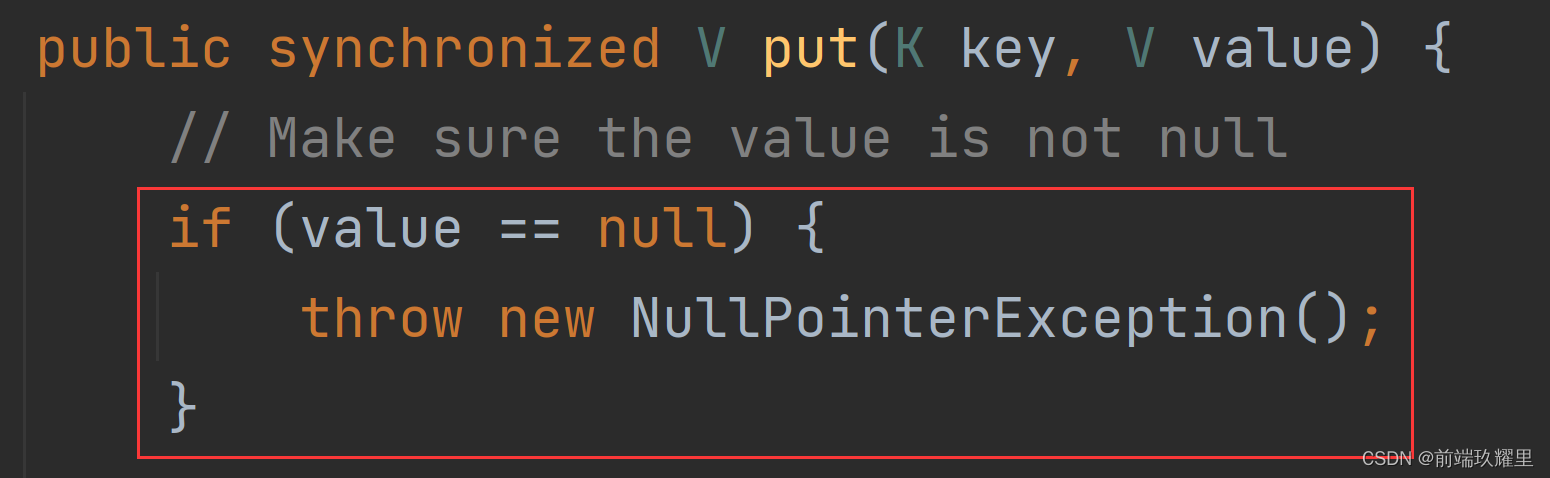
Hashtable 中, key 和 value 都不允许出现 null 值。但是如果在 Hashtable 中有类似 put(null,null)的操作, 编译同样可以通过,因为 key 和 value 都是 Object 类型,但运行时会抛出 NullPointerException异常,这是 JDK 的规范规定的。
HashMap 中, null 可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为 null 。当 get()方法返 回 null 值时,可能是 HashMap 中没有该键,也可能使该键所对应的值为 null 。因此,在 HashMap中不能由 get() 方法来判断 HashMap 中是否存在某个键, 而应该用 containsKey() 方法来判断。
5、两个遍历方式的内部实现上不同
Hashtable 、 HashMap 都使用了 Iterator 。而由于历史原因, Hashtable 还使用了 Enumeration 的方
式 。
6、hash值不同
哈希值的使用不同, HashTable 直接使用对象的 hashCode 。而 HashMap 重新计算 hash 值。
7、内部实现使用的数组初始化和扩容方式不同
HashTable 在不指定容量的情况下的默认容量为 11 ,而 HashMap 为 16 , Hashtable不要求底层数组的容量一定要为 2 的整数次幂,而 HashMap 则要求一定为 2 的整数次幂。
Hashtable 扩容时,将容量变为原来的 2 倍加 1 ,而 HashMap 扩容时,将容量变为原来的2倍。 Hashtable 和 HashMap 它们两个内部实现方式的数组的初始大小和扩容的方式。 HashTable 中hash 数组默认大小是 11 ,增加的方式是 old*2+1 。
至于为什么HashMap要求底层数组的容量一定要为2的整数次幂?
在 JDK1.7 中整个扩容过程就是一个取出数组元素(实际数组索引
位置上的每个元素是每个独立单向链表的头部,也就是发
生 Hash 冲突后最后放入的冲突元素)然后遍历以该元素为
头的单向链表元素,依据每个被遍历元素的 hash 值计算其
在新数组中的下标然后进行交换( 即原来 hash 冲突的单向
链表尾部变成了扩容后单向链表的头部)。
在 JDK 1.8 中 HashMap 的扩容操作就显得更加的骚气了,
由于扩容数组的长度是 2 倍关系,所以对于假设初始
tableSize = 4 要扩容到 8 来说就是 0100 到 1000 的变化
(左移一位就是 2 倍), 在扩容中只用判断原来的 hash 值
与左移动的一位(newtable 的值)按位与操作是 0 或 1 就
行,0 的话索引就不变,1 的话索引变成原索引加上扩容前
数组






















![[数据结构]二叉树(下)](https://img-blog.csdnimg.cn/direct/eeaee104ac4e4d98847e81205169edec.png)