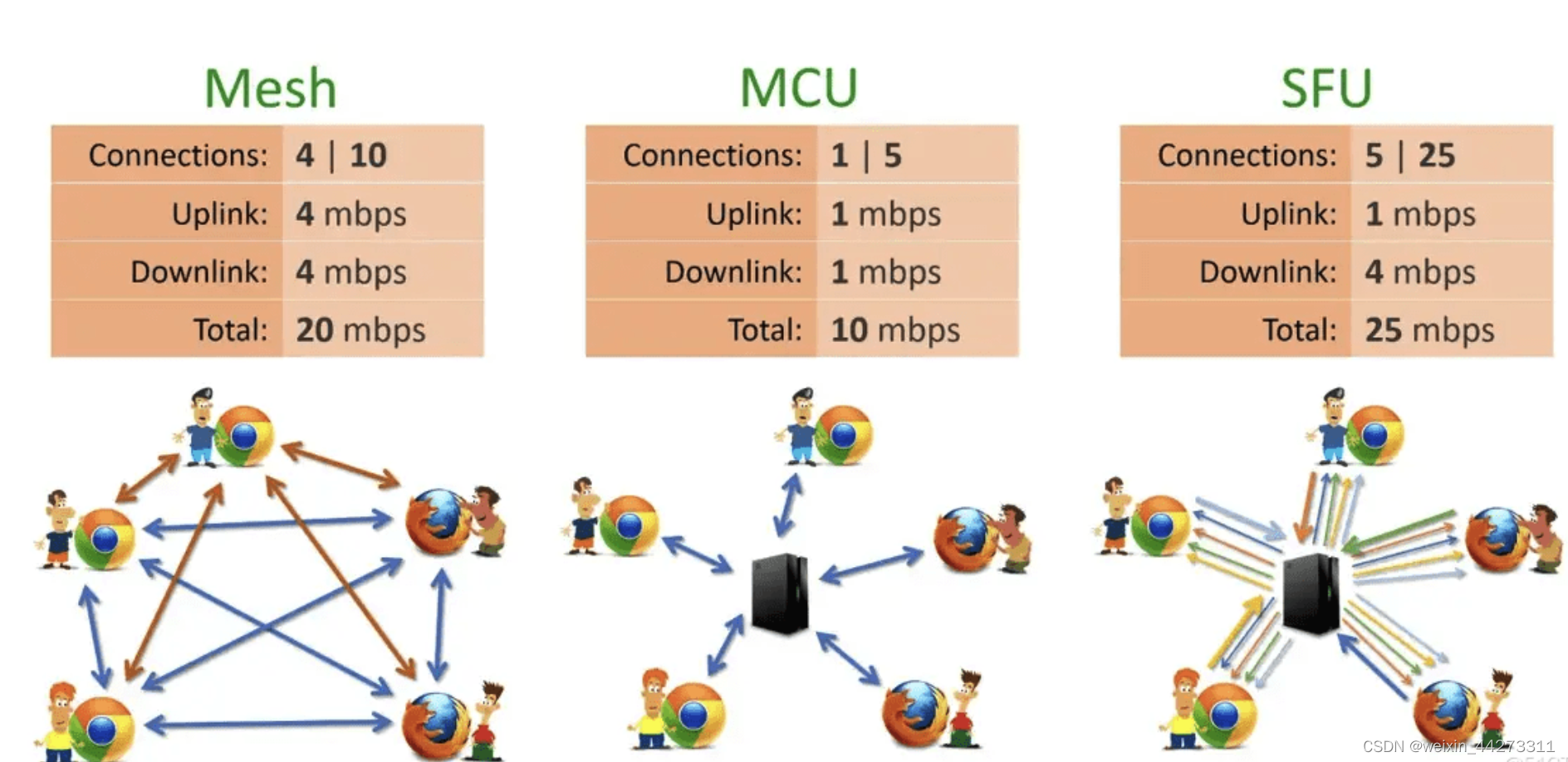
基于 MindSpore 实现 BERT 对话情绪识别
上几章我们学习过了基于MindSpore来实现计算机视觉的一些应用,那么从这期开始要开始一个新的领域——LLM
首先了解一下什么是LLM
LLM 是 “大型语言模型”(Large Language Model)的缩写。LLM 是一种人工智能模型,通常基于深度学习技术,特别是使用Transformer架构,经过在大规模文本数据上训练,能够理解和生成自然语言文本。这些模型在处理各种自然语言处理任务方面表现出色,例如文本生成、翻译、问答、摘要和对话。
以下是关于 LLM 的一些关键点:
规模:
- LLM 通常具有数十亿到数百亿个参数。这些参数量级使得模型能够捕捉语言中的复杂模式和语义关系。
训练数据:
- LLM 使用大量文本数据进行训练,包括书籍、文章、网站内容和其他形式的书面语言。这些数据可以覆盖各种主题和风格,使得模型具有广泛的知识和多样的语言能力。
应用:
- 生成文本:创建高质量的文章、故事、对话等。
- 语言翻译:将文本从一种语言翻译到另一种语言。
- 问答系统:回答用户提出的问题。
- 文本摘要:从长文中提取关键信息并生成摘要。
- 对话系统:与用户进行自然的对话交流。
模型架构:
- 大多数 LLM 基于 Transformer 架构,特别是它的自注意力机制,使模型能够处理序列数据并捕捉长距离依赖关系。
知名模型:
- 一些知名的 LLM 包括 OpenAI 的 GPT-3、GPT-4,Google 的 BERT 和 T5,以及 Facebook 的 RoBERTa。
挑战和考虑:
- 计算资源:训练和运行 LLM 需要大量的计算资源和存储空间。
- 偏见和伦理:由于训练数据可能包含偏见,模型输出也可能反映这些偏见。因此,在使用 LLM 时需要注意伦理问题和偏见风险。
- 可解释性:大型模型通常被认为是“黑箱”,难以理解其内部决策过程。
LLM 在人工智能和自然语言处理领域有着广泛的应用前景,但也伴随着技术、伦理和社会挑战。
在自然语言处理(NLP)中,文本解码是生成自然语言文本的重要步骤。本文将介绍文本解码的基本原理,并结合MindNLP框架,提供具体的代码实例和详细注释,帮助大家更好地理解文本解码的实现过程。
什么是文本解码
文本解码是将模型的输出(通常是概率分布或词汇索引)转换为可读的自然语言文本的过程。在生成文本时,常见的解码方法包括贪心解码、束搜索(Beam Search)、随机采样等。
MindNLP简介
MindNLP是昇思(MindSpore)提供的一个用于自然语言处理的工具包,旨在简化NLP模型的开发和部署。本文将通过MindNLP实现文本解码过程,并展示如何利用该工具包进行文本生成任务。
实验环境
首先,我们需要安装MindNLP及其依赖库。
!pip install mindnlp
文本解码实现
以下是一个使用MindNLP实现文本解码的实例代码:
import mindspore as ms
import mindnlp
from mindnlp.modules import RNNDecoder
from mindnlp.models import Seq2SeqModel
from mindspore import nn
from mindspore import Tensor
# 设置随机种子以确保结果可复现
ms.set_seed(42)
# 定义解码器
class GreedyDecoder(RNNDecoder):
def __init__(self, rnn, out_proj):
super(GreedyDecoder, self).__init__(rnn, out_proj)
def decode(self, encoder_outputs, max_length, start_token, end_token):
batch_size = encoder_outputs.shape[0]
decoder_input = Tensor([[start_token]] * batch_size, dtype=ms.int32)
decoder_hidden = None
decoded_sentences = []
for _ in range(max_length):
decoder_output, decoder_hidden = self.forward(decoder_input, decoder_hidden, encoder_outputs)
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach()
decoded_sentences.append(decoder_input.asnumpy())
if (decoder_input == end_token).all():
break
return decoded_sentences
# 定义编码器和解码器
encoder = nn.LSTM(input_size=10, hidden_size=20, num_layers=2, batch_first=True)
decoder = GreedyDecoder(nn.LSTM(input_size=10, hidden_size=20, num_layers=2, batch_first=True), nn.Dense(20, 10))
# 定义序列到序列模型
model = Seq2SeqModel(encoder, decoder)
# 模拟输入数据
encoder_outputs = Tensor(ms.numpy.random.randn(5, 7, 20), dtype=ms.float32)
start_token = 0
end_token = 9
max_length = 10
# 进行解码
decoded_sentences = decoder.decode(encoder_outputs, max_length, start_token, end_token)
# 打印解码结果
for i, sentence in enumerate(decoded_sentences):
print(f"Sentence {i + 1}: {sentence}")
代码解释
导入必要的库:
首先,导入MindSpore和MindNLP的相关模块。RNNDecoder是用于解码RNN模型输出的模块,Seq2SeqModel是用于构建序列到序列模型的类。设置随机种子:
使用ms.set_seed(42)确保结果的可复现性。定义解码器:
GreedyDecoder类继承自RNNDecoder,实现贪心解码算法。在解码过程中,依次选取每个时间步概率最大的词作为输出。定义编码器和解码器:
使用LSTM定义编码器和解码器,并将解码器封装在GreedyDecoder中。定义序列到序列模型:
使用Seq2SeqModel类将编码器和解码器封装在一起。模拟输入数据:
创建一个随机的编码器输出,作为解码器的输入。定义起始标记和结束标记,以及最大解码长度。进行解码:
调用解码器的decode方法,执行解码过程。打印解码结果:
打印解码得到的句子,展示每个时间步的预测结果。
通过本文的介绍,我们了解了文本解码的基本原理,并结合MindNLP框架,详细讲解了如何实现一个简单的贪心解码器。希望这篇文章能帮助大家更好地理解文本生成任务中的解码过程。如果有任何问题或建议,欢迎在评论区留言讨论。