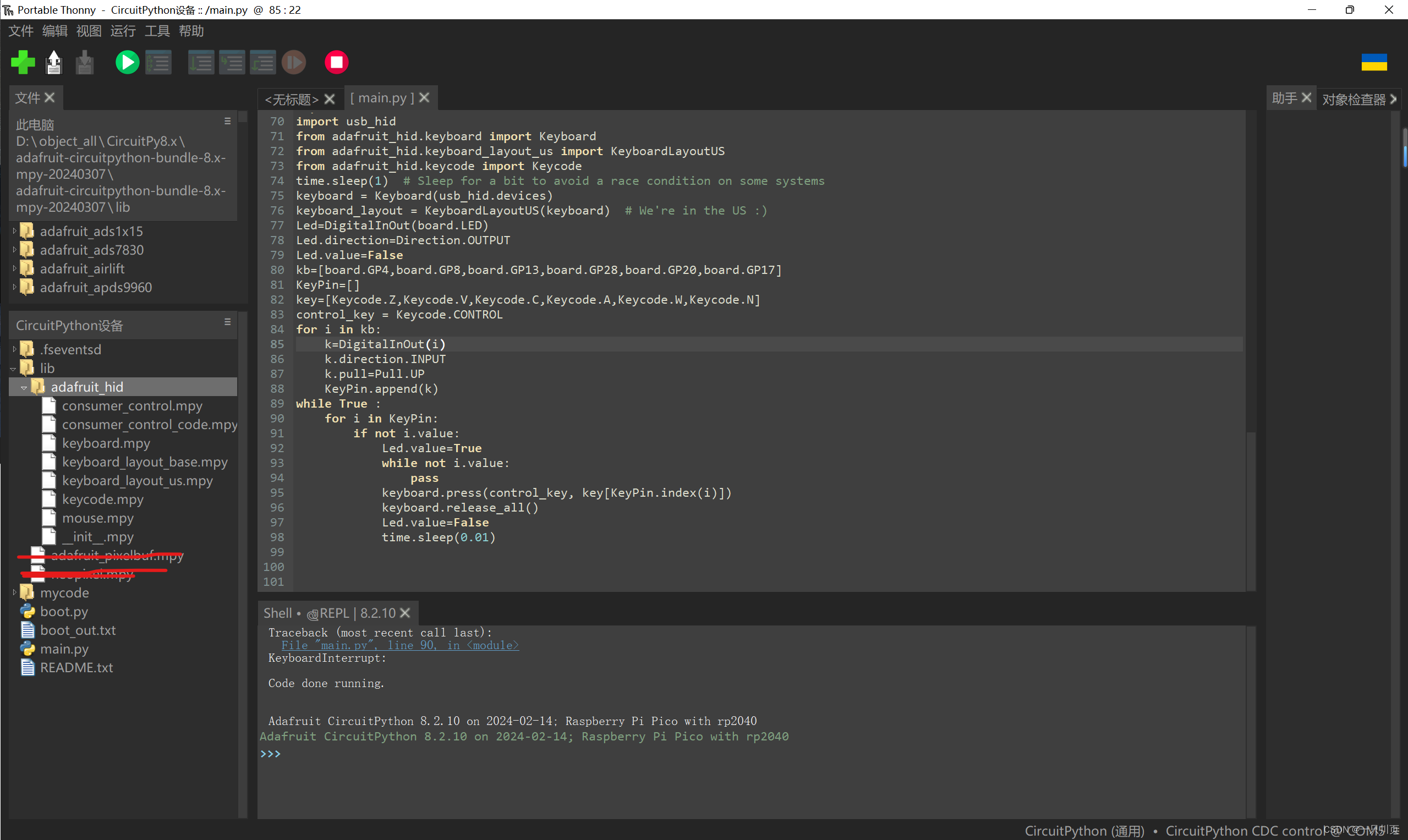
虚拟环境的存储地址:pytorch * C:\Users\huhuhu\MiniConda3\envs\pytorch
推出当前虚拟环境:
conda deactivate检查是否退出:
如果你成功退出了虚拟环境,你会看到一个星号(*)标记在 base 环境旁边,表示当前你在 base 环境中:
# conda environments:
#
base * /Users/<YourUsername>/anaconda3
pytorch /Users/<YourUsername>/anaconda3/envs/pytorch
2.1:数据操作
1、创建行向量:
张量:表示一个由数值组成的数组
创建一个含n个元素的行向量:
x = torch.arrange(n)
x2、访问张量形状
x.shape3、获取张量元素总数
x.numel()4、改变张量形状
X = x.reshape(3, 4)
X可以通过-1来自动计算出形状:
X = x.reshape(-1, 4)
X
X = x.reshape(3, -1)
X5、创建只包含特定元素的张量
(1)创建全为0的张量:
torch.zeros((2, 3, 4))
创建了一个两层三行四列的全为0的张量
(2)创建全为1的张量:
torch.ones((2, 3, 4))6、获取特定的形状的服从高斯分布的随机元素张量(均值为0,标准差为1)
标准差(Standard Deviation, 简称SD)是一种用于量化数据集中每个值相对于平均值(均值)的分散程度的统计指标。它反映了数据的离散程度,即数据点与均值的偏离程度。标准差越小,表示数据点越接近均值;标准差越大,表示数据点分布得越广。
torch.randn(3, 4)7、为所需张量每个值进行赋值:
tensor:张量
torch.tensor([[2, 1, 3, 4], [1, 2, 3, 4], [4, 3, 2, 1]])8、运算符:

求e的x次方:
x = torch.tensor([1, 2, 3, 4])
tensor.exp(x)9、连接两个张量:
torch.cat((X, Y), dim=0)按0轴(行)连接两个张量。
10、对张量中所有元素求和
X.sum()11、广播机制
进行广播的前提:
维度大小一致或其中一个维度为 1:
- 对于每一个维度,两个张量的维度大小必须相等,或者其中一个维度的大小为 1。
从末尾维度开始比较:
- 广播是从末尾的维度开始逐一比较的。也就是说,两个张量的末尾维度(最后一个维度)必须相等或其中一个为 1,然后逐步向前比较。
两个张量的形状不一致不能够进行运算会进行广播,多数情况下我们会对数组中长度为1的轴进行广播:
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2),reshape((1, 2))
a, b
a + b
矩阵将a复制列,矩阵b将复制行,然后元素相加
12、索引和切片
索引:
X[-1]切片:
X[1, 3]取区间[1 ,3)左闭右开
可以根据指定索引将数据写入张量
X[1, 2] = 9修改多行元素:
X[0:2, :] = 12
X修改多列元素:
X[:, 0:2]
X13、节省内存
通常我们在对一个张量进行运算过后,新的张量会存储在新的内存中:
before = id(y) // 获取y的内存地址
Y = Y + X
id(Y) == before这是不可取的:
(1)我们不想总是不必要的分配内存,我们希望原地执行这些更新
(2)如果不原地更新,其他引用依然会指向就得内存位置,这样我们的某些代码会引用旧的数据

也可以使用X += Y,不能使用X = X + Y
14、转换为其他python对象
A = X.numpy()
B = torch.tensor(A)
type(A), type(B)将大小为1的张量转换为python标量:
a = torch.tensor([3.5])
a, a.item(), float(a), int(a)2.2:数据预处理:
1、处理缺失值:
pd.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False, dtype=None)
data:要转换的数据,可以是 Pandas 的 Series、DataFrame 或者包含 Series 的字典。prefix:哑变量列名的前缀,可以是字符串或字符串列表。prefix_sep:前缀与原始列名之间的分隔符,默认是'_'。dummy_na:是否为 NaN 值创建哑变量列,默认为False,即不创建。columns:要进行转换的列名列表。如果指定了columns,只有这些列会被转换成哑变量。sparse:是否返回稀疏矩阵,默认为False。drop_first:是否删除每个变量的第一个水平(category),以避免多重共线性,默认为False。dtype:指定生成的哑变量的数据类型。
实例:
import pandas as pd
# 创建一个包含分类变量的 DataFrame
df = pd.DataFrame({'A': ['type1', 'type2', 'type3', 'type1', 'type2']})
print("原始数据:\n", df)
# 将分类变量转换为哑变量
dummy_df = pd.get_dummies(df['A'])
print("\n转换后的哑变量数据:\n", dummy_df)
输出:
原始数据:
A
0 type1
1 type2
2 type3
3 type1
4 type2
转换后的哑变量数据:
type1 type2 type3
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
4 0 1 0
在这个示例中,pd.get_dummies() 将列 'A' 中的分类变量转换为哑变量。每个分类变量的每个水平(category)都会被转换成一个新的二进制列。
示例 2:使用前缀和前缀分隔符
import pandas as pd
# 创建一个包含分类变量的 DataFrame
df = pd.DataFrame({'A': ['type1', 'type2', 'type3', 'type1', 'type2']})
# 使用前缀和前缀分隔符
dummy_df = pd.get_dummies(df['A'], prefix='category', prefix_sep='-')
print(dummy_df)
输出:
category-type1 category-type2 category-type3
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
4 0 1 0
在这个示例中,使用了前缀 'category' 和前缀分隔符 '-',生成了带有前缀的哑变量列。
2、转换为张量格式
X, y = torch.tensor(inputs.value), torch.tensor(output.values)
X, y2.3:线性代数
1、标量
import torch
x = torch.tensor(n)
y = torch.tensor(n)
x + y, x * y
2、向量
长度和维度和形状及矩阵的转置:
维度即为数组的长度也就是数组内元素的个数:
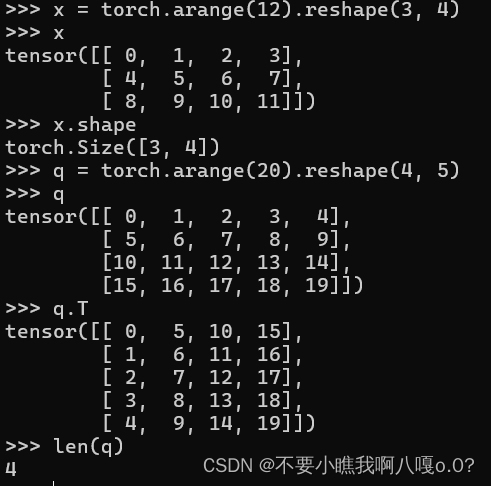
3、张量算法
(1)两个矩阵按原素乘法:哈达玛积(Hadamard product)
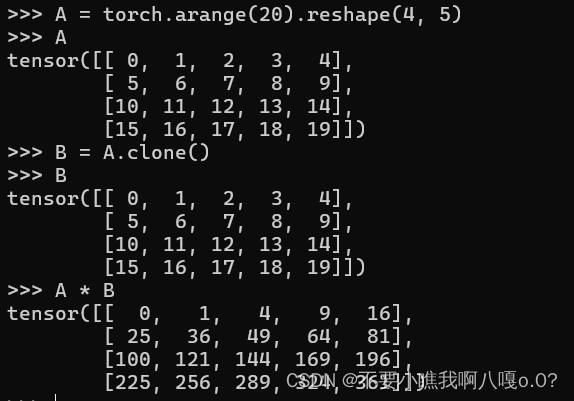
4、降维
求和:
A.sum(axis=0)axis=0表示沿着轴0进行降维操作也就是对每一列操作
对特定的行或者列进行操作(三维或以上):
三维张量:
- 轴0(axis 0):沿着第一个维度(深度方向)。
- 轴1(axis 1):沿着第二个维度(行方向)。
- 轴2(axis 2):沿着第三个维度(列方向)。
A.sum(axis=[0, 1])求均值:
这里注意mean求均值只能对float小数进行使用
三维的张量:
沿着轴0进行操作:沿着深度进行切片,可以想象为对一个正立方体进行切割,在黑夜里沿着深度切片也就是沿着z轴即将每一个长方体内的所有数据进行降维求和:
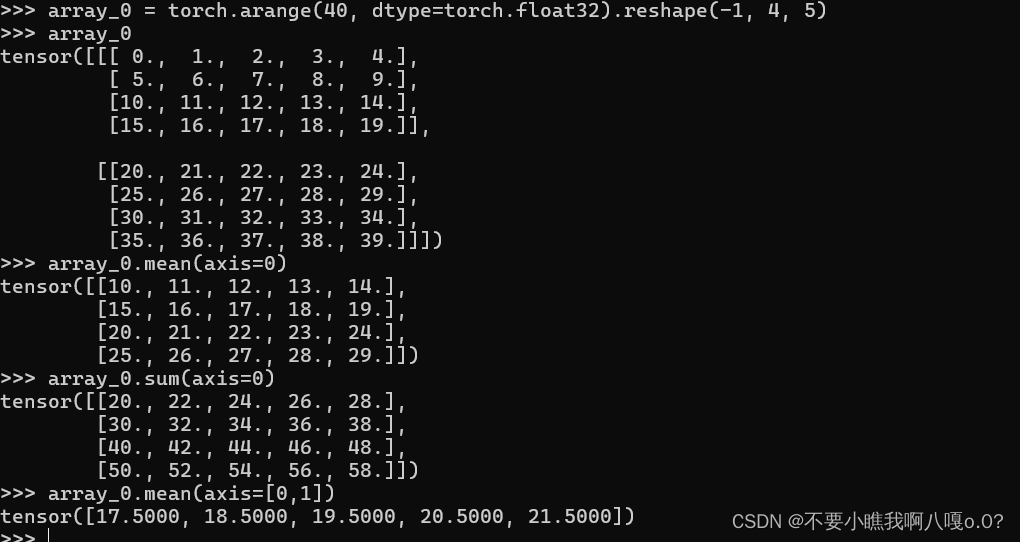
解释:
沿着轴0和轴1求均值,意味着在第一个和第二个维度上进行降维,即对整个 4×54 \times 54×5 矩阵求均值。具体计算如下:
首先将数组展平并求和:
flattened_array = [
0, 1, 2, 3, 4,
5, 6, 7, 8, 9,
10, 11, 12, 13, 14,
15, 16, 17, 18, 19,
20, 21, 22, 23, 24,
25, 26, 27, 28, 29,
30, 31, 32, 33, 34,
35, 36, 37, 38, 39
]
每列的均值计算如下:
mean_col_0 = (0+5+10+15+20+25+30+35) / 8 = 140 / 8 = 17.5
mean_col_1 = (1+6+11+16+21+26+31+36) / 8 = 148 / 8 = 18.5
mean_col_2 = (2+7+12+17+22+27+32+37) / 8 = 156 / 8 = 19.5
mean_col_3 = (3+8+13+18+23+28+33+38) / 8 = 164 / 8 = 20.5
mean_col_4 = (4+9+14+19+24+29+34+39) / 8 = 172 / 8 = 21.5
这块可能有点不好想象,但我们可以一步一步来进行降维:
先沿深度进行降维:
a_mean0 = array_0.mean(axis=0)
再沿着横轴进行降维也就是对每一列进行操作:
这里要注意我们已经将三维降低到了两维,所以我们的轴0也就变为横轴了:
a_mean0.mean(axis=0)5、非降维求和
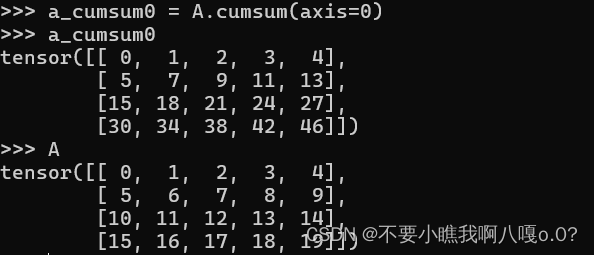
保持轴数不变:
sum_A = A.sum(axis=0, keepdims=True)由于轴数并未改变,所以我们可以通过广播将A除以sum_A
如果我们想沿某个轴计算A的元素的累计总和,可以调用consume函数,该函数不会沿任何轴降低输入张量的维度:
注意这里的求和并不是像sum那样降维操作,这里是针对每一个元素进行沿着特定轴进行求和操作
6、点积
向量是一维数组:
对两个向量进行求点积:可以用dot来求,也可以通过先对两个向量求哈达玛积然后再进行求和运算:
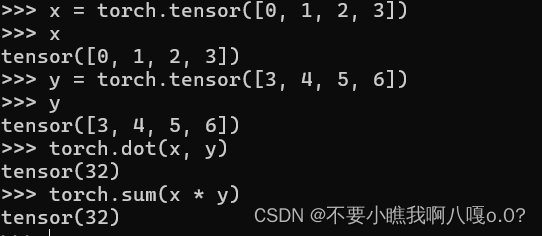
7、矩阵向量积
这里注意A向量的列维数(沿着轴1的长度)要等于x的长度
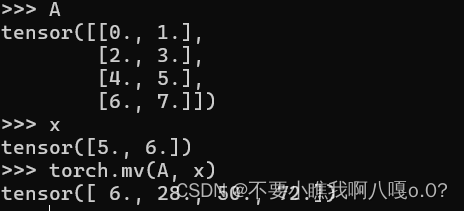
8、矩阵乘积
C(m, n) = A(m, i) * B(i, n) + .....
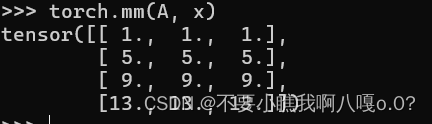
9、范数
L0范数是指向量中非0的元素的个数。(L0范数很难优化求解)
L1范数是指向量中各个元素绝对值之和
L2范数是指向量各元素的平方和然后求平方根

L1范数:
![]()
弗罗贝尼乌斯范数:是矩阵元素平方和的平方根

import torch
# 创建一个形状为 (4, 9) 的全是1的张量
matrix = torch.ones((4, 9))
# 计算 Frobenius 范数
frobenius_norm = torch.norm(matrix, p='fro')
print(frobenius_norm)