Python高级
概述
本课程旨在介绍Python编程语言中的面向对象编程(OOP)概念和技术。学生将学习如何使用类、对象、继承、多态等OOP的关键要素来构建灵活、可重用和可扩展的代码。通过实际编程练习和项目,学生将提高他们的编程技能,学会设计和实现面向对象的解决方案。
面向对象编程是在面向过程编程的基础上发展来的,它比面向过程编程具有更强的灵活性和扩展性。面向对象编程是程序员发展的分水岭,很多初学者会因无法理解面向对象而放弃学习编程,所以我们一定要足够重视。
Day11:面向对象基础
1. 类和对象
【1】类和对象的概念
面向对象编程(Object-oriented Programming,简称 OOP)是一种编程范式。
- 从思想角度讲
面向对象思想来源于对现实世界的认知。现实世界缤纷复杂、种类繁多,难于认识和理解。但是聪明的人们学会了把这些错综复杂的事物进行分类,从而使世界变得井井有条。现实世界中每一个事物都是一个对象,它是一种具体的概念。类是人们抽象出来的一个概念,所有拥有相同属性和功能的事物称为一个类;而拥有相同属性和功能的具体事物则成为这个类的实例对象。
比如现实世界中,
狗的属性是有尾巴,有毛,四条腿等,功能是能汪汪叫,能吃骨头,能咬人等。能有这些属性和功能的事物我们就认为属于狗类。
人的属性是两条腿,没有尾巴等,功能是能玩火,能尿炕,能使用工具。能有这些属性和功能的事物我们就认为属于人类。
电脑属性是有CPU,存储器,操作系统等,功能就是能安装APP,能连网等。能有这些属性和功能的事物我们就认为属于电脑类。
汽车的属性是有四个轮子,一个底盘,一个方向盘等,功能是能行驶,能加速,能刹车等。能有这些属性和功能的事物我们就认为属于汽车类。
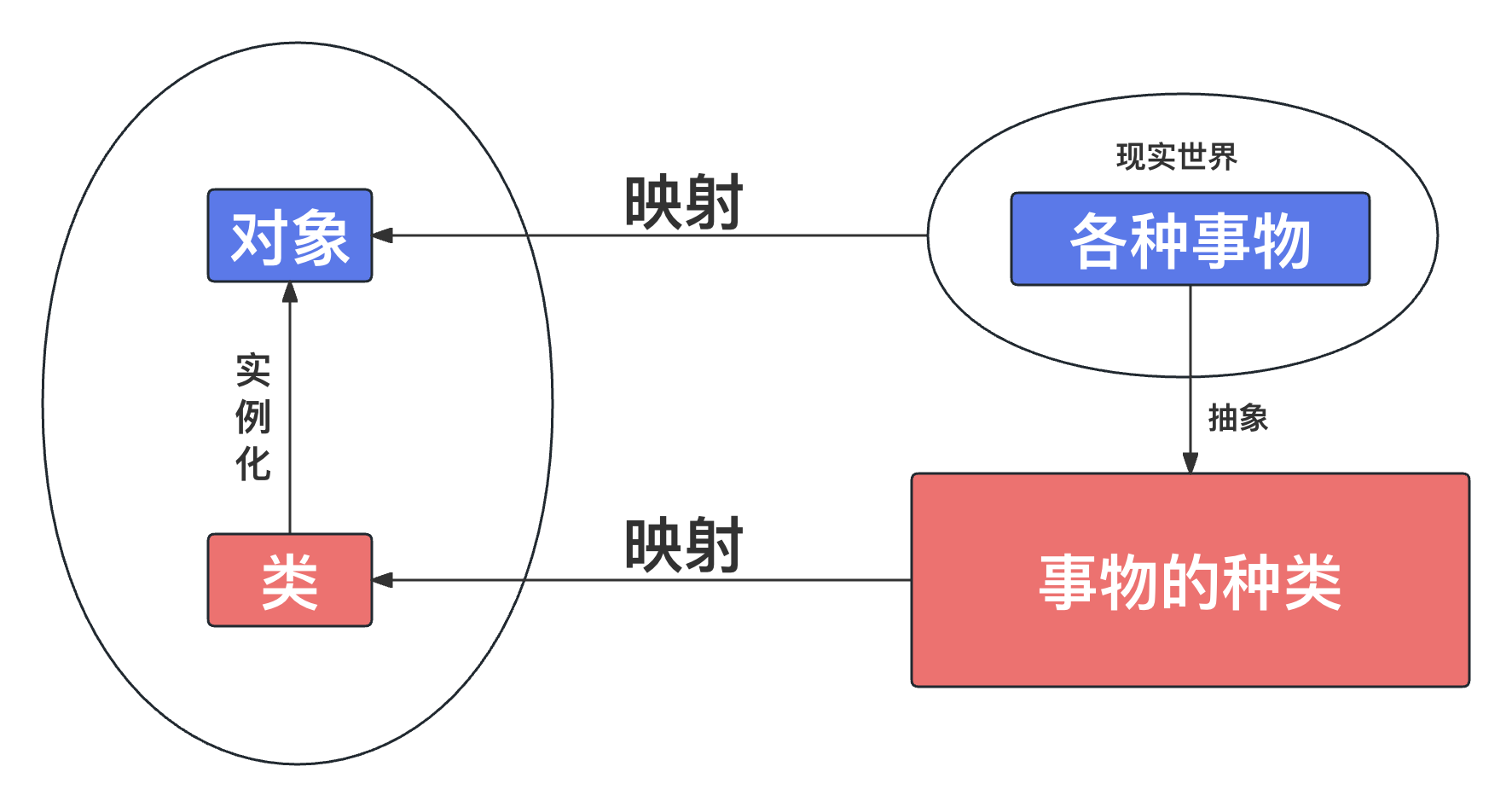
面向对象编程提供了一种从现实世界中抽象出概念和实体的方法。通过类和对象的概念,可以将现实世界中的问题和关系转化为代码结构,使得程序更加符合问题域的模型化。
面向对象编程通过采用类的概念,把事物编写成一个个“类”。在类中,用数据表示事物的状态,用函数实现事物的行为,这样就使编程方式和人的思维方式保持一致,极大的降低了思维难度。
legs_num = 4
has_hair = True
has_tail = True
def bark(self):
print("狗狂吠")
def bite(self):
print("狗咬人")
def fetch(self):
print("狗捡球")
legs_nums = 2
has_wings = True
has_teeth = False
def fly(self):
print("鸟飞翔")
def eat_worms(self):
print("鸟吃虫子")
def nest(self):
print("鸟筑巢")
类版本:
# 声明类
class Dog:
legs_num = 4
has_hair = True
has_tail = True
def bark(self):
print("狗狂吠")
def bite(self):
print("狗咬人")
def fetch(self):
print("狗捡球")
# 实例化对象
alex = Dog()
print(alex.legs_num)
alex.bark()
alex.bite()
class Bird:
legs_nums = 2
has_wings = True
has_teeth = False
def fly(self):
print("鸟飞翔")
def eat_worms(self):
print("鸟吃虫子")
def nest(self):
print("鸟筑巢")
# 实例化对象
b1 = Bird()
print(b1.has_wings)
print(b1.has_teeth)
b1.fly()
- 从封装角度讲
面向对象编程(Object-oriented Programming,简称 OOP),是一种封装代码的方法。其实,在前面章节的学习中,我们已经接触了封装,比如说,将乱七八糟的数据扔进列表中,这就是一种简单的封装,是数据层面的封装;把常用的代码块打包成一个函数,这也是一种封装,是语句层面的封装。
面向对象编程,也是一种封装的思想,不过显然比以上两种封装更先进,它可以更好地模拟真实世界里的事物(将其视为对象),并把描述特征的数据和代码块(函数)封装到一起。
面向对象编程(Object-Oriented Programming,简称OOP)相较于面向过程编程(Procedural Programming)有以下几个优点:
- 封装性(Encapsulation):面向对象编程通过将数据和操作封装在一个对象中,使得对象成为一个独立的实体。对象对外部隐藏了内部的实现细节,只暴露出必要的接口,从而提高了代码的可维护性和模块化程度。
- 继承性(Inheritance):继承是面向对象编程的重要特性之一。它允许创建一个新的类(子类),从一个现有的类(父类或基类)继承属性和方法。子类可以通过继承获得父类的特性,并可以在此基础上进行扩展或修改。继承提供了代码重用的机制,减少了重复编写代码的工作量。
- 多态性(Polymorphism):多态性使得对象可以根据上下文表现出不同的行为。通过多态机制,可以使用统一的接口来处理不同类型的对象,而不需要针对每种类型编写特定的代码。这提高了代码的灵活性和可扩展性。
- 代码的可维护性和可扩展性:面向对象编程强调模块化和代码复用,通过将功能划分为独立的对象和类,使得代码更易于理解、测试和维护。当需求变化时,面向对象编程的结构和机制使得代码的修改和扩展更加简洁和可靠。
总的来说,面向对象编程提供了一种更加结构化、可扩展和可维护的编程范式。它通过封装、继承和多态等特性,使得代码更加模块化、灵活和易于理解。这些优点使得面向对象编程成为当今广泛采用的编程范式之一,被广泛应用于软件开发中。
【2】类和实例对象的语法
面向对象最重要的概念就是类(Class)和实例(Instance),必须牢记类是抽象的模板,比如Person类,而实例是根据类创建出来的一个个具体的“对象”。
# 声明类
class 类名:
类属性...
方法...
# 类的实例化
实例对象 = 类名() # 开辟一块独立的属于实例空间,将空间地址作为返回值
# 实例对象可以通过句点符号调用类属性和方法
实例对象.类属性
实例对象.方法(实参)
- 和变量名一样,类名本质上就是一个标识符,命名遵循变量规范。如果由单词构成类名,建议每个单词的首字母大写,其它字母小写。
- 冒号 + 缩进标识类的范围
- 无论是类属性还是类方法,对于类来说,它们都不是必需的,可以有也可以没有。另外,Python 类中属性和方法所在的位置是任意的,即它们之间并没有固定的前后次序。
# 声明类
class Dog:
legs_num = 4
has_hair = True
has_tail = True
def bark(self):
print("狗狂吠")
def bite(self):
print("狗咬人")
def fetch(self):
print("狗捡球")
# 实例化对象
alex = Dog()
print(alex.legs_num)
alex.bark()
alex.bite()
# 实例化对象
peiQi = Dog()
# print(id(alex))
# print(id(peiQi))
print(id(alex.legs_num))
print(id(peiQi.legs_num))
print(id(alex.bark))
print(id(peiQi.bark))
2. 实例属性和实例方法
【1】实例属性
类变量(类属性)的特点是,所有类的实例化对象都同时共享类变量,也就是说,类变量在所有实例化对象中是作为公用资源存在的。实例属性是属于类的每个实例对象的特定属性。实例属性是在创建对象时赋予的,每个对象可以具有不同的实例属性值。
alex = Dog()
peiQi = Dog()
# 实例属性: 属于实例对象自己的属性
alex.name = "李杰"
alex.age = 10
peiQi.name = "武大郎"
peiQi.age = 20
# 问题1:
print(alex.name)
alex.age = 30
print(alex.age)
# 问题2:
print(peiQi.age)
# 问题3:
alex.bark()
alex.bark = "hello world"
# alex.bark()
peiQi.bark()
【2】实例方法和self
在 Python 的类定义中,self 是一个特殊的参数,用于表示类的实例对象自身。self 参数必须作为第一个参数出现在类的方法定义中,通常被约定为 self,但实际上你可以使用其他名称。
当你调用类的方法时,Python 会自动将调用该方法的实例对象传递给 self 参数。这样,你就可以通过 self 参数来引用和操作实例对象的属性和方法。
class Dog:
legs_num = 4
has_hair = True
has_tail = True
def eat(self):
print(f"{self.name}正在吃东西。")
def run(self):
print(f"{self.name}正在跑。")
def sleep(self):
print(f"{self.name}正在睡觉。")
def bark(self):
print(f"{self.name}正在狂吠。")
def show_info(self):
print(f"名字:{self.name},品种:{self.breed},颜色:{self.color},年龄:{self.age}")
# 声明对象
bulldog = Dog()
# 赋值实例属性
bulldog.name = "小灰"
bulldog.breed = "斗牛犬"
bulldog.color = "浅灰色"
bulldog.age = 5
# 调用斗牛犬的行为
bulldog.eat()
bulldog.run()
bulldog.sleep()
bulldog.bark()
bulldog.show_info()
3. 构造方法__init__
类实例化的步骤:类的实例化步骤:
1.创建一个实例化空间
2.自动调用__init__方法,对实例化对象属性进行赋值
3.返回实例化对象的空间地址

在上节0课的代码中,对象的属性是通过直接赋值给对象的实例属性来实现的,而不是在构造方法中进行初始化。这样做可能会导致以下问题:
- 代码冗余:每次创建对象时都需要分别为每个对象赋值实例属性,这会导致代码冗余和重复劳动。
- 可维护性差:如果类的属性发生变化或新增属性,需要修改多处代码来适应这些变化,而如果使用构造方法来初始化属性,则只需要在一个地方进行修改。
为了改进这种写法,可以使用构造方法来初始化对象的属性。构造方法在创建对象时自动调用,并可以接受参数来初始化对象的属性。
class Dog:
def __init__(self, name, breed, color, age):
self.name = name
self.breed = breed
self.color = color
self.age = age
def eat(self):
print(f"{self.name}正在吃东西。")
def run(self):
print(f"{self.name}正在跑。")
def sleep(self):
print(f"{self.name}正在睡觉。")
def bark(self):
print(f"{self.name}正在狂吠。")
def show_info(self):
print(f"名字:{self.name},品种:{self.breed},颜色:{self.color},年龄:{self.age}")
# 声明对象
bulldog = Dog("小灰", "斗牛犬", "浅灰色", 5)
# 调用斗牛犬的行为
bulldog.bark()
bulldog.show_info()
# 声明对象
beagle = Dog("小黄", "小猎犬", "橘色", 6)
beagle.bark()
beagle.show_info()
实例化一个类的过程可以分为以下几个步骤:
- 创建一个新的对象(即开辟一块独立空间),它是类的实例化结果。
- 调用类的
__init__方法,将新创建的对象作为第一个参数(通常命名为self),并传递其他参数(如果有的话)。 - 在
__init__方法中,对对象进行初始化,可以设置对象的属性和执行其他必要的操作。 - 返回新创建的对象,使其成为类的实例。
在创建类时,我们可以手动添加一个 __init__() 方法,该方法是一个特殊的类实例方法,称为构造方法(或构造函数)。
__init__() 方法可以包含多个参数,但必须包含一个名为 self 的参数,且必须作为第一个参数。除了 self 参数外,还可以自定义一些参数,从而完成初始化的工作。
- 注意到
__init__方法的第一个参数永远是self,表示创建的实例本身,因此,在__init__方法内部,就可以把各种属性绑定到self,因为self是指向创建的实例本身。- 实例属性,实例变量,实例成员变量都是指的存在实例空间的属性
4. 一切皆对象
python中的一切皆对象,任何数据类型都是对象,同时自定义的实例对象也是一等公民,具有参数传递,可以作为函数参数和返回值
在python语言中,一切皆对象!
我们之前学习过的字符串,列表,字典等等数据都是一个个的类,我们用的所有数据都是一个个具体的实例对象。
区别就是,那些类是在解释器级别注册好的,而现在我们学习的是自定义类,但语法使用都是相同的。所以,我们自定义的类实例对象也可以和其他数据对象一样可以进行传参、赋值等操作。
- 自定义类对象是可变数据类型,我们可以在创建后对其进行修改,添加或删除属性和方法,而不会改变类对象的身份。
- 实例对象也是一等公民
5. 类对象、类属性以及类方法
类对象,任何一个类也是一个对象,拥有自己的空间,有类属性和类方法,类属性不能通过实例对象修改,只能通过类对象修改。类方法调用自己的类方法就是一个普通的函数,不会像实例对象调用那样自动传入self,需要手动传入。
这节课讲了类方法:@classmethod
类方法默认传入一个cls对象,是当前类对象的地址。类方法可以通过类对象调用
【1】类对象
类对象是在Python中创建类时生成的对象,它代表了该类的定义和行为,存储着公共的类属性和方法
class Car(object):
# 类属性
total_cars = 0
def __init__(self,make,model):
self.make = make
self.model = model
# 实例方法
def accelerate(self):
print(f"一辆{self.make}的{self.model}正在加速")
car1 = Car("Toyota", "Camry")
类对象.实例方法会怎么样?
【2】修改类属性
class Car:
total_cars = 0
def __init__(self, make, model):
self.make = make
self.model = model
Car.total_cars += 1
# 实例方法
def accelerate(self):
print(f"一辆{self.make}的{self.model}正在加速")
def display_total_cars(self):
# print("Total cars:", self.total_cars)
print("Total cars:", Car.total_cars)
# 创建两辆汽车
car1 = Car("Toyota", "Camry")
car1.display_total_cars()
car2 = Car("Honda", "Accord")
car1.display_total_cars()
【3】类方法
定义:使用装饰器@classmethod。第一个参数必须是当前类对象,该参数名一般约定为cls,通过它来传递类的属性和方法(不能传实例的属性和方法);
调用:类对象或实例对象都可以调用。
class Car:
total_cars = 0
def __init__(self, make, model):
self.make = make
self.model = model
Car.total_cars += 1
@classmethod
def display_total_cars(cls):
print(f"Total cars of {cls.__name__}: {cls.total_cars}")
# 创建两辆汽车
car1 = Car("Toyota", "Camry")
car2 = Car("Honda", "Accord")
# 显示车辆总数
Car.display_total_cars() # 输出: Total cars of Car: 2
# 创建另一辆汽车
car3 = Car("Ford", "Mustang")
# 显示更新后的车辆总数
Car.display_total_cars() # 输出: Total cars of Car: 3
6. 静态方法
定义:使用装饰器@staticmethod。参数随意,没有self和cls参数,但是方法体中不能使用类或实例的任何属性和方法;
调用:类对象或实例对象都可以调用。
class Cal():
@staticmethod
def add(x,y):
return x+y
@staticmethod
def mul(x,y):
return x*y
cal=Cal()
print(cal.add(1, 4))
or
print(Cal.add(3,4))
面向对象进阶
1. 三大特性之继承
面向对象的编程带来的主要好处之一是代码的重用,实现这种重用的方法之一是通过继承机制。通过继承创建的新类称为子类或派生类,被继承的类称为基类、父类或超类。
class 派生类名(基类名)
...
【1】继承的基本使用
继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承我们能够非常方便地复用以前的代码,能够大大的提高开发的效率。
实际上继承者是被继承者的特殊化,它除了拥有被继承者的特性外,还拥有自己独有得特性。例如猫有抓老鼠、爬树等其他动物没有的特性。同时在继承关系中,继承者完全可以替换被继承者,反之则不可以,例如我们可以说猫是动物,但不能说动物是猫就是这个道理,其实对于这个我们将其称之为“向上转型”。
诚然,继承定义了类如何相互关联,共享特性。对于若干个相同或者相识的类,我们可以抽象出他们共有的行为或者属相并将其定义成一个父类或者超类,然后用这些类继承该父类,他们不仅可以拥有父类的属性、方法还可以定义自己独有的属性或者方法。
同时在使用继承时需要记住三句话:
1、子类拥有父类非私有化的属性和方法。
2、子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
3、子类可以用自己的方式实现父类的方法。(下面会介绍)。
# 无继承方式
class Dog:
def eat(self):
print("eating...")
def sleep(self):
print("sleep...")
def swimming(self):
print("swimming...")
class Cat:
def eat(self):
print("eating...")
def sleep(self):
print("sleep...")
def climb_tree(self):
print("climb_tree...")
# 继承方式
class Animal:
def eat(self):
print("eating...")
def sleep(self):
print("sleep...")
class Dog(Animal):
def swimming(self):
print("toshetou...")
class Cat(Animal):
def climb_tree(self):
print("climb_tree...")
alex = Dog()
alex.run()
【2】重写父类方法和调用父类方法
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def sleep(self):
print(":::", self.name)
print("基类sleep...")
class Emp(Person):
# def __init__(self,name,age,dep):
# self.name = name
# self.age = age
# self.dep = dep
def __init__(self, name, age, dep):
# Person.__init__(self,name,age)
super().__init__(name, age)
self.dep = dep
def sleep(self):
# print("子类sleep...")
# 调用父类方法
# 方式1 :父类对象调用 父类对象.方法(self,其他参数)
# Person.sleep(self)
# 方式2: super关键字 super().方法(参数)
super().sleep()
yuan = Emp("yuan", 18, "教学部")
yuan.sleep()
print(yuan.dep)
# 测试题:
class Base:
def __init__(self):
self.func()
def func(self):
print('in base')
class Son(Base):
def func(self):
print('in son')
s = Son()
【3】多重继承
多重继承后,现在对实例方法的查找顺序是:实例空间->类空间->父类空间依次查找
如果在继承元组中列了一个以上的类,那么它就被称作"多重继承" 。派生类的声明,与他们的父类类似,继承的基类列表跟在类名之后,如下所示:
class SubClassName (ParentClass1[, ParentClass2, ...]):
...
多继承有什么意义呢?还拿上面的例子来说,蝙蝠和鹰都可以飞,飞的功能就重复定义了。
class Animal:
def eat(self):
print("eating...")
def sleep(self):
print("sleep...")
class Eagle(Animal):
def fly(self):
print("fly...")
class Bat(Animal):
def fly(self):
print("fly...")
有同学肯定想那就放到父类Animal中,可是那样的话其他不会飞的动物还怎么继承Animal呢?所以,这时候多重继承就发挥功能了:
class Fly:
def fly(self):
print("fly...")
class Eagle(Animal,Fly):
pass
class Bat(Animal,Fly):
pass
【4】内置函数补充
实例对象的内置函数:
isinstance(alex,dog)用来判断该实例是否是该类的实例对象。
dir(alex)可以获取该对象的全部方法,包括内置和自定义的
alex.__dict__只能获取自定义的属性
(1) type 和isinstance方法
class Animal:
def eat(self):
print("eating...")
def sleep(self):
print("sleep...")
class Dog(Animal):
def swim(self):
print("swimming...")
alex = Dog()
mjj = Dog()
print(isinstance(alex,Dog))
print(isinstance(alex,Animal))
print(type(alex))
(2)dir()方法和__dict__属性
dir(obj)可以获得对象的所有属性(包含方法)列表, 而obj.__dict__对象的自定义属性字典
注意事项:
dir(obj)获取的属性列表中,方法也认为属性的一种。返回的是listobj.__dict__只能获取自己自定义的属性,系统内置属性无法获取。返回是dict
class Student:
def __init__(self, name, score):
self.name = name
self.score = score
def test(self):
pass
yuan = Student("yuan", 100)
print("获取所有的属性列表")
print(dir(yuan))
print("获取自定义属性字段")
print(yuan.__dict__)
其中,类似__xx__的属性和方法都是有特殊用途的。如果调用len()函数视图获取一个对象的长度,其实在len()函数内部会自动去调用该对象的__len__()方法
2. 三大特性之封装
封装是指隐藏对象的属性和实现细节,仅对外提供公共访问方式。
我们程序设计追求“高内聚,低耦合”
- 高内聚:类的内部数据操作细节自己完成,不允许外部干涉
- 低耦合:仅对外暴露少量的方法用于使用。
隐藏对象内部的复杂性,只对外公开简单的接口。便于外界调用,从而提高系统的可扩展性、可维护性。通俗的说,把该隐藏的隐藏起来,该暴露的暴露岀来。这就是封装性的设计思想。
【1】私有属性
私有属性的实现机制,通过__属性名这种方式其实是将这个变量再创建时对属性名进行一个转换,转换为 _类名__属性名,注意这里的类名是当前属性的代码所再类名。所以在父类定义的__属性是不能在子类通过__获取的,因为两者类名不同转换后的名称也就不同。
在class内部,可以有属性和方法,而外部代码可以通过直接调用实例变量的方法来操作数据,这样,就隐藏了内部的复杂逻辑。但是,从前面Student类的定义来看,外部代码还是可以自由地修改一个实例的name、score属性:
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
alvin = Student("alvin",66)
yuan = Student("yuan",88)
alvin.score=100
print(alvin.score)
如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线__,在Python中,实例的变量名如果以__开头,就变成了一个私有变量(private),只有内部可以访问,外部不能访问,所以,我们把Student类改一改:
class Student(object):
def __init__(self, name, score):
self.name = name
self.__score = score
alvin = Student("alvin",66)
yuan = Student("yuan",88)
print(alvin.__score)
改完后,对于外部代码来说,没什么变动,但是已经无法从外部访问实例变量.__name和实例变量.__score。这样就确保了外部代码不能随意修改对象内部的状态,这样通过访问限制的保护,代码更加健壮。但是如果外部代码要获取name和score怎么办?可以给Student类增加get_score这样的方法:
class Student(object):
def __init__(self, name, score):
self.name = name
self.__score = score
def get_score(self):
return self.__score
alvin=Student("alvin",66)
yuan=Student("yuan",88)
print(alvin.get_score())
如果又要允许外部代码修改score怎么办?可以再给Student类增加set_score方法:
class Student(object):
def __init__(self, name, score):
self.name = name
self.__score = score
def get_score(self):
return self.__score
def set_score(self,score):
self.__score = score
alvin = Student("alvin",12)
print(alvin.get_score())
alvin.set_score(100)
print(alvin.get_score())
你也许会问,原先那种直接通过alvin.score = 100也可以修改啊,为什么要定义一个方法大费周折?因为在方法中,可以设置值时做其他操作,比如记录操作日志,对参数做检查,避免传入无效的参数等等:
class Student(object):
...
def set_score(self,score):
if isinstance(score,int) and 0 <= score <= 100:
self.__score = score
else:
raise ValueError('error!')
注意
1、这种机制也并没有真正意义上限制我们从外部直接访问属性,知道了类名和属性名就可以拼出名字:
_类名__属性,然后就可以访问了2、变形的过程只在类的内部生效,在定义后的赋值操作,不会变形
class Student(object):
def __init__(self, name, score):
self.name = name
self.__score = score
def get_score(self):
return self.__score
yuan=Student("yuan",66)
print(yuan.__dict__)
yuan.__age=18
print(yuan.__dict__)
案例
class Person(object):
def __init__(self, name, score):
self.name = name
self.__score = score
class Student(Person):
def get_score(self):
return self.__score
def set_score(self,score):
self.__score=score
yuan=Student("yuan",66)
print(yuan.__dict__)
print(yuan.get_score())
子类无法直接访问父类的私有属性。子类只能在自己的方法中访问和修改自己定义的私有属性,无法直接访问父类的私有属性。
单下划线、双下划线、头尾双下划线说明:
__foo__: 定义的是特殊方法,一般是系统定义名字 ,类似__init__()之类的。__foo: 双下划线的表示的是私有类型(private)的变量, 只能是允许这个类本身进行访问了。_foo: 以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问。(约定成俗,不限语法)
【2】私有方法
在父类和子类中分类定义__name,两者互不影响,因为该私有属性由于类名不同,在转换后空间中的属性名也就不同
私有方法是指只能在类的内部访问和调用的方法,无法在类的外部直接访问或调用。
class AirConditioner:
def __init__(self):
# 初始化空调
pass
def cool(self, temperature):
# 对外制冷功能接口方法
self.__turn_on_compressor()
self.__set_temperature(temperature)
self.__blow_cold_air()
self.__turn_off_compressor()
def __turn_on_compressor(self):
# 打开压缩机(私有方法)
pass
def __set_temperature(self, temperature):
# 设置温度(私有方法)
pass
def __blow_cold_air(self):
# 吹冷气(私有方法)
pass
def __turn_off_compressor(self):
# 关闭压缩机(私有方法)
pass
在继承中,父类如果不想让子类覆盖自己的方法,可以将方法定义为私有的:
class Base:
def foo(self):
print("foo from Base")
def test(self):
self.foo()
class Son(Base):
def foo(self):
print("foo from Son")
s=Son()
s.test()
class Base:
def __foo(self):
print("foo from Base")
def test(self):
self.__foo()
class Son(Base):
def __foo(self):
print("foo from Son")
s=Son()
s.test()
【3】property属性操作
(1)property属性装饰器
使用接口函数获取修改数据 和 使用点方法设置数据相比, 点方法使用更方便,我们有什么方法达到 既能使用点方法,同时又能让点方法直接调用到我们的接口了,答案就是property属性装饰器:
class Student(object):
def __init__(self,name,score,sex):
self.__name = name
self.__score = score
self.__sex = sex
@property
def name(self):
return self.__name
@name.setter
def name(self,name):
if len(name) > 1 :
self.__name = name
else:
print("name的长度必须要大于1个长度")
@property
def score(self):
return self.__score
# @score.setter
# def score(self, score):
# if score > 0 and score < 100:
# self.__score = score
# else:
# print("输入错误!")
yuan = Student('yuan',18,'male')
yuan.name = '苑昊' # 调用了@name.setter
print(yuan.name) # 调用了@property的name函数
yuan.score = 199 # @score.setter
print(yuan.score) # @property的score方法
(2)property属性函数
python提供了更加人性化的操作,可以通过限制方式完成只读、只写、读写、删除等各种操作
class Person:
def __init__(self, name):
self.__name = name
def __get_name(self):
return self.__name
def __set_name(self, name):
self.__name = name
def __del_name(self):
del self.__name
# property()中定义了读取、赋值、删除的操作
# name = property(__get_name, __set_name, __del_name)
name = property(__get_name, __set_name)
yuan = Person("yuan")
print(yuan.name) # 合法:调用__get_name
yuan.name = "苑昊" # 合法:调用__set_name
print(yuan.name)
# property中没有添加__del_name函数,所以不能删除指定的属性
del p.name # 错误:AttributeError: can't delete Attribute
@property广泛应用在类的定义中,可以让调用者写出简短的代码,同时保证对参数进行必要的检查,这样,程序运行时就减少了出错的可能性。
3. 三大特性之多态
多态:是一个对象在传入的参数不同时有着不同的表现结果。
python中解释多态的鸭子模型:就是不需要显示的指定传入参数的类型,只要对象有所需要的方法,就可以使用。
【1】java多态
在java里,多态是同一个对象具有不同表现形式或形态的能力,即对象多种表现形式的体现,就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量倒底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
如下图所示:使用手机扫描二维码支付时,二维码并不知道客户是通过何种方式进行支付,只有通过二维码后才能判断是走哪种支付方式执行对应流程。
// 支付抽象类或者接口
public class Pay {
public String pay() {
System.out.println("do nothing!")
return "success"
}
}
// 支付宝支付
public class AliPay extends Pay {
@Override
public String pay() {
System.out.println("支付宝pay");
return "success";
}
}
// 微信支付
public class WeixinPay extends Pay {
@Override
public String pay() {
System.out.println("微信Pay");
return "success";
}
}
// 银联支付
public class YinlianPay extends Pay {
@Override
public String pay() {
System.out.println("银联支付");
return "success";
}
}
// 测试支付
public static void main(String[] args) {
// 测试支付宝支付多态应用
Pay pay = new AliPay();
pay.pay();
// 测试微信支付多态应用
pay = new WeixinPay();
pay.pay();
// 测试银联支付多态应用
pay = new YinlianPay();
pay.pay();
}
// 输出结果如下:
支付宝pay
微信Pay
银联支付
多态存在的三个必要条件:
- 继承
- 重写
- 父类引用指向子类对象
比如:
Pay pay = new AliPay()
当使用多态方式调用方法时,首先检查父类中是否有该方法,如果没有,则编译错误;如果有,再去调用子类的同名方法。
【2】鸭子模型
鸭子模型(Duck typing)是一种动态类型系统中的编程风格或理念,它强调对象的行为比其具体类型更重要。根据鸭子模型的说法,如果一个对象具有与鸭子相似的行为,那么它就可以被视为鸭子。
鸭子模型源自于一个简单的说法:“如果它看起来像鸭子,叫起来像鸭子,那么它就是鸭子。”在编程中,这意味着我们更关注对象是否具有特定的方法或属性,而不是关注对象的具体类型。
通过鸭子模型,我们可以编写更灵活、通用的代码,而不需要显式地指定特定的类型或继承特定的接口。只要对象具有所需的方法和属性,就可以在代码中使用它们,无论对象的具体类型是什么。
class AliPay:
def pay(self):
print('通过支付宝消费')
class WeChatPay:
def pay(self):
print('通过微信消费')
class Order(object):
def account(self,pay_obj):
pay_obj.pay()
pay1 = WeChatPay("yuan", 100)
pay2 = AliPay("alvin", 200)
order = Order()
order.account(pay1)
order.account(pay2)
4. 反射
反射的基本操作,其实就是反射方法通过变量名称字符串来访问修改操作的行为。
反射这个术语在很多语言中都存在,并且存在大量的运用,今天我们说说什么是反射,反射主要是指程序可以访问、检测和修改它本身状态或行为的一种能力。
==在Python中,反射是指在运行时通过名称字符串来访问、检查和操作对象的属性和方法的能力。==Python提供了一些内置函数和特殊方法,使得可以动态地获取对象的信息并执行相关操作。
Python中的反射主要有下面几个方法:
# 1. 判断对象中有没有一个name字符串对应的方法或属性
hasattr(object,name)
# 2. 获取对象name字符串属性的值,如果不存在返回default的值
getattr(object, name, default=None)
# 3. 设置对象的key属性为value值,等同于object.key = value
setattr(object, key, value)
# 4. 删除对象的name字符串属性
delattr(object, name)
应用1:
class Person:
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
yuan=Person("yuan",22,"male")
print(yuan.name)
print(yuan.age)
print(yuan.gender)
while 1:
# 由用户选择查看yuan的哪一个信息
attr = input(">>>")
if hasattr(yuan, attr):
val = getattr(yuan, attr)
print(val)
else:
val=input("yuan 没有你该属性信息!,请设置该属性值>>>")
setattr(yuan,attr,val)
应用2:
class CustomerManager:
def __init__(self):
self.customers = []
def add_customer(self):
print("添加客户")
def del_customer(self):
print("删除客户")
def update_customer(self):
print("修改客户")
def query_one_customer(self):
print("查询一个客户")
def show_all_customers(self):
print("查询所有客户")
class CustomerSystem:
def __init__(self):
self.cm = CustomerManager()
def run(self):
print("""
1. 添加客户
2. 删除客户
3. 修改客户
4. 查询一个客户
5. 查询所有客户
6. 保存
7. 退出
""")
while True:
choice = input("请输入您的选择:")
if choice == "6":
self.save()
continue
elif choice == "7":
print("程序退出!")
break
try:
method_name = "action_" + choice
method = getattr(self, method_name)
method()
except AttributeError:
print("无效的选择")
def save(self):
print("保存数据")
def action_1(self):
self.cm.add_customer()
def action_2(self):
self.cm.del_customer()
def action_3(self):
self.cm.update_customer()
def action_4(self):
self.cm.query_one_customer()
def action_5(self):
self.cm.show_all_customers()
cs = CustomerSystem()
cs.run()
5. 魔法方法
Python 类里有一种方法,叫做魔法方法(special method)。Python 的类里提供的,两个下划线开始,两个下划线结束的方法,就是魔法方法,魔法方法在特定行为下就会被激活,自动执行。
【1】__new__()方法
__new__魔法方法:是在__init__方法执行前执行的,__new__方法返回一个创建的实例的地址,也就是self。
__new__通常应用在单例模式,就是一个类只能被实例化一次,每次实例化都返回同一个对象实例。
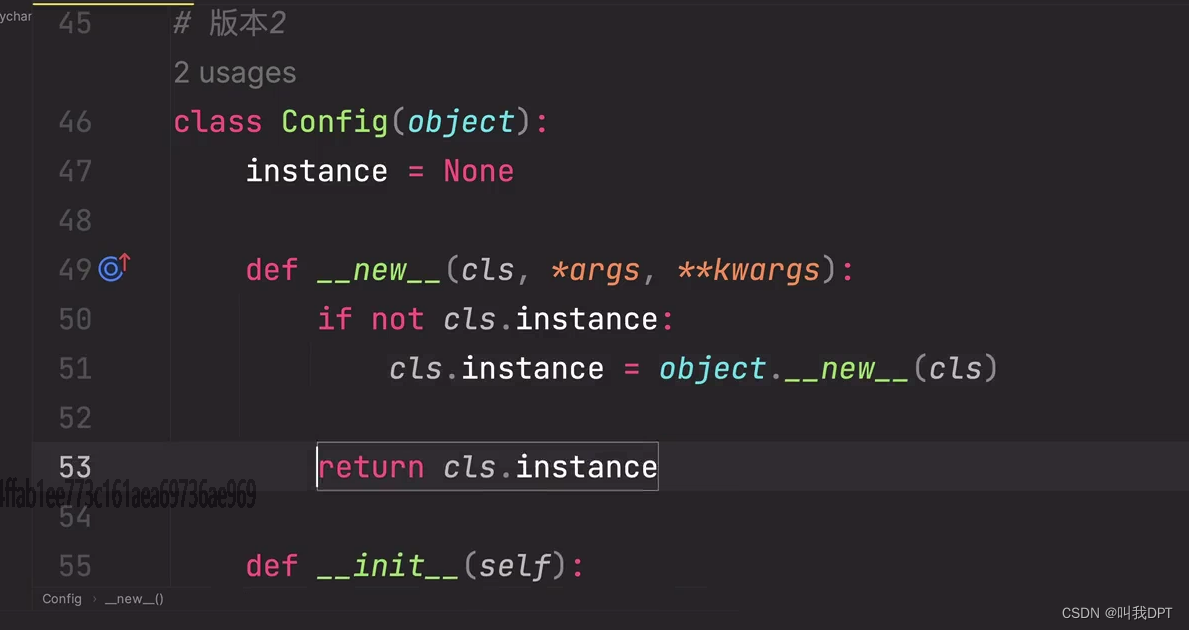
__new__() 方法是在 Python 中定义一个类的时候可以定义的一个特殊方法。它被用来创建一个类的新实例(对象)。
在 Python 中,创建一个新的实例一般是通过调用类的构造函数 __init__() 来完成的。然而,类名()创建对象时,在自动执行 __init__()方法前,会先执行 object.__new__方法,在内存中开辟对象空间并返回该对象。然后,Python 才会调用 __init__() 方法来对这个新实例进行初始化。
class Person(object):
# 其中,cls参数表示类本身,*args 和 **kwargs参数用于接收传递给构造函数的参数。
def __new__(cls, *args, **kwargs):
print("__new__方法执行")
# return object.__new__(cls)
def __init__(self, name, age):
print("__init__方法执行")
self.name = name
self.age = age
yuan = Person("yuan", 23)
_new__()方法的主要作用是创建实例对象,它可以被用来控制实例的创建过程。相比之下,__init__()方法主要用于初始化实例对象。
__new__() 方法在设计模式中常常与单例模式结合使用,用于创建一个类的唯一实例。单例模式是一种创建型设计模式,它确保一个类只有一个实例,并提供一个全局访问点来获取该实例。
class Singleton:
_instance = None
def __new__(cls, *args, **kwargs):
if not cls._instance:
cls._instance = super().__new__(cls)
return cls._instance
# 创建实例
obj1 = Singleton()
obj2 = Singleton()
# 检查是否为同一个实例
print(obj1 is obj2) # 输出: True
【2】__str__方法
触发__str__方法的操作是str()强转,print内部会自动帮我str强转。
__str__函数必须返回字符串,因为当print(对象)时会自动触发str(对象)强转,当对对象进行str()强转时会自动执行__str__函数直接返回
改变对象的字符串显示。可以理解为使用print函数打印一个对象时,会自动调用对象的__str__方法
class Person(object):
def __init__(self, name, age):
print("__init__方法执行")
self.name = name
self.age = age
def __str__(self):
return self.name
yuan = Person("yuan", 23)
print(yuan)
# 案例2
class Book(object):
def __init__(self, title, publisher, price):
self.title = title
self.publisher = publisher
self.price = price
book01 = Book("金瓶梅", "苹果出版社", 699)
print(book01)
【3】__eq__ 方法
__eq__在判断两个实力对象==时自动触发,object基类的eq方法默认判断id值
两个不同类的对象也可以比较,dog==cat,此时就调用的是dog的__eq__方法
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def __eq__(self, obj):
return self.name == obj.name
yuan = Person("yuan", 23)
alvin = Person("alvin", 23)
print(yuan == alvin)
__eq__(self, other): 判断对象是否相等,通过==运算符调用。__lt__(self, other): 判断对象是否小于另一个对象,通过<运算符调用。__gt__(self, other): 判断对象是否大于另一个对象,通过>运算符调用。__add__(self, other): 对象的加法操作,通过+运算符调用
【4】__len__方法
__len__方法在len()时自动触发,len方法一般使用在容器类型
当定义一个自定义的容器类时,可以使用 __len__() 方法来返回容器对象中元素的数量。下面是一个示例,演示了如何在自定义列表类中实现 __len__() 方法:
class Cache01:
def __init__(self):
self.data = []
def __len__(self):
return len(self.data)
def add(self, item):
self.data.append(item)
def remove(self, item):
self.data.remove(item)
# 创建自定义列表对象
cache = Cache01()
# 获取列表的长度
print(len(cache))
class Cache02:
def __init__(self):
self.data = {}
def __len__(self):
return len(self.data)
def add(self, key, value):
self.data[key] = value
def remove(self, key):
del self.data[key]
一定会有同学问,Dpt老师,为什么要封装这个类,直接使用self.data = {}不就完了吗?
当我们封装一个类时,我们将相关的数据和操作放在一个包裹(类)中,就像把一些东西放进一个盒子里一样。这个盒子提供了一种保护和管理数据的方式,同时也定义了外部与内部之间的交互方式。
为什么要这样做呢?想象一下,如果我们直接将数据存储在类之外的变量中,其他代码可以直接访问和修改它。这可能导致数据被误用或篡改,造成不可预测的结果。而通过封装,我们可以将数据放在类的内部,并提供一些方法(接口)来访问和修改数据。这就像将数据放进盒子里,并用盒子上的门来控制对数据的访问。
这种封装的好处是什么呢?首先,它提供了一种信息隐藏的机制。外部代码只能通过类提供的方法来访问数据,无法直接触及数据本身。这样可以保护数据的完整性和一致性,防止不恰当的访问和修改。其次,封装使得代码更加模块化和可重用。我们可以将相关的数据和操作组织在一个类中,成为一个功能完整的单元,方便调用和扩展。
总而言之,封装就像把数据放进一个盒子里,通过提供方法来控制对数据的访问。这样做可以保护数据,提高代码的可读性和可维护性,并促进代码的模块化和重用。
【5】__item__系列
这节课讲了item系列的魔法方法,旨在让我们可以像操作字典数据一样操作自定义的容器对象
class Cache:
def __init__(self):
self.data = {}
def __getitem__(self, key):
return self.data[key]
def __setitem__(self, key, value):
self.data[key] = value
def __delitem__(self, key):
del self.data[key]
def __contains__(self, key):
return key in self.data
在上述例子中,我们创建了一个名为 Cache 的自定义类,并实现了 __getitem__、__setitem__、__delitem__ 和 __contains__ 这些特殊方法。
使用这个自定义的缓存类,我们可以像操作字典一样操作缓存数据,例如:
cache = Cache()
# 存储数据
cache['key1'] = 'value1'
cache['key2'] = 'value2'
# 获取数据
print(cache['key1']) # 输出: 'value1'
print(cache['key2']) # 输出: 'value2'
# 检查键是否存在
print('key1' in cache) # 输出: True
# 删除数据
del cache['key1']
# 检查键是否存在
print('key1' in cache) # 输出: False
通过实现特殊方法,我们可以使用类似于==字典的语法来访问和操作缓存对象==。这样,我们可以更方便地存储、获取和删除缓存数据,同时也可以使用其他字典操作,如检查键是否存在。
【6】__attr__系列
attr系列方法可以让我们属性操作的语法一样操作我们自定义的容器类型
class Cache:
def __init__(self):
self.__data = {}
def __setattr__(self, name, value):
self.__data[name] = value
def __getattr__(self, name):
if name in self.__data:
return self.__data[name]
else:
raise AttributeError(f"'Cache' object has no attribute '{name}'")
def __delattr__(self, name):
if name in self.__data:
del self.__data[name]
else:
raise AttributeError(f"'Cache' object has no attribute '{name}'")
def __contains__(self, name):
return name in self.__data
在这个示例中,我们使用 __setattr__ 方法来设置属性,将属性存储在私有属性 __data 中。当我们尝试设置属性时,__setattr__ 方法会被自动调用,并将属性存储到私有字典中。
而在 __getattr__ 方法中,我们实现了对属性的访问。如果属性存在于私有字典 __data 中,它将返回属性的值。如果属性不存在,则会引发 AttributeError 异常。
类似地,我们还实现了 __delattr__ 方法来删除属性。如果属性存在于私有字典 __data 中,它将被删除。如果属性不存在,则会引发 AttributeError 异常。
最后,我们还重写了 __contains__ 方法,以实现在缓存中检查属性是否存在的功能。
使用这个经过修改的缓存类,我们可以使用类似于==属性操作的语法:对象.属性==来访问和操作缓存对象。
class Cache(object):
def __init__(self):
self.__dict__["data"] = {}
def __setattr__(self, key, value):
# 有效控制,判断,监控,日志
self.__dict__["data"][key] = value
def __getattr__(self, key):
if key in self.__dict__["data"]:
return self.__dict__["data"][key]
else:
raise AttributeError(f"'Cache' object has no attribute '{key}'")
def __delattr__(self, key):
if key in self.__dict__["data"]:
del self.__dict__["data"][key]
else:
raise AttributeError(f"'Cache' object has no attribute '{key}'")
def __contains__(self, name):
return name in self.__dict__["data"]
cache = Cache()
cache.name = "yuan"
cache.age = 19
print(cache.name)
del cache.age
print("age" in cache)
# print(cache.age)
6. 异常机制
异常机制是一种在程序运行过程中处理错误和异常情况的机制。当程序执行过程中发生异常时,会中断正常的执行流程,并转而执行异常处理的代码。这可以帮助我们优雅地处理错误,保证程序的稳定性和可靠性。
在Python中,异常以不同的类型表示,每个异常类型对应不同的错误或异常情况。当发生异常时,可以使用 try-except 语句来捕获并处理异常。try 块中的代码被监视,如果发生异常,则会跳转到对应的 except 块,执行异常处理的代码。
【1】Error类型
在Python中,常见的错误关键字(Exception Keywords)指的是一些常见的异常类型,它们用于表示不同的错误或异常情况。以下是一些常见的错误关键字及其对应的异常类型:
SyntaxError:语法错误,通常是由于代码书写不正确而引发的异常。NameError:名称错误,当尝试访问一个未定义的变量或名称时引发的异常。IndexError:索引错误,当访问列表、元组或字符串等序列类型时使用了无效的索引引发的异常。KeyError:键错误,当尝试使用字典中不存在的键引发的异常。ValueError:值错误,当函数接收到一个正确类型但是不合法的值时引发的异常。FileNotFoundError:文件未找到错误,当尝试打开或操作不存在的文件时引发的异常。ImportError:导入错误,当导入模块失败时引发的异常,可能是因为找不到模块或模块中缺少所需的内容。ZeroDivisionError:零除错误,当除法或取模运算的除数为零时引发的异常。AttributeError:属性错误,当尝试访问对象不存在的属性或方法时引发的异常。IOError:输入/输出错误,当发生与输入和输出操作相关的错误时引发的异常。例如,尝试读取不存在的文件或在写入文件时磁盘已满。
【2】基本语法
异常的基本结构:try except
# (1) 通用异常
try:
pass # 正常执行语句
except Exception as ex:
pass # 异常处理语句
# (2) 指定异常
try:
pass # 正常执行语句
except <异常名>:
pass # 异常处理语句
# (3) 统一处理多个异常
try:
pass # 正常执行语句
except (<异常名1>, <异常名2>, ...):
pass # 异常处理语句
# (4) 分别处理不同的异常
try:
pass # 正常执行语句
except <异常名1>:
pass # 异常处理语句1
except <异常名2>:
pass # 异常处理语句2
except <异常名3>:
pass # 异常处理语句3
# (5) 完整语法
try:
pass # 正常执行语句
except Exception as e:
pass # 异常处理语句
else:
pass # 测试代码没有发生异常
finally:
pass # 无论是否发生异常一定要执行的语句,比如关闭文件,数据库或者socket
机制说明:
- 首先,执行try子句(在关键字try和关键字except之间的语句)
- 如果没有异常发生,忽略except子句,try子句执行后结束。
- 如果在执行try子句的过程中发生了异常,那么try子句余下的部分将被忽略。如果异常那么对应的except子句将被执行。
- 在Python的异常中,有一个通用异常:
Exception,它可以捕获任意异常。
【3】raise
很多时候,我们需要主动抛出一个异常。Python内置了一个关键字raise,可以主动触发异常。
raise可以抛出自定义异常,我们已将在前面看到了python内置的一些常见的异常类型。大多数情况下,内置异常已经够用了。但是有时候你还是需要自定义一些异常:自定义异常应该继承Exception类,直接继承或者间接继承都可以,例如:
class CouponError01(Exception):
def __init__(self):
print("优惠券错误类型1")
class CouponError02(Exception):
def __init__(self):
print("优惠券错误类型2")
class CouponError03(Exception):
def __init__(self):
print("优惠券错误类型3")
try:
print("start")
print("...")
x = input(">>>")
if x == "1":
raise CouponError01
elif x == "2":
raise CouponError02
elif x == "3":
raise CouponError03
except CouponError01:
print("优惠券错误类型1")
except CouponError02:
print("优惠券错误类型2")
except CouponError03:
print("优惠券错误类型3")
若有错误与不足请指出,关注DPT一起进步吧!!!