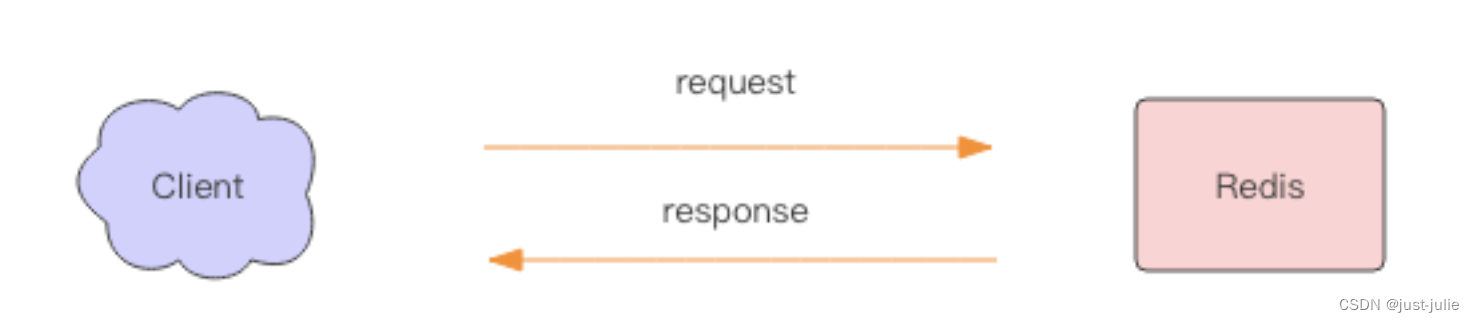
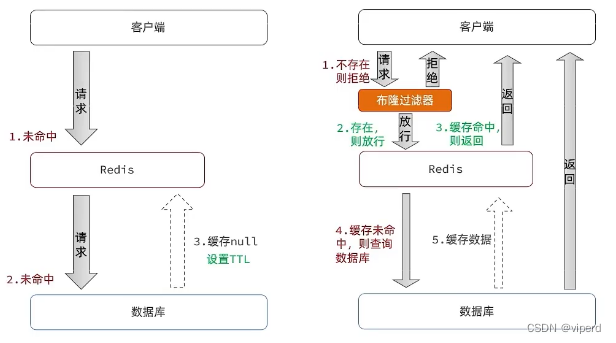
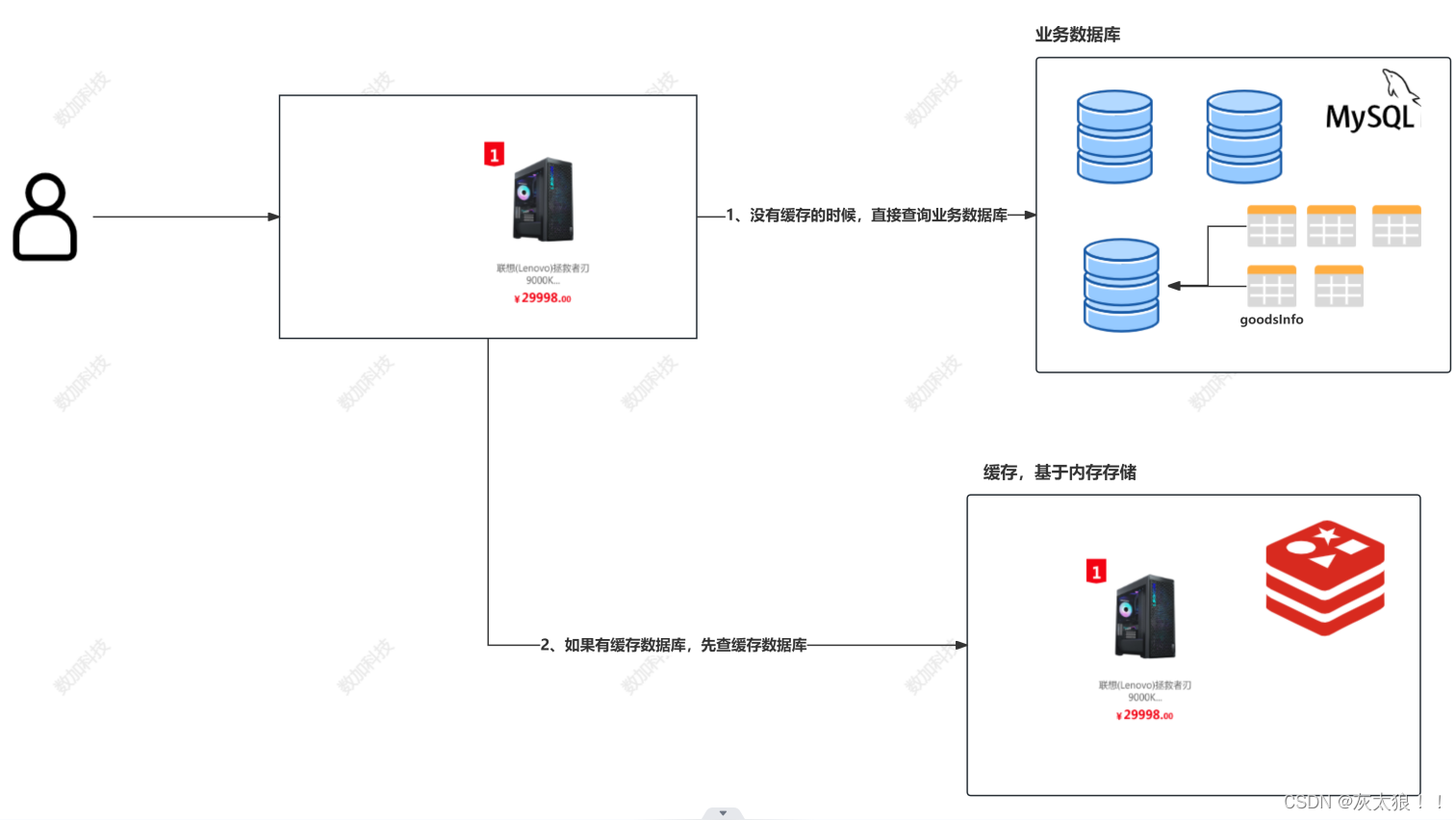
Redis缓存穿透是指查询一个不存在于数据库中的数据(通常是恶意用户发起的连续请求),由于缓存中没有,每次请求都会穿透到数据库,这可能会对数据库造成不必要的压力。解决缓存穿透问题的常见策略包括:
1. 布隆过滤器:用于判断一个元素是否可能存在于集合中,即使它返回存在,也可能是个假阳性(误报),但不会出现假阴性(即如果布隆过滤器说不存在,则该元素一定不存在)。因此,可以在查询数据库之前先检查布隆过滤器。
2. 空值缓存:即使数据库中没有找到对应记录,也将空值(如null)写入缓存,并设置一个较短的有效期。这样,后续相同请求在缓存有效期内可以直接从缓存中得到结果,而不需要再次访问数据库。
3. 设置黑白名单:通过白名单使需要的请求访问,通过黑名单防止攻击。
首先,确保你的项目中包含了Spring Data Redis和Guava的依赖。
布隆过滤器配置
import com.google.common.hash.Funnel;
import com.google.common.hash.Hashing;
import com.google.common.math.LongMath;
import com.google.common.primitives.Chars;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 布隆过滤器配置类,用于初始化布隆过滤器的实例及其相关组件。
*/
@Configuration
public class BloomFilterConfig {
/**
* 创建字符串处理的Funnel,用于将字符串转换为哈希输入。
*
* @return 字符串Funnel实例
*/
@Bean
public Funnel<String> stringFunnel() {
return (from, into) -> Chars.forEachUtf8(from, c -> into.putChar(c));
}
/**
* 初始化布隆过滤器,基于预期插入数量和误报率进行配置。
*
* @param funnel 字符串处理的Funnel
* @return 布隆过滤器实例
*/
@Bean
public BloomFilter<String> bloomFilter(Funnel<String> funnel) {
int expectedInsertions = 100000; // 预计需要插入过滤器的元素数量
double fpp = 0.01; // 可接受的误报率,即预测为存在但实际上不存在的概率
// 计算所需的哈希函数数量
int numHashFunctions = LongMath.log2(LongMath.pow(2, Long.SIZE) / expectedInsertions * fpp);
// 创建布隆过滤器实例
return BloomFilter.create(funnel, expectedInsertions, fpp, Hashing.murmur3_128());
}
}
缓存服务实现
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
/**
* 缓存服务实现类,负责处理数据的缓存逻辑,包括使用布隆过滤器和空值缓存策略防止缓存穿透。
*/
@Service
public class CacheService {
private final StringRedisTemplate redisTemplate;
private final BloomFilter<String> bloomFilter;
/**
* 构造函数注入Redis模板和布隆过滤器实例。
*
* @param redisTemplate Redis操作模板
* @param bloomFilter 布隆过滤器实例
*/
@Autowired
public CacheService(StringRedisTemplate redisTemplate, BloomFilter<String> bloomFilter) {
this.redisTemplate = redisTemplate;
this.bloomFilter = bloomFilter;
}
/**
* 获取数据的方法,首先检查布隆过滤器,然后尝试从Redis缓存中获取,
* 若缓存未命中且布隆过滤器认为可能存在,则查询数据库,并实施空值缓存策略。
*
* @param key 数据的唯一标识
* @return 查询到的数据或空值、提示信息
*/
public String getData(String key) {
// 使用布隆过滤器快速判断key是否可能存在,减少不必要的数据库查询
if (!bloomFilter.mightContain(key)) {
return "This key is likely not in the database.";
}
// 尝试从Redis缓存中获取数据
String value = redisTemplate.opsForValue().get(key);
// 如果缓存未命中,且布隆过滤器判断可能在数据库中,则查询数据库
if (value == null) {
value = databaseFetch(key);
// 数据库中也不存在,则将空值写入缓存,设置较短过期时间以避免长时间占用缓存
if (value == null) {
redisTemplate.opsForValue().set(key, "", 5, TimeUnit.MINUTES);
} else {
// 数据库中存在,则正常缓存该值
redisTemplate.opsForValue().set(key, value);
}
}
return value;
}
/**
* 模拟从数据库获取数据的方法,实际应用中应替换为真实的数据库访问逻辑。
*
* @param key 数据查询键
* @return 从数据库查询到的数据或null
*/
private String databaseFetch(String key) {
// 示例中始终返回null,表示数据库中也没有该数据
return null;
}
}





![[<span style='color:red;'>Redis</span>]——缓存击穿和缓存<span style='color:red;'>穿透</span>及<span style='color:red;'>解决</span><span style='color:red;'>方案</span>(图解+代码+<span style='color:red;'>解释</span>)](https://img-blog.csdnimg.cn/direct/b259e82ea25f4703bc116c82ebfd2307.png)