一、背景
不管是实际工作还是面试,这3个问题都是非常常见的,今天我们就好好探讨一下这个三个问题的解决方案
三者的区别:
缓存穿透:查询缓存和数据库都不存在的数据,缓存没有,数据库也没有
缓存击穿:缓存中数据的key过期了,这时候所有请求都到数据库查询,瞬时大量请求击穿数据库
缓存雪崩:缓存雪崩通常发生在大量key同一时间失效,⼤量的请求进来直接打到DB上,影响整个系统,而缓存击穿是针对某一具体的缓存 key 失效而言,影响相对局部。
接下来,我们逐个分析并解决上述问题
二、缓存穿透
缓存穿透指的查询缓存和数据库中都不存在的数据,这样每次请求直接打到数据库,就好像缓存不存在一样。
缓存穿透指的是一个请求查询一个缓存中不存在的数据,而且这个数据也不在后端存储中,导致大量的请求直接访问后端存储,从而增加了后端存储的负载。
通常情况下,大量的缓存穿透问题不太可能由正常的程序行为引起,更可能是由于恶意攻击者的行为。正常的程序通常会经过合理的设计,避免频繁查询不存在的数据,或者在查询不存在的数据时会有一些容错机制或者缓存预热等策略。
为了防止缓存穿透,可以采取一些预防措施,例如:
- 数据校验:对请求的数据进行校验,确保数据的完整性和有效性
- 缓存空对象:对于不存在的数据,将其缓存起来,并设置一个较短的过期时间,这样可以避免大量请求直接穿透到数据库。
- 布隆过滤器:布隆过滤器是一种数据结构,可以快速判断一个元素是否在一个集合中。在缓存系统中,可以使用布隆过滤器来过滤掉非法请求,避免它们穿透到数据库。
- 限流和验证:对于频繁出现缓存穿透的请求,可以进行限流,确保不会过多地访问数据库。
使用互斥锁或分布式锁:在缓存失效时,使用锁机制防止多个线程同时查询数据库,只允许一个线程去数据库查询,其他线程等待查询结果。
1 未做处理出现缓存穿透
代码演示:
@GetMapping("/getGoodsDetailsWithCache")
public GoodsInfo getGoodsDetailsWithCache(@RequestParam(value = "goodsId") Long goodsId) {
String goodsInfoCache = stringRedisTemplate.opsForValue().get(RedisConstants.GOODS_INFO + goodsId);
if (StringUtils.isNotBlank(goodsInfoCache)) {
log.info("getGoodsDetailsWithCache hit cache, goodsId: {}", goodsId);
return JSON.parseObject(goodsInfoCache, GoodsInfo.class);
}
log.info("getGoodsDetailsWithCache request database, goodsId: {}", goodsId);
GoodsInfo goodsInfo = goodsInfoMapper.selectByPrimaryKey(goodsId);
// 数据也没有
if (goodsInfo == null) {
log.warn("getGoodsDetailsWithCache data not find, goodsId: {}", goodsId);
return null;
}
// 保存到Redis
stringRedisTemplate.opsForValue().set(RedisConstants.GOODS_INFO + goodsId, JSON.toJSONString(goodsInfo), Duration.ofSeconds(300));
log.info("getGoodsDetailsWithCache get by mysql, goodsId: {}", goodsId);
return goodsInfo;
}
演示同一个不存在的Key大量请求,goodsId = 10000000(数据库不存在)
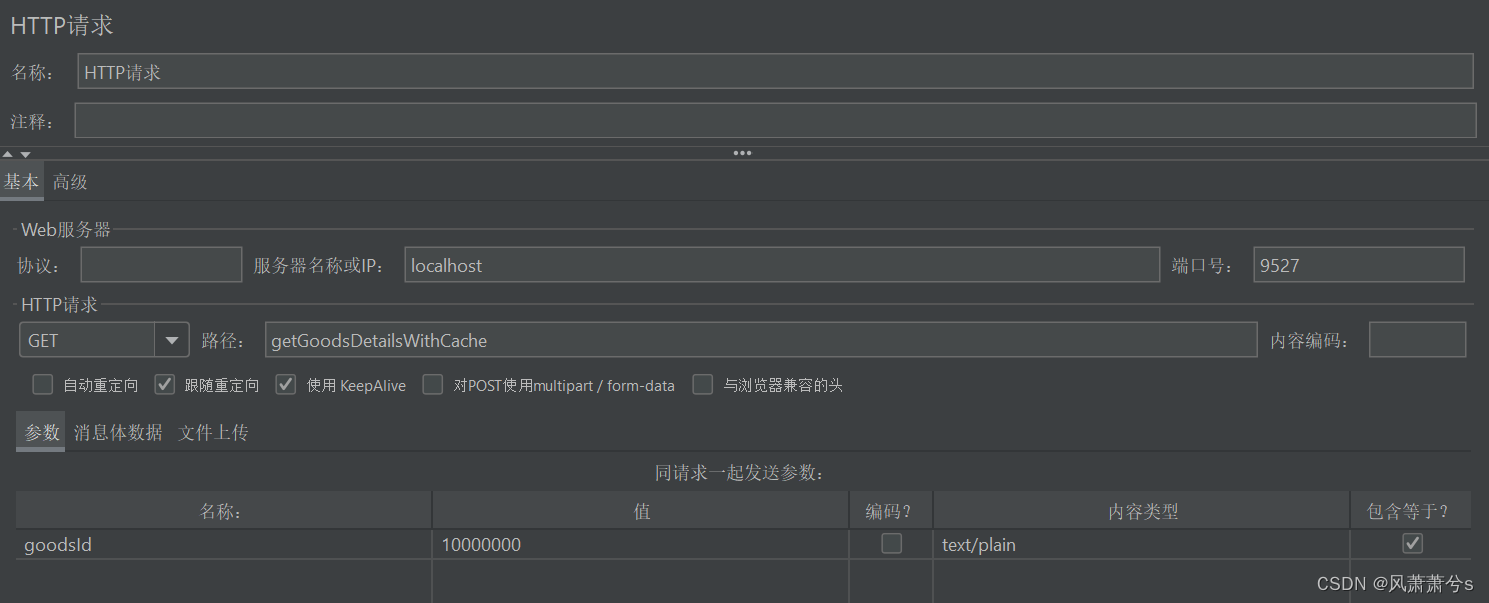

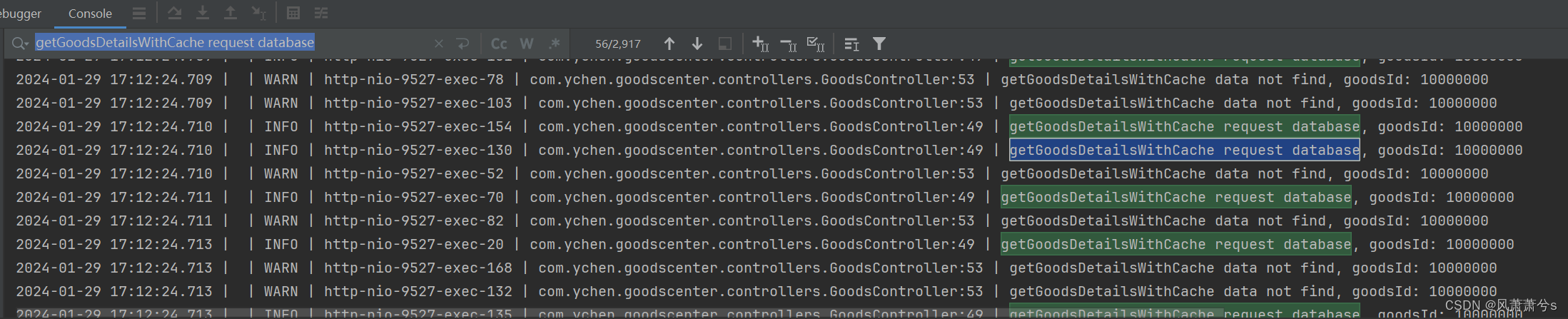
大量的请求访问数据库,导致数据库的压力剧增加,严重时会出其他的正常的请求无法访问数据库,所以这种问题必须要提前预防
2 数据校验
对一些明显无效的数据进行校验,可以在一定程度上防止黑客恶意仿造数据库中不存在的Key
存在的问题: 攻击者可以轻松找到key的规律,生成符合规律的Key,比较简单,这里就不演示了
3 缓存空对象
对数据库中不存在的对象也缓存一个Null到Redis中,可以解决攻击者采用少量不同的key攻击
存在的问题:如果攻击者仿造大量不同的key,缓存穿透问题没有解决,还导致Redis增加大量的无效Key,影响正常的key
代码演示
@GetMapping("/getGoodsDetailsWithCache1")
public GoodsInfo getGoodsDetailsWithCache1(@RequestParam(value = "goodsId") Long goodsId) {
String goodsInfoCache = stringRedisTemplate.opsForValue().get(RedisConstants.GOODS_INFO + goodsId);
if (StringUtils.isNotBlank(goodsInfoCache)) {
log.info("getGoodsDetailsWithCache hit cache, goodsId: {}", goodsId);
return JSON.parseObject(goodsInfoCache, GoodsInfo.class);
}
if (Objects.equals(goodsInfoCache, "")) {
log.info("getGoodsDetailsWithCache hit cache, goodsId: {}", goodsId);
return null;
}
log.info("getGoodsDetailsWithCache request database, goodsId: {}", goodsId);
GoodsInfo goodsInfo = goodsInfoMapper.selectByPrimaryKey(goodsId);
// 数据也没有
if (goodsInfo == null) {
log.warn("getGoodsDetailsWithCache data not find, goodsId: {}", goodsId);
stringRedisTemplate.opsForValue().set(RedisConstants.GOODS_INFO + goodsId, "", Duration.ofSeconds(120));
return null;
}
// 保存到Redis
stringRedisTemplate.opsForValue().set(RedisConstants.GOODS_INFO + goodsId, JSON.toJSONString(goodsInfo), Duration.ofSeconds(300));
log.info("getGoodsDetailsWithCache get by mysql, goodsId: {}", goodsId);
return goodsInfo;
}演示不存在同一个Key的大量请求
goodsId = 10000000(数据库不存在)


全部命中cache,并发量也达到了8k+,数据库仍然得到了保护
演示不存在且不同Key的大量请求




大量的请求仍然访问到了数据库,另外Redis中存在大量的空值,所以比什么都不做,导致系统的问题更大
4 布隆过滤器
因为我们是分布式系统,所以选择Redis版本的布隆过滤器,在分布式环境中使用Redis版本会更容易管理和维护
布隆过滤器的安装过程,这里不做重点演示了,如果连接github网络情况比较差的话,非常麻烦,下面推荐一篇博文,我的安装过程比这个遇到的坑更多安装RedisBloom插件_redisbloom下载-CSDN博客
布隆过滤器在java中的使用,这里我尝试通过Spring提供的RedisTemplate,各种尝试均失败了,无法通过RedisTemplate 操作Redis的布隆过滤器,最后无赖放弃了,网上比较推荐的是使用Redisson,所以最后没办法在一个项目中使用了2个Redis组件,不多说开始演示吧
代码演示
初始化布隆过滤器,预计200w的数据,误判率1%,现在有100w的商品ID需要初始化, 需要等待大约5分钟左右初始化完成(真实的应用是要一直维护布隆过滤器的,每新增一件商品都需要往布隆过滤器中添加商品ID)
@Test
public void testRedissonBloom() {
RBloomFilter<Long> filter = redissonClient.getBloomFilter("goods_id_bloom_filter");
filter.tryInit(2000000, 0.01);
List<Long> idList = goodsInfoMapper.selectGoods();
int size = idList.size();
for (int i = 0; i < size; i++) {
filter.add(idList.get(i));
if (i % 1000 == 0) {
log.info("进度: " + i * 100 / size + "%");
}
}
}下面是用于测试商品加入了布隆过滤器解决了缓存穿透问题,这里要注意的是,布隆过滤器请求需要放在缓存请求之后,数据库访问之前,这样不会影响到正常访问缓存中数据的吞吐量,并且同样能够保护到MySQL数据库
@GetMapping("/getGoodsDetailsWithCache2")
public GoodsInfo getGoodsDetailsWithCache2(@RequestParam(value = "goodsId") Long goodsId) {
if(!bloomFilter.contains(goodsId)){
log.info("bloomFilter not contains, goodsId: {}", goodsId);
return null;
}
String goodsInfoCache = stringRedisTemplate.opsForValue().get(RedisConstants.GOODS_INFO + goodsId);
if (StringUtils.isNotBlank(goodsInfoCache)) {
log.info("getGoodsDetailsWithCache hit cache, goodsId: {}", goodsId);
return JSON.parseObject(goodsInfoCache, GoodsInfo.class);
}
if (Objects.equals(goodsInfoCache, "")) {
log.info("getGoodsDetailsWithCache hit cache, goodsId: {}", goodsId);
return null;
}
log.info("getGoodsDetailsWithCache request database, goodsId: {}", goodsId);
GoodsInfo goodsInfo = goodsInfoMapper.selectByPrimaryKey(goodsId);
// 数据也没有
if (goodsInfo == null) {
log.warn("getGoodsDetailsWithCache data not find, goodsId: {}", goodsId);
stringRedisTemplate.opsForValue().set(RedisConstants.GOODS_INFO + goodsId, "", Duration.ofSeconds(86400));
return null;
}
// 保存到Redis
stringRedisTemplate.opsForValue().set(RedisConstants.GOODS_INFO + goodsId, JSON.toJSONString(goodsInfo), Duration.ofSeconds(86400));
log.info("getGoodsDetailsWithCache get by mysql, goodsId: {}", goodsId);
return goodsInfo;
}演示不存在且不同Key的大量请求

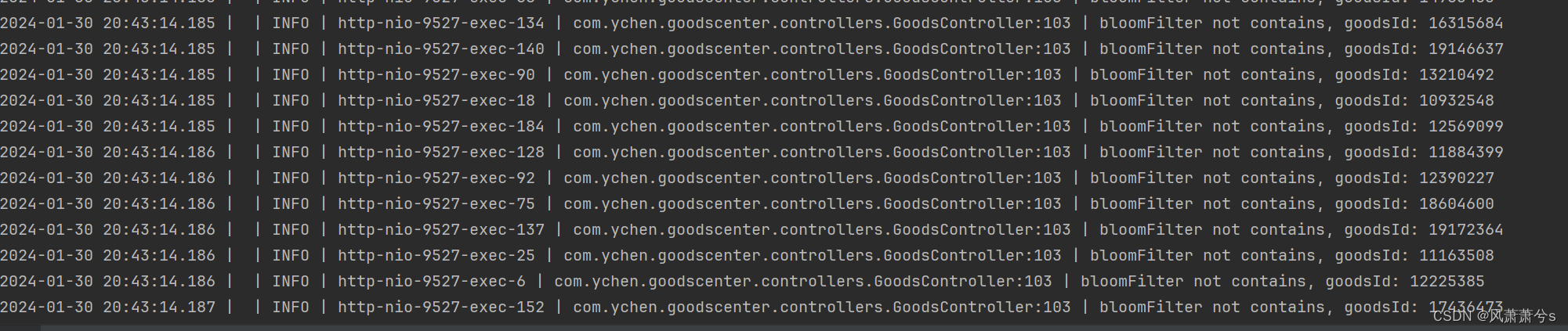
大量的请求都被布隆过滤器过滤掉了

演示访问存在且在缓存中的key


结论
从上面的演示结果来看,引入布隆过滤器的确解决了大量不存在且不同Key缓存穿透问题,虽然牺牲部分Redis的性能,但是保护了MySQL的正常访问。
5 限流和验证
限制来自客户端的请求数量和频率,防止过多的请求直接穿透到数据库,这里可以使用Sentinel 框架限制请求,比如通过IP限流,用户ID限流,一般情况下我们系统访问商品详情需要登录才能访问,那么如果一个用户疯狂请求商品详情接口,也就说明这是恶意攻击了,可以直接拦截掉,所以我认为
6 使用互斥锁或分布式锁
在缓存失效时,使用锁机制防止多个线程同时查询数据库,只允许一个线程去数据库查询,其他线程等待查询结果。我认为这种方式也是一种非常不错简单高效的方式,或者另一种变相的方式是,就不演示了
三、缓存击穿
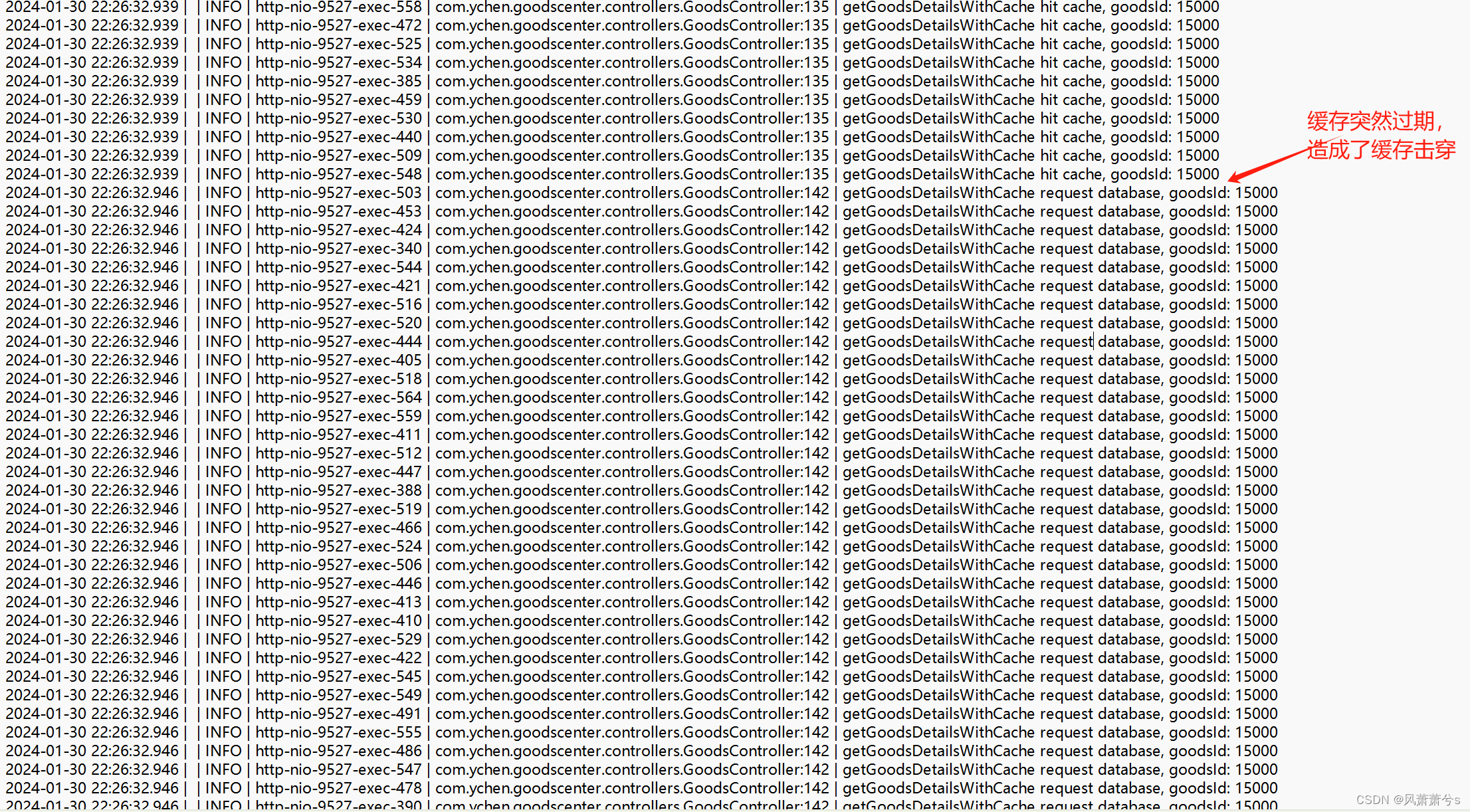
缓存中数据的key过期了,这时候所有请求都到数据库查询,瞬时大量请求击穿数据库,常见的解决方案
使用互斥锁或分布式锁: 在缓存失效时,只允许一个线程去加载数据到缓存,其他线程需要等待。这样可以避免多个线程同时访问数据库,减轻数据库压力。
提前设置较长的缓存过期时间: 在设置缓存的过期时间时,可以将其设置得相对较长,避免在短时间内多次发生缓存失效。
使用二级缓存: 引入两层缓存,第一层是短期缓存,用于解决高并发下的缓存击穿问题,第二层是较长期的缓存,用于存放相对不频繁变更的数据。这样在第一层缓存失效时,可以从第二层缓存中快速获取数据。
预加载热点数据: 在系统启动或运行过程中,将一些热点数据提前加载到缓存中,防止在短时间内多次发生缓存失效。
1 未做处理出现缓存击穿场景演示

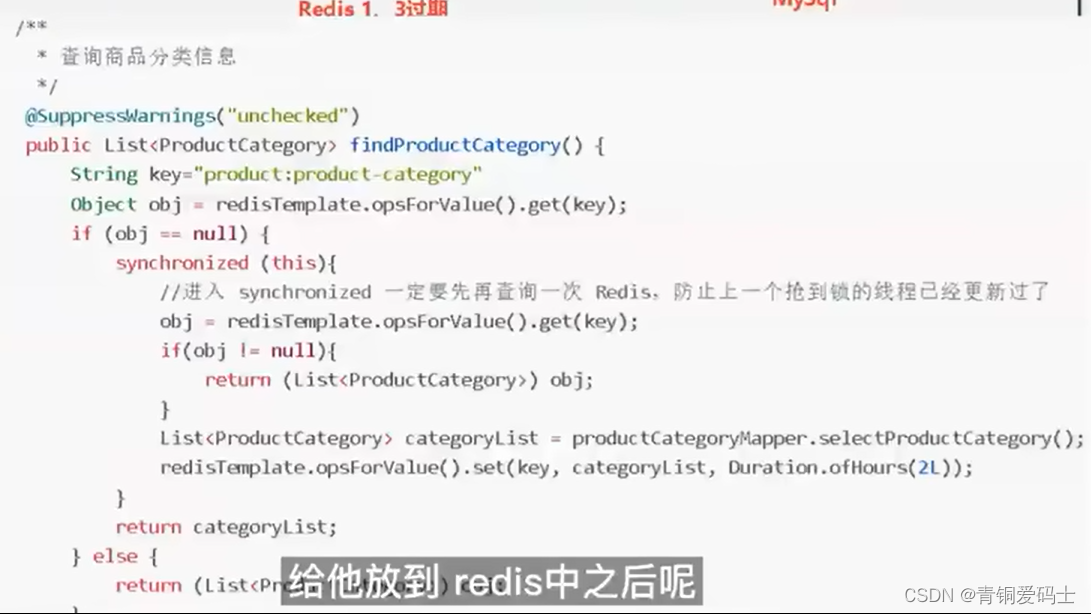
2 添加互斥锁
看代码,我在请求数据之前加了synchronized 互斥锁,达到保护数据库的作用
@GetMapping("/getGoodsDetailsWithCache4")
public GoodsInfo getGoodsDetailsWithCache4(@RequestParam(value = "goodsId") Long goodsId) {
String goodsInfoCache = stringRedisTemplate.opsForValue().get(RedisConstants.GOODS_INFO + goodsId);
if (StringUtils.isNotBlank(goodsInfoCache)) {
log.info("getGoodsDetailsWithCache hit cache, goodsId: {}", goodsId);
return JSON.parseObject(goodsInfoCache, GoodsInfo.class);
}
if (Objects.equals(goodsInfoCache, "")) {
log.info("getGoodsDetailsWithCache hit cache, goodsId: {}", goodsId);
return null;
}
GoodsInfo goodsInfo;
synchronized (this) {
log.info("getGoodsDetailsWithCache request database, goodsId: {}", goodsId);
goodsInfo = goodsInfoMapper.selectByPrimaryKey(goodsId);
// 数据也没有
if (goodsInfo == null) {
log.warn("getGoodsDetailsWithCache data not find, goodsId: {}", goodsId);
stringRedisTemplate.opsForValue().set(RedisConstants.GOODS_INFO + goodsId, "", Duration.ofSeconds(3));
return null;
}
// 保存到Redis
stringRedisTemplate.opsForValue().set(RedisConstants.GOODS_INFO + goodsId, JSON.toJSONString(goodsInfo), Duration.ofSeconds(3));
log.info("getGoodsDetailsWithCache get by mysql, goodsId: {}", goodsId);
}
return goodsInfo;
}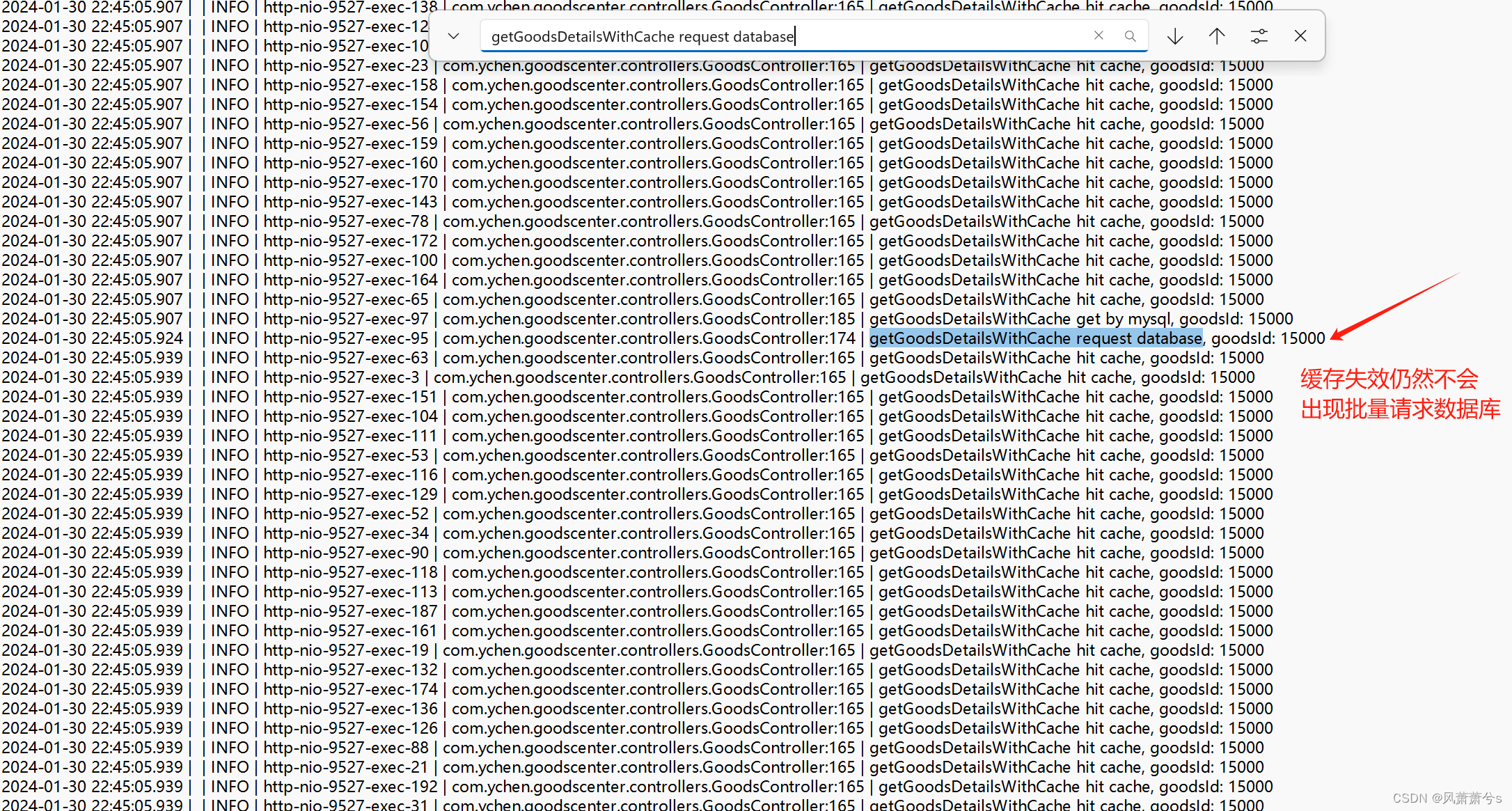
使用synchronized锁的确对数据库起到了保护作用,但是会不会降低正常的并发数,接下来我们测试一下正常没有缓存的商品访问看看吞吐量是多少,使用随机10w个商品ID请求,最后测试的吞吐量为388,比不加synchronized锁直接请求数据库800多的吞吐量还是少了一半多


3 提前设置较长的缓存过期时间
在设置缓存的过期时间时,可以将其设置得相对较长,避免在短时间内多次发生缓存失效
4 使用二级缓存
引入两层缓存,第一层是短期缓存,用于解决高并发下的缓存击穿问题,第二层是较长期的缓存,用于存放相对不频繁变更的数据。这样在第一层缓存失效时,可以从第二层缓存中快速获取数据。
5 预加载热点数据
在系统启动或运行过程中,将一些热点数据提前加载到缓存中,防止在短时间内多次发生缓存失效。
四、缓存雪崩
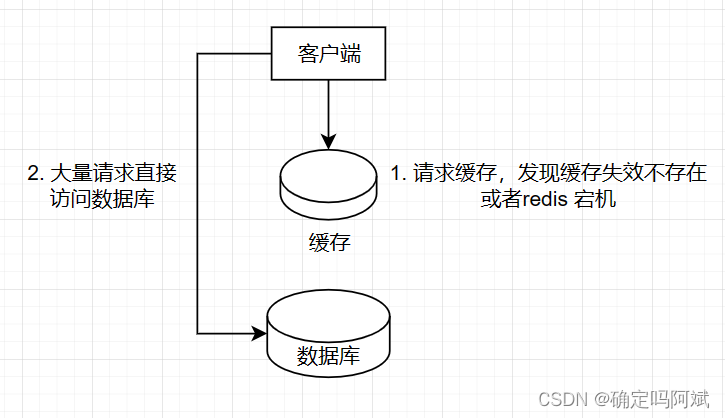
缓存雪崩通常发生在大量key同一时间失效,⼤量的请求进来直接打到DB上,影响整个系统,而缓存击穿是针对某一具体的缓存 key 失效而言,影响相对局部。
设置合理的过期时间:
在缓存中设置过期时间,避免所有缓存同时过期。可以使用随机的过期时间,分散缓存过期的时间点,减缓雪崩效应。使用互斥锁机制:
在缓存中加入互斥锁,保证在缓存失效的情况下,只有一个请求能够重新生成缓存,其他请求等待该请求完成后再获取缓存,避免大量请求同时落到数据库。采用多级缓存:
使用多级缓存架构,例如本地缓存、分布式缓存、全局缓存等。即使一个缓存层出现问题,其他层次的缓存仍然可用,降低缓存雪崩的风险。预热缓存:
在系统启动或低峰期,预先加载热门数据到缓存中,避免在高峰期大量请求同时访问数据库。这样可以降低缓存失效时对后端资源的冲击。使用缓存异步刷新:
在缓存即将过期时,异步地去更新缓存,而不是等到缓存失效时再去重新生成。这样可以确保缓存数据的时效性,并减小因缓存过期导致的并发请求冲击。限流和熔断机制:
对访问缓存的请求进行限流和熔断,防止大量请求同时涌入,减轻系统压力,确保系统能够稳定运行。监控和报警:
部署监控系统,实时监测缓存的使用情况、命中率、过期情况等,设置相应的报警机制,及时发现并解决潜在的缓存问题。
综合使用上述策略可以有效地降低缓存雪崩的风险,提高系统的稳定性和性能。
五、总结
缓存穿透、缓存击穿、缓存雪崩看似3个问题,实际上还是有一些相通的点,总结一下,如何在一个接口中做到同时预防这3个问题
1 兜底处理--访问数据库加上互斥锁
3个问题都是要解决缓存失效导致数据库访问量突然增大,那么可以使用一个兜底逻辑,那就是对数据库访问加同步锁,这样最坏的情况,很多请求卡在获取锁的位置,正常没有缓存的请求可能会变慢,但是总体的来说,数据库得到了保护,有缓存的用户请求仍然可以正常访问。
2 布隆过滤器--解决缓存穿透问题
布隆过滤器虽然解决缓存穿透问题,但是需要不断维护,必要时需要重新构建
3 缓存过期时间设置随机
分散缓存过期的时间点,可以减缓雪崩效应。
4 预热缓存
比如某些被认为是热点的商品在添加之时就加入到缓存,而不是等到上架或者访问时加入缓存。
5 对缓存命中率进行监控
实时监测缓存的使用情况、命中率、过期情况等,设置相应的报警机制也是很重要的,一旦发现异常,可以通知到开发人员,及时处理问题。
6 熔断机制
一旦出现大量线程等待或者访问失败,可以启动熔断机制,保护正常的服务不受影响